- 概要
- 機能
確実な低オーバーヘッドのプロファイリングでコードを最適化
Linaro MAP は、並列/マルチスレッド/シングルスレッドの C/C++、Fortran/F90 コード向けのプロファイラーです。詳細な解析を実施し、パフォーマンスのボトルネックとなる部分をソースの行レベルで示します。Pthreads、OpenMP、MPI の並列化/スレッド化されたコードをプロファイリングできるように設計されています。
Linaro MAP の使用方法は簡単です。コードを計測したり、難解なコンパイルの設定を覚える必要はありません。-g オプションでコンパイルし、以下の通り Linaro MAP を実行するだけです。
$ map my_application.exe
MPI ユーザーであれば以下の通りです。
$ map mpirun -np 128 ./bt_128_C datafile.in
簡単です。
Linaro MAP は、世界最大級のマシンから組込みプロセッサーまで幅広く利用されています。
本製品は開発ツールスイートである Linaro Forge に含まれています。
分りやすい結果表示
プログラムの終了後、Linaro MAP は最も時間が掛ったソース コードの行を示します。また、演算時間は緑のグラフ、通信時間は青のグラフで表示され、プログラムの実行中に何が起こっているのかを把握することは簡単です。
ソース コード ビュー、並列スタック ビューなど Linaro MAP のインターフェースの多くは Linaro Forge や Linaro DDT のインターフェースと同一であり、新たなインターフェースを覚える必要はほとんどありません。
シングルコアから数万コアまで、信頼できるパフォーマンス
古典的なトーレスベースのパフォーマンス ツールとは異なり、Linaro MAP はデータ システム内のファイルを決してダウンさせません。
Linaro の業界をリードするクラスター上のマージ テクノロジと組み合わさったアダプティブ サンプリング レートは、適切なデータ量が正確に記録されます。ワークステーションで 10 分間実行した場合であっても、リモートで数万コアのスーパーコンピューターを 1 週間実行した場合であっても問題ありません。
Linaro MAP であれば、適切なメトリクスを選択したか、実装レベルが適切か、といった心配をする必要はありません。どのような場合であっても処理速度の低下は 5% 程度です。
Linaro Map の機能
開発者にとって、必要以上に複雑なツールを習得するために時間を浪費するのではなく、素晴らしいコーディングに時間やエネルギーを注ぐことが効率的です。Linaro MAP は、パフォーマンスを低下させているコードの場所とその理由を的確に表示するプロファイラーです。
Linaro Map は、以下の機能を提供します。
- 簡単なコードのプロファイリング - 多くのシステムでビルドしたコードを変更する必要がありません。
- 複数のサーバーとプロセスで実行されるアプリケーションのプロファイリング - HPC クラスターや、MPI の使用が含まれます。
- I/O、計算、スレッド、またはマルチプロセス アクティビティにおけるボトルネックの明確なビュー。
- ベクトル化やメモリ帯域幅など、パフォーマンスに影響を与える実際のプロセッサー命令タイプへの深い洞察。
- 最高水準点および完全なメモリー占有スペースにおける変化を検出するための、時間の経過に伴うメモリー使用量。
- 変更内容を編集、ビルド、およびコミット可能なリモート システムでの作業に対する優れたサポートを備えた強力かつナビゲート可能なソース ブラウザー。
結果のより素早い提供
