企業の AI システムを統制する運用基盤
エージェントのセキュリティ確保、インタラクションのモデル化、ツール呼び出しの管理に関するポリシーを自動適用し、データ漏洩を未然に防ぎます。管理体制を損なうことなく、AI トランスフォーメーションを加速させましょう。
エージェントのセキュリティ確保、インタラクションのモデル化、ツール呼び出しの管理に関するポリシーを自動適用し、データ漏洩を未然に防ぎます。管理体制を損なうことなく、AI トランスフォーメーションを加速させましょう。
生成 AI の活用が進むほど、モデルや外部 API、MCP サーバー、エージェントの利用は分断され、全体像が把握しづらくなります。その結果、意図しない挙動や管理の抜け漏れが発生しやすくなります。Prediction Guard は、分散した AI 利用をコントロール プレーンに集約し、自社の VPC やオンプレミス環境に展開できる「主権型 AI システム」の運用基盤を提供します。ポリシー適用やアクセス制御、監査ログを組み込み、データやガバナンスを外部に委ねることなく、全体を可視化します。
これにより、表面的なルールではなく、実運用で機能する管理体制を確立できます。モデル、ツール、エージェント、データの連携を継続的に把握・制御し、企業利用に求められる安全性と信頼性を維持します。
OWASP や NIST が提唱する AI ガバナンスのベストプラクティスに準拠するために必要なサービスや製品の数を削減します。[1]
[1] NIST 600-1 ガイダンスに準拠するために Azure で必要となる個別のサービスの数と、Prediction Guard が提供する単一の包括的なソリューションの比較結果です。
AI エージェントの本番環境への導入を加速します。[2]
[2] 断片化した API 管理から統合型 AI ゲートウェイへ移行した組織では、従来 2 〜 6 か月かかっていたシステムの機能提供の遅延が、即時に機能を利用できるレベルまで短縮されました。この構造的な転換により、API 定義にかかるオーバーヘッドが最大 85% 削減され、リリースサイクルも数週間から数日に短縮されました。
「AI コントロール プレーン」として企業の生成 AI システムを安全に運用するための主要機能
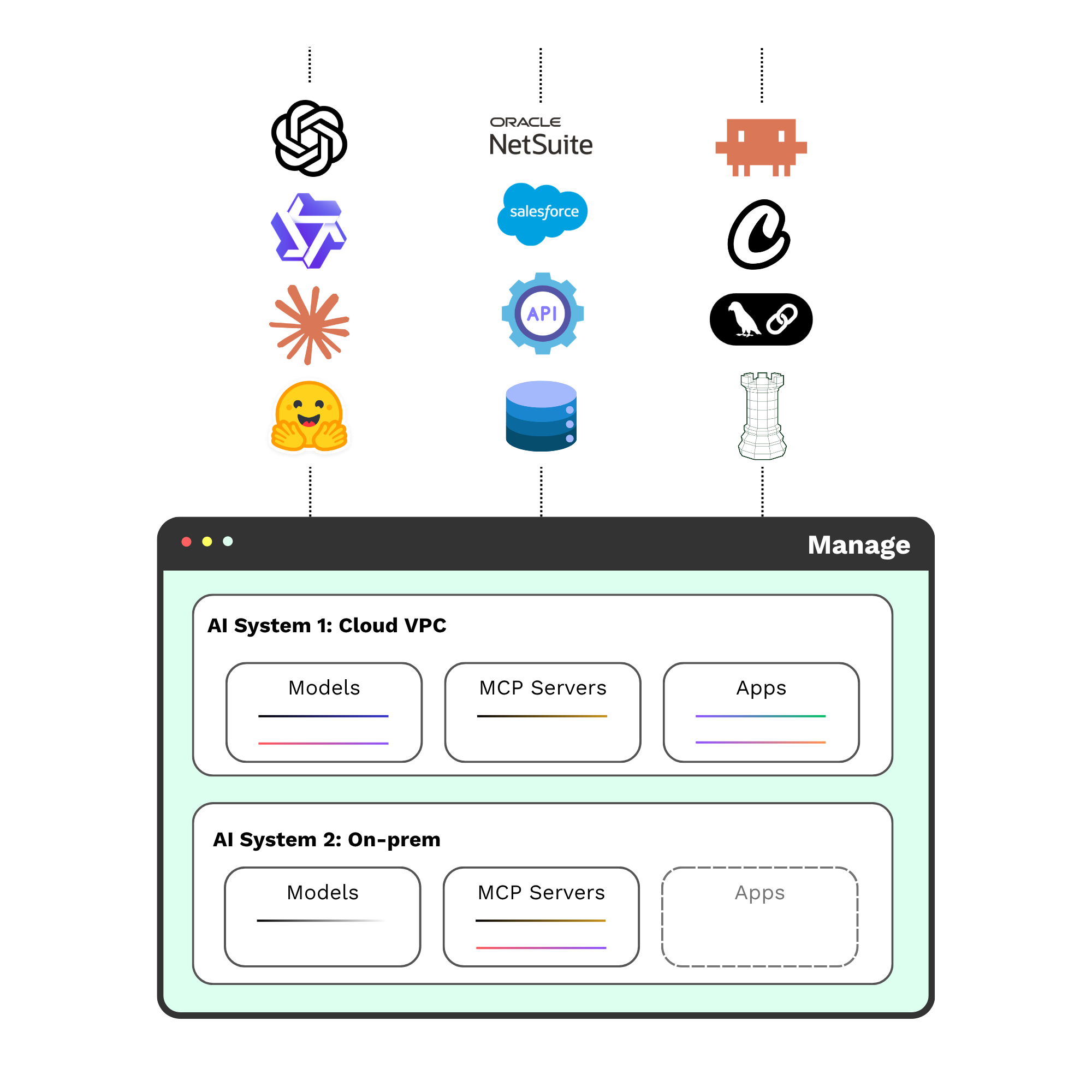
制御は、AI システムのセキュリティにおいて不可欠です。ガバナンスを運用レベルで実装するには、企業は自社の AI システムの連携部分を自ら所有し、追跡や管理できるようになる必要があります。
システムレベルのセキュリティを実現するには、ポイント ソリューションや外部のファイアウォールに依存するのではなく、AI システムの運用基盤に直接ポリシーを組み込む必要があります。

