概要
Python* 向けハイパフォーマンス・ツール

インテル® ディストリビューションの Python* は、現代のインテル® プラットフォーム上で Python* アプリケーションのパフォーマンスを向上するためのツールや機能を提供します。
あなたが経験豊富な開発者であろうとワークフローをスピードアップしたいデータ科学者であろうと、インテル® ディストリビューションの Python* は、容易なインストールと厳しいパフォーマンス要件を満たすために最適化済みの Python* パッケージを提供します。Windows*、Linux* がサポートされています。
詳細・新機能 ライセンス・サポートサービス iSUS 製品紹介特長
Python* の最大のメリットの1つは、習得や使用が容易だということです。 しかし、インタプリター言語として、Python* は高性能な計算集約型アプリケーションではパフォーマンスが遅いということも知られています。
NumPy、SciPy、pandas、scikit-learn、Jupyter、 matplotlib、および mpi4py などの Python* の計算パッケージをすべて含み、強力なインテル® MKL、インテル® oneDAL、pyDAAL、インテル® MPI ライブラリー、インテル® oneTBB を提供することで、大幅なパフォーマンスを改善を実現できます。
マルチスレッドの Python* ワークロードは、インテル® oneTBB の最適化されたスレッドのスケジューリングと、インテル® MPI ライブラリーとの効率的な通信を使用して、インテルのマルチコア・アーキテクチャーのパフォーマンスを発揮します。
インテル社から提供されているオールインワンのインストーラーによって 容易に Python* 環境をインストール、管理することができ、Python* アプリケーションのパフォーマンスを向上するとともに、インテル® VTune™ プロファイラーを使うことで正確にチューニングすることができます。
インテル® VTune™ プロファイラーは、ネイティブ拡張、低オーバーヘッドとソースコードの行レベルの詳細情報を使用して、Python* コードの明らかな、または明らかでないパフォーマンス・ボトルネックを特定するパフォーマンス・アナライザーです。
インテル® パフォーマンス・ライブラリー、解析ツールの詳細は以下ページを参照ください。
インテル® ディストリビューションの Python* 2026
