このトピックの情報は、パフォーマンスの拡張手法を使用していて、最適化しているアプリケーション形式の解析が済んでいることを前提に説明しています。
最適な手法を判断するためにアプリケーションのプロファイリングを行った後、コンパイラーによって行われた最適化および制限を確認します。そして、コンパイラー・レポートを使用して、次に何を行うかを決定します。
レポートの内容に応じて、コンパイラーが重要なアーキテクチャー上の機能を活用して最高レベルのパフォーマンスを達成できるように、オプション、プラグマを選択し、必要なコード修正を行います。
コンパイラー・レポートは、コンパイラーによって行われた仮定に基づいて、行うことができる処理とできない処理を示します。オプションとプラグマを色々と試すことで、コンパイラーが行った仮定を理解し、また、新しい最適化の手法やテクニックを導き出すことができます。
コンパイラーの活用
いくつかの重要な方法でコンパイラーを効率的に利用できます。
-
適切なレポートを読み、コンパイラーが行っていることとコンパイラーがコードに関して行った仮定を理解する。
-
アプリケーションから最高レベルのパフォーマンスが得られるように、特定のオプション、組み込み関数、ライブラリー、およびプラグマを使用する。
例えば、単精度値の平方根を絶えず計算する場合、単精度データ型用の適切な組み込み関数を使用すると、パフォーマンスを向上できます。例えば、C で sqrt() の代わりに sqrtf() を使用します。
他の推奨する手法は、「最適化手法の適用」を参照してください。
 警告
警告
上記の例のように restrict キーワードを使用するには、コンパイル行で restrict (Linux) または /Qrestrict (Windows*) オプションを使用する必要があります。
非ユニット・ストライド・メモリー・アクセス
パフォーマンスに大きな影響を与える別の問題は、非ユニットストライド方式におけるメモリーアクセスです。これは、内部ループが連続的にインクリメントし、隣接していない場所からメモリーにアクセスしていることを意味します。例えば、次のような行列乗算コードを考えてみます。
|
例 |
|---|
// Non-Unit Stride access problem with b[k][j] void non_unit_stride(int **a, int **b, int **c) {
int A = 42; for(int i=0; i<A; i++) for(int j=0; j<A; j++) for(int k=0; k<A; k++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
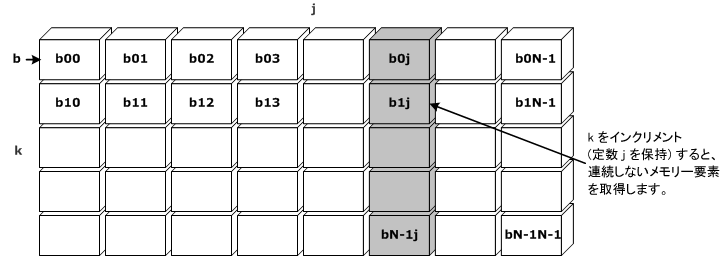
配列に関連した最内ループがインクリメントされるときに、c[i][j] および a[i][k] の両方が連続するメモリーの場所にアクセスする点に注意してください。しかし、配列 b は、インデックス k および j のループでメモリー・ユニット・ストライドにアクセスしません。ループが b[k=0][j=0] を読み取った後、k ループが 1 から b[k=1][j=0] にインクリメントします。
この問題に対処するには、ループ変換 (ループ交換とも呼ばれます) を行います。コンパイラーでループ交換を自動的に行ったとしても、必ずしもすべての機会を認識するとは限りません。
上記の例のメモリー・アクセス・パターンは、次の図のようになります。
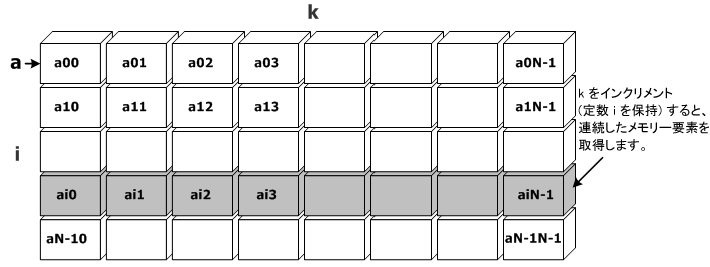
上記の例に、ループ交換を行うために次のような変更を加えたとします。
|
例 |
|---|
// After loop interchange of k and j loops. void unit_stride(int **a, int **b, int **c) {
int A = 42; for(int i=0; i<A; i++) for(int k=0; k<A; k++) for(int j=0; j<A; j++) c[i][j] = c[i][j] + a[i][k] * b[k][j]; } |
ループ交換の後、メモリー・アクセス・パターンは次の図のようになります。