
「セキュリティ」と「プライバシー」は、企業での生成 AI の導入において誰もが関心を持つテーマです。しかし、これらの用語は混乱を招き、曖昧になりがちです。開発現場のエンジニアは、AI を活用したアプリケーションの安全性の確保に関して混乱することがよくあります。 NIST の AI リスク管理フレームワークや OWASP の大規模言語モデル アプリケーション トップ 10 は一定の指針を提供しますが、時に内容が包括的すぎて圧倒されることもあります。そのため、実際の現場でこれらのフレームワークをどのように応用するかを見極めることが課題となります。
AI のリスクと定義
まずはじめに、OWASP が提供するリソースをもとに、注意すべき AI セキュリティ リスクを定義しましょう。
プロンプト インジェクションまたはジェイルブレイク
プロンプト インジェクションとは、特定のユーザー入力によって言語モデルの動作や出力が意図しない形で操作され、ガイドライン違反、有害なコンテンツ生成、不正アクセス、または重要な意思決定への不当な影響を招く恐れのある脆弱性を指します。人間には気づけないような入力であっても、モデルには影響を与える場合があります。これは、モデルによるプロンプト処理における脆弱性ですが、安全制限の回避 (ジェイルブレイク) など、モデルの挙動を変更するために悪用されることがあります。
機密情報開示および個人情報/医療情報漏洩
機密情報の開示とは、言語モデルやそのアプリケーションが、個人識別情報 (PII)、財務データ、健康記録、機密性の高い業務データ、セキュリティ認証情報、法的文書、独自アルゴリズム、ソースコードを意図せず出力してしまう事象を指します。これにより、不正なデータ アクセス、プライバシー侵害、知的財産権の侵害につながる可能性があります。ユーザーは LLM に機密データを提供することに注意し、意図しない開示のリスクを理解しておくべきです。
サプライ チェーンの脆弱性
LLM におけるサプライ チェーンの脆弱性は、サプライ チェーン全体のトレーニング データ、モデル、展開プラットフォームの整合性を損なう可能性のあるさまざまなリスクを指します。これらの脆弱性は、偏った出力、セキュリティ侵害、システム障害につながる可能性があります。コードの欠陥や依存関係といった従来のソフトウェアのリスクに加え、LLM は第三者が提供する事前学習済みモデルやデータからの脅威にさらされやすく、改ざんや汚染攻撃によって操作される恐れがあります。オープンアクセス型 LLM やファインチューニング手法の利用、さらにオンデバイス型 LLM の登場は、これらのサプライ チェーン リスクをさらに悪化させています。
安全性の低い出力処理
安全性の低い出力処理、または出力検証の欠如とは、大規模言語モデルが生成した出力に対して、下流にある他のコンポーネントやシステムに渡される前に検証、サニタイズ、処理が不十分である状態を指します。この脆弱性は、プロンプト入力によって制御される LLM 生成コンテンツで悪用され、ユーザーが追加機能に間接的にアクセスできるようにします。不適切な出力処理は、以下のようなセキュリティ問題を引き起こす可能性があります。
- クロスサイト スクリプティング (XSS)
- クロスサイト リクエスト偽造 (CSRF)
- サーバーサイド リクエスト偽造 (SSRF)
- 特権のエスカレーション
- リモート コード実行
この脆弱性の影響を増大させる要因には、以下が含まれます。
- LLM への過剰な権限の付与
- 間接的なプロンプト インジェクション攻撃への脆弱性
- サードパーティ拡張における不十分な入力検証
- 適切な出力エンコーディングの欠如
- LLM 出力の監視とログの不十分さ
- LLM 使用におけるレート感度制限や異常検出の欠如
過剰な主体性
過剰な主体性とは、LLM ベースのシステムが、予期しない、曖昧な、あるいは操作された出力に反応して、損害を引き起こす行動を実行してしまう脆弱性を指します。これは、設計が不十分なプロンプトによるハルシネーションや作話、または悪意あるユーザーによる直接的・間接的なプロンプト インジェクションなどによって引き起こされる可能性があります。根本的な原因としては、過剰な機能性、権限、そして自律性が挙げられます。その影響は、LLM ベースのアプリケーションが連携・操作できるシステムの範囲に応じて、機密性、完全性、可用性といった複数の側面に及ぶ可能性があります。攻撃者はこれらのシステムを操作することで、悪意ある動作を実行させ、重大なセキュリティ リスクをもたらす可能性があります。
