インテル® Advisor 2017 for Windows® ベクトル化アドバイザー 入門ガイド
インテル® Advisor には、Fortran、C および C++ (ネイティブ/マネージド) アプリケーションでインテル® Xeon® プロセッサーのような最新のプロセッサーのパフォーマンスを最大限に引き出すことができるように支援する 2 つのツール (ベクトル化最適化ツールとスレッド化設計/プロトタイプ生成ツール) が含まれています。このトピックでは、Windows® プラットフォームでのベクトル化アドバイザー GUI の使用方法を説明します。
主な機能
ベクトル化アドバイザーには次のような機能があります。
- 調査レポート (Survey Report) - コンパイラー・レポート・データとパフォーマンス・データを 1 カ所に統合します。調査レポートから、次のことが分かります。
- どのベクトル化により最も大きな利点が得られるか
- ベクトル化されたループの利点が得られているか (得られていない場合、その理由)
- ベクトル化されなかったループとベクトル化されたループ、ベクトル化 (およびより適切なベクトル化) の推定予想パフォーマンス・ゲイン
- ベクトル化されたループによりアクセスされたデータの構成と再構成による推定予想パフォーマンス・ゲイン
調査レポートからは、次のことも分かります。
- ベクトル化問題の解決方法についての分かりやすいコード固有の推奨事項
- ソースコードおよびアセンブリー・コードの迅速な可視化
- トリップカウント (Trip Counts) 解析 - ループの呼び出し回数および実行回数 (コールカウント/ループカウントおよび反復カウントと呼ばれることもあります) を動的に識別します。すでに並列化されているループの最適化に加えて、特定のループのベクトル化方法に関してより適切な決定を行うには、調査レポートのこの追加情報を使用します。
- 依存性レポート (Dependencies Report) - 安全のため、コンパイラーは保守的にデータ依存性を想定します。想定された依存性によりコンパイラーがベクトル化しないループの実際のデータ依存性を確認するには、依存性に注目した詳細レポート (Refinement Report) を使用します。実際の依存性が検出された場合、依存性の解決を支援する追加の詳細が提供されます。このレポートを利用することで、ベクトル化を行うと安全でなくなる実際のデータ依存性を識別して区別できます。
- メモリー・アクセス・パターン (MAP) レポート (Memory Access Patterns (MAP) Report) - 連続していないメモリーアクセスやユニット・ストライド・アクセスと非ユニット・ストライド・アクセスのような、さまざまなメモリー問題をチェックするには、マップに注目した詳細レポートを使用します。このレポートを利用することで、重要なベクトルコードの実行速度を低下させたり、コンパイラーによる自動ベクトル化の妨げとなる原因を排除します。
必要条件
正確で完全なベクトル化アドバイザーの解析結果が得られるアプリケーションを作成するには、以下の設定を使用してリリースモードでアプリケーションの最適化されたバイナリーをビルドします。
操作
最適な C/C++ 設定
完全なデバッグ情報を要求します (コンパイラーおよびリンカー)。
コマンドライン:
- /ZI
- /DEBUG
Microsoft® Visual Studio® IDE:
- [C/C++] > [General (全般)] > [Debug Information Format (デバッグ情報の書式)] > [Program Database (/Zi) (プログラム・データベース (/Zi))]
- [Linker (リンカー)] > [Debugging (デバッグ)] > [Generate Debug Info (デバッグ情報の作成)] > [Yes (/DEBUG) (はい (/DEBUG))]
中程度の最適化を要求します。
コマンドライン: /O2 またはそれ以上
Visual Studio® IDE: [C/C++] > [Optimization (最適化)] > [Optimization (最適化)] > [Maximize Speed (/O2) (実行速度 (/O2))] またはそれ以上
コンパイラー診断を生成します (インテル® コンパイラー 15.0 で必要、インテル® コンパイラー 16.0 以降は不要)。
コマンドライン: /Qopt-report:5
Visual Studio® IDE: [C/C++] > [Diagnostics [Intel C++] (診断 [インテル(R) C++])] > [Optimization Diagnostic Level (最適化診断レベル)] > [Level 5 (/Qopt-report:5) (レベル 5 (/Qopt-report:5))]
ベクトル化を有効にします。
コマンドライン: /Qvec
SIMD ディレクティブを有効にします。
