概要
ソフトウェアの並列化により、データセットの実行時間の短縮、一定時間でのデータセットの実行、あるいはスレッド化されていないソフトウェアでは扱うのが難しい大規模なデータセットの実行が可能になります。ソフトウェアをシリアルで実行した場合と並列で実行した場合を比較して、達成された速度向上を数値化することで並列化が成功しかたどうかを判断できます。また、期待できる性能向上と比較するのも有益です。期待できる性能向上は、アムダールの法則とグスタフソンの法則によって導くことができます。
この記事は、「マルチスレッド・アプリケーションの開発のためのインテル・ガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
アプリケーションの実行が高速化すると、その分ユーザーの待機時間が短縮されます。また、実行時間が短縮されれば、大きなデータセット (大規模なデータレコード、多くのピクセル、大規模な物理モデル) でも妥当な時間で実行できるようになります。シリアルで実行した場合と並列で実行した場合の比較を具体的に数量化する指標の 1 つに「速度向上 (スピードアップ)」が挙げられます。
速度向上とは、簡単に言うとシリアルで実行した場合の時間と並列で実行した場合の時間の比率のことです。例えば、アプリケーションをシリアルで実行した場合に 6,720 秒かかり、並列で実行した場合に 126.7 秒 (64 スレッド、64 コアを使用) かかったとすると、並列の場合には 53 倍 (6720/126.7 = 53.038) の速度向上が達成されたことになります。
アプリケーションのスケーラビリティーが優れていれば、コア数 (スレッド数) が増えるにしたがって、同程度かあるいはほぼ近い率で速度向上が達成されます。使用するスレッド数を増やしても、速度向上が維持できなかったり、横ばいだったり、または速度が低下し始めた、などの現象が起きたら、測定対象のデータセットのスケーラビリティーが低いと言えます。測定対象のデータセットがアプリケーションの典型的なデータセットであれば、アプリケーション自体のスケーラビリティーが低いと言えるでしょう。
速度向上と関連して、「効率性 (ゲイン)」という指標があります。シリアル実行の場合と比較して並列実行がどの程度速くなったかを計る指標が「速度向上」であるのに対し、「効率性」はソフトウェアがシステムの計算リソースをいかに活用しているかを示すものです。並列実行の効率性は、測定された速度向上を使用されたコア数で割り、得られた数字をパーセンテージに変換することで算出できます。例えば、64 コアで 53 倍の速度向上を得られた場合、効率性は 82.8% (53/64 = 0.828) です。つまり、実行中、各コアのアイドル状態の時間は平均 17% です。
アムダールの法則
並列化プロジェクトに着手する前に、まず達成可能な性能向上 (速度向上) を把握しましょう。並列に実行できるシリアルコードの比率がわかっていれば (または予想できれば)、実際に並列コードを記述して実行しなくても、アムダールの法則を使用して達成可能なアプリケーションの速度向上の限界を知ることができます。アムダールの法則の数式には、いくつかバリエーションがあります。どの数式でも、並列実行の時間の割合 (pctPar)、シリアル実行の時間 (1 - pctPar)、スレッド数/コア数 (p) が使用されます。p コアで実行した場合の並列アプリケーションの速度向上を予測する簡単な式を次に示します。
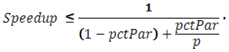
従来のシリアル実行時間を 1 として、単純に並列実行の時間で割ります。並列実行の時間は、シリアル実行の割合 (1 - pctPar) と並列で実行できる割合を使用されるコア数 (pctPar/p) で割った数で算出できます。例えば、シリアル・アプリケーションの実行時間のうちの 95% を 8 コアで並列実行できる場合、アムダールの法則で予測される速度向上は 6 倍 (1 / (0.05 + 0.95/8) = 5.925) となります。
数式の (≦) の関係に加え、アムダールの法則では、並列で実行可能な計算処理は、無限数のコアで割ることができると仮定されています。このような仮定によって、分母の 2 番目の項を解り易く整理できます。つまり、速度向上の限界はシリアル実行の割合を逆にしたものということです。
これまで、アムダールの法則は現実に存在する通信や同期、その他のスレッド管理などから生じるオーバーヘッドを無視していること、コア・プロセッサー数を無限と仮定していることに批判がありました。同時実行されるアルゴリズムには付きもののオーバーヘッドが考慮されていないほか、一番の批判の的は、コア数の増加に伴って処理するデータ量が増えることが考慮されていない点です。アムダールの法則では、使用されるコア数に関わらずデータサイズが固定であること、シリアル実行時間全体における割合は同じであると仮定されています。
グスタフソンの法則
8 個のコアを使用する並列アプリケーションで元のサイズの 8 倍のデータセットが計算できるとすると、シリアル部分の実行時間は長くなるでしょうか。もし長くなるとしても、データセットと同じ割合では長くなりません。実際のデータでは、シリアル実行の時間はほとんど一定です。
グスタフソンの法則は、「scaled speedup (スケールする速度向上)」としても知られ、コア数に比例したデータサイズの拡大を考慮に入れ、大規模なデータセットをシリアル実行できるものとして、アプリケーションの速度向上 (の限界) を計算します。数式は以下のように表されます。
