インテル® Xeon Phi™ 製品ファミリーでのインテル® MPI ライブラリーの使用ガイド
はじめに
メッセージ・パッシング・インターフェイス (MPI) 標準は、分散メモリー並列プログラミングで使用されるルーチン群で構成されるメッセージ・パッシング・ライブラリーです。このガイドは、インテル® Xeon Phi™ プロセッサー/コプロセッサーを含む開発プラットフォーム上で、インテル® MPI ライブラリーを使用してコードを記述し、MPI アプリケーションを実行するのを支援することを目的としています。インテル® MPI ライブラリーは、MPI-3.1 仕様を実装するマルチファブリック・メッセージ・パッシング・ライブラリーです (表 1)。
ここでは、インテル® MPI ライブラリー 2017 および 2018 Beta for Linux* を使用します。
表 1. インテル® MPI ライブラリーの概要
プロセッサー
インテル® プロセッサー、インテル® コプロセッサー、互換プロセッサー
言語
C/C++、Fortran 開発をネイティブサポート
開発環境
Microsoft* Visual Studio* (Windows*)、Eclipse*/CDT (Linux*)
オペレーティング・システム
Linux*、Windows*
インターコネクト・ファブリック
共有メモリー
DAPL を介した RDMA 対応のネットワーク・ファブリック (例: InfiniBand*, Myrinet*)
インテル® Omni-Path アーキテクチャー
ソケット (例: イーサネット、ギガビット・イーサネット経由の TCP/IP) ほか
このガイドは、インテル® Xeon Phi™ プロセッサー x200 製品ファミリー、インテル® Xeon Phi™ コプロセッサー x200 製品ファミリー、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー上で、MPI アプリケーションをビルドして、ネイティブまたはシンメトリックに実行する手順を要約します。最初に、インテル® Xeon Phi™ プロセッサー x200 製品ファミリー、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー、MPI プログラミング・モデルについて説明します。
インテル® MPI ライブラリーは単体での販売に加え、インテル® Parallel Studio XE Cluster Edition にも同梱されています。
インテル® Xeon Phi™ プロセッサー・アーキテクチャー
- インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512)
- 最大 72 コア、2D メッシュ・アーキテクチャー
- コアごとに 2 つの 512 ビット幅のベクトル・プロセシング・ユニット (VPU) と 4 つのハードウェア・スレッド
- コアのペア (タイル) ごとに 1MB の共有 L2 キャッシュ
- 8 または 16GB のオンパッケージ高帯域幅メモリー (MCDRAM)
- 6 チャネル DDR4、最大 384GB (プロセッサー・バージョンのみ)
- 第 3 世代 PCIe* によりホストに接続 (コプロセッサー・バージョンのみ)
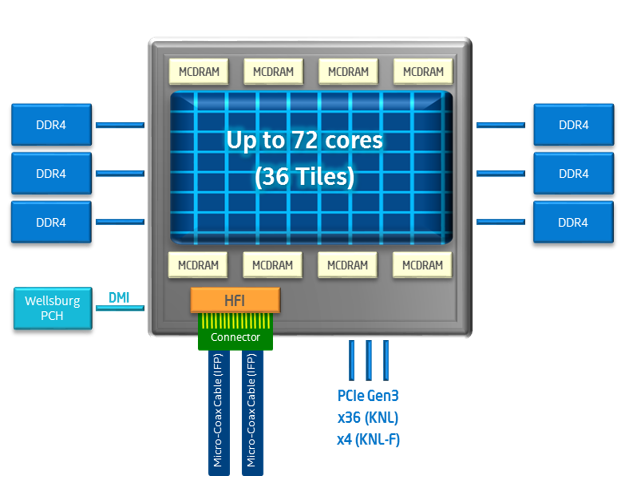
図 1. インテル® Xeon Phi™ プロセッサー x200 製品ファミリーのアーキテクチャー
インテル® Xeon Phi™ プロセッサー x200 製品ファミリーの機能を有効にするには、こちらからインテル® Xeon Phi™ Processor Software をダウンロードしてインストールする必要があります。
インテル® Xeon Phi™ コプロセッサー x200 製品ファミリーは、第 3 世代 PCIe* インターフェイスを介してインテル® Xeon® プロセッサー・ベースのホストに接続されます。コプロセッサーは、標準の Linux* OS 上で動作します。(ホストがワークロードをオフロード可能な) ホストの拡張として使用することも、個別の計算ノードとして使用することもできます。インテル® Xeon Phi™ コプロセッサー x200 製品ファミリーをサービスとしてロードするには、最初にこちらからインテル® メニーコア・プラットフォーム・ソフトウェア・スタック (インテル® MPSS) 4.x をダウンロードして、ホストにインストールします。インテル® MPSS は、デバイスドライバー、コプロセッサー管理ユーティリティー、コプロセッサー向け Linux* OS を含む、ソフトウェアのコレクションです。
インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーのアーキテクチャー: インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーは、インテル® Xeon Phi™ 製品ファミリーの最初の世代です。コプロセッサーは、第 2 世代 PCIe* インターフェイスを介してインテル® Xeon® プロセッサー・ベースのホストに接続されます。ホストとは別の OS 上で動作し、次のアーキテクチャーを持っています (図 2)。
- インテル® イニシャル・メニー・コア命令 (インテル® IMCI)
- 最大 61 コア、高帯域幅の双方向リング・インターコネクト・アーキテクチャー
- コアごとに 1 つの 512 ビット幅のベクトル・プロセシング・ユニット (VPU) と 4 つのハードウェア・スレッド
- コアごとに 512KB のプライベート L2 キャッシュ
- 16GB GDDR5 メモリー
- 第 2 世代 PCIe* によりホストに接続
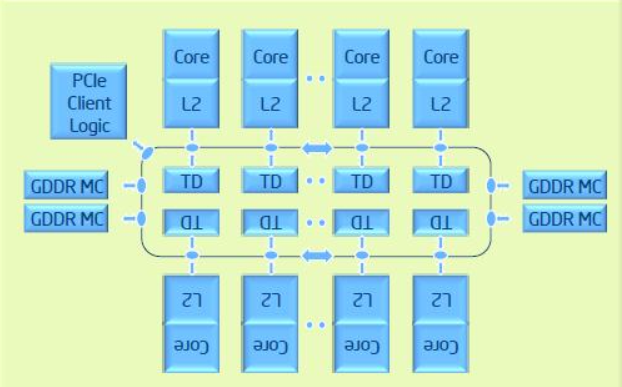
図 2. インテル® Xeon Phi™ プロセッサー x100 製品ファミリーのアーキテクチャー
インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーをサービスとしてロードするには、こちらからインテル® MPSS 3.x をダウンロードして、ホストにインストールします。
MPI プログラミング・モデル
インテル® MPI ライブラリーは、次の MPI プログラミング・モデルをサポートします (図 3)。
- ホストのみ (インテル® Xeon® プロセッサーまたはインテル® Xeon Phi™ プロセッサー): このモードでは、すべての MPI ランクがホスト CPU (またはインテル® Xeon Phi™ プロセッサー) 上に存在し、そこでワークロードを実行します。
- オフロード: このモードでは、インテル® Xeon® プロセッサー・ベースのホスト上にのみ MPI ランクが存在します。MPI ランクは、インテル® C/C++ コンパイラーまたはインテル® Fortran コンパイラーのオフロード機能によってワークロードをコプロセッサーへオフロードします。通常、ホストごとに 1 MPI ランクが使用され、MPI ランクはコプロセッサーへのオフロードを実行します。
- コプロセッサーのみ: このネイティブモードでは、コプロセッサー上にのみ MPI ランクが存在します。アプリケーションは、コプロセッサーから起動します。
- シンメトリック: このモードでは、ホストとコプロセッサーの両方に MPI ランクが存在します。アプリケーションは、ホストから起動します。
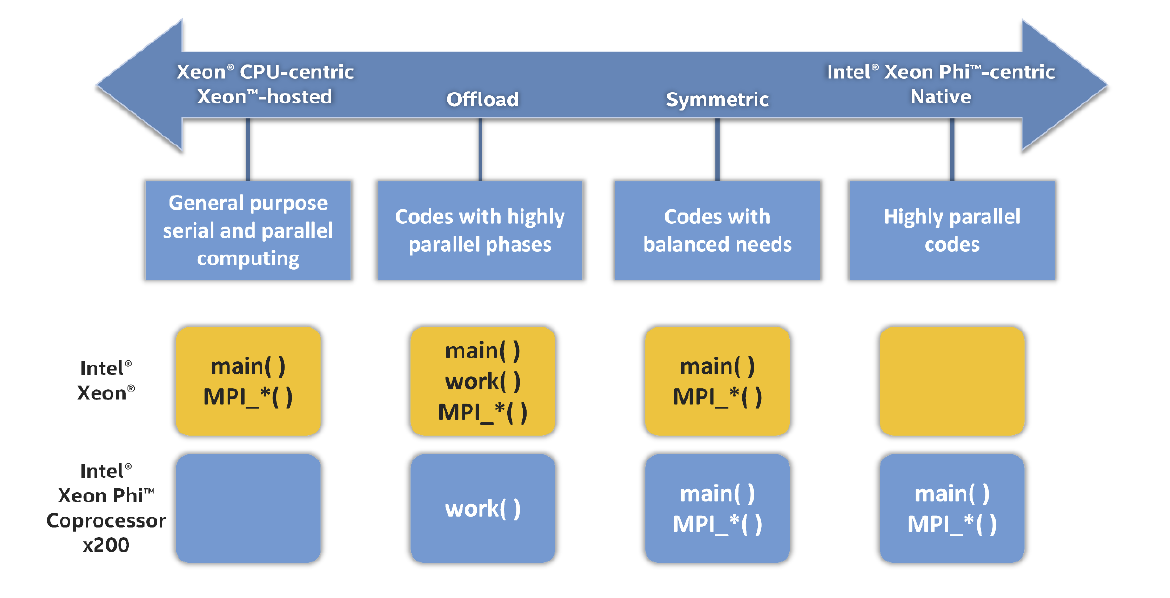
図 3. MPI プログラミング・モデル
インテル® MPI ライブラリーの使用
このセクションでは、次のシステム構成で MPI アプリケーションをビルドして実行する方法を示します: インテル® Xeon Phi™ プロセッサー x200 製品ファミリー、1 基以上のインテル® Xeon Phi™ コプロセッサー x200 製品ファミリーが搭載されたシステム、および 1 基以上のインテル® Xeon Phi™ コプロセッサー x100 製品ファミリーが搭載されたシステム (図 4)。
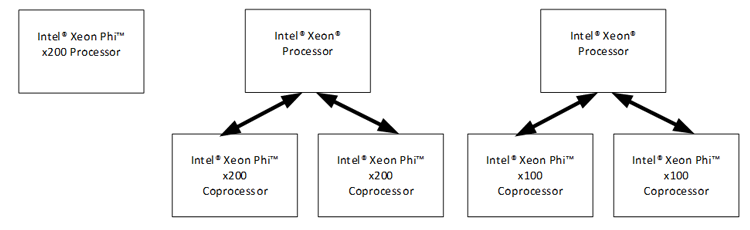
図 4. 異なるシステム構成: (a) スタンドアロンのインテル® Xeon Phi™ プロセッサー x200 製品ファミリー、(b) インテル® Xeon® プロセッサー・ベースのシステムに装着されたインテル® Xeon Phi™ コプロセッサー x200 製品ファミリー、および (c) インテル® Xeon® プロセッサー・ベースのシステムに装着されたインテル® Xeon Phi™ コプロセッサー x100 製品ファミリー
