製品紹介
インテル® oneAPI ツールキット関連製品の紹介動画

このビデオでは、インテルと Accenture が共同で開発した「Visual Quality Control Inspections for Life Sciences (ライフサイエンス向けビジュアル品質管理検査)」を用いた製品ラインの品質管理 (Visual Inspection リファレンス・キット) について紹介します。

このビデオでは、生産ラインで不良錠剤を識別する例をもとに、製品ラインの品質管理 (Visual Inspection リファレンス・キット) に関するフロー全体をステップごとに実行していきます。
お客様のユースケース動画

このビデオでは、ANSYS、Brightskies、Dell、GoogleCloud、Samsung Medison、Stephen Hawking Center for Theoretical Cosmology (CTC)、Zuse Institute Berlin (ZIB) のイノベーション・リーダーが、インテル oneAPI クロスアーキテクチャー・ツールを利用してヘテロジニアス開発を簡素化し、優れたパフォーマンスを実現する方法を紹介します。
インテル® 優先サポートの紹介動画

このビデオでは、インテル® oneAPI ツールキットの商用製品に含まれるインテル® 優先サポートについて紹介します。
インタビュー形式の動画

ベクトル化と並列化は、プロセッサーを最大限に活用しようとするすべてのソフトウェア開発者にとって不可欠です。
このビデオでは、インテル コーポレーション シニア主席エンジニアの Henry Gabb と Larry Meadows がコードの現代化の過去、現在、そして将来について紹介します。

インテル® TBB は長年の実績のあるスレッド化手法です。インテル® TBB を使用することで C++ プログラマーは並列処理の実装ではなく、並列処理の設計に専念できます。
このビデオでは、スレッド化の今後に関するエキスパートのアドバイス、ガイダンス、予測を紹介します。
GDC 2020 トーク動画

このビデオでは、Unity* や Unreal Engine* で低速なフレームとタスクを簡単に見つけるなど、CPU パフォーマンス・ボトルネックの特定に役立つ機能を備えたインテル® VTune™ プロファイラーを紹介します。

このビデオでは、物理シミュレーションとマシンラーニングを使用して、ゲームで新たなレベルの没入感、インタラクション、リアルなキャラクターの動きを実現する DeepMotion の Motion Brain を紹介します。

このビデオでは、インテル® VTune™ プロファイラーを使用して、非効率なスレッド並行性、メモリーアクセス問題、I/O 待機、または不要な命令によって生じるボトルネックを改善し、 CPU パフォーマンスを向上する方法を紹介します。
トレーニング
インテル® oneAPI / インテル® DPC++/C++ コンパイラー
oneAPI で FPGA の開発とパフォーマンスを最適化
oneAPI を使用して FPGA をターゲットにしようとしている開発者を対象に、完全なハードウェア・コンパイルを行わずに高位設計 (HLD) コードで FPGA ハードウェア・レベルの最適化をたった数分で評価する方法や、高位設計において RTL とのパフォーマンス・ギャップを埋めるための手法を紹介します。
パート 1 では、マージソート・アルゴリズムの概要や最適化、高位設計 (HLD) の基本概念や用語、および FPGA でのマージソート設計について分かりやすく説明します。
パート 2 では、パフォーマンスを向上するインクリメンタルな最適化手法の紹介や結果の評価を行った後、本コースの要点を振り返り、oneAPI の関連情報を提供します。


CUDA* から DPC++ へ移行してエッジの計算パフォーマンスを最適化
インテル® oneAPI ベース・ツールキットに含まれるインテル® DPC++ 互換性ツールを使用することで、CUDA* コードからデータ並列 C++ (DPC++) コードへ容易に移行できます。本セッションでは、開発者、研究者、システム・インテグレーター、学生向けに、CUDA* から DPC++ へ移行する方法と役立つ情報を提供します。
パート 1 では、oneAPI の概要、データ並列 C++ (DPC++) の概要、そしてインテル® DPC++ 互換性ツール (インテル® DPCT) の概要と使用法について説明します。
パート 2 では、インテル® oneAPI サンプルを例に、実際にインテル® DPC++ 互換性ツールを使用して CUDA* コードを DPC++ コードへ移行する方法を紹介します。


