概要
すぐに利用でき、優れたパフォーマンスを実現

インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) には、パフォーマンスの向上と開発時間の短縮に役立つ豊富なルーチンが含まれています。高度にベクトル化およびスレッド化された線形代数、高速フーリエ変換 (FFT)、ベクトル演算関数、そして統計関数を含んでいます。
プロセッサーの処理能力のすべてを活用する最も簡単な方法は、その潜在能力を引き出すように設計された最適化済みの数学ライブラリーを使用することです。コンパイラーも、手動で最適化されたライブラリーが引き出すパフォーマンス・レベルには敵いません。アプリケーションが BLAS や LAPACK 関数を使用しているのであれば、インテルおよび互換プロセッサーでパフォーマンスを更に向上するために、簡単なインテル® oneMKL への再リンクをお試しください。
インテルでは、開発者がすぐに利用できるよう、ランタイムの再配布権が含まれる関数群を開発しており、開発者から寄せられた要望をもとに、機能追加を進めます。インテル® oneMKL を使用することで、開発したコードを将来の世代のインテル ® プロセッサーでも最小限の労力で適切に実行できるため、長期に渡り開発、デバッグそして保守時間を節約できます。
詳細・新機能 技術情報製品種類
スイート製品に同梱
インテル® IPP は単体で販売されておりません。以下製品に同梱されます。

インテル® oneAPI ベース・ツールキット
1 つのプログラミング・モデルで複数のアーキテクチャー (CPU、GPU、FPGA) にわたって高いパフォーマンスを発揮できるコードの開発を支援します。

