インテル® コンパイラーには並列に実行できるコード構造を自動的に検出して最適化するいくつかの方法 (自動ベクトル化や自動並列化など) が用意されていますが、ほとんどの手法ではコードの変更が必要です。挿入するプラグマや関数は、並列スレッドの分解やスケジュール実行を実際に行うランタイム・ライブラリー (OpenMP*、インテル® スレッディング・ビルディング・ブロック (インテル® TBB)、Win32* API など) に依存します。各手法の主な違いは、実行のために提供される制御のレベルです。一般に、より多くの制御が提供されるほど、より多くのコードの変更が必要になります。
OpenMP を使用した並列化
OpenMP は、移植性に優れたマルチスレッド・アプリケーション開発のための業界標準規格です。インテル® C++ コンパイラーは、OpenMP C/C++ バージョン 3.0 の仕様をサポートしています。詳細は、OpenMP Web サイト (http://www.openmp.org/) を参照してください。OpenMP を使用した並列化は、ユーザーが OpenMP 宣言子を使用して制御します。このアプローチは細粒度 (ループレベル) および粗粒度 (関数レベル) のスレッド化に効果的です。OpenMP 宣言子は、シリアル・アプリケーションを並列アプリケーションに変換する容易でパワフルな方法を提供し、マルチコアシステムの並列実行から大きなパフォーマンス・ゲインを引き出す可能性をもたらします。宣言子は、/Qopenmp コンパイラー・オプションを指定すると有効になります。このコンパイラー・オプションを指定しなかった場合、宣言子は無視されます。つまり、同じソースコードからアプリケーションのシリアルバージョンと並列バージョンの両方をビルドできます。共有メモリー並列コンピューターでは、シリアル実行と並列実行の単純比較ができます。
次の表に、一般的に使用される OpenMP 宣言子を示します。
| 宣言子 |
説明 |
| #pragma omp parallel for [clause] ... for - loop |
プラグマ直後のループを並列化します。 |
| #pragma omp parallel sections [clause] ... { [#pragma omp section structured-block] ... } |
並列チームのスレッドに異なるセクションの実行を分配します。各構造ブロックは、チームの 1 つのスレッドにより、その暗黙的なタスクのコンテキスト内で一度実行されます。 |
| #pragma omp master structured-block |
マスター構造内に含まれるコードをスレッドチームのマスタースレッドで実行します。 |
| #pragma omp critical [ (name) ] structured-block |
構造ブロックへの排他制御アクセスを提供します。プログラムの任意の場所で、一度に 1 つのクリティカル・セクションのみ実行できます。 |
| #pragma omp barrier |
並列領域内の複数のスレッドの実行を同期させます。バリアーの前のすべてのコードが全スレッドで完了するまで待機します。同期が完了するまでどのスレッドも barrier 宣言子の後のコードは実行しません。 |
| #pragma omp atomic expression-statement |
ハードウェア同期プリミティブによる排他制御を提供します。クリティカル・セクションはコードのブロックに対する排他制御アクセスを提供しますが、atomic 宣言子は単一のステートメントに対する排他アクセスを提供します。 |
| #pragma omp threadprivate (list) |
スレッドごとに 1 つのインスタンスの (つまり、各スレッドは変数の個々のコピーで動作) 複製するグローバル変数のリストを指定します。 |
例 1:
void sp_1a(float a[], float b[], int n) {
int i;
#pragma omp parallel shared(a,b,n) private(i)
{
#pragma omp for
for (i = 0; i < n; i++)
a[i] = 1.0 / a[i];
#pragma omp single
a[0] = a[0] * 10;
#pragma omp for nowait
for (i = 0; i < n; i++)
b[i] = b[i] / a[i];
}
}
icl /c /Qopenmp par1.cpp
par2.cpp(5): (col. 5) remark: OpenMP 定義ループが並列化されました。
par2.cpp(10): (col. 5) remark: OpenMP 定義ループが並列化されました。
par2.cpp(3): (col. 3) remark: OpenMP 定義領域が並列化されました。
/Qopenmp-report[n] (n は 0 から 2) コンパイラー・オプションは、OpenMP パラレライザーの診断メッセージのレベルを制御します。このオプションを使用するには、/Qopenmp オプションを指定する必要があります。n を指定しない場合、デフォルトの /Qopenmp-report1 が使用され、正常に並列化されたループ、領域、セクションを示す診断メッセージが表示されます。