バージョン 2026.0 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートやシステム要件、およびインテル社公開の情報を参照ください。
インテル® ディストリビューションの Python* に関するその他のドキュメントについては、こちらを参照ください。
詳細
ダイレクト ・プログラミングを実現するデータ並列 C++ (DPC++) コンパイラー
数値解析において、グローバル・インタープリター・ロック(GIL)を持つインタプリタ言語である Python* は、一般的に HPC 向けに使用されるコンパイル言語よりも本質的に遅くなります。しかし、Python* は、そのシンプルさと開発スピードの速さで知られています。インテル® ディストリビューションの Python* は、その特性を活用して、この基本的なパフォーマンスの課題に対処します。
- インテル® oneMKL と Python* 計算パッケージ (NumPy、SciPy および scikit-learn) でパフォーマンスを強化
- Python* パッケージとしてインテル® oneTBB ライブラリーを使い、スレッドのスケジューリングを合理化
- ジャストインタイム(JIT)コンパイルを通して、Numba でコード実行を高速化
- mpi4py と Cythonおよびインテル® MPI ライブラリーを通して、パフォーマンスを向上
- pyDAAL を通じて、インテル® oneDAL との強力なデータ分析とニューラルネットワーク機能を実装
- conda* と PIP を使用して簡単にインストール可能
容易なインストール
1回のインストールで、データーサイエンスと科学計算のためのコアパッケージを得られます。 すべてのパッケージはバイナリーで自己完結型なので、コンパイラーや追加のライブラリーをインストールする必要はありません。
相互運用性
サードパーティー・パッケージのインストールに Conda* または PIP* を使用
スケーラビリティー
インテル® ディストリビューションの Python* を使って、インテル® Xeon Phi™ プロセッサー向けにスケールリングできます。業界をリードするインテル® MPI ライブラリーと併せて mpi4py を提供します。 NumPy と SciPy は、多くのアルゴリズム向けに自動的に複数コアを使用します。効率的なスレッドのスケジューリングのためのインテル® TBB を使用します。
パフォーマンス