生成 AI や LLM のセキュリティ リスクに対処しなければ、組織およびその顧客は、データ侵害、不正アクセス、ならびにコンプライアンス違反といったリスクにさらされる可能性があります。これらのリスクは状況に依存し、組織の運用においてさまざまな側面に影響を及ぼす可能性があります。LLM の急速な普及と生成 AI アプリケーションの進化は、包括的なセキュリティ対策の整備を上回るスピードで進んでおり、その結果、多くのアプリケーションや組織が高リスクな問題に対して脆弱な状態に置かれています。
一般的なリスク対策 (およびそれに伴う欠点)
Anthropic や OpenAI といったフロンティア系のクローズド モデルの提供企業、ならびにオープン ソース プロジェクトでは、これらのセキュリティ脆弱性に対応するため、一定の対策が講じられています。以下では、それらのいくつかを取り上げ、それぞれの利点と限界について見ていきます。
モデルのアライメント (整合性)
- 定義 : 人間の価値観や目標を大規模言語モデル向けにエンコードし (モデルの重みの修正などの微調整)、ビジネス ルールやポリシーに適合するよう、それらを有用で安全かつ信頼できる形にカスタマイズします。
- 利点 : AI モデルを意図された目的に沿って望ましい行動に従わせることで (つまり特定の方法でバイアスをかける)、運用者の目標との整合を促進します。
- 欠点 : 望ましい行動、および望ましくない行動の全範囲を正確に定義することは困難であり、その結果、必要な制約を見落としたり、実質的な整合ではなく表面的な「整合しているように見える状態」を優先してしまったり、より単純な代理目標が用いられる傾向にあります。そのため、アライメントを通して、「ジェイルブレイクに耐性のある」あるいは「完全に整合された」モデルを生み出すことは不可能です。
意図的なシステム プロンプト インジェクション
- 定義 : タスクの主目的の理解、出力の構造化、ユーザー コンテンツの保持、改善の提案、そして明確な推論の確保など、対話全体を通じて AI がどのように振る舞うべきかを導くバックグラウンドで設定された指示を指します。これらの指示は多くの場合、ユーザーの制御外で、ユーザーが提供するすべてのシステム プロンプトに対して意図的かつ自動的に注入されます。
- 利点 : AI モデルのパフォーマンスや挙動を最適化するための詳細な技術的、ドメイン特有かつ関連性の高い情報を提供します。
- 欠点 : LLM は、意図的に注入されたシステム プロンプトに常に一貫して従うとは限りません。また、これらの注入されたシステム プロンプトをリバース エンジニアリングし、指示を回避するための新たな攻撃手法が継続的に開発されています。
ガードレールまたは入出力フィルター
- 定義 : ユーザーと AI モデルの間に配置され、入力および/または出力をフィルタリング、修正、または検証するためのプログラム可能なシステムを指します。これらは組織によって定義された原則のもとで動作し、前処理または後処理のレイヤーとして追加されます (たとえば、モデルへの入力から個人識別情報 (PII) を除外したり、出力から有害な言語をブロックしたりする目的で用いられます)。
- 利点 : 組織が生成 AI を活用しつつ、特定のリスクをプログラムを通して緩和または監視できるようにします。
- 欠点 : 外部 AI システムを囲みこむガードレールでは、LLM の実際の挙動や固有の脆弱性を制御することはできません。また、LLM の前後にレイヤーを追加すると、リクエストのレイテンシやコストが増加します。さらに、誤検知はユーザーにとって煩わしく感じられる場合があります。
これらの手法はいずれも AI セキュリティ全体を構成する重要な要素ではあるものの、それだけで十分とは言えず、限界があることも明らかです。
システム レベルの AI リスク管理
前述した各対策はいずれも全体の一部に過ぎず、さらにこれらのリスク対策では解決されないセキュリティ問題が存在するため、Prediction Guard は AI セキュリティをより体系的な視点で捉える必要があると考えています。LLM (または他の生成 AI モデル) に関連する脅威は、AI 開発ライフサイクルのさまざまな段階で発生する可能性があります。これらの脆弱性を包括的に対処するために、リスクを 「デプロイ前」、「デプロイ時」、「オンライン運用時」 の三つの段階に分類することができます。
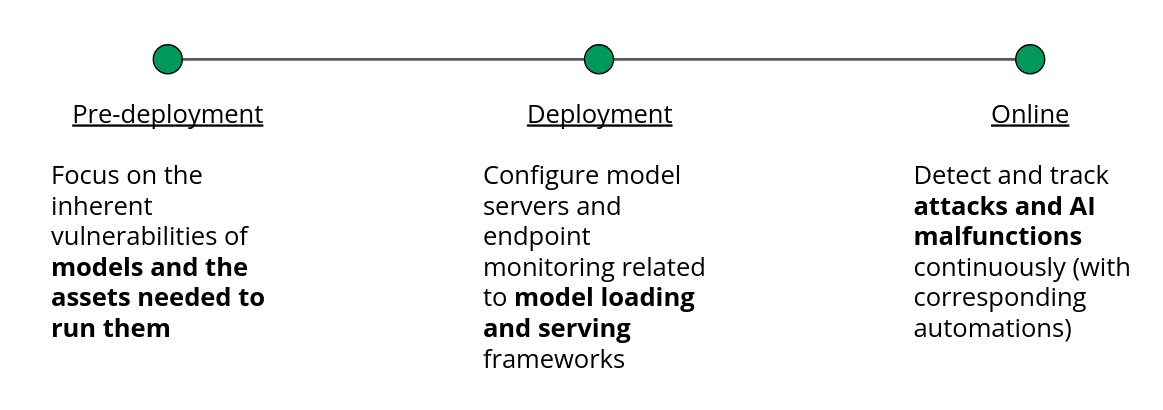
デプロイ前
サプライ チェーンの脆弱性 :
オープンソースの LLM は、pickle ファイルの使用など、モデルの重みのデシリアライズを通じて任意のコードが実行され得ることから、しばしばセキュリティ リスクを持ち込みます。これに対するリスク対策としては、以下のようなものがあります。
- safetensors などの安全なシリアライズ方式を提供するツールを使用する (Hugging Face ドキュメントを参照)