インテル® MPI ライブラリーのインストール
インテル® MPI ライブラリーは、スタンドアロン製品またはインテル® Parallel Studio XE Cluster Edition の一部として利用できます。
デフォルトでは、インテル® MPI ライブラリーは、ホストシステムまたはインテル® Xeon Phi™ プロセッサー・ベースのシステム上の /opt/intel/impi にインストールされます。最初に、適切な手順に従って、インテル® C/C++ コンパイラーおよびインテル® Fortran コンパイラーをインストールします。
インテル® Parallel Studio XE の購入または 30 日間評価版は こちらのページからお申し込みいただけます。ここで紹介する手順は、インテル® MPI ライブラリーの tar ファイル (l_mpi_<version>.<package_num>.tgz) をお持ちであることを前提にしています。インテル® ソフトウェア開発製品レジストレーション・センターにログインして、最新バージョンを確認してください。以下の手順は、現在および以降のリリースで有効です。
root ユーザーで tar ファイル l_mpi_<version>.<package_num>.tgz を展開します。
# tar -xzvf l_mpi_<version>.<package_num>.tgz
# cd l_mpi_<version>.<package_num>
ホスト上でインストール・スクリプトを実行して、手順に従います。root 権限でインテル® MPI ライブラリーをインストールすると、デフォルトのインストール・ディレクトリー /opt/intel/impi/<version>.<package_num> にインストールされます。
# ./install.sh
MPI プログラムのコンパイル
ホストまたはインテル® Xeon Phi™ プロセッサー x200 製品ファミリー上で MPI プログラムをコンパイルするには、次の操作を行います。
MPI プログラムをコンパイルする前に、コンパイラーとインテル® MPI ライブラリー向けに環境を設定する必要があります。
$ source /opt/intel/compilers_and_libraries_<version>/linux/bin/compilervars.sh intel64
$ source /opt/intel/impi/<version>.<package_num>/bin64/mpivars.sh
別の方法として、インテル® Parallel Studio XE Cluster Edition をインストールした場合は、設定スクリプトを source して設定することもできます。
$ source /opt/intel/parallel_studio_xe_<version>/psxevars.sh intel64
適切なコンパイラー・コマンドで MPI プログラムをコンパイルおよびリンクします。
コンパイルしてインテル® MPI ライブラリーとリンクするには、表 2 の適切なコマンドを使用します。
表 2. MPI コンパイル用の Linux* コマンド| プログラミング言語 | MPI コンパイル用の Linux* コマンド |
|---|---|
| C | mpiicc |
| C++ | mpiicpc |
| Fortran 77/95 | mpiifort |
例えば、ホスト向けに C プログラムをコンパイルするには、mpiicc ラッパーを使用します。
$ mpiicc ./myprogram.c -o myprogram
インテル® Xeon Phi™ プロセッサー x200 製品ファミリーおよびインテル® Xeon Phi™ コプロセッサー x200 製品ファミリー向けにコンパイルするには、このアーキテクチャーで利用可能なインテル® AVX-512 命令セット・アーキテクチャー (ISA) の利点が得られるように、-xMIC-AVX512 オプションを指定します。例えば、次のコマンドは、インテル® AVX-512 ISA を利用して、インテル® Xeon Phi™ プロセッサー/コプロセッサー x200 製品ファミリー向けに C プログラムをコンパイルします。