Python* の使いやすさとネイティブコードのパフォーマンスの組み合わせで開発を効率化、パフォーマンスを向上。インテル® ディストリビューションの Python* は、インテル® oneMKL およびその他のライブラリーを使用して、最新インテル® Core™、インテル® Xeon®、およびインテル® Xeon Phi™ プロセッサーを最適化します。インテル® ディストリビューションの Python* を使うことで、通常はコードを変更することなくインテル® AVX とマルチコア・プロセッサーのパフォーマンスを発揮できます。
パフォーマンス・ベンチマーク
ペンチマークについては、本ページ下部に掲載されている法務上の注意書きも併せてご参照してください。
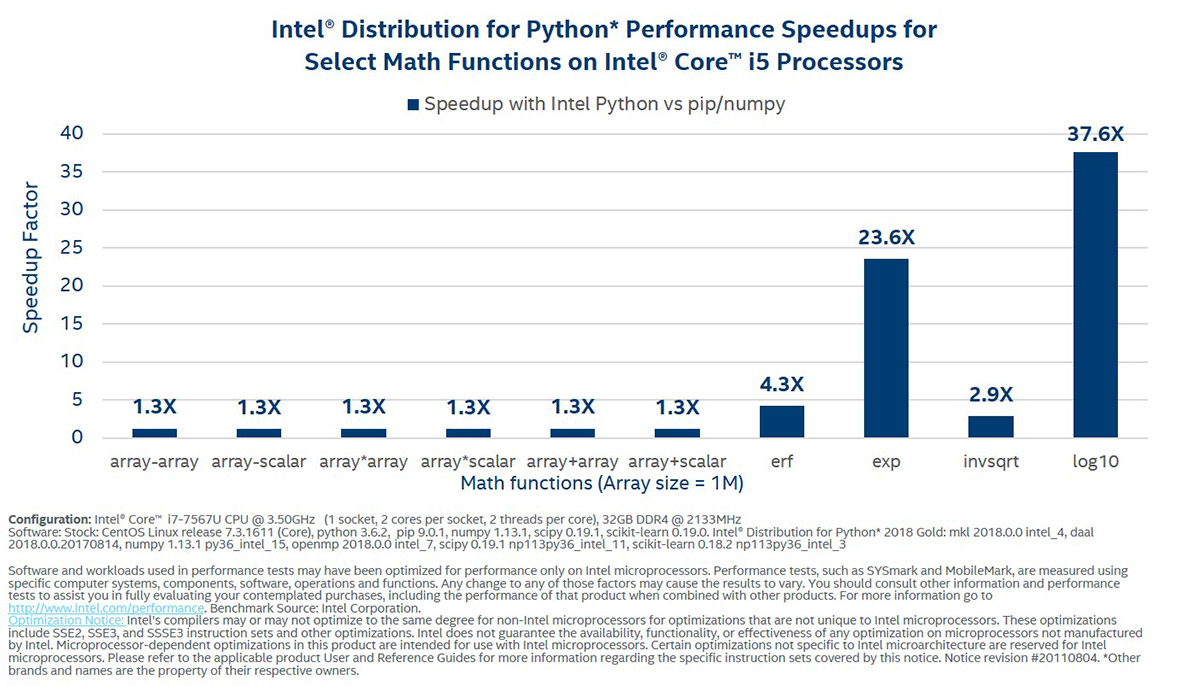
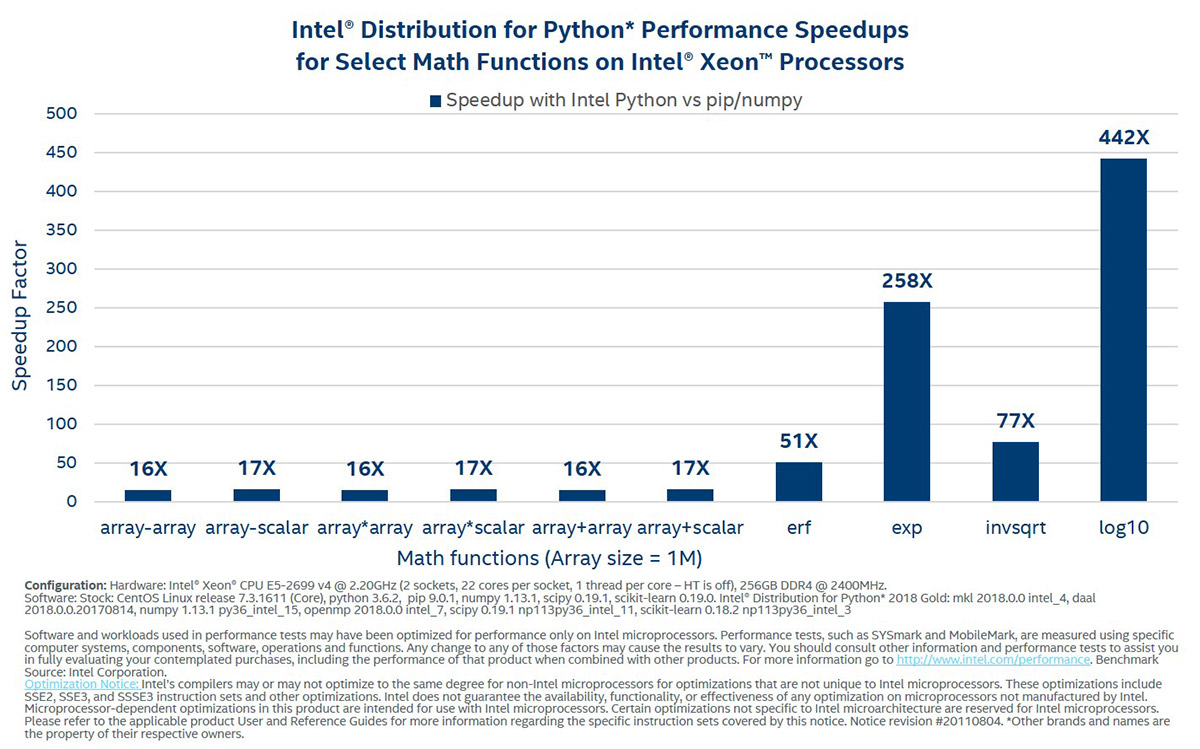
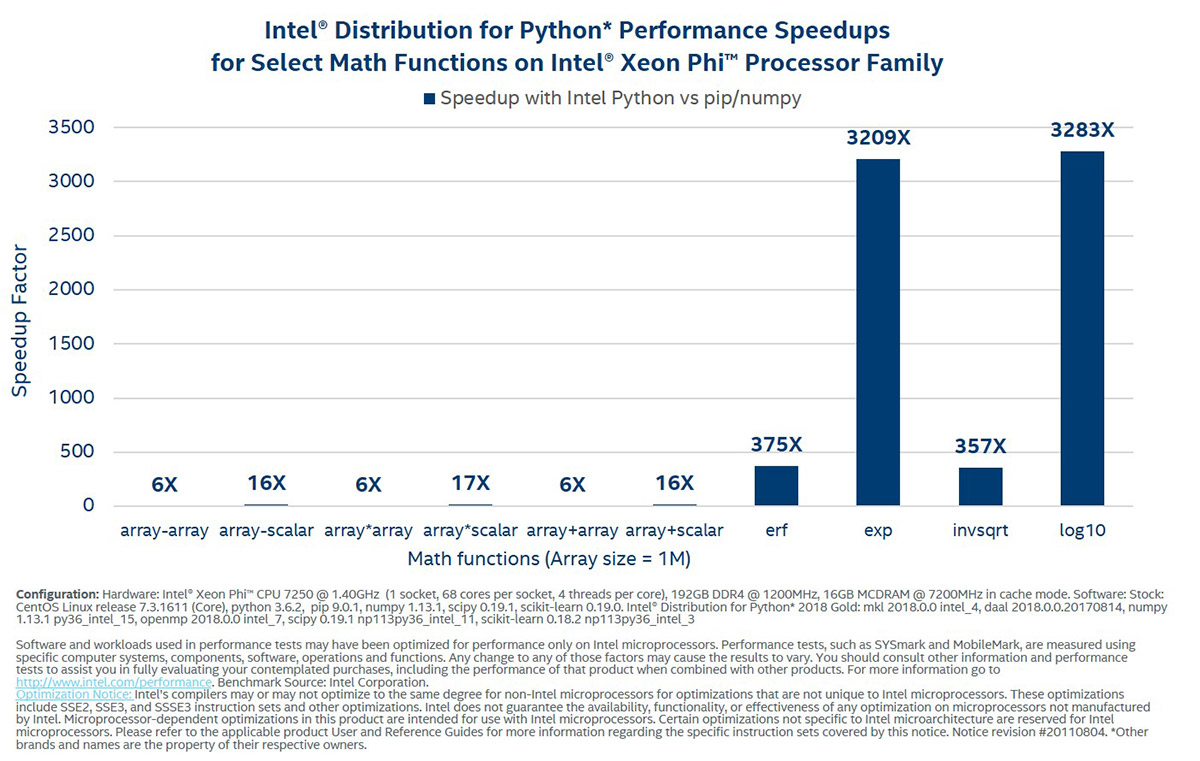
線形代数と NumPy ユニバーサル関数
これらの関数は、Python* での数値計算のビルディング・ブロックです。インテル® ディストリビューションの Python* は、インテル® AVX とマルチコアのパフォーマンス特典を利用して、サーバーで最大 200 倍、デスクトップ・システムで 10 倍高速にキールーチンを実行します。 このディストリビューションでは、BLAS および LAPACK にインテル® oneMKL を使用しています。汎用関数の場合、インテル® コンパイラーとベクトル演算ライブラリーを使用します。
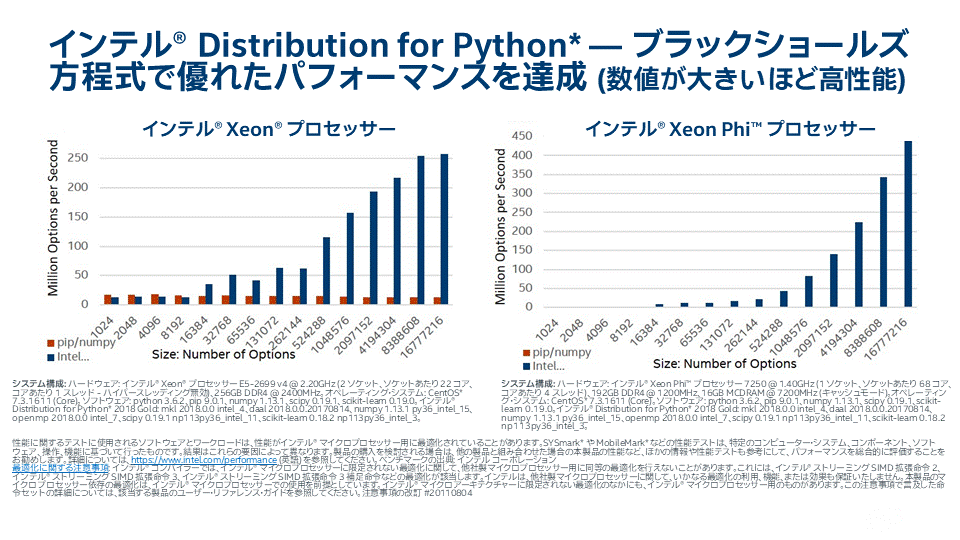
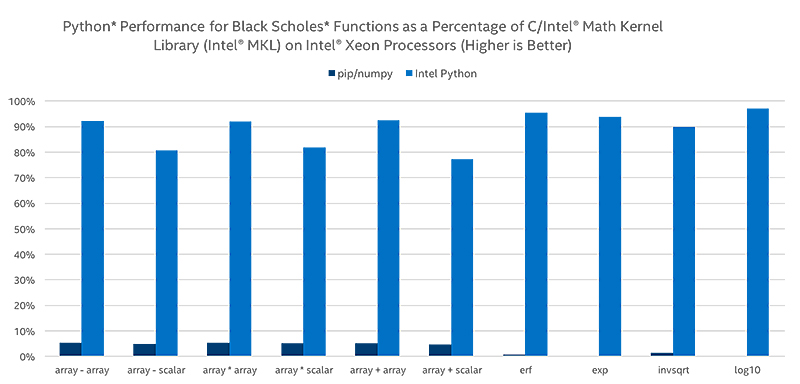
インテル® Xeon Phi™ プロセッサーでは、ベクトル - ベクトルと、ベクトル - スカラーの NumPy 算術演算と超越数演算が最大 400 倍まで高速化されます。次のベンチマークは、Black-Scholes 関数をベンチマークすることによって、算術および超越式の高速化のスケールを示しています。
これらのベンチマークは、インテル® ディストリビューションの Python* と Black-Scholes を使用したスピードアップを実証しています。
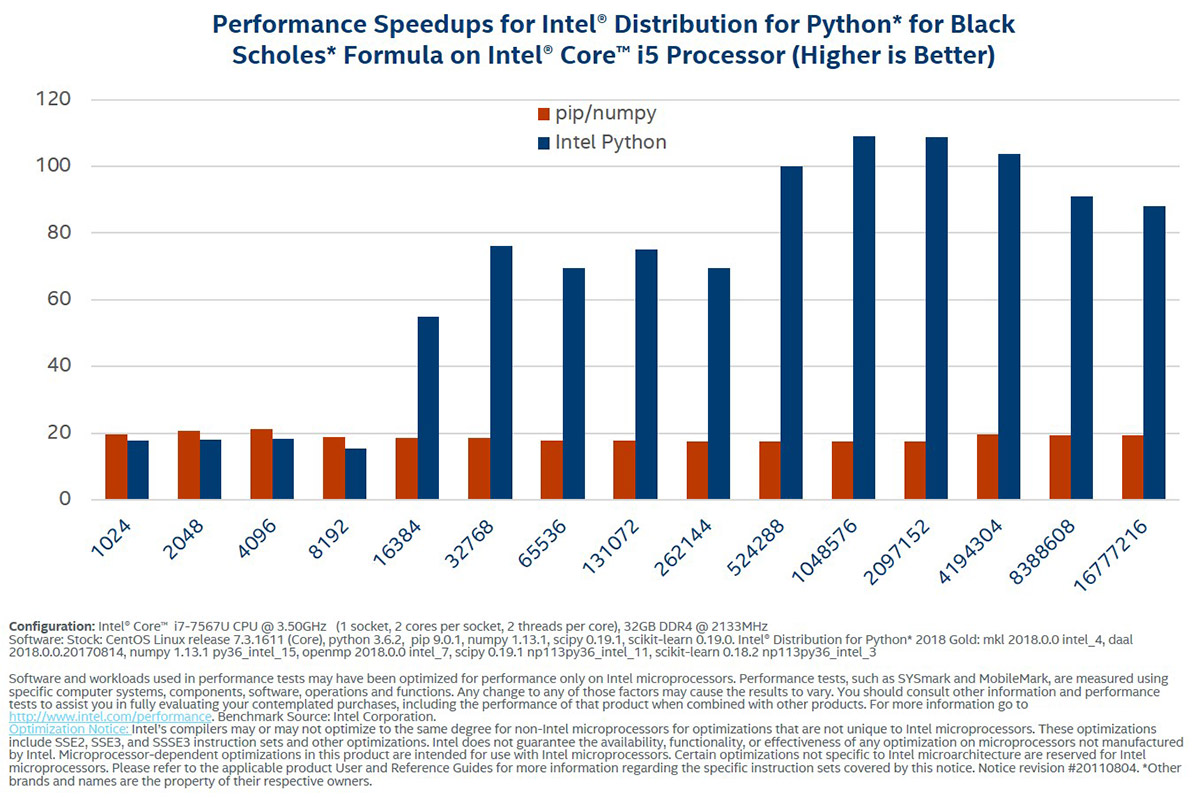
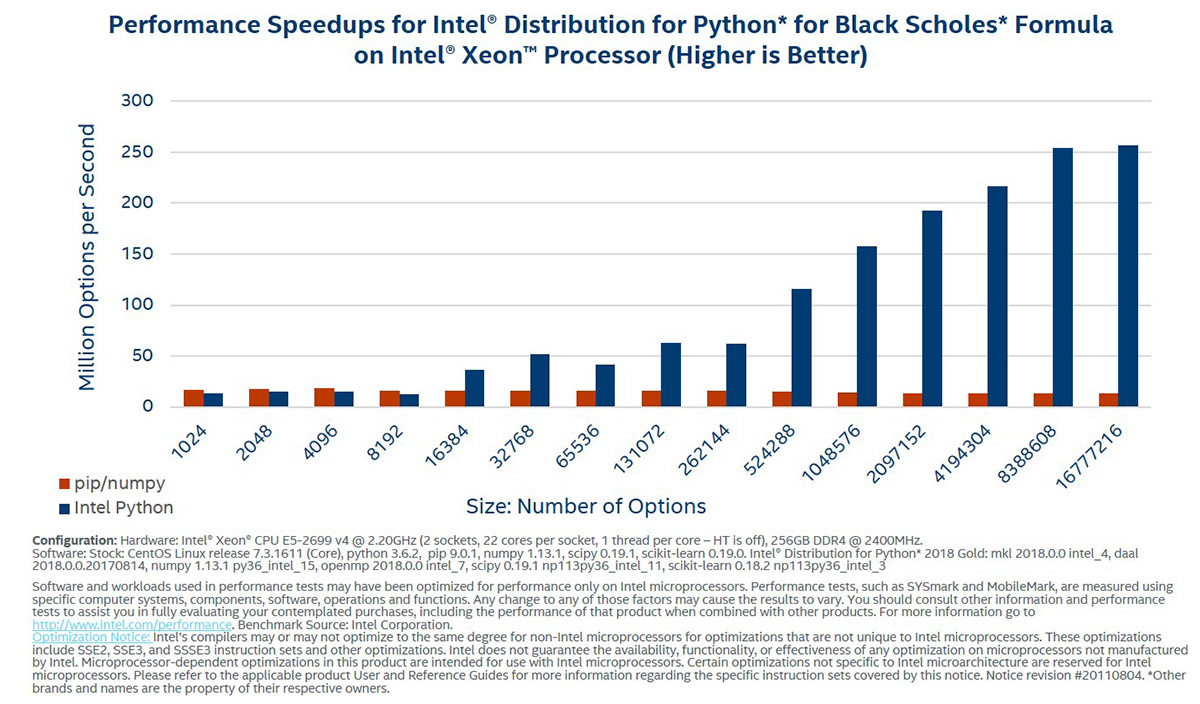
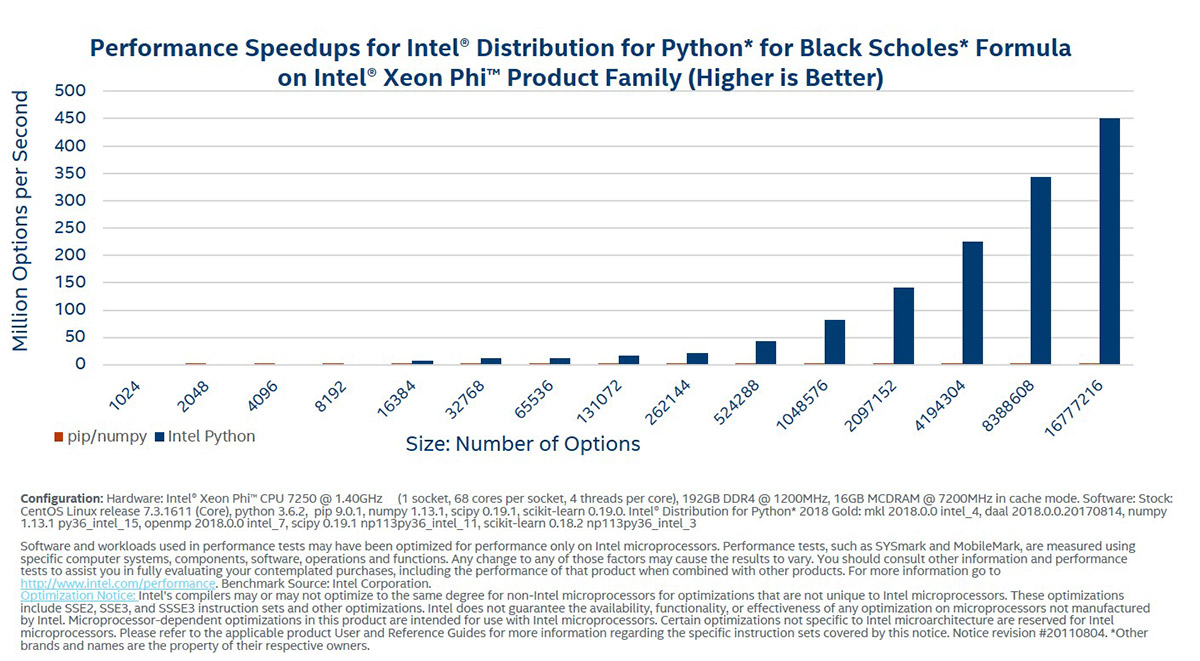
