
AIが導く、次世代の製品開発
実験回数を 1/120 に削減¹。コストと時間を劇的に圧縮し、イノベーションを加速する AI 解析プラットフォーム。
¹ AIST (産業技術総合研究所) の人工心臓設計事例より
実験回数を 1/120 に削減¹。コストと時間を劇的に圧縮し、イノベーションを加速する AI 解析プラットフォーム。
¹ AIST (産業技術総合研究所) の人工心臓設計事例より

Multi-Sigma は、AI の力で研究開発の常識を覆す解析プラットフォームです。
日本の製造業が抱える、以下のような根深い課題を解決します。
膨大な組み合わせの中から最適解を見つけるための、時間とコストのかかる試行錯誤から抜け出せません。
匠の技に頼るあまり、技術の継承が困難になり、組織としての成長が停滞してしまいます。
Multi-Sigma は、独自の「革新的実験計画法」により、最小限のデータから最適解を導き出します。
プログラミング不要の直感的な操作で、誰もがデータに基づいた合理的な意思決定を行える環境を提供します。
昨今、デジタル トランスフォーメーション (DX) やマテリアルズ インフォマティクス (MI) という言葉が賑わう一方、現場では依然として Excel と格闘し、試行錯誤が繰り返されています。Multi-Sigma は、それぞれの立場で抱える課題に寄り添い、具体的な解決策を提示します。
「開発スピードを上げたいが、人員は増やせない」「熟練研究員の退職による技術伝承が課題」
「毎日の実験とデータ整理に追われている」「Python を勉強する時間がない」「AI ツールは難しくて使いこなせない」
「全社的なDXツールを導入したいが、現場が使ってくれない」「セキュリティや導入コストが心配」
Multi-Sigma は、ブラウザーさえあればすぐに利用を開始できるクラウド サービス (SaaS) です。
特別なソフトウェアのインストールや、ハイ スペックな PC は必要ありません。
Google Chrome や Microsoft Edge などのモダンブラウザーに対応しています。OS を問わず利用できます。
ソフトウェアのインストールやアップデートは不要です。常に最新バージョンを利用できます。
データは安全なクラウド環境で管理。場所を選ばずにどこからでもアクセス可能です。
Multi-Sigma は、研究開発から製造プロセス全体にわたり、具体的かつ測定可能な効果をもたらします。
AI が次に試すべき「価値の高い実験」を提案することで、試行錯誤の回数を大幅に削減します。AIST (産業技術総合研究所) の事例では、実験回数を従来の 1/120 に削減し、開発期間の大幅な短縮を達成しました。
わずか 10~20 件のスモール データからでも高精度な予測が可能です。高価な材料の使用量やエネルギー消費を最適化し、無駄なコストを削減します。これにより、研究開発および製造全体の生産性が向上します。
熟練研究員の経験や勘といった暗黙知を、操作ログや実験データから AI が学習します。誰でもトップ レベルの成果を再現できる「形式知」へと変換します。これにより、属人化していた技術の継承問題を解決します。
プロセスの最適化は、エネルギー効率の向上や廃棄物の削減に直結します。Multi-Sigma の活用は、企業の収益性向上だけでなく、CO2 排出量削減といった環境目標の達成にも貢献します。
Multi-Sigma を一言で表現するならば、「逆算の達人」です。従来の AI ツールの多くは、「条件を入力して結果を予測する」という順方向の解析 (フォワード アナリシス) に主眼を置いていました。例えば、「温度 200℃、圧力 5MPa で加工したら、強度はどうなるか?」という問いに答えるものです。しかし、現場のエンジニアが真に求めているのは、「強度を 100 以上にしたい。そのための温度と圧力の最適条件は何か?」という問いへの答えです。
Multi-Sigma は、この「欲しい結果 (出力)」から「最適な条件 (入力)」を導き出す「逆解析 (インバース デザイン)」に特化して設計されています。しかも、単一の目的ではなく、「強度は最大化したいが、コストは最小化したい」といった相反する複数の目的 (多目的最適化) を同時に扱い、さらに「材料 A と B の合計は 100% でなければならない」といった現実的な制約条件を加味した上で最適解を探索できる点が、世界的に見ても極めてユニークな特徴です。
この「多目的最適化」と「制約条件付き探索」を、プログラミング スキルを一切必要としないノーコード環境 (SaaS) で提供している点こそが、Multi-Sigma の最大の価値提案 (バリュー プロポジション) です。Citrine Informatics などのグローバル プレーヤーが数千万円規模のエンタープライズ契約を前提とする中で、ブラウザー一つでスモール スタートできる Multi-Sigma は、日本の製造業の裾野を広げるための最適解と言えるでしょう。