$ mpiicc -xMIC-AVX512 ./myprogram.c -o myprogram.knl
インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー向けにコンパイルするには、-mmic オプションを指定します。次のコマンドは、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー向けに C プログラムをコンパイルします。
$ mpiicc -mmic ./myprogram.c -o myprogram.knc
インテル® Xeon Phi™ プロセッサー x200 製品ファミリー上での MPI プログラムの実行
インテル® Xeon Phi™ プロセッサー x200 製品ファミリー上でアプリケーションを実行するには、mpirun スクリプトを使用します。
$ mpirun -n <# of processes> ./myprogram.knl
n は、プロセッサー上で起動する MPI プロセスの数です。
インテル® Xeon Phi™ コプロセッサー x200 製品ファミリーおよびインテル® Xeon Phi™ コプロセッサー x100 製品ファミリー上での MPI プログラムの実行
コプロセッサー上でアプリケーションを実行するには、次の操作が必要です。
- インテル® MPSS サービスが停止している場合は、開始します。
$ sudo systemctl start mpss
- MPI 実行ファイルをホストからコプロセッサーへ転送します。例えば、scp ユーティリティーを使用して、(インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー向けの) 実行ファイルを mic0 という名前のコプロセッサーへ転送します。
$ scp myprogram.knl mic0:~/myprogram.knc
- MPI ライブラリーとコンパイラー・ライブラリーをコプロセッサーへ転送します。インテル® Xeon Phi™ コプロセッサー上で MPI アプリケーションを初めて実行する前に、適切な MPI ライブラリーとコンパイラー・ライブラリーを、システム上の各コプロセッサーの次のディレクトリーへコピーする必要があります: インテル® Xeon Phi™ コプロセッサー x200 製品ファミリーの場合は /lib64 ディレクトリー以下、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーの場合は /mic ディレクトリー以下。
例えば、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーの最初のコプロセッサー mic0 へコピーする場合、mic0 は IP アドレス 172.31.1.1 を利用してアクセスすることができます。すべてのコプロセッサーには一意の IP アドレスが割り当てられるため、個別にアクセスできます。最初のコプロセッサーは、mic0 として、または IP アドレスを利用して参照できます。
# sudo scp /opt/intel/impi/2017.3.196/mic/bin/* mic0:/bin/
# sudo scp /opt/intel/impi/2017.3.196/mic/lib/* mic0:/lib64/
# sudo scp /opt/intel/composer_xe_2017.3.196/compiler/lib/mic/* mic0:/lib64/
MPI ライブラリーとコンパイラー・ライブラリーを手動でコピーする代わりに、次のスクリプトを実行して、2 つのコプロセッサー mic0 と mic1 へ転送することもできます。サンプルコードはこちら。
別のアプローチは、ホストからコプロセッサーのファイルシステムを NFS マウントして、そこからコプロセッサーが MPI ライブラリーにアクセスできるようにします。NFS マウントを使用する利点の 1 つは、コプロセッサー上の RAM 領域を節約できることです。NFS マウントのセットアップ方法については、このガイドの最初の例を参照してください。