コマンドライン: /Qsimd
OpenMP* ディレクティブに基づくマルチスレッド・コードの生成を有効にします。
コマンドライン: /Qopenmp
Visual Studio® IDE: [C/C++] > [Language [Intel C++] (言語 [インテル(R) C++])] > [OpenMP Support (OpenMP* サポート)] > [Generate Parallel Code (/Qopenmp) (並列コードの生成 (/Qopenmp))]
操作
最適な Fortran 設定
完全なデバッグ情報を要求します (コンパイラーおよびリンカー)。
コマンドライン:
- /debug=full
- /DEBUG
Visual Studio® IDE:
- [Fortran] > [General (全般)] > [Debug Information Format (デバッグ情報の書式)] > [Full (/debug=full) (フル (/debug=full))]
- [Linker (リンカー)] > [Debugging (デバッグ)] > [Generate Debug Info (デバッグ情報の作成)] > [Yes (/DEBUG) (はい (/DEBUG))]
中程度の最適化を要求します。
コマンドライン: /O2 またはそれ以上
Visual Studio® IDE: [Fortran] > [Optimization (最適化)] > [Optimization (最適化)] > [Maximize Speed (実行速度)] またはそれ以上
コンパイラー診断を生成します (インテル® コンパイラー 15.0 で必要、インテル® コンパイラー 16.0 以降は不要)。
コマンドライン: /Qopt-report:5
Visual Studio® IDE: [Fortran] > [Diagnostics (診断)] > [Optimization Diagnostic Level (最適化診断レベル)] > [Level 5 (/Qopt-report:5) (レベル 5 (/Qopt-report:5))]
ベクトル化を有効にします。
コマンドライン: /Qvec
SIMD ディレクティブを有効にします。
コマンドライン: /Qsimd
OpenMP* ディレクティブに基づくマルチスレッド・コードの生成を有効にします。
Visual Studio® IDE: [Fortran] > [Language (言語)] > [Process OpenMP Directives (OpenMP* ディレクティブの処理)] > [Generate Parallel Code (/Qopenmp) (並列コードの生成 (/Qopenmp))]
追加の操作: インテル® Advisor でアプリケーションを解析する前に、アプリケーションが正しく動作することを確認します。
環境の設定
- インテル® Advisor 環境の設定は、advixe-gui コマンドを使用してインテル® Advisor スタンドアロン GUI を起動する (または advixe-cl コマンドを使用してコマンドライン・インターフェイスを実行する) 場合にのみ必要です。インテル® Advisor 環境を設定するには、<advisor-install-dir>\advixe-vars.bat または <parallel-studio-install-dir>\psxevars.bat を実行します。
- <advisor-install-dir> および <parallel-studio-install-dir> のデフォルトのインストール・パスは、C:\Program Files (x86)\IntelSWTools\ です (システムによっては、フォルダー名が Program Files (x86) ではなく Program Files になります)。
はじめに
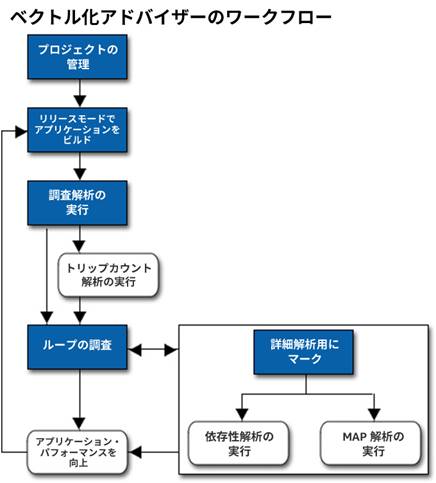
インテル® Advisor のベクトル化アドバイザーを使用するには、以下の操作を行います (白のブロックはオプションです)。
インテル® Advisor の起動
スタンドアロン GUI インターフェイスの場合は、次のいずれかの操作を行います。
- advixe-gui コマンドを実行します。
- Microsoft® Windows® 7 の [スタート] メニューから、[Intel Parallel Studio XE 201n (インテル(R) Parallel Studio XE 201n)] > [Analyzers (アナライザー)] > [Advisor (アドバイザー)] を選択します。
- Microsoft® Windows® 8/8.1/10 の [すべてのアプリ] 画面から、[Intel Parallel Studio XE 201n (インテル(R) Parallel Studio XE 201n)] > [Intel Advisor 201n (インテル(R) Advisor 201n)] を選択します。
