概要
メモリー・サブシステムのコンポーネントは、アプリケーションのパフォーマンスを大きく左右します。キャッシュ容量やメモリー帯域幅などの限られたリソースを共有するスレッドやプロセス数が増えるにつれて、マルチスレッド・アプリケーションのスケーラビリティーは制約されます。メモリーを多用するマルチスレッド・アプリケーションでは、スレッド数の増加に伴いメモリー帯域幅の飽和が生じます。飽和問題が発生すると、期待通りのスケーラビリティーが得られず、パフォーマンスが低下します。ここでは、マルチスレッド・アプリケーションでメモリー帯域幅の飽和を検出するための手法を紹介します。
この記事は、「マルチスレッド・アプリケーションの開発のためのインテル・ガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
現在のプロセッサーは、コア数やキャッシュ容量が増強されており、メモリー・サブシステムのコンポーネントよりも高速になっています。ダイあたりのコア数は増加の一途にあり、キャッシュ容量とメモリー帯域幅への負荷が増しています。そのため、各コアで利用可能なキャッシュとメモリー帯域幅を最大限に活用することが、フォワード・スケーリングなアプリケーションを開発する上で不可欠です。システムがメインメモリーからコアへデータを迅速に移動しないと、コアはアイドル状態のままデータを待機することになります。計算中のアイドルコアはリソースの浪費であり、実行時間全体が長くなるだけでなく、マルチコアのメリットを損なうことにもなります。
インテル® マイクロアーキテクチャー Nehalem を採用しているインテル® プロセッサーでは、コアで利用可能なメモリー帯域幅を拡大し帯域飽和を緩和するために、従来のフロントサイド・バス (FSB) から NUMA (Non-Uniform Memory Access) に移行しています。図 1 は、FSB から NUMA への移行を示しています。
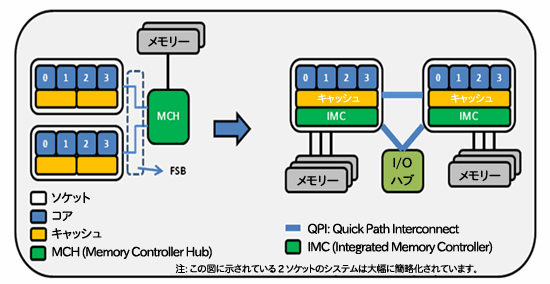
図 1. FSB から NUMA への移行
並列アプリケーションで期待通りのスケーラビリティーが得られない場合は、帯域飽和の疑いがあります。利用可能なメモリー帯域幅を使い果たしてしまったアプリケーションでは、スレッド数やコア数を増やしても、それに見合ったスケーラビリティーが得られません。ただし、マルチスレッド・アプリケーションでスケーラビリティーが得られない原因はこのほかにも多くあり、パフォーマンスの妨げとなる要因の一例として、スレッド化によるオーバーヘッド、ロード・インバランス、不適切な粒度などが挙げられます。インテル® スレッド・プロファイラーは、このようなパフォーマンス問題をアプリケーション・レベルで識別するように設計されています。
以下に STREAM バージョン 5.6 を使用して、さまざまなスレッド数でベンチマーク・テストを行った結果を示します (ここでは、Triad の結果のみを表示しています)。
| |
関数 |
速度 (MB/秒) |
平均時間 |
最小時間 |
最大時間 |
| 1 スレッド |
Triad: |
7821.9511 |
0.0094 |
0.0092 |
0.0129 |
| 2 スレッド |
Triad: |
8072.6533 |
0.0090 |
0.0089 |
0.0093 |
| 4 スレッド |
Triad: |
7779.6354 |
0.0096 |
0.0093 |
0.0325 |
このプラットフォーム (シングルソケットのインテル® Core™2 Quad プロセッサー・ベースのシステム) では、スレッド数を増やしても STREAM の結果が伸びていません。2 スレッドでは Triad の結果がわずかに速くなっていますが、4 スレッドでは 1 スレッドの場合よりも遅くなっています。
図 2 は、インテル®スレッド・プロファイラーでこのベンチマークを解析した結果です。タイムライン・ビューでは、すべてのスレッドに負荷がバランスよく配分されており、同期化のオーバーヘッドも存在しないことがわかります。インテル®スレッド・プロファイラーは、スレッド化のパフォーマンス問題をアプリケーション・レベルで識別できるパワフルなツールですが、マルチスレッド・アプリケーションのメモリー帯域飽和は検出できません。
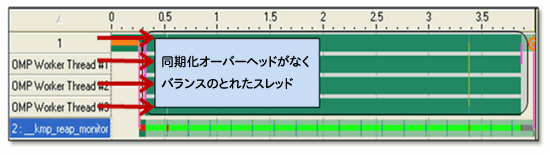
図 2. STREAM ベンチマークで 4 つの OpenMP* スレッドを使用した結果を示すインテル®スレッド・プロファイラーのタイムライン・ビュー
アドバイス
インテル® VTune™ パフォーマンス・アナライザーおよびパフォーマンス・チューニング・ユーティリティー (PTU) とイベント・ベース・サンプリング (EBS) を組み合わせることで、アプリケーションの帯域幅の使用量を測定し、システムで達成可能な (理論上の) 帯域幅と比較することができます。イベント・ベース・サンプリングは、プロセッサーでサポートされているパフォーマンス・モニタリング・ユニット (PMU) を使用します。