コプロセッサー上でアプリケーションをネイティブ実行するには、コプロセッサーにログインして、mpirun スクリプトを実行します。
$ ssh mic0
$ mpirun -n <# of processes> ./myprogram.knc
n は、コプロセッサー上で起動する MPI プロセスの数です。
最後に、ホストから (シンメトリックに) MPI プログラムを実行するには、追加の操作が必要です。
インテル® MPI ライブラリーの環境変数 I_MPI_MIC を設定して、インテル® MPI ライブラリーがコプロセッサーを認識できるようにします。
$ export I_MPI_MIC=enable
ホストのファイアウォールを無効にします。
$ systemctl status firewalld
$ sudo systemctl stop firewalld
複数のカードを使用する場合は、インテル® MPSS をピアツーピアとして設定し、各カードが互いに ping できるようにします。
$ sudo /sbin/sysctl -w net.ipv4.ip_forward=1
デバッグ情報を取得するには、アプリケーションの実行時に -verbose と -genv I_MPI_DEBUG=n オプションを指定します。 以降のセクションでは、C++ で記述されたサンプル MPI プログラムを紹介します。1 つ目の例は、インテル® Xeon Phi™ プロセッサー x200 製品ファミリーおよびインテル® Xeon Phi™ コプロセッサー x200 製品ファミリー向けにプログラムをコンパイルして実行する方法を示します。2 つ目の例は、インテル® Xeon Phi™ コプロセッサー x100 製品ファミリー向けにプログラムをコンパイルして実行する方法を示します。
例 1
この例は、2 基のインテル® Xeon Phi™ コプロセッサー x200 製品ファミリーが装着されたホスト上でインテル® MPI ライブラリーを使用するアプリケーションをビルドし、シンメトリック・モードで実行する方法を示します。インテル® Xeon Phi™ コプロセッサー x200 製品ファミリーを有効にするには、ホストにインテル® MPSS 4.x がインストールされている必要があります。
この例では、次の積分式を用いてPi (π) を計算します。
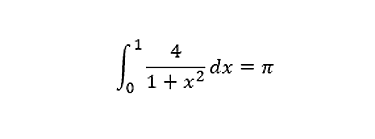
プログラムのコードは付録 A を参照してください。ワークロードは、MPI ランク間で分配されます。各ランクは OpenMP* スレッドのチームをスポーンし、ベクトル化の利点が得られるように、各スレッドがワークロードのチャンクを処理します。最初に、インテル® Xeon® プロセッサー・ベースのホスト上でこのアプリケーションを実行します。このプログラムは OpenMP* (英語) を使用するため、OpenMP* ライブラリーとともにプログラムをコンパイルする必要があります。ここでは、インテル® Parallel Studio XE 2018 を使用します。
環境変数を設定し、ホスト向けにアプリケーションをコンパイルして、ベクトル化と OpenMP* に関する最適化レポートを生成します。
$ source /opt/intel/compilers_and_libraries_2018/linux/bin/compilervars.sh intel64
$ mpiicc mpitest.c -qopenmp -O3 -qopt-report=5 -qopt-report-phase:vec,openmp -o mpitest
ホスト上で 2 つのランクを実行するコマンドは、こちらのサンプルコードをご覧ください。
次に、インテル® Xeon Phi™ コプロセッサー x200 製品ファミリー向けにアプリケーションをコンパイルして、コプロセッサー mic0 と mic1 に実行ファイルを転送します (コプロセッサー側でパスワードなしの設定が完了していると仮定します)。
$ mpiicc mpitest.c -qopenmp -O3 -qopt-report=5 -qopt-report-phase:vec,openmp -xMIC-AVX512 -o mpitest.knl
$ scp mpitest.knl mic0:~/.
