インテル® MKL には、行列乗算用のルーチンが用意されています。最も広く利用されるのは、倍精度行列の積を計算する dgemm ルーチンです。
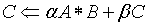
dgemm ルーチンは、いくつかの計算を実行できます。 例えば、このルーチンを使用して、A と B の転置または共役転置を実行することができます。 dgemm ルーチンの機能の詳細とすべての引数については、『インテル® マス・カーネル・ライブラリー (インテル® MKL) リファレンス・マニュアル』の ?gemm のトピックを参照してください。
行列乗算に dgemm を使用する
この演習は、変数を宣言し、行列値を配列で格納した後、dgemm を呼び出して行列の積を計算します。 これらの行列の格納には配列を使用します。

演習の 1 次元配列は、配列の連続するセルに各列の要素を配置して、行列を格納します。
注
このチュートリアルの演習の Fortran ソースコードは、<install-dir>\Samples\ja-JP\mkl\tutorials.zip (Windows*) または <install-dir>/Samples/ja-JP/mkl/tutorials.zip (Linux*/OS X*) を参照してください。
インテル® MKL は Fortran 90 以降をサポートしていますが、このチュートリアルの演習では、より多くの Fortran バージョンとの互換性のために FORTRAN 77 を使用しています。
tutorials.zip ファイルを展開すると、Fortran ソースコードは mkl_mmx_f ディレクトリーに配置され、C ソースコードは mkl_mmx_c ディレクトリーに配置されます。
* Fortran ソースコードは dgemm_example.f を参照
PROGRAM MAIN
IMPLICIT NONE
DOUBLE PRECISION ALPHA, BETA
INTEGER M, K, N, I, J
PARAMETER (M=2000, K=200, N=1000)
DOUBLE PRECISION A(M,K), B(K,N), C(M,N)
PRINT *, "This example computes real matrix C=alpha*A*B+beta*C"
PRINT *, "using Intel® MKL function dgemm, where A, B, and C"
PRINT *, "are matrices and alpha and beta are double precision "
PRINT *, "scalars"
PRINT *, ""
PRINT *, "Initializing data for matrix multiplication C=A*B for "
PRINT 10, " matrix A(",M," x",K, ") and matrix B(", K," x", N, ")"
10 FORMAT(a,I5,a,I5,a,I5,a,I5,a)
PRINT *, ""
ALPHA = 1.0
BETA = 0.0
PRINT *, "Intializing matrix data"
PRINT *, ""
DO I = 1, M
DO J = 1, K
A(I,J) = (I-1) * K + J
END DO
END DO
DO I = 1, K
DO J = 1, N
B(I,J) = -((I-1) * N + J)
END DO
END DO
DO I = 1, M
DO J = 1, N
C(I,J) = 0.0
END DO
END DO
PRINT *, "Computing matrix product using Intel® MKL DGEMM "
PRINT *, "subroutine"
CALL DGEMM('N','N',M,N,K,ALPHA,A,M,B,K,BETA,C,M)
PRINT *, "Computations completed."
PRINT *, ""
PRINT *, "Top left corner of matrix A:"
PRINT 20, ((A(I,J), J = 1,MIN(K,6)), I = 1,MIN(M,6))
PRINT *, ""
PRINT *, "Top left corner of matrix B:"
PRINT 20, ((B(I,J),J = 1,MIN(N,6)), I = 1,MIN(K,6))
PRINT *, ""
20 FORMAT(6(F12.0,1x))
PRINT *, "Top left corner of matrix C:"
PRINT 30, ((C(I,J), J = 1,MIN(N,6)), I = 1,MIN(M,6))
PRINT *, ""
30 FORMAT(6(ES12.4,1x))
PRINT *, "Example completed."
STOP
END注
この演習は、dgemm ルーチンの呼び出し方法を説明します。 実際のアプリケーションでは、行列乗算の結果を使用します。
この dgemm ルーチンの呼び出しは、行列の乗算を行います。
CALL DGEMM('N','N',M,N,K,ALPHA,A,M,B,K,BETA,C,M)引数は、インテル® MKL がどのように演算を行うかを指定するオプションです。ここでは、以下の引数が指定されています。
- 'N'
行列 A と B を乗算前に転置または共役転置しないことを示す文字。
- M、N、K
行列のサイズを示す整数:
A: M 行 K 列
B: K 行 N 列
C: M 行 N 列
- ALPHA
行列 A と B の積の測定に使用する実数値。
- A
行列 A の格納に使用する配列。
- M
配列 A のリーディング・ディメンジョン、またはメモリーの連続する行 (行優先で格納する場合) 間の要素の数。 この演習では、リーディング・ディメンジョンは行の数と同じです。
- B
行列 B の格納に使用する配列。
- K
配列 B のリーディング・ディメンジョン、またはメモリーの連続する行 (行優先で格納する場合) 間の要素の数。 この演習では、リーディング・ディメンジョンは行の数と同じです。
- BETA
行列 C の測定に使用する実数値。
- C
行列 C の格納に使用する配列。
- M
配列 C のリーディング・ディメンジョン、またはメモリーの連続する行 (行優先で格納する場合) 間の要素の数。 この演習では、リーディング・ディメンジョンは行の数と同じです。
コードのコンパイルとリンク
インテル® MKL には、さまざまなコンパイラーとサードパーティのライブラリー、およびインターフェイスと互換性のある、複数のプロセッサーとオペレーティング・システム向けにコードを生成する多くのオプションが用意されています。インテル® Parallel Studio XE Composer Edition でこの演習をコンパイルおよびリンクする場合は、以下のように入力します。
注
ここでは、http://software.intel.com/en-us/articles/intel-mkl-112-getting-started/ (英語) で説明されているようにインテル® MKL をインストールして環境変数を設定済みであることを想定しています。
ほかのコンパイラーの場合は、インテル® MKL リンクライン・アドバイザー (http://software.intel.com/en-us/articles/intel-mkl-link-line-advisor/ (英語)) を使用して、このチュートリアルの演習をコンパイルおよびリンクするコマンドラインを取得します。
コンパイルとリンクが完了したら、生成された実行ファイル dgemm_example.exe (Windows*) または a.out (Linux*/OS X*) を実行します。
インテル® コンパイラーは、互換マイクロプロセッサー向けには、インテル製マイクロプロセッサー向けと同等レベルの最適化が行われない可能性があります。これには、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2)、インテル® ストリーミング SIMD 拡張命令 3 (インテル® SSE3)、ストリーミング SIMD 拡張命令 3 補足命令 (SSSE3) 命令セットに関連する最適化およびその他の最適化が含まれます。インテルでは、インテル製ではないマイクロプロセッサーに対して、最適化の提供、機能、効果を保証していません。本製品のマイクロプロセッサー固有の最適化は、インテル製マイクロプロセッサーでの使用を目的としています。インテル® マイクロアーキテクチャーに非固有の特定の最適化は、インテル製マイクロプロセッサー向けに予約されています。この注意事項の適用対象である特定の命令セットの詳細は、該当する製品のユーザー・リファレンス・ガイドを参照してください。 改訂 #20110804 |