このセットは、インテル® ディストリビューションの Python* と Black-Scholes 式を使用したスピードアップを実証しています。これらの結果は、インテル® oneMKL と併せてネイティブ C を実行することによって得られたパフォーマンスを、パーセンテージで表しています。
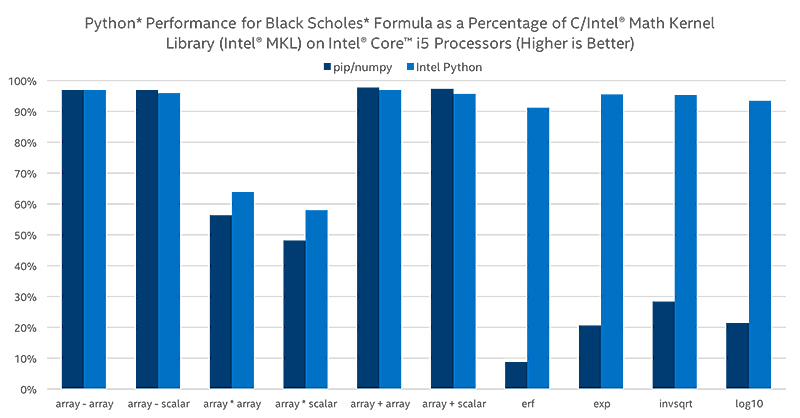
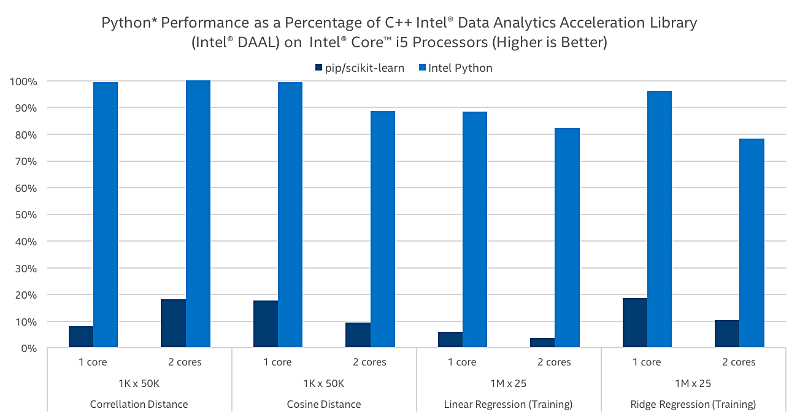
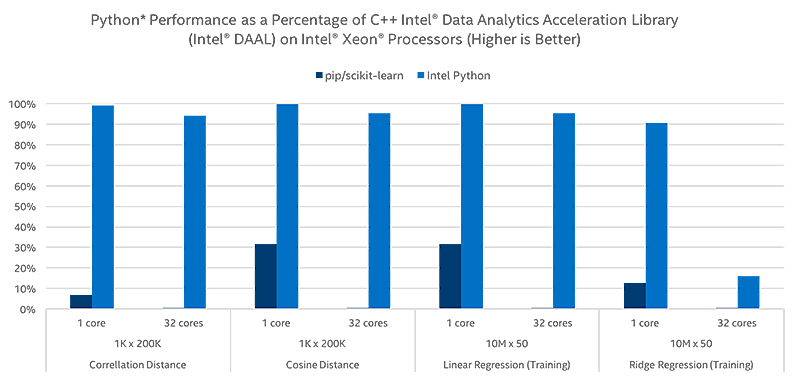
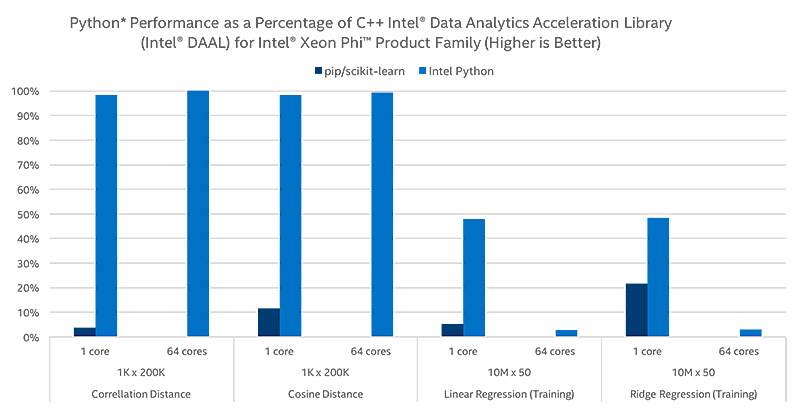
Scikit-learn*
最適化された SciPy ライブラリーと NumPy パッケージは、機械学習の最も一般的なパッケージの 1 つである scikit-learn の広範なスピードアップを提供します。また、インテル® DAAL を利用して、scikit-learn 内の選択されたアルゴリズムに最大 140 倍のスピードを実現しています。
高速フーリエ変換(FFT)
FFTは、信号処理および画像処理において最も重要なアルゴリズムの 1 つです。NumPy と SciPy で FFT を最適化し、現実的で複雑な、一次元および多次元のインプレースおよびアウトオブプレイスの結果を得て、パフォーマンスを最大 60 倍向上させます。
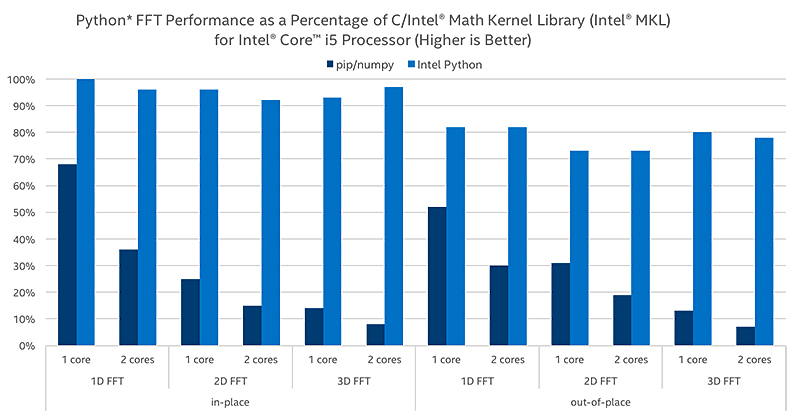
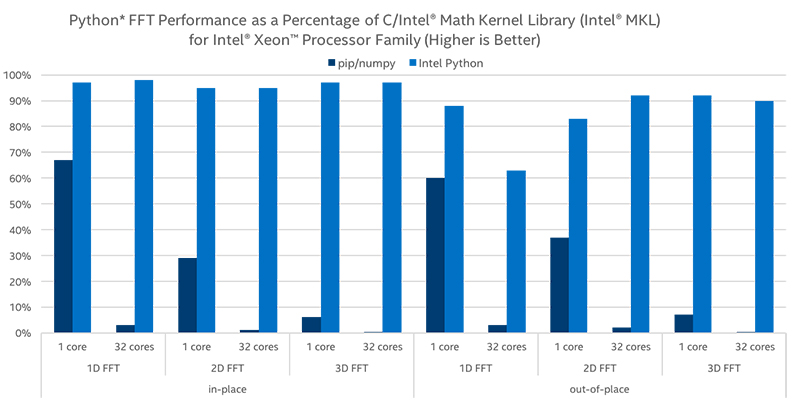
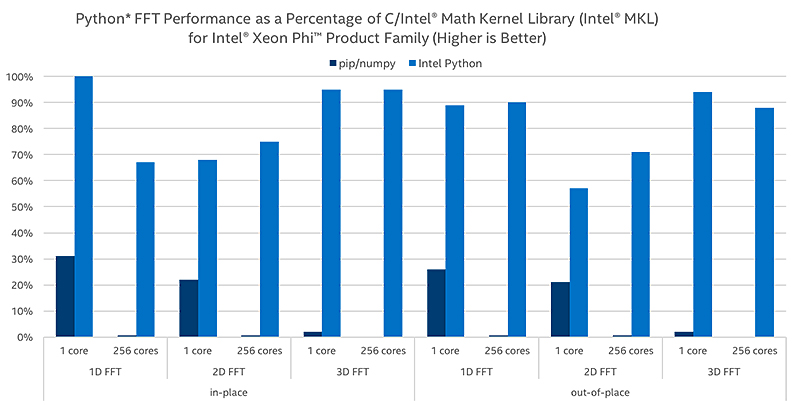
乱数ジェネレーターと一般的なディストリビューションによるパフォーマンス向上
乱数を生成する際、通常、モンテカルロ・シミュレーションと暗号化でボトルネックが発生します。インテル® ディストリビューションの Python* は、さまざまなディストリビューションの生成を最大 56 倍高速化することでこの問題を解決します。インテル® ディストリビューションの Python* の numpy.random_intel パッケージは、Numpy の拡張機能で、numpy.random のデザインを密接に反映し、インテル® oneMKL のベクトル統計を使用して大幅なパフォーマンス向上を実現します。
次の表は、一般的なディストリビューションによるパフォーマンスの改善を示しています。 (100,000 回のサンプリング、256 回繰り返し)
| ディストリビューション | タイミング(random) 秒あたり |