$ scp mpitest.knl mic1:~/.
コプロセッサー向けに MPI を有効にし、ホストでファイアウォールを無効にします。
$ export I_MPI_MIC=enable
$ sudo systemctl stop firewalld
この例は、ネットワーク・ファイル・システム (NFS) を使用して共有ディレクトリーをマウントする方法も示します。root でインテル® C++ コンパイラーとインテル® MPI ライブラリーがインストールされている /opt/intel ディレクトリーをマウントします。最初に、ホスト上の /etc/exports 設定ファイルに記述子を追加して、コプロセッサーと /opt/intel ディレクトリーを読み取り専用 (ro) 権限で共有します。ここでは、コプロセッサーの IP アドレスは、172.31.1.1 と 172.31.2.1 です。
[host~]# cat /etc/exports
/opt/intel 172.31.1.1(ro,async,no_root_squash)
/opt/intel 172.31.2.1(ro,async,no_root_squash)
NFS エクスポート・テーブルを更新して、ホストで NFS サーバーを再起動します。
[host~]# exportfs -a
[host~]# service nfs restart
次に、コプロセッサーにログインして、マウントポイント /opt/intel を作成します。
[host~]# ssh mic0
mic0:~# mkdir /opt
mic0:~# mkdir /opt/intel
mic0 の /etc/fstab ファイルに記述子 "172.31.2.254:/opt/intel /opt/intel nfs defaults 1" を追加します。サンプルコードはこちら。
最後に、コプロセッサー上で共有ディレクトリー /opt/intel をマウントします。
mic0:~# mount -a
同様に、mic1 に対してこの操作を行います。/etc/fstab ファイルに記述子 "172.31.2.254:/opt/intel /opt/intel nfs defaults 1 1" を追加します。
mic0 と mic1 が /etc/hosts ファイルに含まれていることを確認します。サンプルコードはこちら。
デフォルトでは、利用可能な最大数のハードウェア・スレッドが各計算ノードで使用されます。このデフォルトの動作を変更するには、計算ノードでローカル環境変数 -env を追加します。例えば、mic0 の OpenMP* スレッド数を 68 に設定し、スレッド・アフィニティーを compact に設定するには、こちらのサンプルコードにあるコマンドを実行します。
簡単に起動できるように、すべてのマシン名を含むファイルを定義し、すべての実行ファイルに名前を付けて、事前定義したディレクトリーに移動します。例えば、すべての実行ファイル名を mpitest とし、ユーザーのホーム・ディレクトリーに配置します。 サンプルコードはこちら。
例 2
例 2 は、2 基のインテル® Xeon Phi™ コプロセッサー x100 製品ファミリーが装着されたホスト上でインテル® MPI ライブラリーを使用するアプリケーションをビルドし、シンメトリック・モードで実行する方法を示します。インテル® Xeon Phi™ コプロセッサー x100 製品ファミリーを有効にするには、ホストにインテル® MPSS 3.x がインストールされている必要があります。
このサンプルプログラムは、モンテカルロ法を使用して Pi (π) の計算を推定します。原点を中心とし、立方体に外接する球について考えます。球の半径は r、立方体の辺の長さは 2r とします。球体と立方体の容積は次の式で表現できます。
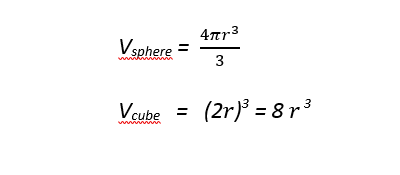
座標系の最初の八分円には球体と立方体両方の容積の 1/8 が含まれます。八分円の容積は次の式で表現できます。