データ並列 C++ (DPC++) プログラミング・セミナー・シリーズ ~ インテル® oneAPI によるヘテロジニアス環境への移行方法を紹介 ~
データ並列 C++ (DPC++) は、Khronos の SYCL* をベースにした最新の C++ 並列プログラミング・モデルです。Khronos の SYCL* 言語仕様の最新バージョンは SYCL* 1.2.1 です。次のバージョンの SYCL* 2020 は、現在暫定版が公開されており、インテルと SYCL* ワーキンググループのほかのメンバーがリリースに向けて最終調整中です。DPC++ にはSYCL* を容易に使用できるようにする拡張が含まれており、その多くは SYCL* 2020 で実装される予定です。標準化する前に DPC++ コンパイラーに実装することで、コミュニティーがこれらの拡張の有効性を評価するのに役立ちます。
このセッションでは、インテル® oneAPI でダイレクト・プログラミングを実現するためのデータ並列 C++ (DPC++) プログラミング・モデルについて紹介します。 DPC++ の動作の仕組みをはじめ、DPC++ によるプログラミング方法、インテル® ライブラリーからインテル® oneAPI ライブラリーへの移行方法、ヘテロジニアス環境への移行方法、パフォーマンス・チューニングの取り組み方、そして C および Fortran ユーザー向けのプログラミング方法について説明します。
パート 1 では、コンパイルの手順をはじめ、レガシーコンパイル、JIT コンパイル、AOT コンパイル、ファットバイナリー等、データ並列 C++ (DPC++) コンパイラーがどのように動作するかについて説明します。
パート 2 では、インテル® Parallel Studio XE に同梱されるコンパイラーとの比較をはじめ、データ並列 C++ の概念や対象となるユーザー、C/C++ および SYCL* におけるベクトル加算、SYCL* キューやバッファー等、実行例とともに説明します。
パート 3 では、データ並列 C++ (DPC++) プログラミング言語の基本機能を紹介します。バッファーに代わって統合共有メモリー (USM) を使用して、ホストとデバイスのメモリーの管理とアクセスを行います。
パート 4 では、インテル® oneMKL の概要や新機能をはじめ、並列正弦、マルチデバイス FFT、行列乗算といったインテル® oneMKL の利用法のほか、C/C++ や従来の MKL、バッファーによる oneMKL、USM による oneMKL などのサンプルコードについて説明します。
パート 5 では、クラシック・コンパイラーを使用するプロジェクトを新しいコンパイラー (dpcpp/icx/ifx) 環境に移行する際の注意点や問題点を解説します。
パート 6 では、クラシック・コンパイラー (ICC/ICL) および新しい LLVM ベース・コンパイラー (ICX/DPCPP) を使用して、実際にパフォーマンスの比較や検証を行います。また、インテル oneAPI C++ コンパイラーにおける疑問点についても紹介します。






データ並列 C++ と SYCL* 2020 機能による単一ソースの異種プログラミング
このセミナーでは、異種プログラミングを実現する oneAPI とデータ並列 C++ (DPC++) について紹介します。SYCL* の仕様を使用して、言語に直接的に並列処理を組み込む標準 C++ の拡張である DPC++ テクノロジーをはじめ、統合共有メモリー (USM)、サブグループ、リダクション等の SYCL* 2020 の機能について紹介します。また、デモを通して実践的なコーディング・サンプルに取り組み、DPC++ による生産性の向上やパフォーマンスを最適化する方法について分かりやすく説明します。

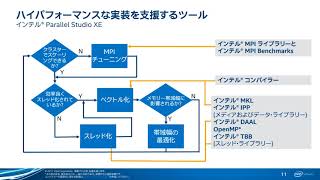
インテル® Parallel Studio XE
インテル® Parallel Studio XE によりアプリケーション・パフォーマンスを大幅に向上
インテル® Parallel Studio XE を使用することにより、パフォーマンスを引き出すコードを生成することが可能です。このツールを使用することによって、インテルのプロセッサーとハードウェアの能力を最大限に発揮し、ハイパフォーマンスでスケーラブルな HPC、エンタープライズ、およびクラウド・アプリケーションを開発できます。
インテル® Xeon® スケーラブル・プロセッサーとインテル® Xeon Phi™ プロセッサー向けのインテル® AVX-512 をサポートし、ベクトル化、マルチスレッド、マルチノード、メモリーの最適化手法を使用したコードの生成や、数値ライブラリーやパフォーマンス・プロファイラーによるソフトウェアの最適化をサポートします。
本セッションは、2 部構成となっており、インテル® Parallel Studio XE の概要、特長、および最適化手法についてご紹介しています。
前半では、インテル® Parallel Studio XE 2018 の概要紹介に加え、最適化をどこから開始すべきかや、スレッド化の方法などを説明しています。
後半では、インテル
® Parallel Studio XE 2018 によるベクトル化、メモリー/ストレージ問題の特定、クラスターのスケーラビリティーなどを説明しています。