コードには宣言子のみが挿入されるため、インクリメンタルにコードを変更することができます。インクリメンタルなコードの変更は、シリアルの一貫性の維持に役立ちます。コードを 1 つのプロセッサーで実行すると、変更前のソースコードを実行したときと同じ結果が得られます。OpenMP は、複数のプラットフォームとオペレーティング・システムをサポートするシングル・ソースコード・ソリューションです。また、OpenMP ランタイムにより適切なコア数が自動的に選択されるため、コア数を特定する必要はありません。
OpenMP バージョン 3.0 では、OpenMP が最もよく使用されるループレベルの並列化に加え、新しくタスクレベルの並列化構造が追加され、関数の並列化が容易になりました。タスクモデルでは、効率的に並列化することが困難な、再帰などの不規則なパターンの動的データ構造や複雑な制御構造を含むプログラムを並列化できます。task プラグマは並列領域のコンテキスト内で動作し、明示的なタスクを作成します。並列領域内に task プラグマが存在すると、タスクブロックの内側のコードは、概念的には並列領域を実行するスレッドのうちの 1 つによって実行されるようにキューイングされます。シーケンシャルなセマンティクスを保持するために、並列領域内でキューイングされているすべてのタスクは並列領域の最後までに完了します。開発者は、明示的なタスク間、および明示的なタスクの内側と外側のコード間で依存性が存在しないこと、または適切に同期されることを確認する必要があります。
例 2:
#pragma omp parallel
#pragma omp single
{
for(int i = 0; i < size; i++)
{
#pragma omp task
setQueen (new int[size], 0, i, myid);
}
}
インテル® C++ コンパイラーの並列化用言語拡張
インテル® コンパイラーは、C/C++ 言語拡張を使用して、並列プログラミングを容易にします。このバージョンのコンパイラーには、4 つのキーワードが用意されています。
- __taskcomplete
- __task
- __par
- __critical
アプリケーションでこれらのキーワードを使用して並列化を行うには、コンパイル時に /Qopenmp コンパイラー・スイッチを指定する必要があります。コンパイラーは、適切なランタイム・サポート・ライブラリーにリンクします。実際の並列化のレベルは、ランタイムシステムによって管理されます。この並列拡張機能は、OpenMP 3.0 ランタイム・ライブラリーを利用しますが、OpenMP プラグマと宣言子を使用することなく、より自然な C/C++ コードを保つことができます。並列拡張機能と OpenMP 構造のマッピングは次のとおりです。
| 並列拡張 |
OpenMP |
| __par |
#pragma omp parallel for |
| __critical |
#pragma omp critical |
| __taskcomplete S1 |
#pragma omp parallel #pragma omp single { S1 } |
| __task S2 |
#pragma omp task { S2 } |
キーワードは、文のプリフィックスとして使用されます。
例 3:
__par for (i = 0; i < size; i++)
setSize (new int[size], 0, i)
__taskcomplete {
__task sum(500, a, b, c);
__task sum(500, a+500, b+500, c+500)
)
if ( !found )
__critical item_count++;
インテル® スレッディング・ビルディング・ブロック (インテル® TBB)
インテル®TBB は、C++ プログラムを並列化する豊富な手法を提供する、マルチコア・プロセッサーのパフォーマンスの活用に役立つライブラリーです。プラットフォームの詳細を抽象化する、より高いレベルのタスクベースの並列化と、パフォーマンスとスケーラビリティーのためのスレッド化メカニズムを示します。オブジェクト指向や C++ の汎用フレームワークにも適合します。インテル®TBB は、ランタイムベースのプログラミング・モデルを使用し、開発者に標準テンプレート・ライブラリー (STL) と同じようなテンプレート・ライブラリーをベースとした汎用並列アルゴリズムを提供します。
例 4:
#include "tbb/ParallelFor.h"
#include "tbb/BlockedRange2D.h"
void solve()
{
parallel_for (blocked_range<size_t>(0, size, 1), [](const blocked_range<int> &r)
{
for (int i = r.begin(); i != r.end(); ++i)
setQueen(new int[size], 0, (int)i);
}
}