タイミング(random_intel) 秒あたり |
スピードアップ・ファクター |
|---|---|---|---|
| uniform(-1. 1) | 0.357 | 0.034 | 10.52 |
| normal(0, 1) | 0.834 | 0.081 | 10.35 |
| gamma(5.2, 1) | 1.399 | 0.267 | 5.25 |
| beta(0.7, 2.5) | 3.677 | 0.556 | 6.61 |
| randint(0. 100) | 0.228 | 0.053 | 4.33 |
| poisson(7.6) | 2.990 | 0.052 | 57.44 |
| hypergeometric(214, 97, 83) | 11.353 | 0.517 | 21.96 |
法務上の注意書き ※1
全てのベンチマークのシステム構成:
ソフトウェア:
Linux*: Ubuntu*、Python* 3.5.2、NumPy* 1.12.1 (pip でインストール)、scikit-learn 0.18.1
Windows*: Python*
3.5.2、NumPy* 1.12.1 (pip でインストール)、scikit-learn 0.18.1、インテル® ディストリビューションの Python* 2017 Update 2
ハードウェア:
インテル® Core™ i5-4300M プロセッサー、2.60GHz および 2.59GHz (1 ソケット、2 コア、コアあたり 2 スレッド)、8GB DRAM。インテル® Xeon® プロセッサー E5-2698、2.30GHz (2 ソケット、1 ソケットあたり 16 コア、コアあたり 1 スレッド)、64GB DRAM。インテル® Xeon Phi™ プロセッサー 7210、1.30GHz (1 ソケット、64 コア、コアあたり 4 スレッド)、32GB DRAM、16GB MCDRAM (フラット・メモリー・モード)。
変更:
scikit-learn: Windows* 上で conda でインストールされた NumPy* とインテル® oneMKL を使用 (Windows* 上で pip でインストールされた SciPy* はインテル® oneMKL の依存性を含む)。インテル® Core™ i5 プロセッサーのブラックショールズ: Windows* 上で pip でインストールされた NumPy* と conda でインストールされた SciPy* を使用。
