概要
対称型マルチプロセッサー (SMP) システムでは、プロセッサーごとにローカルキャッシュを持っています。このため、メモリーシステムはキャッシュ・コヒーレンシーを保証する必要があります。フォルス・シェアリングは、異なるプロセッサー上のスレッドが同じキャッシュライン上にある変数を変更したときに発生します。変更によりキャッシュラインが無効化され、キャッシュが強制的に更新されることでパフォーマンスが低下します。この記事では、フォルス・シェアリングを検出し修正する方法を説明します。
この記事は、「マルチスレッド・アプリケーションの開発のためのインテル・ガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
フォルス・シェアリングは、プロセッサーごとにローカルキャッシュを持つ SMP システムではよく知られたパフォーマンス問題です。この問題は、図 1 に示すように、異なるプロセッサー上のスレッドが同じキャッシュライン上に置かれた変数を変更したときに発生します。この状況がフォルス・シェアリングと呼ばれるのは、各スレッドが同じ変数へのアクセスを実際に共有していないためです。同じ変数へのアクセスを実際に共有する場合は、プログラムの同期構造を使用して、順序付けされたデータアクセスを保証する必要があります。
フォルス・シェアリングが発生する可能性のあるサンプルコードを次に示します。
double sum=0.0, sum_local[NUM_THREADS];
#pragma omp parallel num_threads(NUM_THREADS)
{
int me = omp_get_thread_num();
sum_local[me] = 0.0;
#pragma omp for
for (i = 0; i < N; i++)
sum_local[me] += x[i] * y[i];
#pragma omp atomic
sum += sum_local[me];
}
9 行目の配列 sum_local でフォルス・シェアリングが発生する可能性があります。この配列はスレッドの数によって次元が決まり、1 つのキャッシュラインに入る程度の大きさです。コードを並列で実行した場合、各スレッドは sum_local の隣接した異なる要素を変更するため、すべてのプロセッサーに対してこのキャッシュラインが無効化されます。
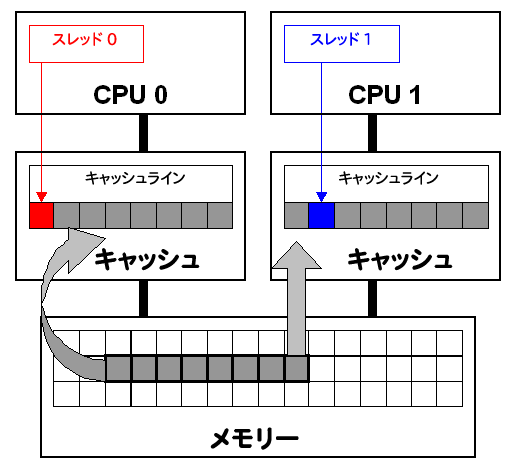
図 1. フォルス・シェアリングは、異なるプロセッサー上のスレッドが同じキャッシュライン上に置かれた変数を変更したときに発生します。変更によりキャッシュラインが無効化され、キャッシュ・コヒーレンシーを維持するためにメモリーが強制的に更新されます。
図 1 で、スレッド 0 とスレッド 1 は、メモリー内で互いに隣接する、同じキャッシュライン上に置かれた変数を要求します。このキャッシュラインは、CPU 0 と CPU 1 のキャッシュにロードされます (グレーの矢印)。各スレッドは異なる変数を変更している (赤と青の矢印) にもかかわらず、キャッシュラインが無効化され、キャッシュ・コヒーレンシーを維持するためにメモリーが強制的に更新されます。
複数のキャッシュにわたるデータの一貫性を保証するために、マルチプロセッサー対応のインテル® プロセッサーでは、MESI (Modified/Exclusive/Shared/Invalid) プロトコルを採用しています。プロセッサーは、最初にキャッシュラインを ‘Exclusive’ (排他) アクセスとしてロードします。キャッシュラインが ‘Exclusive’ としてマークされている間、以降のロードではキャッシュにある既存のデータを自由に使用できます。バス上の別のプロセッサーが同じキャッシュラインをロードすると、キャッシュラインは ‘Shared’ (共有) アクセスに変更されます。プロセッサーが ‘Shared’ としてマークされたキャッシュラインに書き込みを行うと、キャッシュラインは ‘Modified’ (変更) としてマークされ、他のすべてのプロセッサーに ‘Invalid’ (無効) キャッシュ・ライン・メッセージが送られます。‘Modified’ とマークされたキャッシュラインに別のプロセッサーがアクセスすると、プロセッサーはキャッシュラインをメモリーに書き込み、‘Shared’ としてマークします。このとき、同じキャッシュラインにアクセスしている別のプロセッサーは、キャッシュミスになります。
キャッシュラインが ‘Invalid’ としてマークされると、プロセッサー間で頻繁な調整が必要になり、キャッシュラインのメモリーへの書き込みとロードが要求されます。フォルス・シェアリングが発生すると、この調整が増加し、アプリケーションのパフォーマンスが大幅に低下する場合があります。