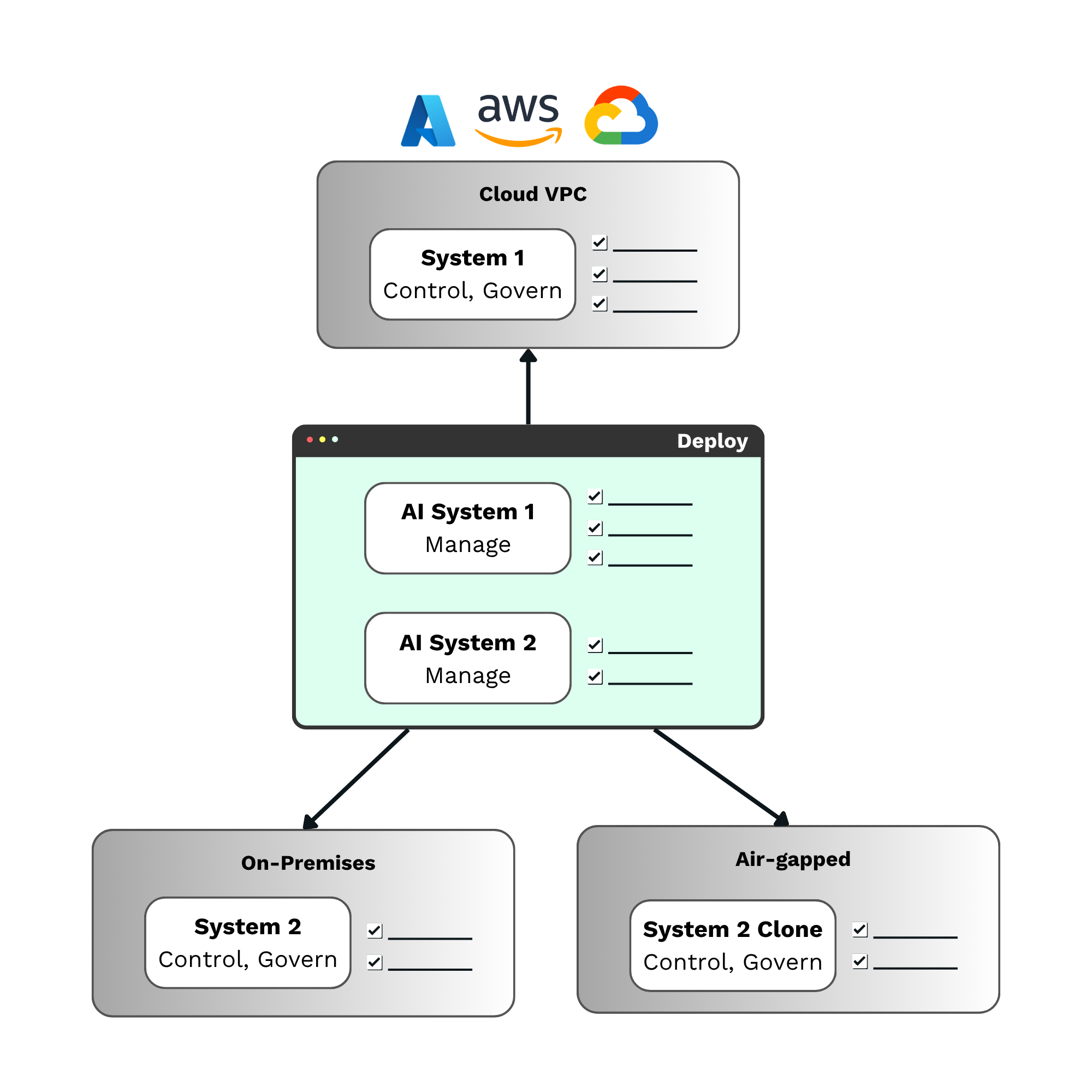
AI システムを適切に制御するには、セキュリティ境界の中で AI ガバナンスを適用する必要があります。Prediction Guard のコントロール プレーンは、お客様のインフラストラクチャ内に導入できます。
ノーコードおよびコードベースの統合により、価値創出までのスピードと長期的な柔軟性を両立させます。コードを書かずにエージェントを迅速に作成できると同時に、開発者は使いやすい集中管理 API を通じてカスタム統合を構築できます。
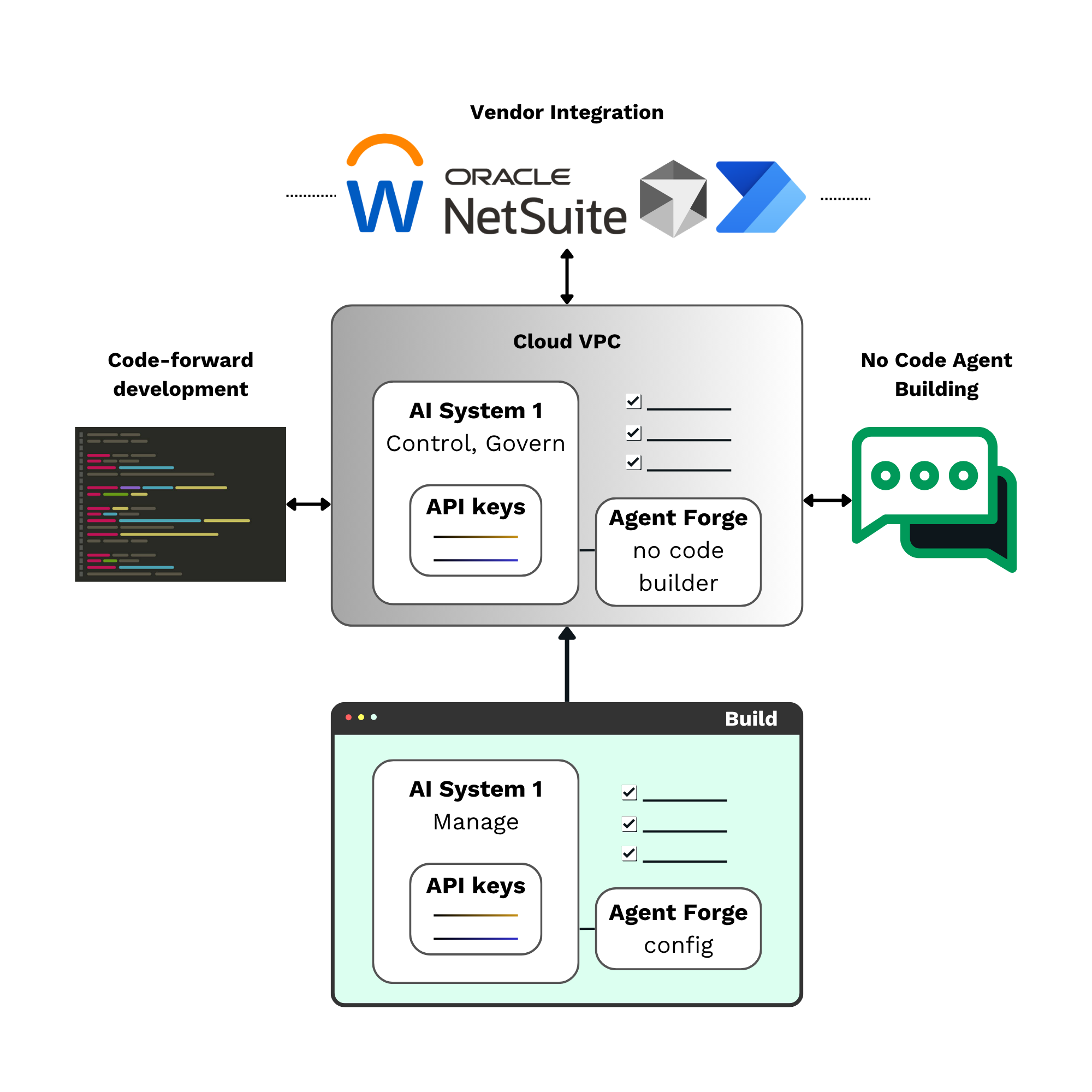
企業の生成 AI 活用を安全かつ効率的に拡張するための主なメリット
大規模システムでセキュアな運用
AWS Bedrock や Azure OpenAI、自社でホスティングするモデル、MCP ツール、AI エージェントなど、分散した AI 資産を単一のセキュアな環境に統合します。スケールに伴う管理のばらつきを防ぎ、システム全体で一貫した制御とガバナンスを維持できます。
予測可能なコスト
AI システムの TCO を 4 分の 1 に削減します。分散した AI セキュリティ ツールや個別対策の導入を不要にし、拡張性を確保しつつ完全なコンプライアンスを実現する単一のコントロール プレーンを導入しましょう。