※1 性能に関するテストに使用されるソフトウェアとワークロードは、性能がインテル® マイクロプロセッサー用に最適化されていることがあります。SYSmark* や MobileMark*
などの性能テストは、特定のコンピューター・システム、コンポーネント、ソフトウェア、操作、機能に基づいて行ったものです。結果はこれらの要因によって異なります。製品の購入を検討される場合は、他の製品と組み合わせた場合の本製品の性能など、ほかの情報や性能テストも参考にして、パフォーマンスを総合的に評価することをお勧めします。詳細については、
www.intel.com/benchmarks (英語) を参照してください。
最適化に関する注意事項:
インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令
3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂
#20110804
ドキュメント
関連ページ


関連製品

お知らせ
2026年5月、インテル社よりリリースされたインテル® ソフトウェア開発ツールの最新バージョン 2026 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2026 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2023年11月24日、インテル® ディストリビューションの Python* 2024 が同梱されるインテル® ソフトウェア開発ツールに対応する有償サポートサービスの提供を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
2022年12月19日、インテル® ディストリビューションの Python* 2023 が同梱されるインテル® oneAPI 2023 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日、インテル® ディストリビューションの Python* 2022 が同梱されるインテル® oneAPI 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
- インテル® ディストリビューションの Python* は、単体製品としては販売されておりません。
2020年 12月 9日、インテル® ディストリビューションの Python* 2021 が同梱されるインテル® oneAPI 2021 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2021 を無料でダウンロードしてご利用いただけます。