インテル® Advisor が Visual Studio® IDE に統合されている場合: Visual Studio® IDE でソリューションを開きます。
プロジェクトの管理
スタンドアロン GUI の場合:
- [File (ファイル)] > [New (新規作成)] > [Project… (プロジェクト…)] を選択して (または [Welcome (ようこそ)] ページで [New Project… (新規プロジェクト…)] をクリックして)、[Create a Project (プロジェクトの作成)] ダイアログボックスを開きます。
- プロジェクトの名前と場所を指定したら、[Create Project (プロジェクトの作成)] ボタンをクリックして [Project Properties (プロジェクト・プロパティー)] ダイアログボックスを開きます。
- [Analysis Target (解析ターゲット)] タブの左側で、[Survey Hotspots Analysis (調査 hotspot 解析)] タイプが選択されていることを確認します。
- 適切なパラメーターを設定します。(バイナリー/シンボル検索およびソース検索ディレクトリーの設定はオプションです。)
- [OK] をクリックして、[Project Properties (プロジェクト・プロパティー)] ダイアログボックスを閉じます。
Visual Studio® IDE の場合:
- [プロジェクト] > [Intel Advisor version Project Properties… (インテル(R) Advisor version プロジェクトのプロパティー…)] を選択して、[Project Properties (プロジェクト・プロパティー)] ダイアログボックスを開きます。
- [Analysis Target (解析ターゲット)] タブの左側で、[Survey Hotspots Analysis (調査 hotspot 解析)] タイプが選択されていることを確認します。
- 適切なパラメーターを設定します。(バイナリー/シンボル検索およびソース検索ディレクトリーの設定はオプションです。)
- [OK] をクリックして、[Project Properties (プロジェクト・プロパティー)] ダイアログボックスを閉じます。
- ほかのベクトル化解析タイプを実行する予定がある場合は、それらのパラメーターも設定します (可能な場合)。
- 可能な場合は、ほかの解析タイプで [Inherit settings from Survey Hotspots Analysis Type (調査 hotspot 解析タイプから設定を継承する)] チェックボックスをオンにします。
- [Survey Trip Counts Analysis (調査トリップカウント解析)] タイプには、[Survey Hotspots Analysis (調査 hotspot 解析)] タイプと同様のパラメーターがあります。
- [Dependencies Analysis (依存性解析)] および [Memory Access Patterns Analysis (メモリー・アクセス・パターン解析)] タイプは、[Survey Hotspots Analysis (調査 hotspot 解析)] タイプよりも多くのリソースを消費します。これらの詳細解析に時間がかかる場合は、ワークロードを減らすことを検討してください。
- 可能性のある依存関係をすべて検出するには、[Dependencies Analysis (依存性解析)] タイプで [Track stack variables (スタック変数を追跡する)] を選択します。
- 必要な場合は、[Workflow (ワークフロー)] ペインの上部のタブをクリックして、[Vectorization Workflow (ベクトル化ワークフロー)] と [Threading Workflow (スレッド化ワークフロー)] を切り替えます。
調査解析の実行
[Vectorization Workflow (ベクトル化ワークフロー)] の [Survey Target (調査ターゲット)] で、![]() コントロールをクリックして、アプリケーションの実行中に調査データを収集します。
コントロールをクリックして、アプリケーションの実行中に調査データを収集します。
[Vectorization Workflow (ベクトル化ワークフロー)] が表示されていない場合は、次の操作を行います。
- [ソリューション エクスプローラー] で、プロジェクトを右クリックします。
- [Intel Advisor 201n (インテル(R) Advisor 201n)] > [Start Survey Analysis (調査解析の開始)] を選択します。
インテル® Advisor がデータを収集すると、次のような [Survey Report (調査レポート)] が表示されます。