"map -profile my_program.exe" を実行するだけで、Linux 上の C++、C、Fortran、F90 コードをとても簡単にプロファイリングすることができます。それ以上の手順は必要なく、複雑なインストルメンテーションも必要ありません。Linaro MAP では、MPI や OpenMP、pthread、スレッド化されていないコードなどのすべてをプロファイリングすることができます。

グラフィカルに表示される結果は正確で、ソースコード内のどの部分がボトルネックとなっているのかがわかりやすく表示されます。
Linaro Forge ご利用の場合は、デバッガーである Linaro DDT と統合され、共通のインターフェイスを使っているため、開発サイクルの各ステージにおいて、必要な時にツール間を簡単に移動することができます。
低オーバーヘッドなプロファイリング
お使いのプロファイラーを運用コードで実行したことはありますか。
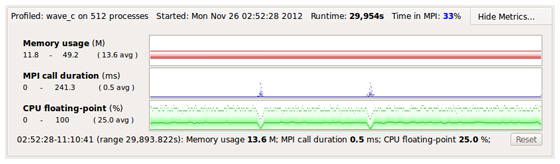
Linaro MAP は、実行時のオーバーヘッドが 5% 未満に収まるように開発されました。また、生成されるデータファイルのサイズはコードのサイズや実行時間が長い場合でも大きくならないため、毎日でも、また変更を加える度に、実行することができます。これにより、本番環境の条件下で本番コードのパフォーマンスに対する解析結果を得ることができます。
実行に掛かった時間はソースコードの横に表示されるため、どの処理がボトルネックとなっているのかがはっきりとわかります。また、すべてのプロセスにわたって掛かった時間ごとに降順で表示するスタック ビューを使用すると、コードの中から問題となる箇所に容易にたどり着くことができます。
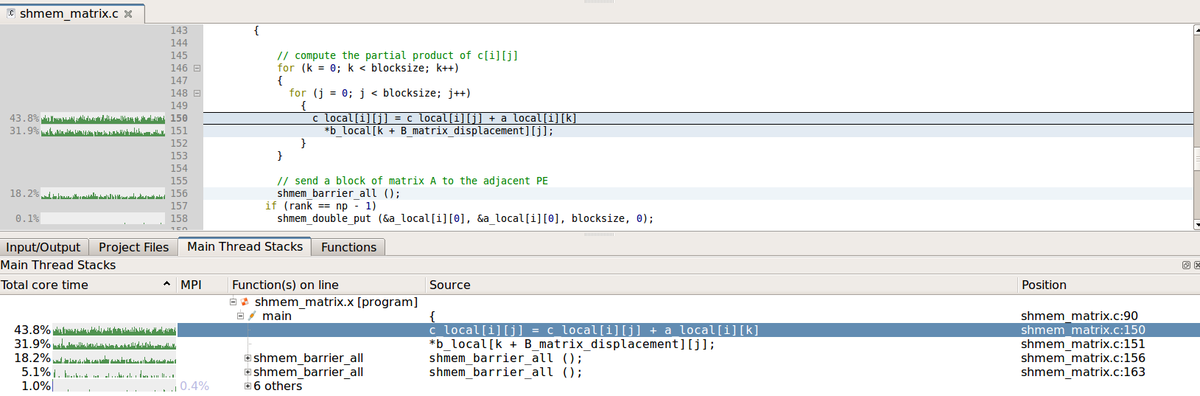
I/O プロファイリング
I/O パフォーマンスが悪い場合、システムの規模が大きくなるにつれて、コードに悪影響を及ぼすようになります。この問題が起こっても、通常は気が付かないか、またはアプリケーションが上手くスケールしていないと勘違いしてしまいます。Linaro MAP を使用すると、ファイルの I/O 帯域幅がどこで使用されているのかをはっきりとわかるため、過負荷状態の共有ファイルシステムや、読出し/書込みパターン、またシステムの設定ミスの問題を診断するのに役立ちます。
スレッドと OpenMP コードのプロファイリング
マルチスレッド化されたコードから良いパフォーマンスを得るのは、なかなか難しいものですが、Linaro MAP を使用すると、スレッドの同期時にサイクルが費やされた場合や、時間が掛かっているスレッドを見つけやすくなります。
CPU の主なアクティビティーを表示するビューや、コアごとの実際の総経過時間によるコードのプロファイリングにより、実際のワークロードをベースに、スレッドのプロファイリングを正確に素早く実施します。
メモリーのプロファイリング

アプリケーションが進むにつれて、Linaro MAP ではすべての計算ノード/サーバーおよびアプリケーション内の全プロセスをまたがる実際のメモリー使用率を表示することができます。メモリー使用率がわかることで、不均衡な状態や、アプリケーション内のフェーズにより発生した変更点を特定するのに役立ちます。使用率はソースコードと並べて表示されます。 最大使用率が可視化されると、一時的にメモリーを大量に消費するサードパーティー製のライブラリーに依存するアプリケーションを確認することができます。時間の経過とともに使用するメモリー量が増えるアプリケーションでは、Linaro DDT のメモリー デバッグ機能を使用して、潜在的なメモリーリークを見つけることができます。
