[Bottom-up (ボトムアップ)] ペインにアクセスするには、結果タブで  サブタブをクリックします。[Bottom-up (ボトムアップ)] ペイン、[Timeline (タイムライン)] ペイン、そしてビューポイントに応じて [Call Stack (コールスタック)] ペインを含む [Bottom-up (ボトムアップ)] ウィンドウが表示されます。
サブタブをクリックします。[Bottom-up (ボトムアップ)] ペイン、[Timeline (タイムライン)] ペイン、そしてビューポイントに応じて [Call Stack (コールスタック)] ペインを含む [Bottom-up (ボトムアップ)] ウィンドウが表示されます。
[Bottom-up (ボトムアップ)] ペインには、評価基準ごとのプログラムユニットのパフォーマンス・データを示す表が表示されます。表の各行はプログラムユニット (モジュール、関数、同期オブジェクト、その他) を表し、 各列はパフォーマンス評価基準を表します。評価基準のリストとプログラムユニットの階層はビューポイントによって異なります。
- ユーザーモード・サンプリング/トレース収集に基づくビューポイントでは、プログラムユニットはデフォルトでボトムアップでグループ化されます (子関数が親関数の真上に配置されます)。このような検証方法は、ボトムアップ解析として知られています。
- ハードウェア・イベントベース・サンプリング収集に基づくビューポイントでは、プログラムユニットは階層でグループ化されます (例えば、関数は対応するモジュールの下にグループ化されます)。
ビューポイントに応じて、[Bottom-up (ボトムアップ)] は次の評価基準を使用します。
| 評価基準 | 説明 | ビューポイント |
|---|---|---|
| CPU Time (CPU 時間) | 実行スレッドの Self Time (セルフ時間)。複数のスレッドの場合は CPU 時間が合計されます。 |
hotspot、CPU 使用率別 hotspot、スレッドのコンカレンシー別 hotspot |
| Wait Time (待機時間) | 指定されたスレッドが、同期待機や I/O 待機などのイベントが発生するまで待機に要したプロセッサー時間。OK または Ideal (理想) バー (デフォルトでは緑) はプロセッサーが効率良く使用されていることを表し、その他のバーは最適化可能なプログラムユニットを表します。 |
スレッドのコンカレンシー別 hotspot、ロックと待機 |
| Wait Count (待機カウント) | システム待機 API が呼び出された回数。ロックの場合は、ロックの競合により待機が発生した回数。 |
ロックと待機 |
| Spin Time (スピン時間) | 同期構造でスレッドがアクティブな時間。 |
ロックと待機 |
| Overhead Time (オーバーヘッド時間) | 共有リソースの解放からリソースの取得までの時間。オーバーヘッド時間はできるだけ短いのが理想的です。短いほど、リソースを取得するためにスレッドが待機しなければならない時間が少ないためです。 |
ロックと待機 |
| <Event-based metrics> (<イベントベースの評価基準>) | ハードウェア関連のパフォーマンス問題 (メモリーアクセス問題やバンド幅問題など) を特定するのに使用される評価基準。各評価基準は、ハードウェア・イベントの比率です。列見出し上にマウスカーソルを移動すると、評価基準の説明が表示されます。 |
ハードウェア問題 |
| <Hardware Event Count> (<ハードウェア・イベント・カウント>) | 解析中にイベントが発生した予測回数。 |
イベントカウント別 PMU イベント |
| <Hardware Event Sample Count> (<ハードウェア・イベント・サンプル・カウント>) | 実際にイベントで収集したサンプルの数。 |
イベントカウント別 PMU イベント |
デフォルトでは、すべてのプログラムユニットは [Data of Interest (特定のデータ)] 列で降順にソートされ、最も時間のかかっているプログラムユニットが最初に表示されます。[Bottom-up (ボトムアップ)] ペインを使用して、最適化すべきユニットを特定できます。
ユーザーモード・サンプリング/トレース収集結果ビューポイントの [Bottom-up (ボトムアップ)] ペイン
ユーザーモード・サンプリング/トレース収集に基づくビューポイントの各プログラムユニットに対して、そのプログラムユニットまでのコールスタックのツリー階層を解析できます。各ツリーでは、呼び出し関係を示す矢印 ![]() とともに、呼び出し元が 1 つだけのすべてのプログラムユニットが同じ行にリストされます。呼び出し元が 2 つ以上あるプログラムユニットは、それぞれの呼び出し元が個別の行になるように分割されます。
とともに、呼び出し元が 1 つだけのすべてのプログラムユニットが同じ行にリストされます。呼び出し元が 2 つ以上あるプログラムユニットは、それぞれの呼び出し元が個別の行になるように分割されます。
例えば以下のスクリーンショットでは、2 つ目の hotspot である DD_BltBackToPrimary 関数は Paint という 1 つの関数によって呼び出され、この呼び出し元関数は 3 つの呼び出しシーケンスで呼び出されています。
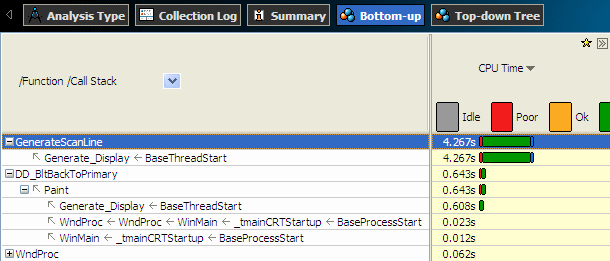
行の CPU 時間の値は、その行の入れ子されたすべての項目の CPU 時間の合計の値です。例えば上記のスクリーンショットでは、Paint 行の CPU 時間の値は、それ以下の入れ子されたすべての項目の CPU 時間の合計値になります。
ハードウェア・イベントベース・サンプリング収集結果ビューポイントの [Bottom-up (ボトムアップ)] ペイン
イベント・サンプリング収集に基づく解析を実行すると、[Bottom-up (ボトムアップ)] ペインにハードウェア・イベント関連の評価基準が表示されます。デフォルトでは、表のデータは 1 つ目の列の Clockticks イベント (プロセッサーによっては CPU Cycles イベント) でグループ化されます。
イベント列見出しで  ボタンをクリックすると、各プロセッサーでサンプリングされたイベントの数を確認することができます。
ボタンをクリックすると、各プロセッサーでサンプリングされたイベントの数を確認することができます。
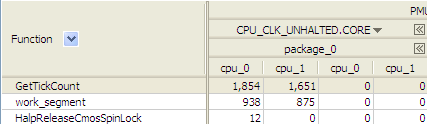
[package (パッケージ)] 列はシステムの物理プロセッサーをリストし、 [cpu] 列はパッケージごとに 2 つのハードウェア・スレッド 0 と 1 をリストします。上記の例では、package_0 という列の名前は物理プロセッサーが 1 つだけであり、このプロセッサーにはハードウェアスレッド '0' と '1' があることを示しています。