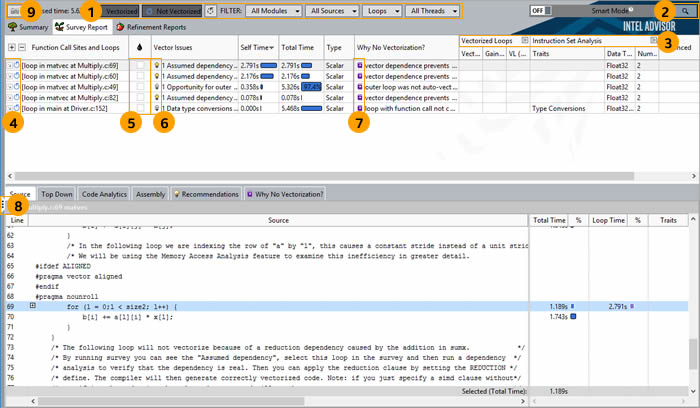
最も重要なデータに注目できるように、次のコントロールを含む、多くのコントロールが用意されています。
- さまざまな [Filter (フィルター)] コントロール (ボタンおよびドロップダウン・リスト) をクリックすると、条件に基づいて表示されるデータを一時的に制限します。
- [Search (検索)] コントロールをクリックすると、特定のデータを検索します。
- [Expand/Collapse (展開/折りたたみ)] コントロールをクリックすると、列のセットを表示/非表示にします。
- [Survey Report (調査レポート)] の上部のループデータ行をクリックすると、[Survey Report (調査レポート)] の下部にループ固有のデータを表示します。ループデータ行をダブルクリックすると、[Survey Source (調査ソース)] ウィンドウを表示します。
- チェックボックスをクリックすると、より詳細な解析のためにループをマークします。
- 存在する場合、
 コントロールをクリックすると、[Recommendations (推奨事項)] ペインにコード固有の問題の解決方法が表示されます。
コントロールをクリックすると、[Recommendations (推奨事項)] ペインにコード固有の問題の解決方法が表示されます。
- 存在する場合、
 コントロールをクリックすると、[Compiler Diagnostic Details (コンパイラー診断詳細)] ペインにコード固有の問題の解決方法が表示されます。
コントロールをクリックすると、[Compiler Diagnostic Details (コンパイラー診断詳細)] ペインにコード固有の問題の解決方法が表示されます。
- コントロールをクリックすると、[Workflow (ワークフロー)] ペインを表示/非表示にします。
- コントロールをクリックすると、結果のスナップショットを保存して後から表示できます。
トリップカウント解析の実行
このステップはオプションです。
トリップカウント解析を実行する前に、[Survey Trip Counts Analysis (調査トリップカウント解析)] タイプで適切な [Project Properties (プロジェクト・プロパティー)] を設定していることを確認します。(同じアプリケーションを使用しますが、可能な場合は入力データセットをより小さくします。)
[Vectorization Workflow (ベクトル化ワークフロー)] の [Find Trip Counts (トリップカウントの検索)] で、![]() コントロールをクリックして、アプリケーションの実行中にトリップカウントを収集します。
コントロールをクリックして、アプリケーションの実行中にトリップカウントを収集します。
インテル® Advisor がデータを収集すると、[Survey Report (調査レポート)] に [Trip Counts (トリップカウント)] 列が追加されます。[Median (中)] データはデフォルトで表示されます。[Min (最小)]、[Max (最大)]、[Call Count (コールカウント)]、および [Iteration Duration (反復期間)] データは列セットを拡張すると表示されます。
トリップ・カウント・データを使用して、次の操作を行うことができます。
- トリップカウントが非常に小さなループおよびトリップカウントがベクトル長の倍数でないループの検出。
- より詳細な並列処理粒度の解析。
ループの調査
[Survey Report (調査レポート)] は、次の情報を含む、豊富な情報を提供します。
- インテル® コンパイラーのベクトル化レポートおよび最適化レポートからの重要な情報
- レポートの上部で選択されたデータ行のソースとアセンブリー・コード
- レポートの上部で選択されたデータ行のコード固有の問題の解決方法 ([Recommendations (推奨事項)] および [Compiler Diagnostic Details (コンパイラー診断詳細)] ペイン)
- [Self Time (セルフ時間)] と [Total Time (合計時間)] の観点から最もホットなループに特に注目してください。これらのループを最適化すると最も効果があります。最内ループおよび最内ループに近いループは、多くの場合、ベクトル化に適した候補です。[Total Time (合計時間)] の長い最外ループは、多くの場合、スレッドによる並列化に適した候補です。
- アプリケーションで最適な [Vector ISA (ベクトル ISA)] が使用されているか、またはマスクやギャザー操作のようにベクトル化で問題となる重い操作がないか確認します。