オンプレミスとクラウドでの HPC パフォーマンス ― 準備はできていますか?
パブリック・クラウド・プロバイダーは、クラウドで HPC ワークロードを実行するため、競争力のある環境を提供しようと取り組んでいます。プライベート・サーバーでは、クラウドで実行する場合、時間とコストを軽減し、最高のパフォーマンスを達成することが求められます。インテルではプロバイダー各社と協力して、クラウド環境で最高のパフォーマンスを引き出すには、インテルのツールが非常に有用であることを皆さんに知っていただけるよう努めています。
インテル® Parallel Studio XE には 3 つのエディションがあります。Composer Edition にはコンパイラーとライブラリー、Professional Edition にはそれらに加えて解析ツール、そして、Cluster Edition にはさらに追加で MPI ライブラリーとその他のクラスター・パフォーマンス・ツールとチェッカーが含まれます。 ニーズに応じて適切なエディションを選択できます。HPC ワークロードには、一般に Cluster Edition が使用されます。
本コースでは、コードの現代化にあたり、手間をかけずに利用できる最適化から手動のチューニング、そして検証から正当性のチェックまでカバーするワークフローについて、インテル® Parallel Studio XE スイートに含まれるツールを使用して分かりやすく説明します。
本コースは、2 つのトレーニング・ビデオにより構成されています。


インテル® Parallel Studio XE による並列プログラミング入門シリーズ
プログラムの計算時間は、ソフトウェアがハードウェアを活用しているかどうかで大きく左右されます。第 1 部となるこのコースでは、CPU の機能やハードウェアの構成について説明したうえで、インテル® コンパイラーの機能を使った、基本的なプログラムの最適化手法について紹介いたします。
また、システム上でアプリケーションが効率よく動作しているか判断するためにはプロファイラーから得られる情報が役立ちます。第 2 部となるこのコースでは、インテル® VTune™ プロファイラーを使用して得られた解析結果からプログラムを最適化する基本的な手法をご紹介いたします。
インテル® コンパイラーを使った自動ベクトル化機能は強力ですが、十分な性能が引き出せない場合は、インテル® Advisor のベクトル化アドバイザーから得られる情報を活用します。第 3 部となるこのコースでは、インテル® Advisor の機能を使い、ベクトル化を考慮するにあたり有益な情報とあわせて、ベクトル化が不十分なプログラムを最適化する方法をご紹介いたします。



インテル® コンパイラーを使用した OpenMP* 5.0 による並列プログラミング・シリーズ
インテル® コンパイラーは、バージョン 18.0 以降、インテル® グラフィックスへの OpenMP* オフロード機能をサポートしていませんが、現行のインテル® コンパイラー 19.1 の新機能を使用して、インテル® グラフィックスへのオフロード実行が可能になりました。このセッションでは、CPU および GPU 向けにサポートされる OpenMP* の機能を含め、開発手順や新機能について説明します。最後に、oneAPI HPC ツールキットのベータ版に含まれるコンパイラーでコンパイルし、GPU への移行ができているか確認します。
パート 1 では、OpenMP* が広く導入される背景とこれまでの歴史を振り返ってみます。異なるバージョンのインテル® コンパイラーや異なるコンパイラー間で OpenMP* を使用する注意点や制限について説明します。また、OpenMP* 3.1 で追加されたタスク機能が 4.0 から 4.5 でどのように進化したかを例を使用して説明し、最新の OpenMP* 5.0 で強化された新機能を紹介します。
パート 2 では、OpenMP* のスレッド化機能を使用してプログラマーがマルチスレッドの動作をプログラミングしたように、OpenMP* 4.0 からは omp simd を使用してプログラマーが明示的にベクトル化もできるようになりました。OpenMP simd に関連する機能を 4.0 から 5.0 までの進化を追って紹介します。また、OpenMP* 4.0 で追加されたオフロード機能を利用することで、これまで共有メモリー型並列処理に加え分散メモリー型の並列処理を表現できるようになりました。注目されるヘテロジニアス・プログラミング環境での OpenMP オフロード機能についても説明します。
パート 3 では、パート 1 および 2 でカバーされなかった OpenMP* 5.0 のそのほかの機能について紹介します。最後に、oneAPI 向けのデータ並列 C++ (DPC++) へ移行する前に、現行のインテル® C++/Fortran コンパイラー v.19.1 や oneAPI HPC ツールキットに含まれるインテル® C++ および Fortran コンパイラー 2021 ベータ版を使用して、簡単にインテル グラフィックスへのオフロードを行うソフトウェアの開発および検証方法を紹介します。