- インテル® ディストリビューションの Python* は、単体製品としては販売されておりません。
2019年 12月 18日、インテル® ディストリビューションの Python* 2020 を同梱したインテル® Parallel Studio XE 2020 の販売を開始しました。
過去にインテル® Parallel Studio XE 製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2020 を無料でダウンロードしてご利用いただけます。
- インテル® ディストリビューションの Python* は、単体製品としては販売されておりません。
2018年 9月 13日、インテル® ディストリビューションの Python* 2019 を同梱したインテル® Parallel Studio XE 2019 の販売を開始しました。
過去にインテル® Parallel Studio XE 製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2019 を無料でダウンロードしてご利用いただけます。
- インテル® ディストリビューションの Python* は、単体製品としては販売されておりません。
FAQ
インテル® Parallel Studio XE の評価版をお申し込みいただくと、コンポーネント・ツールとして、インテル® ディストリビューションの Python* をご利用いただけます。
インテル® Parallel Studio XE の評価版は、 こちらからダウンロードできます。
インテル® ディストリビューションの Python* は、Windows® (7 以降)、Linux* プラットフォームと Python* 2/3 をサポートしています。特定バージョンについての詳細は、 リリースノートを参照してください。
スタンドアロンのインテル® ディストリビューションの Python* は無料で利用できます。フォーラムサポートのみ含まれています。インテル® プレミアサポートは、 インテル® Parallel Studio XE のライセンスを購入すると利用できます。
いいえ。インテル® ディストリビューションの Python* の商用/非商用利用に制限はありません。
インテル® ディストリビューションの Python* は無料で利用できます。フォーラムサポートのみ含まれています。インテル® プレミアサポートは、インテル® Parallel Studio XE を購入すると利用できます。