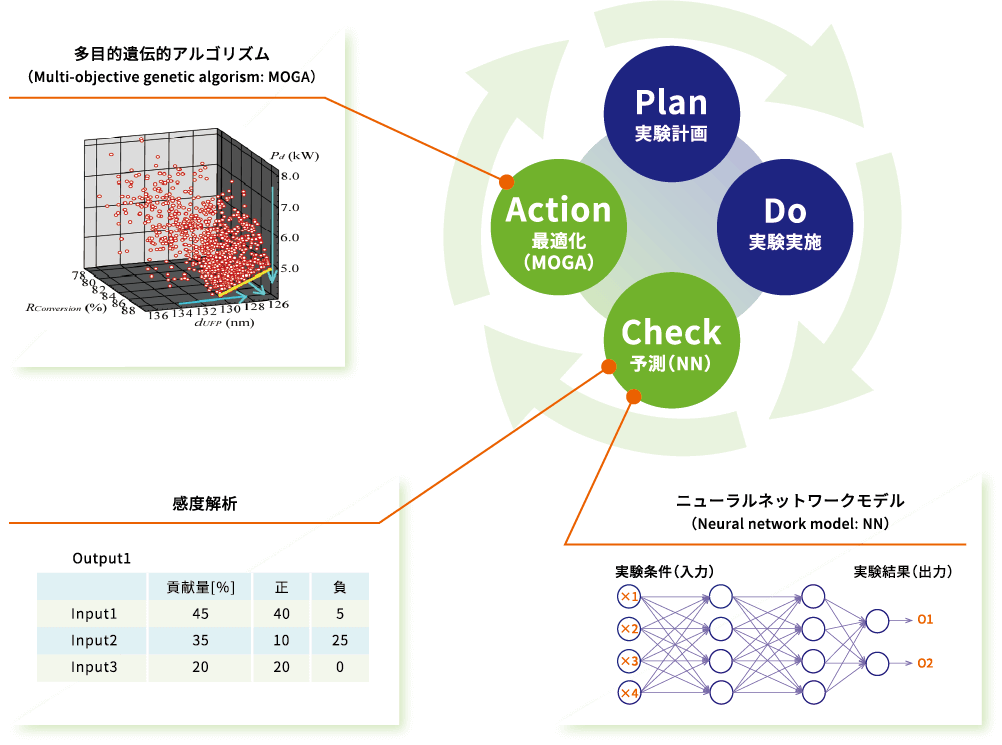
Multi-Sigma は、データの規模や特性に応じて最適な解析を実現するため、2 つの強力なエンジンを搭載しています。それぞれの長所を理解し使い分けることが、成果への近道です。
データ数が概ね 20 件以上ある場合に推奨されます。人間の脳神経回路を模したモデルで、複雑な非線形関係の学習に長けています。
最大の特徴は「オート チューニング (自動調整)」機能です。通常は専門家による手動調整が必要な「ハイパー パラメーター」を、ボタン一つで自動的に最適化します。
実験コストが高くデータが 10 件程度しか得られない場合、NN では学習データに過剰に適合してしまい、未知のデータに対する予測精度が落ちる「過学習 (オーバーフィット)」のリスクがあります。そこで活躍するのが GPR です。ベイズ統計学に基づき、予測値とその「不確実性」を同時に出力します。
この不確実性を利用したベイズ最適化により、次に実験すべき「情報の価値が高い点」を提案できます。
わずか 10 点のデータからでも、物理的に妥当な予測モデルを構築できること。これこそが、高コストな実験やシミュレーションが前提となる研究開発の現場で、Multi-Sigma が選ばれる最大の理由です。
AI プロジェクトの成否はデータ前処理で決まると言われます。Multi-Sigma は、不完全なデータを克服し、AI の判断根拠を可視化する高度な機能を備えています。
産業データは往々にして欠損値を含みます。Multi-Sigma は貴重なデータを無駄にしないため、以下の高度な手法を実装しています。
単位や桁数が異なる変数 (例: 温度と濃度) をそのまま AI に入力すると、数値の大きな変数に学習が偏ってしまいます。Multi-Sigma はこれを防ぐため、複数のスケーリング手法を実装しています。
製造業において AI の「ブラックボックス問題」は許されません。Multi-Sigma は、感度分析 (Gevrey らの Partial Derivative 法がベース) を用いた要因分析機能を提供し、「なぜその予測になったのか」という問いに答えます。
各入力変数が結果にプラスに働くか、マイナスに働くかを分離して定量化することで、単なる重要度ランキングでは分からない複雑な影響を可視化します。例えば、「温度を上げると反応速度は上がる (プラス) が、上げすぎると副反応で収率が下がる (マイナス)」といった非線形な挙動を捉え、物理現象の深い理解と納得感のある意思決定を支援します。
従来の AI 解析では、原料投入から最終製品までの全工程を一つの巨大な AI モデルで学習させようとしていました。これでは、途中のどの工程が品質に影響を与えているのか特定が困難でした。
連鎖解析では、製造プロセスを工程ごとに分割し、それぞれの工程で AI モデル (サロゲート モデル) を作成します。そして、それらを GUI 上でブロックのように連結させることで、ライン全体をデジタル空間に再現します。
ワークフローの例:
このようにモデルを数珠繋ぎにすることで、「原料 A を 10% 変えると、最終的に欠陥率にどう影響するか」を一気通貫でシミュレーションできます。これは、いわば現実の設備や工程をデジタル空間上に再現する「ノーコードで作れるデジタル ツイン」であり、「部分最適」ではなく「全体最適」を実現します。
Multi-Sigma は、単なる解析ツールではなく、産業 R&D のプロセスを変革するプラットフォームです。
カゴメ、産総研、NEDO、東プレ、SWCC といった多様な組織における事例は、その核心的な価値が以下の 3 点に集約されることを示しています。
Industry 4.0 や Society 5.0 が叫ばれる中、現場のデータを価値に変え、持続可能な成長を実現するための具体的かつ強力な手段として、Multi-Sigma の戦略的導入は今後ますます重要性を増すでしょう。
| サービス詳細 | 基本的にオンラインでの実施となります。AI の動作原理や Multi-Sigma の利用方法に関する研修、お客様の事例を用いた OJT ベースでの技術指導、必要に応じた AI の専門家による解析のサポートなどを提供します。 |
|---|---|
| 強み | 世界最高峰の研究者・技術者が、Multi-Sigma の導入を支援します。 |
| 作業期間 | 3 か月〜 |
| 費用 | 内容に応じて相談 |