インテル® ディストリビューション for Python* およびインテル® ライブラリー
Python* と daal4py 使用したマシンラーニング
このコースでは、Python*、インテル® ディストリビューション for Python*、データサイエンスのワークフローについて簡単に説明した後、インテル® ディストリビューション for Python* を使用する方法を説明します。また、データサイエンスとマシンラーニングの重要なステップである前処理、トレーニング、推論についても説明します。
本コースは、2 つのトレーニング・ビデオにより構成されています。


エッジにおける Python* 開発
このコースでは、インテル® ディストリビューション for Python* のインストールやサンプル・アプリケーションの実行の様子を記録したデモとともに、使用するツールから IDE Python* プラグインと Eclipse* IDE の統合方法など、エッジにおける Python* の開発方法を紹介します。
本コースは、4 つのトレーニング・ビデオにより構成されています。


Python* はネイティブコードと同じくらい速いのか?
まず最初に、Python* コミュニティーにおいて、インテル社が Python* パフォーマンス向上にどれだけ貢献しているかご紹介します。 その後、Python* コードを高速化するための 3 つのステップによるアプローチや、インテルのプラットフォーム上で Python* を高速に実行するためのライブラリーをご紹介します。 また、Python* のデモおよび関連情報についてもお話します。
本コースは、3 つのトレーニング・ビデオにより構成されています。

インテル® ライブラリー
数行の DPC++ とインテル® oneMKL でフーリエ相関アルゴリズムを実装する
このセッションでは、データ並列 C++ (DPC++) キュー、バッファー、統合共有メモリー (USM)、データ移動、暗黙的同期と明示的同期に関する基本事項の他、1 次元フーリエ相関のバッファリングと USM 実装について紹介します。また、ホストとデバイス間におけるデータ移動や、不要なデータ移動を回避する方法について分かりやすく解説します。
このセッションに関する動画および資料につきましては、インテル® ソフトウェア開発製品 / 有償サポート製品を購入いただき、有効なサポートをお持ちの方を対象に公開中の限定サイトにてオンデマンド配信および配布しています。

インテル® TBB のコンカレント・コンテナー・クラスを利用して C++ アプリケーションを効率的にスケールする
このセッションでは、コンテナーの定義や標準コンテナーの種類をはじめ、インテル® スレッディング・ビルディング・ブロック (インテル® TBB) のコンカレント・コンテナー・クラスを利用して C++ 言語アプリケーションを効率的にスケールする方法を紹介します。
本コースは、3 つのトレーニング・ビデオにより構成されています。
パート 1 では、C++ 言語におけるコンテナーの定義および標準コンテナーの種類について説明します。
パート 2 では、並列環境におけるコンテナーの使用方法およびインテル® TBB のコンテナーについて説明します。
パート 3 では、インテル® TBB のコンカレント・ベクトルや最適な使用方法について説明します。



ハイブリッド・クラウド: オンプレミスとクラウドでの HPC パフォーマンスのベスト・プラクティス
このセッションでは、インテル® MKL やインテル® IPP など、インテル® アーキテクチャー向けに最適化されたライブラリーを使用し、ワークロードを実行するシステムに応じて、アーキテクチャー固有の最適化を指定してコンパイルします。次に、メインのトピックであるインテル® Advisor およびインテル® VTune™ プロファイラーを使用した解析とチューニングについてデモとともに分かりやすく説明します。
本コースは、2 つのトレーニング・ビデオにより構成されています。
パート 1 では、オンプレミスとクラウドで HPC パフォーマンスを最大限に引き出すため、インテル・ツールを使用してコードを現代化するワークフローを紹介します。
パート 2 では、実際にツールを使用してワークフローを実行する方法を紹介します。


さらに効率良く高速でスケーラブル: エクサスケールに向けて前進
このセッションでは、新しいシステムにおける課題と対応方法を説明し、大規模システム向けのインテル 製品についての概要や開発フローと役立つツールを紹介します。主に、柔軟で効率の良い、スケーラブルなクラスターメッセージを提供する「インテル® MPI ライブラリー」について説明します。
本コースは、2 つのトレーニング・ビデオにより構成されています。
パート 1 では、分散プログラミング向けインテル® ソフトウェア・ツール (解析ツールプロファイル・データのスナップショット機能)
や、インテル
® MPI ライブラリーの概要を説明しています。インテル® MPI ライブラリーの最新バージョン 2018 Update 1 の新機能についても紹介します。
パート 2 では、インテル® MPI ライブラリー製品の今後や、インテル® MPI ライブラリー 次期バージョン 2019 のテクニカルプレビュー機能について紹介しています。
このテクニカルプレビューでは、大規模システム向けに多くの機能改善が行われています。