インテル® oneAPI ベース & HPC ツールキット
DPC++/C++、Fortran コンパイラーと MPI 開発ツールにより、CPU およびアクセラレーターまたはそれらのクラスターへ最適化された HPC アプリケーションの開発を支援します。
インテル® oneMKL 2025
バージョン 2025.1 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートや動作環境、およびインテル社公開の情報を参照ください。
最新バージョンに関する日本語情報をお探しの方は、ライブラリーが同梱されているツールキットのリリースノートをご参照ください。
インテル® oneMKL に関するその他のドキュメントについては、こちらを参照ください。
詳細
総合的な数学機能 – 広範囲なアプリケーションの要求をカバー
インテル® oneMKL は、高度にベクトル化およびスレッド化された線形代数、高速フーリエ変換 (FFT)、ベクトル演算関数、そして統計関数を含んでいます。単一の C および Fortran の API 呼び出しにより、これらの関数は自動的にコードパスが選択され、過去、現在そして将来のプロセッサー・アーキテクチャーにスケールできます。クラスター版の LAPACK、FFT およびスパースソルバーには、MPI ベースの分散メモリー演算サポートが含まれます。
標準 API – 簡単にコードに統合でき、パフォーマンス向上を実現
最小限のコード変更で他のライブラリーから切り替えられるよう、インテル® oneMKL はデファクト・スタンダードとなっている API を採用しています。これにより、単純に関数を置き換えるか再リンクすることで、迅速にそして容易にアプリケーションのパフォーマンスを向上できます。
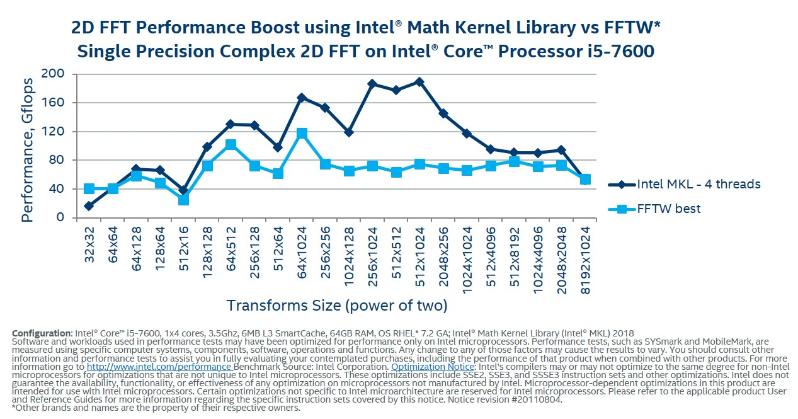
単純にインテル® oneMKL の LAPACK (線形代数パッケージ) に置き換えることで、500% 以上の性能向上が達成できた例もあります。業界標準の BLAS と LAPACK 線形代数 API に加えて、インテル® oneMKL は高速フーリエ変換向けの MIT FFTW C インターフェイスをサポートしています。
過去、現在そして将来のプロセッサーに渡って最高のパフォーマンスとスケーラビリティーを実現 – 容易にそして自動的に
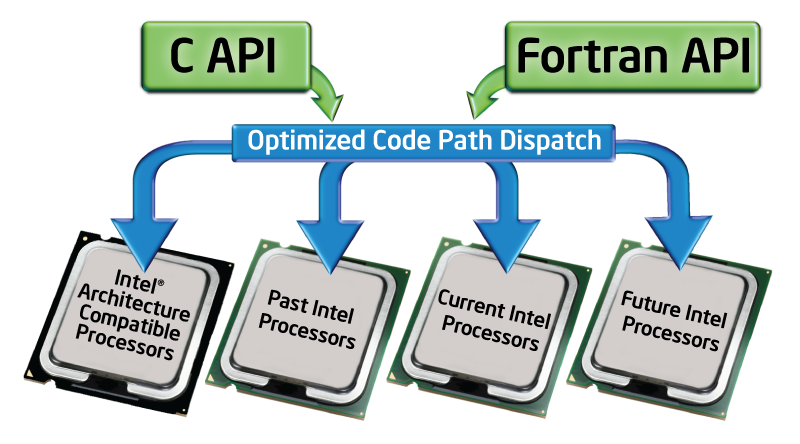
インテル® oneMKL は、単一の C もしくは Fortran API に、各世代のインテルおよび互換プロセッサー向けに最適化された、複数のコードパスを実装します。アプリケーション開発者によりコード分岐がないことが要求されますが、インテル® oneMKL は、最大限のパフォーマンスを得るため最良のコードパスを利用します。新たに最適化されたコードパスは、将来のプロセッサーがリリースされる前に同じ API の配下に追加されるため、開発者は新しいバージョンのインテル® oneMKL にリンクするだけで、アプリケーションは最新のプロセッサー・アーキテクチャーを最大限に活用する準備を整えることができます。
開発者の要求に柔軟に対応
開発者が達成しなければならない多くの要件は、時に競合し合い、調整しなければいけないことがあります。可能な限り高いアプリケーションのパフォーマンスと一貫性のある浮動小数点の結果は必要ですか? 高速なベクトル演算関数パフォーマンスを必要とするが、精度は求めませんか?
インテル® oneMKL は、必要に応じて以下のようなトレードオフを制御できます。
- 結果の一貫性とパフォーマンス
- 精度とパフォーマンス
- コンパイラー、リンカーおよびスレッドモデル
- 言語とオペレーティング・システム
また、多くの開発者が使用するコンパイラー、言語、オペレーティング・システム、リンク方法、そしてスレッドモデルと互換性があります。複数の環境をサポートするため、開発者はライブラリー使用の習得も管理方法もインテル® oneMKL のみを考慮すれば良く効率的です。
線形代数


インテル® oneMKL の高度に最適化された BLAS および BLAS のような拡張機能を使用すると、高性能コンピューティング、機械学習、その他の分野のアプリケーションでパフォーマンス・アドバンテージが得られます。
低レベルの線形代数ルーチンは、ベクトルと行列で動作し、次のような業界標準の BLAS 演算と互換性があります。
- レベル 1 : ベクトル - ベクトル演算
- レベル 2 : 行列 - ベクトル演算
- レベル 3 : 行列 - 行列演算
インテル® oneMKL には、多くの BLAS のような拡張機能も含まれています。
- 三角 GEMM ルーチン : 行列 - 行列演算を行うが、上三角部分または下三角部分のみの結果行列を更新
- バッチ GEMM ルーチン : 複数の GEMM 操作を並行して実行
- パックされた GEMM ルーチン : 複数の GEMM 操作にまたがる内部パッキングコストを償却
高速フーリエ変換 (FFT)