また、メモリー アクセスに掛かった時間もプロファイリングすることができるため、良くないメモリー アクセス パターンとキャッシュの利用について簡単に見つけることができます。
アクセラレーター メトリック
Linaro MAP は最新の NVIDIA CUDA GPU に対応しており、CUDA GPU と CPU を一緒にプロファイリングすることができます。プロファイリングすることで、GPU の処理が完了するまで CPU の待機時間がどれ位掛かったかを確認できるだけでなく、グローバル メモリー アクセス内の CUDA GPU の時間、GPU 使用率、そして GPU の温度さえも表示することができます。
エネルギーのプロファイリング
エネルギー消費量とピーク時の電力使用率は、ハイパフォーマンスなアプリケーションの場合、特に重要です。Linaro MAP の Energy Pack を使用することで、開発者は時間とエネルギーを最適化することができます。
Sandy Bridge、およびそれ以降のインテル プロセッサー (Haswell と Broadwell チップを含む) に対応しており、内蔵されているインテル® RAPL の電力測定機能を使って、CPU の電力を測定します。電力監視に対応している NVIDIA GPU であれば、どの GPU でも電力測定を実施可能です。ノードレベルの測定はインテル Energy Checker API または Cray HSS エネルギー カウンター (XK6 および XC30 以降) に対応しているシステムで利用できます。
異なるクラスターとアーキテクチャーの性能の比較
Linaro MAP は主要な Linux プラットフォーム対応のクロスプラットフォーム プロファイラーです。データはオープン XML 形式で提供されるため、異なるハードウェア プラットフォーム上の主要なコードのパフォーマンスの特徴を確認したり、比較するための後処理を行うのに最適です。
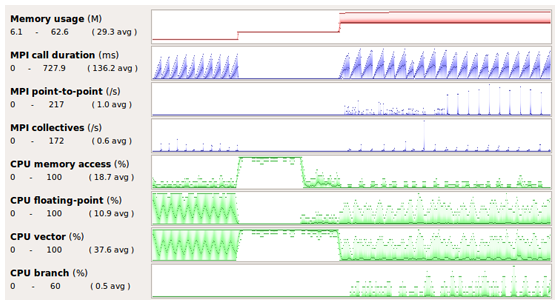
元のソースコードにアクセスせずに、CPU、メモリー、MPI の性能メトリックを経時的に追跡し、レポート出力することができるため、新しいプラットフォームの評価や比較を行うのに必要なすべての情報を得ることができます。
Linaro MAP は最新のプラットフォームすべてに対応しているため、どんなシステムでも生産性を上げることができます。
MPI プロファイラーでもあり、またマルチスレッドのプロファイラー、そして OpenMP* プロファイラーでもあり、ハイブリッド プログラミング モデルに対応しています。
アーキテクチャー
NVIDIA CUDA、OpenPOWER、Arm 8 (64 bit)、インテル Xeon プロセッサー
プログラミング モデル
MPI、OpenMP*、CUDA、OpenACC、UPC、PGAS 言語, pthread によるマルチスレッディング、SHMEM、OpenSHMEM
言語
Fortran、C++、C++11、C、PGAS 言語
サポートスタッフが重要な問題に取り組めるように支援
HPC 分野のコンサルタントやサポート スタッフは、パフォーマンスと最適化ツールについて熟知しています。しかしそれでも、新入りのプログラマーが起こす、よくある基本的なミスを診断するのに時間を費やしてしまうものです。

Linaro MAP は、新人の開発者が MPI や OpenMP* や普通のコードを見て、よくあるパフォーマンス問題の原因をすぐに見つけられるように設計しました。専門家はそういった基本的な問題に時間を取られず、より複雑で高度な最適化の問題を深く掘り下げることができるようになります。