クラウドおよびエッジ・アプリケーション向けデータ圧縮コードの高速化
このセッションでは、クラウドおよびエッジアプリケーション向けデータ圧縮コードの高速化をご紹介します。
ここでは、インテル
® ソフトウェア開発製品のインテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) ライブラリーを使用してコードを高速化します。
本コースは、2 つのトレーニング・ビデオにより構成されています。
パート 1 では、データ圧縮ライブラリーが含まれるインテル® IPP 概要をご説明し、最新バージョン 2018 の新機能を紹介します。さらに、データ圧縮の使用例について、パフォーマンスと圧縮率のトレードオフに注目して述べます。 その後、インテル ® IPP でサポートされる 4つの圧縮関数のうち、zlib についてご紹介します。パート 2 では、引き続き zlib について説明し、残りの 3つの圧縮関数 LZ4、LZO、bzip2 を紹介します。最後に、アプリケーションに最適な圧縮アルゴリズムを選択する方法を、例を使って示します


インテル® MKL を使用した小行列乗算の高速化
本コースはインテル社 Webinar の日本語版です。2部構成となります。
この数年間、インテルは特に小行列をターゲットにした機能をインテル® マス・カーネル・ライブラリー (インテル® MKL) に追加してきました。 このセッションでは、それらの機能とサンプルコード、および基本的な使用モデルを紹介します。
前半では、インテル® MKL の概要、新機能を説明しております。 そして、行列行列乗算について解説し、高速化のための最適化機能を紹介します。
後半では、パフォーマンスの課題を克服するための 4つのソリューションを説明し、最後にパフォーマンスのヒント、サブルーチンのパフォーマンスを測定するためのサンプルコードを紹介します。


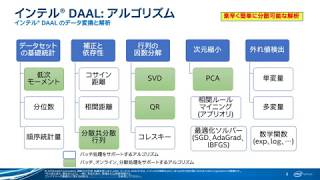
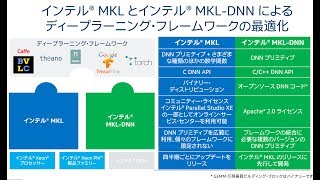
インテル® ライブラリーによるディープラーニングとマシンラーニングの促進
インテルは、ディープラーニングやマシンラーニング・アプリケーションの開発における課題に対処し、インテル・アーキテクチャー (IA) 上で人工知能 (AI) を活用するための様々な取り組みを行っています。
本 Web セミナーでは、その中でもインテル® MKL(マス・カーネル・ライブラリー)およびインテル® DAAL(データ・アナリティクス・アクセラレーション・ライブラリー)について紹介します。これらのライブラリーを適用することで、既存のフレームワークやアルゴリズムにおいて現在および次世代のインテル® プロセッサーの性能を引き出し、モデルの訓練時間を短縮することが可能です。
また本 Web セミナーでは、ディープラーニング・ソリューションの設計、訓練から配備までの流れを容易にする新しいツール、インテル Deep Learning SDK についても紹介します。
クラスターシステム診断ツール インテル® Cluster Checker
インテル® Cluster Checker – 高速かつ信頼性の高いプラットフォームでクラスター・アプリケーションを計算
クラスターシステムは、様々なハードウェア、ソフトウェアが関連した非常に複雑なシステムです。さらに、通常クラスターシステムには、役割が異なる複数のチーム、担当者が関与します。クラスターを構築するクラスター・アーキテクト、システムをマネージメントするシステム管理者、アプリケーションを作成するアプリケーション開発者、そしてクラスターを利用するクラスターユーザーなどです。彼らはそれぞれ固有の問題を持っていますが、クラスターのもつ複雑性を軽減して問題解決に挑むという共通の課題があります。
本セッションでは、これらクラスターシステムにかかわる人々が、抱える問題を取り上げ、また特にアプリケーション開発者についてはツールのデモも交えつつ詳しく説明します。
また、クラスターシステムの一般的な問題として、クラスターシステムで使用されるハードウェアやソフトウェアの一貫性に関する問題や、メモリー構成の問題、レイテンシーや帯域幅、データー転送ファブリック、そして MPI パフォーマンスに関する問題など、数多くの問題が挙げられます。 このような様々な問題があり、しかも複雑なクラスターシステム上で問題の原因を的確に特定することは容易ではありません。このような状況を解決するのが、クラスター向け診断ツール「インテル® Cluster Checker」です。 インテル ® Cluster Checker のツール詳細、クラスターシステム向けの診断方法については、本トレーニング・ビデオをご覧ください。
インテル® Cluster Checker は、インテル® Parallel Studio XE Cluster Edition for Linux に、コンポーネントとして含まれております。