インテル®TBB タスク・スケジューラーはロードバランスを自動的に行うため、開発者が複雑なタスクを実行する必要はありません。プログラムを小さなタスクに分割することによって、インテル®TBB スケジューラーは作業が均等に分散されるようにタスクをスレッドに割り当てます。
インテル®C++ コンパイラーとインテル®TBB はどちらも、新しい C++0x ラムダ関数をサポートしています。これにより、STL とインテル®TBB のアルゴリズムがより使いやすくなります。インテルが提供するラムダ式を使用するには、/Qstd=c++0X コンパイラー・オプションを指定してコードをコンパイルしてください。
Win32 スレッド化 API と Pthreads*
場合によっては、ネイティブスレッド化 API の柔軟性を利用したいこともあるでしょう。この手法の主な利点は、この記事でこれまでに説明した抽象化手法よりも、スレッド化をより柔軟により細かく制御できることです。ただし、他の手法ではランタイムシステムが制御する作成、スケジューリング、同期、ローカルストレージ、ロードバランス、破棄などのスレッド実装作業をこの手法ではすべて開発者が行う必要があるため、実装に必要なコード量は多くなります。さらに、正しい数のスレッドを作成するために、利用可能なコア数を特定する必要があります。特にこの作業は、プラットフォームに依存しないソリューションでは非常に複雑になります。
例 5:
void run_threaded_loop (int num_thr, size_t size, int _queens[])
{
HANDLE* threads = new HANDLE[num_thr];
thr_params* params = new thr_params[num_thr];
for (int i = 0; i < num_thr; ++i)
{
// Give each thread equal number of rows
params[i].start = i * (size / num_thr);
params[i].end = params[i].start + (size / num_thr);
params[i].queens = _queens;
// Pass argument-pointer to a different
// memory for each thread's parameter to avoid data races
threads[i] = CreateThread (NULL, 0, run_solve,
static_cast<void *> (¶ms[i]), 0, NULL);
}
// Join threads: wait until all threads are done
WaitForMultipleObjects (num_thr, threads, true, INFINITE);
// Free memory
delete[] params;
delete[] threads;
}
スレッド化ライブラリー
アプリケーションに並列化を施す別の方法は、インテル® マス・カーネル・ライブラリー (インテル® MKL。インテル®Parallel Composer には含まれていません) やインテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) などのスレッド化ライブラリーを使用することです。インテル®MKL は、スレッド化に OpenMP を使用して、パフォーマンスを最大限に引き出すように高度に最適化されたスレッド化演算ルーチンを提供します。スレッド化されたインテル®MKL 関数を利用するには、OMP_NUM_THREADS 環境変数に 2 以上の値を設定して指定するだけです。インテル®MKL には、シリアルと並列のどちらで計算を実行するかを決定する内部的なしきい値があります。開発者は OpenMP API の omp_set_num_threads 関数を使用してしきい値を手動で設定することもできます。インテル®MKL の並列化については、インテル®MKL 9.0 Windows 版のオンライン・テクニカル・ノート (英語) やインテル® MKL 10.0 のスレッド化に関する別の記事 (英語) も参照してください。
インテル®IPP は、マルチメディア、データ処理、通信アプリケーション向けに高度に最適化された、ソフトウェア関数の広範囲なマルチコア対応ライブラリーです。インテル®IPP も、スレッド化に OpenMP を使用しています。インテル®IPP のスレッド化と OpenMP のサポートについては、別の記事 (英語) も参照してください。
インテル®C++ コンパイラーも、数学演算と超越演算のデータ並列パフォーマンスにはインテル®IPP を使用して STL valarray を実装しています。C++ の valarray テンプレート (http://www.aoc.nrao.edu/~tjuerges/ALMA/STL/html/classstd_1_1valarray.html) には、ハイパフォーマンス・コンピューティング向けの配列演算が含まれています。これらの演算は、ベクトル化などの低レベルのハードウェア機能を活用するように設計されています。インテルの valarray は、最適化された代替の valarray ヘッダーファイルを使用して、インテル®IPP 最適化バージョンの valarray にリンクするように実装されているので、ソースコードを変更する必要はありません。インテルのパフォーマンス最適化ヘッダーファイルを使用して valarray ループを最適化するには、/Quse-intel-optimized-headers コンパイラー・オプションを指定します。