複数のニーズに対する FFT
FFT は 一、二、または三次元で機能し、混合基数をサポートします (2 の累乗に限定されません)。 これらの FFT 関数の分散バージョンはクラスター上で使用されます。 サポートされる機能は次のとおりです。
- 単精度および倍精度の一次元バージョン
- 任意の長さの多次元、複素数間、実数-複素数間、実数 - 実数間の変換
- 業界標準の API との互換性のための FFTW インターフェイス
クラスター向けのフーリエ変換関数
単一ノードのパフォーマンスが不十分な場合は、コンピューティング・ノードのクラスター全体で、分散コンピューティングをサポートします。
ベクトル統計とデータ適合

インテル® oneMKL は、金融工学、ライフサイエンス、エンジニアリング・シミュレーション、データベースなどのアプリケーションの操作を高速化します。モンテカルロ・アプリケーションのパフォーマンスが向上し、乱数ジェネレーター、確率分布、および並列計算のための機能が提供されます。
Mersenne Twister や Niederreiter などの乱数ジェネレーターと、均一分布、ガウス分布、指数分布などのさまざまな確率分布に組み合わせます。
インテル® oneMKL は、インコアとアウトオブコアの両方に対応した統計分析用のハイレベルなコア/ビルディング・ブロックも提供します。これらの統計関数には、以下が含まれます。
- 基本統計の計算
- 依存関係の予測
- 外れ値の検出
- 欠測値の置換
インテル® oneMKL には、一次補間用の豊富なスプライン関数のセットが含まれています。これらの関数は、データ解析 (例: ヒストグラム)、ジオメトリー・モデリング、面近似を含む、さまざまなアプリケーションで役立ちます。スプラインには、線形、平方、立方、ルックアップ、ベーシス( B スプライン)、単調、階段状、定数、ユーザ定義です。
ベクトル演算およびその他のソルバー
![]()
インテル® oneMKL には、計算集約的な数学関数を高速化するベクトル数学ライブラリーが含まれています。 このライブラリーは、単精度および倍精度の要件、実数および複素数、および計算タイプを処理します。 基本ベクトル算術演算には、要素ごとの加算、減算、乗算、除算、および共役が含まれます。 丸め演算には、floor、ceil、および最も近い整数が含まれます。
含まれるその他の機能:- 累乗
- 平方根
- 逆数
- 対数
- 三角関数/三角法
- 双曲線(逆)エラーと累積正規分布
- パックおよびアンパック
- 信頼領域アルゴリズム
- 部分微分方程式
強化された機能:
- 正確性
- 非正規数処理
- エラーモード制御
ベンチマーク
| インテル® Core™ プロセッサー |
インテル® Xeon® プロセッサー |
|
|---|---|---|
| BLAS | ||
| LAPACK | ||
| 高速フーリエ変換 (FFT) | ||
| スパース行列ベクトル乗算 (Sparse Matrix-Vector Multiplication : SpMV) およびスパース・ソルバー |
||
| 乱数ジェネレーター (RNG : Random Number Generator) |
ドキュメント
オンライン・コンテンツ
関連ページ