インテル® Xeon Phi™ プロセッサー
Knights Landing – 開発者向け概要オンライン・トレーニング (前半)
本 Web セミナーは、第 2 世代インテル® Xeon Phi™ プロセッサー、開発コード名 Knights Landing について、アプリケーション開発者向けに概要を説明します。
コプロセッサーからプロセッサーとなり、高いパフォーマンスをより利用しやすくなったメニーコア・プロセッサー、インテル
® Xeon Phi™ 製品についての技術情報を提供します。
後編 (パート 2) は 11 月下旬に公開予定です。

インテル® VTune™ プロファイラー
インテル® VTune™ プロファイラー・サーバーによる容易なプロファイル
インテル® VTune™ プロファイラー・サーバーを使用することで、ウェブブラウザーからターゲットをプロファイルして、どこからでも結果にアクセスできます。サーバーへの一度のインストールで多くのユーザーが利用でき、頻繁なターゲット変更にも対応し、結果をほかのユーザーと共有できます。
パート 1 では、インテル® VTune™ プロファイラー・サーバーの概要、インストールと起動方法を説明します。
パート 2 では、AWS* インスタンス上に構築したインテル® VTune™ プロファイラー・サーバーによる容易なプロファイル プロファイラー・サーバーを使用して、ブラウザーからターゲットの解析を行い、結果を表示する基本的な操作を紹介します。

DPC++ と GPU ワークロードのパフォーマンスをプロファイル
CPU から GPU へアプリケーションをオフロードする場合、パフォーマンスを最適化するため、どこを、どのように変更すれば効果的かを特定することは容易ではありません。本セミナーでは、インテル® VTune™ プロファイラーを使用してこの作業を簡素化する方法を紹介します。
パート 1 では、GPU プログラミング・モデルとインテル® VTune™ プロファイラーの GPU 解析について説明します。
パート 2 では、実際にインテル® VTune™ プロファイラーを操作しながら GPU オフロード解析の利用方法を紹介します。
パート 3 では、実際にインテル® VTune™ プロファイラーを操作しながら GPU 計算/メディア・ホットスポット解析の利用方法を紹介します。

インテル® VTune™ プロファイラーのプラットフォーム・プロファイラーを使用したワークロードとシステムの特徴付け
このセッションでは、インテル® VTune™ プロファイラーのプラットフォーム・プロファイラーによる長時間におよぶシステムの詳細な解析の概要や、システム構成の問題やワークロードを特定する低オーバーヘッドのメトリクスの収集方法を、実際のユースケースをもとにしたデモとともにご紹介します。
本コースは、3 つのトレーニング・ビデオにより構成されています。
パート 1 では、ツールの概要をご説明し、パート 2 にてツールを私用するためのワークフローを紹介します。パート 3 のデモでは、実際にツールを使用する方法、結果を視覚化する方法、そして結果の読み解き方を解説します。



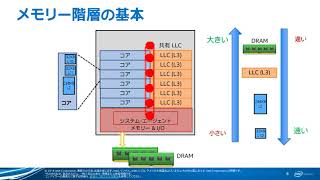
メモリー・アクセス・プロファイル: 一般的なパフォーマンス・ボトルネックの特定と修正
このセッションでは、メモリー・アクセス・プロファイルにおける一般的なパフォーマンス・ボトルネックの特定と修正について説明します。本コースは、2 つのトレーニング・ビデオにより構成されています。
前半では、本セッションのメイントピックであるメモリー階層について、いくつかの基本事項を説明します。また、パフォーマンス・プロファイラー「インテル® VTune™ プロファイラー」の概要、基本操作、プロファイルの設定方法などを解説しています。
後半では、インテル® VTune™ プロファイラーを使ったメモリー階層に関するパフォーマンス解析について、低い NUMA 使用率、非効率な配列アクセスパターンなど、実際の例を見ていきます。また、GUI や解析結果の見方についても説明しています。