EBS を使用することで、VTune™ アナライザーと PTU で特定のアプリケーションのメモリー帯域幅の使用量を予測することができます。インテル® Core™ マイクロアーキテクチャーでは、CPU_CLK_UNHALTED.CORE パフォーマンス・イベントと BUS_TRANS_MEM.ALL_AGENTS パフォーマンス・イベントを使用して、メモリーの帯域幅を予測します。
- CPU_CLK_UNHALTED.CORE イベントは、コアが停止状態ではないサイクル数をカウントします。コアは、HLT 命令の実行時に停止状態になります。
- BUS_TRANS_MEM.ALL_AGENTS イベントは、バス上のエージェントによって開始されたアクティビティーをカウントします。プロセッサーがそれぞれ異なるバスに接続されているシステムでは、それぞれのプロセッサーが接続されているバスのアクティビティーのみカウントされます。
インテル®Core™ マイクロアーキテクチャー・ベースのシステムでは、次の数式を使用してメモリー帯域幅を予測することができます。
(64 * BUS_TRANS_MEM.ALL_AGENTS * CPU 周波数) / CPU_CLK_UNHALTED.CORE

図 3. STREAM で 4 つのスレッドを使用した場合の VTune™ アナライザーの EBS 分析
図 3 は、STREAM ベンチマークで 4 つのスレッドを使用した場合の EBS 結果を表したものです。上記の数式から、STREAM のメモリー帯域幅の使用量は 7.6GB/秒と予測されます。
メモリー帯域幅 = (64 * 1,419,200,000 * 2.9GHz) / 35,576,000,000 = 7.6GB/秒
STREAM ベンチマーク・テストの Triad 結果は 7.7GB/秒なので、VTune™ アナライザーの結果を基に計算した値とほぼ同じであることがわかります。ここでは、STREAM ベンチマークで EBS を使用して測定したメモリー帯域幅から、特定のシステムで達成可能なメモリー帯域幅を予測する方法について説明しました。
利用可能なコアを活用するためにスレッドを追加してもアプリケーションがスケールせず、インテル®スレッド・プロファイラーで前述したようなアプリケーション・レベルのスレッディング問題が検出されない場合は、次の 3 つのステップに従って、特定のアプリケーションで利用可能なメモリー帯域幅の飽和が発生しているかどうかを判断できます。
- STREAM または同様のベンチマークを実行して、ターゲットシステムのメモリー帯域幅を測定します。
- VTune™ アナライザーや PTU でターゲット・アプリケーションを実行して、EBS で適切なパフォーマンス・カウンターのデータを収集します。インテル®Core™ マイクロアーキテクチャーでは、前述のように、CPU_CLK_UNHALTED.CORE イベントと BUS_TRANS_MEM.ALL_AGENTS イベントのデータを収集します。
- VTune™ アナライザーで収集されたデータを基に計算されたメモリー帯域幅と、ステップ 1 で測定されたメモリー帯域幅を比較します。帯域幅の飽和が発生している場合、このアプリケーションではコア数を増やしてもそれに見合ったスケーラビリティーを引き出すことはできません。
一般に、メモリーにバインドされたアプリケーション (メモリーへのアクセス速度によってパフォーマンスが制限されるアプリケーション) では、スレッド数を増やしてもその効果が得られません。
利用ガイド
インテル® Core™ i7 プロセッサーおよびインテル®Xeon® プロセッサー 5500 番台は、CPU にコア以外の部分である「アンコア」を内蔵しています。例えば、インテル®Core™ i7 プロセッサーでは、4 つのコアが L3 キャッシュとメモリー・インターフェイスを共有しています。この L3 キャッシュとメモリー・インターフェイスがアンコア部分にあたります (図 4 を参照)。
VTune™ アナライザーと PTU は、CPU のアンコア部分で発生したイベントのサンプリングをサポートしていません。そのため、両者とも、帯域幅の測定に関連するパフォーマンス・イベントのうち、アンコア部分で発生したものは EBS でサンプリングされません。このような場合、タイム・ベース・サンプリングを使用します。タイム・ベース・サンプリングでは、指定された期間内のシステム全体の帯域幅が測定されます。特定の関数、プロセス、モジュールの帯域幅の使用量は表示されません。
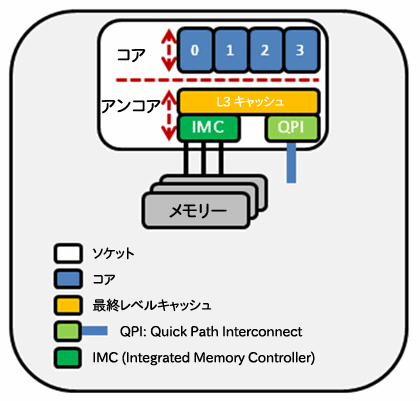
図 4. 4 コア の Nehalem プロセッサーの略図
前述の数式は、すべてのインテル®Core™ マイクロアーキテクチャー・ベースのシステムでアプリケーション、モジュール、関数のメモリー帯域幅の使用量を計算する際に利用できます (ただし、アンコア部分を内臓するインテル®Core™ マイクロアーキテクチャー・ベースのインテル®Xeon®プロセッサー MP は除く)。Nehalem アーキテクチャー・ベースのシステムでは、次の数式を使用してメモリーの帯域幅を計算できます。
メモリー帯域幅 = 1.0e-9 * (UNC_IMC_NORMAL_READS.ANY+UNC_IMC_WRITES.FULL.ANY)*64 / (ウォールクロック時間 (秒))