- モデル化された [Gain Estimate (ゲイン推定)] と [Vector Instruction Set (ベクトル命令セット)] から推定されるゲインを比較して、最適なスピードアップが得られるようにします。例えば、32 ビット整数をインテル® アドバンスト・ベクトル・エクステンション 2 (インテル® AVX2) で処理するとパフォーマンス・ゲインは 8 倍になります。[Gain Estimate (ゲイン推定)] が [Vector ISA (ベクトル ISA)] の予想ゲインよりも大幅に低い場合、重いベクトル操作の排除、データのアライメント、ループの書き直しによる制御フロー節の削除を行い、すでにベクトル化されているループを最適化することを検討してください。
- コンパイラーがソースループをピールループやリマインダー・ループにピールしている場合、ベクトル化されているループは最適なパフォーマンスを達成できません。ピールループやリマインダー・ループがループ実行時間のほとんどを占めている場合、データのアライメントやループ反復数の変更を行うとパフォーマンスの向上に役立ちます。
[Survey Report (調査レポート)] のデータを調査した後、いくつかの選択肢があります。
調査の結果
行う操作
すべてのループが適切にベクトル化され、最適なパフォーマンスが得られています。
操作は完了です。何も行う必要はありません。
1 つ以上のループが適切にベクトル化されず、最適なパフォーマンスが得られていません。
- [Recommendations (推奨事項)] および [Compiler Diagnostic Details (コンパイラー診断詳細)] 情報を使用して、アプリケーションのパフォーマンスを向上します。
- 変更したコードをリビルドします。
- 別の調査解析を実行して、すべてのループが適切にベクトル化され、最適なパフォーマンスが得られているか確認します。
ほかの情報が必要 (例えば、想定される依存性コンパイラー診断がある、またはギャザー、インサート、シャッフルのようなコストのかかるメモリー命令があるため)。
次の操作を行い、調査を続行します。
- より詳細な解析を行う 1 つ以上のループをマークします。
- 実行する詳細解析で適切な [Project Properties (プロジェクト・プロパティー)] を設定します。
- 1 つ以上の詳細解析を実行します。
パフォーマンスを向上する余地があると表示された場合、次の操作を行います。
- パフォーマンスを向上します。
- 変更したコードをリビルドします。
- 別の調査解析を実行して、アプリケーションが正しく実行され、すべてのテストケースをパスし、すべてのループが適切にベクトル化され、最適なパフォーマンスが得られているか確認します。
依存性解析の実行
このステップはオプションです。
依存性解析を実行する前に、次の項目を確認します。
- [Dependencies Analysis (依存性解析)] タイプで適切な [Project Properties (プロジェクト・プロパティー)] を設定します。(同じアプリケーションを使用しますが、可能な場合は入力データセットをより小さくします。可能性のある依存関係をすべて検出するには、[Track stack variables (スタック変数を追跡する)] を選択します。)
- [Survey Report (調査レポート)] で、より詳細な解析を行う 1 つ以上のベクトル化されていないループをマークします。
[Vectorization Workflow (ベクトル化ワークフロー)] の [Check Dependences (依存性のチェック)] で、![]() コントロールをクリックして、アプリケーションの実行中に依存性データを収集します。
コントロールをクリックして、アプリケーションの実行中に依存性データを収集します。
インテル® Advisor がデータを収集すると、次のような依存性に注目した [詳細レポート (Refinement Report)] が表示されます。
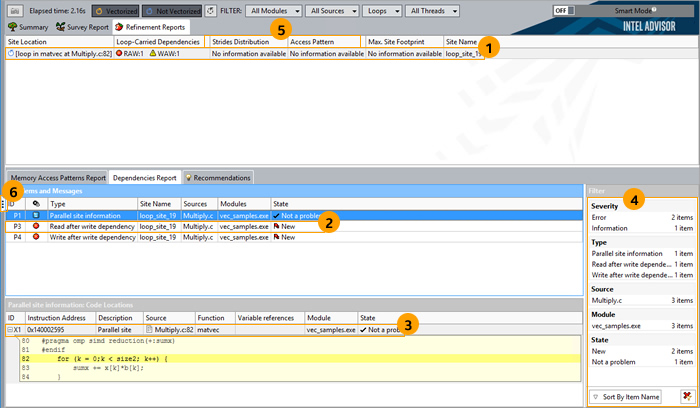
最も重要なデータに注目できるように、次のコントロールを含む、多くのコントロールが用意されています。
- より詳細な解析のために選択したループに関する [Dependencies Report (依存性レポート)] の詳細情報を表示するには、関連するデータ行をクリックします。
- [Code Locations (コードの場所)] ペインに関連するコードの場所の命令アドレスとコードを表示するには、データ行をクリックします。
[Dependencies Source (依存性ソース)] ウィンドウに表示する問題を選択するには、データ行を右クリックして、[View Source (ソースの表示)] を選択します。
別のタブ/ウィンドウでデフォルトのエディターを開くには、データ行を右クリックして、[Edit Source (ソースの編集)] を選択します。
- [Dependencies Source (依存性ソース)] ウィンドウに表示するコードの場所を選択するには、次の操作を行います。
- データ行をクリックします。
- データ行を右クリックして、[View Source (ソースの表示)] を選択します。