インテル® VTune™ Amplifier + OpenMP* によりスレッドのパフォーマンスとスケーラビリティーを向上する
このセッションでは、インテル® VTune™ Amplifier と OpenMP* でスレッドのパフォーマンスとスケーラビリティーを向上する方法を、サンプルプログラムを使用しながら紹介しています。 チューニングの可能性を調査する手法について、フィルターと非最大抑制における計算依存のワークロードを例にとって、以下の項目を順に説明していきます。
- インテル® VTune™ Amplifier とインテル® Advisor – ベクトル化アドバイザーの使用
- インテル® コンパイラーの最適化レポート
- OpenMP* の SIMD プラグマを利用する外側のループのベクトル化
- その他のコンパイラーによる最適化
- OpenMP* によるスレッド化


HPC アプリケーションに役立つハイパフォーマンス解析
このセッションでは HPC の分野に特化したパフォーマンス解析技術を性能解析ツール「インテル® VTune™ Amplifier 」を使用してご紹介します。
まず最初に、現在の
HPC 業界における一般的なパフォーマンス解析の状況をご紹介します。そして次に、インテル® VTune™ Amplifier に搭載される HPC Performance
Characterization (HPC 特性解析) について、その概要を説明します。これは、HPC アプリケーションのパフォーマンス特性を解析する機能となります。 さらに、HPC 特性解析を使用したパフォーマンス解析の例もご紹介します。

製品紹介・使い方
本トレーニングでは、製品概要、パフォーマンス・プロファイル手順、分析結果やタイムライン・ビューの見方、目的別の解析手法を説明します。
- 旧バージョンを使用した内容であっても、基本的には最新バージョンでも活用できます。
- 製品概要
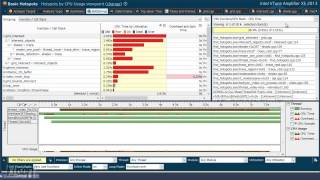
- Hotspot 解析
- Concurrency (コンカレンシー) 解析
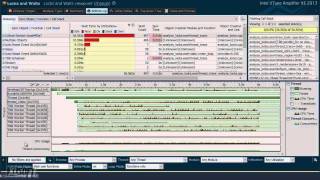
- Locks & Waits (ロックと待機) 解析
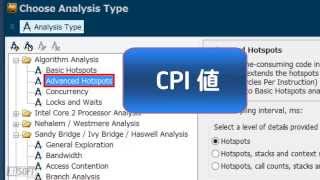
- Advanced Hotspots 解析 (前編)
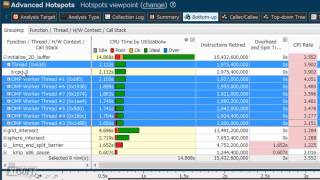
- Advanced Hotspots 解析 (後編)
インテル® Advisor
ヘテロジニアス・ハードウェアの可視化とチューニング
インテル® Advisor は、インテル® oneAPI スイートに含まれるツールです。FGA は、DPC++ (略称 DPC++) プログラムのトレースを収集して、FGA GUI で表示して、アプリケーションのチューニングと最適化を行うための機能を提供します。このセッションでは、インテル® Advisor のフローグラフ・アナライザー (略称 FGA) 機能を使用して、ヘテロジニアス・ハードウェアを可視化してチューニングする方法を紹介します。
パート 1 では、oneAPI とインテル® Advisor の概要、インテル® oneAPI ベース・ツールキットに含まれる新しいインテル® Advisor の GPU サポートについて説明します。
パート 2 では、インテル® Advisor を実際に操作しながら、オフロードのモデル化、GPU ルーフライン、およびフローグラフ・アナライザー機能を使用してオフロード領域を特定し、ボトルネックを特定して排除する方法を説明します。

コードを GPU にオフロードする
ボトルネックの特定と排除は、すべての開発者が避けて通れない課題です。アプリケーションを新しいプラットフォームに移行する場合、例えば CPU から GPU へ移行する場合、この作業はさらに複雑になります。その場合、開発者はボトルネックを特定するだけでなく、まずオフロードにより利点が得られるコード領域を特定する必要があります。
インテル® oneAPI ベース・ツールキットに含まれるインテル® Advisor の GPU 向けの新しい機能は、ボトルネックの特定だけでなく、オフロードにより利点が得られるコード領域の特定を支援します。
パート 1 では、oneAPI とインテル® Advisor の概要、インテル® oneAPI ベース・ツールキットに含まれる新しいインテル® Advisor の GPU サポートについて説明します。
パート 2 では、インテル® Advisor を実際に操作しながら、オフロードのモデル化、GPU ルーフライン、およびフローグラフ・アナライザー機能を使用してオフロード領域を特定し、ボトルネックを特定して排除する方法を説明します。