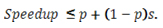
アムダールの法則と同様、p はコア数を表します。s は並列アプリケーションのデータセットのサイズにおけるシリアル実行時間の割合です。例えば、32 コアで実行した場合の時間のうちの 1% がシリアル実行で費やされたとすると、この同じデータセットをシングルスレッド、シングルコアで実行した場合 (可能と仮定する) 、アプリケーションの速度向上は次のとおりです。
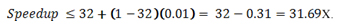
このような仮定でアムダールの法則ではどのように速度向上が計算されるかを考えてみましょう。シリアル実行の割合を 1% と仮定すると、アムダールの法則の式では 1/(0.01 + (0.99/32)) = 24.43 倍 (X) になります。しかし、シリアル時間の割合は 32 コアでの実行に対するものなので、これは誤りです。この例では、コア数が多い場合や少ない場合 (あるいは 1 コアの場合) に対応するシリアル実行の割合が示されていません。コードが完全にスケーラブルでデータサイズがコア数の増加とともにスケールする場合、シリアル実行の割合は一定のままということもあり、アムダールの法則では 32 コアで (固定サイズの) シングルコアの問題を解く場合の速度向上となります。
一方、32 コアでの並列アプリケーションの実行時間の合計がわかっている場合には、シリアル実行時間の計算が可能で、サイズが固定された問題 (さらにシングルコアで計算可能であると仮定する) での 32 コアの速度向上をアムダールの法則によって算出できます。並列アプリケーションを 32 コアで実行した場合の時間の合計が 1,040 秒とすると、その 1% はシリアル実行の割合で 10.4 秒です。並列実行の秒数 (1029.6) を 32 コア数にかけると、アプリケーションの実行時間の合計は 1029.6*32+10.4 = 32957.6 秒になります。並列実行できない時間 (10.4 秒) は合計時間の 0.032% です。この数字を使用して、アムダールの法則で算出すると、速度向上は 1/(0.00032 + (0.99968/32)) = 31.686 倍になります。
グスタフソンの法則では、並列実行におけるシリアル時間の割合が必要なため、通常、同じサイズの問題を解く場合のシリアル実行に対して、スケールする並列実行の速度向上を計算 (コア数の増加に伴って規模が大きくなるデータセット) する場合に使用されます。上記の例から、アムダールの法則の数式を用いてアプリケーション実行のデータを厳密に使用してしまうと、「スケールする速度向上」の数式と比べてかなり低い数字が算出されます。
アドバイス
速度向上の計算には、最良のシリアル・アルゴリズムと最速のシリアルコードを比較する必要があります。最適とは言えないシリアル・アルゴリズムの方が並列化を容易に行えることがよくあります。しかしそのような場合でも、実行速度の速いシリアルコードがあるのに、遅いシリアルコードを使う人はいません。このように、根底のアルゴリズムが異なっても、最速のシリアルコードで得られるベストなシリアル実行時間を使用して、比較対象の並列アプリケーションの速度向上を算出します。
速度向上の値は倍数で表します。以前は、速度向上の比率は % で表されていました。例えば、シリアルコードに対し、並列コードで 200% の速度向上が達成されるとします。この場合、実行時間はシリアル版の半分でしょうか。あるいは 3 分の 1 の時間でしょうか。105% の速度向上の場合はどうでしょう。シリアル実行とほぼ同じ時間で実行されるでしょうか。または 2 倍の速度で実行されるでしょうか。基準値のシリアル時間は 0% あるいは 100% の速度向上でしょうか。このように、% で表すと混乱を招きやすいですが、「並列アプリケーションで 2 倍の速度向上が達成された」と表現すると、従来の半分の時間 (例: シリアルコードが 1 回実行する時間で並列版では 2 回実行できる) で実行できた、ということは明らかです。
非常に稀なケースですが、アプリケーションの速度向上がコア数を上回ることがあります。この現象を「超線形 (スーパーリニア) 速度向上」と言います。超線形速度向上の典型的な要因は、固定サイズのデータセットの分解によって、1 つのコアに対するデータセットが小さくなり、ローカルキャッシュに収まることが挙げられます。シリアルで実行すると、データセットはキャッシュに収まりきらず、プロセッサーはキャッシュラインがフェッチされる間、待機を余儀なくされます。データが大きく、前に使用したキャッシュラインが追い出されてしまった場合は、そのキャッシュラインを再利用する場合には、プロセッサーはもう一度待機しなければなりません。データがコア上のキャッシュにすべて収まるような規模に分割された場合、再利用するキャッシュラインを待たずに済みます。このように、複数のコアを使用すると、シングルコアで実行されるシリアルコードに関連したオーバーヘッドを軽減できます。データセットが小さすぎる (典型的なデータセットよりも小さい) と性能が向上したと錯覚する恐れがありますので注意してください。
利用ガイド
アムダールの法則の数式における矛盾については、さまざまな並列実行モデルによって合理的な仮定が打ち出されています。
アムダールの法則は、今もなおその簡潔さと、理論上の速度向上の限界 (達成あるいは上回ることのできる可能性が低い) であるとの認識によって、シリアル・アプリケーションで期待できる速度向上の貴重な指標と言えるでしょう。