別のタブ/ウィンドウでデフォルトのエディターを開くには、データ行を右クリックして、[Edit Source (ソースの編集)] を選択します。
-
[Filter (フィルター)] ペインを使用して、次の操作を行います。
- 1 つ以上のフィルターカテゴリーでフィルター条件をクリックして、[Problems and Messages (問題とメッセージ)] ペインに表示される項目を一時的に制限します。
- 1 つのフィルターカテゴリーのフィルター条件を選択解除するか、すべてのフィルターカテゴリーのフィルター条件を選択解除します。
- 名前 (アルファベット昇順) またはカウント (数値降順) ですべてのフィルター条件をソートします。(フィルターカテゴリーの表示順は変更できません。)
- これらの列および [Memory Access Patterns Report (メモリー・アクセス・パターン・レポート)] にデータを生成するには、メモリー・アクセス・パターン解析を実行します。
- コントロールをクリックすると、[Workflow (ワークフロー)] ペインを表示/非表示にします。
[Dependencies Report (依存性レポート)] の表示に応じて、次の 1 つ以上の操作を行います。
- 指定されたワークロードのループに実際の依存性がない場合、次のいずれかを使用して、ベクトル化しても安全であることをコンパイラーに知らせます。
- #pragma simd ICL/ICC/ICPC ディレクティブ、#pragma omp simd OpenMP* 4.0 標準規格、あるいは !DIR$ SIMD または !$OMP SIMD IFORT ディレクティブ: ループのすべての依存性を無視する場合
- #pragma ivdep ICL/ICC/ICPC ディレクティブまたは !DIR$ IVDEP IFORT ディレクティブ: ベクトル依存性のみ無視する場合 (最も安全ですが、特定のケースではパフォーマンスが低くなります)
- restrict キーワード
- アンチ依存性 (ライトアフターリードの依存性や WAR と呼ばれることもあります) がある場合、#pragma simd vectorlength(k) ICL/ICC/ICPC ディレクティブまたは !DIR$ SIMD VECTORLENGTH(k) IFORT ディレクティブを使用してベクトル化を有効にします。ここで、k はアンチ依存性の依存項目間の距離よりも小さくなります。
- ループにリダクションがある場合、#pragma omp simd reduction(operator:list) ICL/ICC/ICPC ディレクティブまたは !$OMP SIMD REDUCTION(operator:list) IFORT ディレクティブを使用してベクトル化を有効にします。
- コードを書き直して依存性を削除します。
パフォーマンスの向上が完了したら、次の操作を行います。
- MAP 解析を実行します (必要な場合)。
- 変更したコードをリビルドします。
- 別の調査解析を実行して、アプリケーションが正しく実行され、すべてのテストケースをパスし、すべてのループが適切にベクトル化され、最適なパフォーマンスが得られているか確認します。
メモリー・アクセス・パターン (MAP) 解析の実行
このステップはオプションです。
MAP 解析を実行する前に、次の項目を確認します。
- [Memory Access Patterns Analysis (メモリー・アクセス・パターン解析)] タイプで適切な [Project Properties (プロジェクト・プロパティー)] を設定します。(同じアプリケーションを使用しますが、可能な場合は入力データセットをより小さくします。)
- [Survey Report (調査レポート)] で、より詳細な解析を行う 1 つ以上のループをマークします。
[Vectorization Workflow (ベクトル化ワークフロー)] の [Check Memory Access Patterns (メモリー・アクセス・パターンのチェック)] で、![]() コントロールをクリックして、アプリケーションの実行中に MAP データを収集します。
コントロールをクリックして、アプリケーションの実行中に MAP データを収集します。
インテル® Advisor がデータを収集すると、次のような MAP に注目した [詳細レポート (Refinement Report)] が表示されます。

パフォーマンスの向上が完了したら、次の操作を行います。
- 変更したコードをリビルドします。
- 別の調査解析を実行して、アプリケーションが正しく実行され、すべてのテストケースをパスし、すべてのループが適切にベクトル化され、最適なパフォーマンスが得られているか確認します。
レポートの下部のソース行をダブルクリックすると、ストライド情報が命令レベルで提供される、より詳細なソースとアセンブリー・アクセス・パターンのレポートを入手できます。