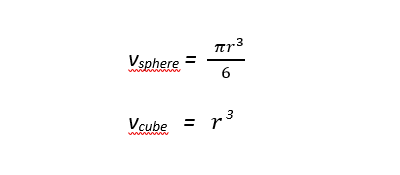
八分円内の立方体で Nc ポイントを一様かつランダムに生成する場合、次の比率に応じて、約 Ns ポイントは球の体積内になると予測します。
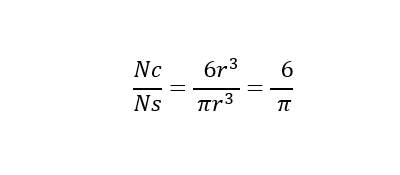
そのため、推定される Pi (π) は次のように計算されます。
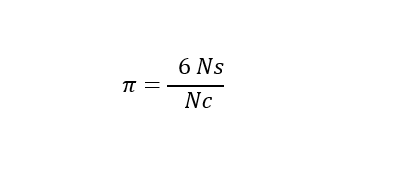
Nc は最初の八分円内の立方体の部分で生成されたポイントの数、Ns は最初の八分円内の球の部分で見つかったポイントの合計数です。
実装では、ランク 0 (プロセス) がほかの n ランクにワークを分配します。各ランクにはワークの一部が割り当てられ、合計 (sum) が Pi を求めるのに使用されます。ランク 0 は、x 軸を n 等分します。各ランクは、割り当てられたセグメントで (Nc /n) ポイントを生成し、球の最初の八分円のポイント数を計算します (図 5)。
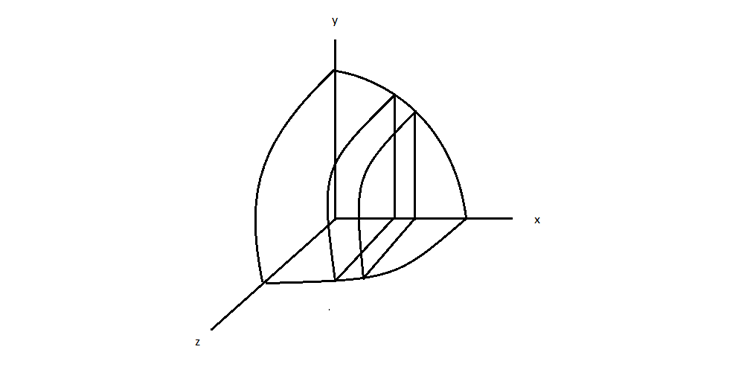
図 5. 各 MPI ランクで最初の八分円の異なる部分を処理
擬似コードはこちら。
インテル® C++ コンパイラー 2017 を使用して、アプリケーション montecarlo.knc をインテル® Xeon Phi™ コプロセッサー x100 製品ファミリー向けにビルドします。プログラムのコードは付録 B を参照してください。この例は、単純にインテル® Xeon Phi™ コプロセッサー x100 製品ファミリー上でコードを実行する方法を示すものです。サンプルコードを最適化することで、さらにパフォーマンスを向上できます。
$ source /opt/intel/compilers_and_libraries_2017/linux/bin/compilervars.sh intel64
$ mpiicc -mmic montecarlo.c -o montecarlo.knc
ホスト用アプリケーションをビルドします。
$ mpiicc montecarlo.c -o montecarlo
scp ユーティリティーを使用して、アプリケーション montecarlo.knc をコプロセッサー上の /tmp ディレクトリーに転送します。この例では、2 基のインテル® Xeon Phi™ コプロセッサー x100 製品ファミリーへコピーします。
$ scp ./montecarlo.knc mic0:/tmp/montecarlo.knc
montecarlo.knc 100% 17KB 16.9KB/s 00:00 $ scp ./montecarlo.knc mic1:/tmp/montecarlo.knc
montecarlo.knc 100% 17KB 16.9KB/s 00:00
図 5 のスクリプトを使用して、MPI ライブラリーとコンパイラー・ライブラリーをコプロセッサーへ転送します。ホストとインテル® Xeon Phi™ コプロセッサー x100 製品ファミリー間の MPI 通信を有効にします。
$ export I_MPI_MIC=enable
mpirun スクリプトを実行してアプリケーションを開始します。-n オプションは MPI プロセスの数を指定し、-host オプションはマシン名を指定します。
$ mpirun -n <# of processes> -host <hostname> <application>
":" で区切って複数のホストでアプリケーションを実行できます。最初の MPI ランク (ランク 0) は常にコマンドの最初に指定します。
$ mpirun -n <# of processes> -host <hostname1> <application> : -n <# of processes> -host <hostname2> <application>
hostname1 でランク 0 が、hostname2 でほかのランクが開始します。