関連製品

{kind=link}
お知らせ
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2023年11月24日、インテル® oneMKL 2024 が同梱されるインテル® ソフトウェア開発ツールに対応する有償サポートサービスの提供を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
2022年12月19日、インテル® oneMKL 2023 が同梱されるインテル® oneAPI 2023 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日、インテル® oneMKL 2022 が同梱されるインテル® oneAPI 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
2020年 12月 9日、インテル® oneMKL 2021 が同梱されるインテル® oneAPI 2021 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2021 を無料でダウンロードしてご利用いただけます。
2019年 12月 18日、インテル® oneMKL 2020 が同梱されるインテル® Parallel Studio XE 2020 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2020 を無料でダウンロードしてご利用いただけます。
2018年 9月 13日、インテル® oneMKL 2019 が同梱されるインテル® Parallel Studio XE 2019 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2019 を無料でダウンロードしてご利用いただけます。
インテル社の方針により、2014年 8月 26日 (火) を以って、インテル® oneMKL 単体製品の新規ライセンスの販売を終息しました。
インテル
® MKL の SSR および、本製品を含むバンドル製品の新規ライセンス、SSR は継続して販売いたします。
FAQ
必要なインテル® oneMKL のコピー数は、インテル® oneMKL API を使用してコードの記述、コンパイル、テストを行っている開発者の数と、コンパイルおよびリンクを行うビルドマシン (フルセットのインテル ® MKL 開発ツールが必要です) の数によって決まります。詳細は、 EULA を参照してください。
はい。インテル® oneMKL を購入すると、インテル® oneMKL の一部のファイルをアプリケーションとともに再配布する権利が得られます。インテル® MKL の評価版には、この権利は含まれません。再配布できるファイルは、製品ライセンス付きのインテル® oneMKL ディストリビューションに含まれている redist.txt にリストされています。
いいえ。コピーごとにロイヤルティーを支払う必要はありません。詳細は、インテル® oneMKL エンド・ユーザー・ソフトウェア使用許諾契約書 EULA を参照してください。
一般に、リンク可能なファイル (Windows ® では .DLL および .LIB ファイル、Linux* では .SO および .A ファイル) を再配布できます。インテル® MKL を購入 (またはサポートサービスを購入して更新) すると、再配布可能なファイルのリストを含む redist.txt ファイルが提供されます。インテル® MKL の評価版には、この権利は含まれません。詳細は、 EULA を参照してください。
EULA の Redistributables セクションで定義されているディレクトリーに含まれているファイルのコピーは無制限に再配布できます。
必要なインテル® oneMKL のコピー数は、インテル® oneMKL API を使用してコードの記述、コンパイル、テストを行っている開発者の数によって決まります。例えば、組織で 5 人の開発者がインテル® oneMKL を使用してコードを記述している場合、5 つのインテル® oneMKL ライセンスが必要です。詳細は、 EULA を参照してください。
必要なインテル® oneMKL のライセンス数は、組織でインテル® oneMKL を同時に使用する開発者とビルドマシンの数によって決まります。同時に使用するコピー数がライセンス数以下であれば、任意の数のマシンにインテル® MKL を配備してアプリケーションをビルド/テストできます。例えば、5 人の開発者が 10 台のマシンで同時にインテル® oneMKL を使用して開発とテストを行う場合、必要なインテル® MKL のライセンス数は 10 になります。詳細は、 EULA を参照してください。
いいえ。インテル® oneMKL の再配布可能ファイルをソフトウェアに含めて再配布するためにロイヤルティーを支払う必要はありません。開発者が使用するインテル® MKL のライセンスを購入することにより、ソフトウェアとともにインテル® oneMKL の再配布可能ファイルを無制限に配布する権利が得られます。詳細は、 EULA を参照してください。
- インテル® oneMKL は、処理するデータ全体がメモリーに収まる場合に有用です。インテル® DAAL は、データが一度にメモリーに収まりきらない状況でも処理できます。インテル® DAAL は、アプリケーションがデータの一部分をチャンクとして処理し、最後に最終結果を取得することを可能にします。
- インテル® oneMKL は、Fortran と C API をサポートします。インテル® DAAL は、C++ と Java* API をサポートします。
- インテル® oneMKL を使用する場合、アプリケーションはデータの管理 (データソースに接続し読み取る) にほかのツールやライブラリーを必要とします。インテル® DAAL は、データ管理機能を持っています。アプリケーションは、各種ソース (ファイル、インメモリー・バッファー、SQL データベース、HDFS など) に直接アクセスできます。
- いくつかのアルゴリズム (行列分解、低次モーメント、分位など) は、インテル® oneMKL にもあります。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。