- モデル ファイルに対して静的コード解析を実施する
- ファイルの完全性を確認するために、チェックサムおよびモデル署名を検証する
これらの方法はリスクを減らすものの、完璧ではありません。たとえば、pickle から safetensors へ移行することで、別の脆弱性が新たに生じる可能性もあります (詳細はこちら)。そのため、インフラストラクチャ全体を包括的に評価することが極めて重要です。
モデルの汚染 :
攻撃者は、偏った、あるいは有害な出力を生成するよう意図的に設計された悪意あるデータセットで学習されたモデルをアップロードする可能性があります。これに対抗するためのベストプラクティスには、以下のようなものが含まれます。
- デプロイ前に敵対的データセットでモデルをテストする
- プロンプトのわずかな変更が出力にどのような影響を与えるかを評価するため、プロンプト感度分析を実施する (Hugging Face のブログ記事を参照)
- 意図しないモデルの意思決定を特定するために、エージェント的な挙動をシミュレーションする (Wired 記事を参照)
デプロイ時
安全なモデルの読み込みと設定 :
デプロイ時には、モデルのパラメータの不適切な保管や、安全性の低い読み込み方法といったリスクが存在します。これに対する推奨事項としては、以下のようなものがあります。
- 機密性の高い設定情報を安全に保管する (たとえば、top-k の設定は悪用を防ぐために非公開にする)
- コード実行に関する脆弱性を防ぐために、安全なチェックポイント (例 : from_flax) からモデルを読み込む
モデルを分離された環境 (サンドボックス) で実行することで、外部からの脅威にさらされるリスクを低減できます。また、Python の依存関係に対して厳格なホワイトリストを実装し、それらを頻繁に更新することで、安全なエコシステムを維持することができます。
オンライン運用時
オンライン運用時におけるリスクは、モデルとのリアルタイムなやり取りに関係します。これらのリスクをより適切に管理するため、入力レベルの脅威と出力レベルの脅威にさらに分類することができます。
入力レベルの脅威 :
- 機密データの漏洩 : ブラックボックス型 API に、機密情報や個人データを送信してしまうこと (OWASP 生成 AI リスク ガイド)
- プロンプト インジェクション攻撃 : 意図しない出力を生成させるために、プロンプトを操作する攻撃手法(OWASP 生成 AI リスク ガイド)
入力レベルのリスク対策 :
- 悪意のある入力を遮断するプロンプト インジェクション検知システム。
- 機密情報を保護するための差分プライバシー技術。
- 多言語およびマルチ モーダル入力に対する保護機構の統合。
出力レベルの脅威 :
- LLM の出力には、コード、SQL クエリ、マークダウン、スクリプトなどが含まれる場合があり、これらが実行または表示されることで、リモート コード実行などの脆弱性を引き起こす可能性があります。
- LLM は、不適切または有害なテキスト (暴言、ヘイト スピーチなど) を出力する可能性があります。
- モデルの出力には、事実とは異なる、あるいは文脈に対して適切でない情報が含まれることがあります。
出力レベルのリスク対策 :
アウトプットの管理と正確性の確認が不可欠です。主な指標には以下が含まれます :
- 生成されたコンテンツに対して、有害性および危険カテゴリをチェックすること。
- 特に検索拡張生成 (RAG) システムにおいて、回答の事実正確性を検証すること。
- トレーサビリティおよび説明責任を確保するために、出力に透かしを付与すること。
システム レベルの AI セキュリティのために構築されたプラットフォーム
これらすべてのリスク対策の戦略は非常に多岐にわたり、AI を取り巻く懸念も日々進化しています。Prediction Guard は、高度なセキュリティとプライバシーを要する AI アプリケーションに対して、適切なリスク対策を容易に実装できるよう、ゼロから設計されています。これらのリスク対策はプラットフォームにシームレスに統合されています。
エクセルソフトは、Prediction Guard の販売代理店として、評価から導入までのプロセスを日本語で支援しています。お見積りに関する依頼、デモのご要望などございましたら、お気軽にご相談ください。
お問い合わせはこちら。
この記事は、Prediction Guard 社の Web サイトで公開されている「System level security for open source AI models」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