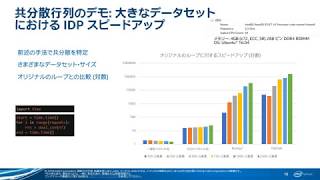
CPU と GPU でのインテル® Advisor のメモリーレベルのルーフライン・モデル
このコースでは、インテルの解析ツールであるインテル® Advisor のルーフライン拡張機能を利用してハードウェアに課せられているパフォーマンスの上限を明らかにする方法を紹介します。ルーフラインの概要に続いて、L1、L2、L3、または DRAM のどのメモリーレベルがボトルネックを引き起こしているか特定するのに役立つ、新しいメモリーレベルのルーフライン機能について説明します。インテル® Advisor の改良されたユーザー・インターフェイスについても取り上げます。


OpenMP* とインテル® TBB タスクグラフ: インテル® Advisor のフローグラフ・アナライザーで問題を解明する
今日の多くのプログラムやプログラミング・モデルは、タスクベースの並列処理をサポートしています。その理由はロード・バランシングを向上し、不規則なランタイム依存の実行を効率良く並列化できるためです。
しかしながら、グラフはプログラムで作成されるため、複雑になりがちで、あとで実際に作成されたものを判断するのはとても大変です。
また、タスクベースの並列処理は一般に構造化されておらず、データによってはグラフの一部のみが実行される可能性があるため、アルゴリズムのパフォーマンス解析が困難です。
このコースでは、タスクベースのプログラミング・モデルの上記のような課題を見つけることができる、インテル® Advisor のフローグラフ・アナライザー (FGA) についてご紹介します。FGA は、インテル® TBB 向けにインタラクティブにグラフを作成できる GUI ベースのツールです。


キャッシュを考慮したルーフライン解析を使用してベクトル化とメモリーの最適化を詳しく調査する
完璧なベクトル化およびスレッド化がおこなれている場合でも、開発者は、CPU、ベクトル、スレッドの利用率と、メモリー・サブシステムのデーター・ボトルネックのバランスを調整する必要があります。
この Webinar で紹介されている「ルーフライン・モデル」を使うことで、アプリケーションのパフォーマンスの問題にどのように適切に対象するかを直観的に理解できます。
本コースでは、まず、ルーフライン・モデルとは何かを説明し、その後、インテル ® Advisor によるルーフライン解析、ケーススタディー、そして、現在の最新バージョンおよび次期バージョンの新機能をご紹介します。

AVX-512 ハードウェアを使用することなく AVX-512 を最適化する
インテル ® Xeon Phi™ プロセッサー (Knights Landing) や、今後登場するインテル® Xeon® プロセッサーなど、ますます複雑化する現代、および次世代のハードウェアを最大限に活用するには、ソフトウェアが効率良くスレッド化およびベクトル化されていることが求められます。
本セッションは、2 部構成となっており、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) のハードウェアを使用することなく、インテル® AVX-512 ソフトウェアを最適化する方法をご紹介します。
- 前半では、ベクトル化の背景と効率の良いベクトル化を支援するツール「インテル® Advisor 2017」の機能について説明します。
- 後半 (近日公開予定) では、AVX-512 の概要についてお話した後、インテル® Advisor 2017 が AVX-512 とそれ以前の命令セットの両方を使用するソフトウェアの最適化に、どのように役立つかを紹介します。

- ベクトル化の背景とインテル® Advisor 2017 機能紹介 (前編)

- AVX-512 の概要とソフトウェア最適化 (後編)
ベクトル化アドバイザー機能紹介
本トレーニングでは、製品概要、基本的な操作方法、バージョン 2016 で追加されたベクトル化アドバイザー機能に関して説明します。
- 旧バージョンを使用した内容であっても、基本的には最新バージョンでも活用できます。
- 製品概要と使い方 (前編)
- 製品概要と使い方 (後編)
- ベクトル化アドバイザー機能のチュートリアル
インテル® Inspector
メモリーとスレッドのバグを検出: インテル® Inspector - スレッド、メモリー、および不揮発性メモリー対応エラー検出ツール
メモリーとスレッドのエラーは見つけるのが困難です。インテル® Inspector は、これらのエラーの検出を支援します。このような正当性検証ツールを使用することで、投資対効果を 12% ~ 21% 向上します。開発サイクルの早期で問題を発見することが非常に重要になります。
本コースでは、インテル® Inspector 2020 の概要や基本的な解析ワークフローをはじめ、メモリー、スレッド、およびパーシステント・メモリーの解析、デバッガーとの統合、自動回帰テストとユーザー API について説明します。