自動並列化
自動並列化はインテル®C++ コンパイラーの機能です。自動並列化モードでは、コンパイラーはプログラムの本来の並列性を自動的に検出します。自動パラレライザーは、アプリケーション・ソースコード中のループのデータフローを解析して、安全かつ効率的に並列実行可能なループに対するマルチスレッド・コードを生成します。データの依存性が存在する場合、ループを自動並列化するためにはループを再構成する必要があります。
自動並列化モードでは、並列化に関するすべての決定はコンパイラーによって行われ、開発者が並列化するループを制御することはできません。自動並列化を OpenMP と組み合わせると、より高いパフォーマンスを得ることができます。OpenMP と自動並列化を組み合わせた場合、OpenMP 宣言子を含むループの並列化には OpenMP が、OpenMP 以外のループの並列化には自動並列化がそれぞれ使用されます。自動並列化を有効にするには、/Qparallel コンパイラー・オプションを指定してください。
例 6:
#define N 10000
float a[N], b[N], c[N];
void f1() {
for (int i = 1; i < N; i++)
c[i] = a[i] + b[i];
}
> icl /c /Qparallel par1.cpp
par1.cpp(5): (col. 4) remark: ループが自動並列化されました。
デフォルトでは、自動パラレライザーは正常に自動並列化されたループを表示します。/Qpar-report[n] オプション (n は 0 から 3) を指定すると、自動パラレライザーは自動並列化されたループと自動並列化に失敗したループに関する診断メッセージを表示します。例えば、/Qpar-report3 を指定すると、正常に自動並列化されたループと自動並列化に失敗したループの診断メッセージに加えて、自動並列化を妨げると判明または想定した依存関係に関する追加情報を表示します。この診断情報は、自動並列化するループを再構成するときに役立ちます。
自動ベクトル化
ベクトル化は、インテル® プロセッサー上でループのパフォーマンスを最適化する手法です。ベクトル化手法で定義される並列化は、プロセッサーの SIMD ハードウェアで実現可能なベクトルレベルの並列処理 (VLP) に基づきます。インテル®C++ コンパイラーの自動ベクトライザーは、並列で実行できるプログラム内の低レベルの演算を検出して、1 つの演算で 1、2、4、8、または 16 バイト (将来のプロセッサーでは 32 および 64 バイトに拡張) のデータ要素を処理するようにシーケンシャル・コードを変換します。コンパイラーで自動的にベクトル化するには、ループは独立している必要があります。自動ベクトル化は、前述した自動並列化や OpenMP などの他のスレッドレベルの並列化手法と組み合わせて使用できます。ほとんどの浮動小数点アプリケーションと一部の整数アプリケーションは、ベクトル化によってパフォーマンスが向上します。デフォルトのベクトル化レベルは /arch:SSE2 で、インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) 向けのコードを生成します。デフォルト以外のターゲットで自動ベクトル化を有効にするには、/arch (例: /arch:SSE4.1) または /Qx (例: /QxSSE4.2, QxHost) コンパイラー・オプションを指定してください。
下記の図の左は、ベクトル化なしでループの反復をシリアル実行しているため、SIMD レジスターの多くが使用されていません。図の右は、ベクトル化によりループの各反復について配列の 4 つの要素が並列に実行され、SIMD レジスターがすべて使用されています。
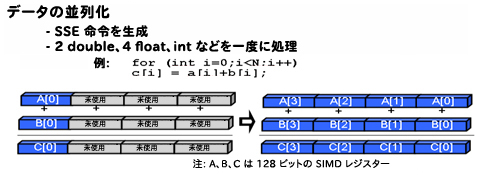
図 1. ループの反復とベクトル化
例 7:
#define N 10000
float a[N], b[N], c[N];
void f1() {
for (int i = 1; i < N; i++)
c[i] = a[i] + b[i];
}
> icl /c /QxSSE4.2 par1.cpp
par1.cpp(5): (col. 4) remark: ループがベクトル化されました。
デフォルトでは、ベクトライザーはベクトル化されたループを表示します。/Qvec-report[n] オプション (n は 0 から 5) を指定すると、ベクトライザーはベクトル化されたループとベクトル化されなかったループ、その理由などの診断情報を表示します。たとえば、/Qvec-report5 オプションを指定すると、ベクトル化されなかったループとベクトル化されなかった理由を表示します。この診断情報は、ベクトル化するループを再構成するときに役立ちます。