次に、ホストでアプリケーションを実行します。以下の mpirun コマンドは、ホストで 2 ランク、コプロセッサー mic0 で 3 ランク、コプロセッサー mic1 で 5 ランクを使用してアプリケーションを開始します。サンプルコードはこちら。
これをシンメトリック・モードで簡単に行うには、I_MPI_MIC_POSTFIX 環境変数を設定して、-machinefile オプションとともに mpirun コマンドを実行します。その場合、すべての実行ファイルがホスト、mic0、mic1 上で同じ場所にあることを確認してください。
I_MPI_MIC_POSTFIX 環境変数は、カードで実行する場合 (カード上の実行ファイルが montecarlo.knc であるため) ライブラリーに .mic ポストフィックスを追加するように指示するだけで済みます。
$ export I_MPI_MIC_POSTFIX=.knc
ホストファイルで (<host>:<#_ranks> 形式を使用して) ランクのマッピングを設定します。
$ cat hosts_file
localhost:2
mic0:3
mic1:5
実行ファイルを実行します。
$ mpirun -machinefile hosts_file /tmp/montecarlo
この構文は、ランク数を変更したり、カードを追加する場合、hosts_file を編集するだけで済むため便利です。
別の方法として、コプロセッサーに ssh 接続して、コプロセッサーからアプリケーションを起動することもできます。
S ssh mic0
S mpirun -n 3 /tmp/montecarlo.knc
Hello world: rank 0 of 3 running on knc0-mic0
Hello world: rank 1 of 3 running on knc0-mic0
Hello world: rank 2 of 3 running on knc0-mic0
Elapsed time from rank 0: 650.47 (sec)
Elapsed time from rank 1: 650.61 (sec)
Elapsed time from rank 2: 648.01 (sec)
Out of 4294967295 points, there are 2248795855 points inside the sphere => pi= 3.141531467438
まとめ
ここでは、簡単な MPI アプリケーションをコンパイルして、シンメトリック・モードで実行する方法を紹介しました。
ヘテロジニアス・コンピューティング・システムでは、各計算ユニットのパフォーマンスが異なるため、このシステム動作がロード・インバランスの原因となります。 インテル® Trace Analyzer & Collectorは、ヘテロジニアス・システムで実行する複雑な MPI プログラムの動作を解析して理解するのに役立ちます。 インテル® Trace Analyzer & Collector を使用することで、ボトルネックを素早く見つけ、ロードバランスを評価し、パフォーマンスを解析して、通信 hotspot を特定することができます。 複数の計算ユニットで構成されるクラスター上で実行する MPI プログラムをデバッグし、パフォーマンスを向上するには、この強力なツールが不可欠です。
インテル® Trace Analyzer & Collectoror の詳細は、/mic-developer (英語) にあるホワイトペーパー「Understanding MPI Load Imbalance with Intel® Trace Analyzer and Collector (インテル® Trace Analyzer & Collector を利用して MPI ロード・インバランスを理解する)」 (英語) を参照してください。詳細、ヒントやコツ、既知の回避策については、インテル® クラスターツールおよびインテル® Xeon Phi™ コプロセッサー (英語) ページを参照してください。