インテル® プレミアサポートを利用可能なインテル® Parallel Studio XE のライセンスをお持ちの場合は、インテル® ディストリビューションの Python* についてもインテル® プレミアサポートを利用できます。
役立つ記事およびユーザーフォーラムへのリンクは、 www.isus.jp/python-distribution/ (英語) を参照してください。
インテル® ディストリビューションの Python* は、Python* のパフォーマンスを向上してネイティブコードの速度に近づけることに焦点を当てています。そのために、ハイパフォーマンスな Python* アプリケーションを生成するための複数のツール、手法および最適化機能が用意されています。例えば、インテル® マス・カーネル・ライブラリー (インテル® MKL) のようなネイティブ・パフォーマンス・ライブラリーによる NumPy*/SciPy*/scikit-learn の高速化、インテル® スレッディング・ビルディング・ブロック (インテル® oneTBB) によるスレッド化の拡張、pyDAAL、Numba、Cython による高度なデータ解析などの最適化を簡単に行うことができます。
はい。セルフブート型のインテル® Xeon Phi™ プロセッサーをお持ちの方は、追加の指示に従う必要はありません。自動オフロードが必要なインテル® Xeon Phi™ コプロセッサーをお持ちの方は、 インテル® ディストリビューションの Python* の使用 (英語) の指示に従ってください。 詳細は、 リリースノートを参照してください。
インテル社のページからお申し込みください。
なお、無償のインテル® ディストリビューションの Python* には製品サポートは含まれておりません。
ご不明点等は インテル社のフォーラム (英語)をご利用ください。
- インテル® Parallel Studio XE を購入された場合は、インテル® ディストリビューションの Python* についてもサポートサービスが提供されます。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。
以下の情報を参照してください。
- サポート FAQ(英語)
- Python* フォーラム(英語)
- インテル® プレミアサポート(英語) (インテル® プレミアサポートを利用可能なインテル® Parallel Studio XE のライセンスが必要です)