コンパイラーはフォルス・シェアリングを検出して、フォルス・シェアリングが発生する可能性のあるインスタンスを排除します。例えば、最適化オプションを指定して上記のコードをコンパイルすると、コンパイラーはスレッドプライベートの一時的な変数を使用して、フォルス・シェアリングを排除します。上記のコードのランタイム・フォルス・シェアリングは、最適化を無効にしてコードをコンパイルした場合にのみ問題となります。
アドバイス
フォルス・シェアリングを回避する第一の手法は、コードの検査です。グローバルまたは動的に割り当てられた共有データ構造に複数のスレッドがアクセスするインスタンスは、フォルス・シェアリングの潜在的な原因となります。複数のスレッドが偶然メモリーの比較的近い場所にある完全に異なるグローバル変数にアクセスして起こるフォルス・シェアリングを検出することは困難です。スレッド・ローカル・ストレージやローカル変数は、フォルス・シェアリングの原因としては除外して良いでしょう。
インテル® VTune™ パフォーマンス・アナライザーやインテル® パフォーマンス・チューニング・ユーティリティー (インテル®PTU、詳細は http://software.intel.com/en-us/articles/intel-performance-tuning-utility/ を参照) を使用すると、ランタイムの検出が可能です。この方法は、イベント・ベース・サンプリングを使用して、キャッシュラインの共有がパフォーマンスに顕著に影響を与える場所を発見します。ただし、この方法では、真の共有とフォルス・シェアリングが区別されません。
インテル® Core™2 プロセッサー・ベースのシステムの場合、MEM_LOAD_RETIRED.L2_LINE_MISS イベントと EXT_SNOOP.ALL_AGENTS.HITM イベントをサンプリングするようにインテル® VTune パフォーマンス・アナライザーまたはインテル® PTU を設定します。インテル® Core i7 プロセッサー・ベースのシステムの場合、MEM_UNCORE_RETIRED.OTHER_CORE_L2_HITM イベントをサンプリングするように設定します。インテル® Core™2 プロセッサー・ファミリーの一部のコード領域で EXT_SNOOP.ALL_AGENTS.HITM イベントが INST_RETIRED.ANY イベントよりも多く高頻度で発生する場合、またはインテル® Core i7 プロセッサー・ファミリーで MEM_UNCORE_RETIRED.OTHER_CORE_L2_HITM イベントが高頻度で発生する場合、真の共有またはフォルス・シェアリングが存在します。スレッド内のロード/ストア命令またはその近くで、対応するシステムに応じて MEM_LOAD_RETIRED.L2_LINE_MISS イベントまたは MEM_UNCORE_RETIRED.OTHER_CORE_L2_HITM イベントが集中するコードを検査して、同じキャッシュライン上にあるメモリーの場所でフォルス・シェアリングが発生する可能性を判断します。
インテル®PTU には、フォルス・シェアリングの特定に役立つイベントを収集するようにあらかじめ定義されたプロファイル設定、[Intel® Core™2 processor family – Contested Usage] および [Intel® Core™ i7 processor family – False-True Sharing] が用意されています。インテル®PTU の Data Access 解析は、異なるスレッドによってアクセスされた同じキャッシュラインの異なるオフセットを監視して、フォルス・シェアリングの候補を識別します。Data Access View でプロファイリング結果を開くと、図 2 に示すように、[Memory Hotspots (メモリー hotspot)] ペインに、キャッシュラインの粒度でフォルス・シェアリングに関するヒントが表示されます。
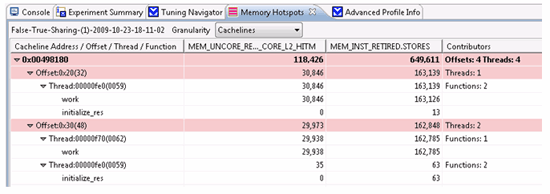
図 2. インテル®PTU の [Memory Hotspots (メモリー hotspot)] ペインに表示されたフォルス・シェアリング。
図 2 では、(アドレス 0x00498180 でキャッシュラインの) メモリーオフセット 32 と 48 が、work 関数で、ID=59 のスレッドと ID=62 のスレッドによってアクセスされています。ID=59 のスレッドによって行われた配列初期化による真の共有もあります。
ピンクの行は、キャッシュライン上のフォルス・シェアリングのヒントとなる行です。キャッシュラインと対応するオフセットに関連した MEM_UNCORE_RETIRED.OTHER_CORE_L2_HITM の高い数値に注意してください。
検出されたフォルス・シェアリングを修正するには、いくつかの方法があります。目標は、フォルス・シェアリングの原因となる変数が同じキャッシュライン上に置かれないように、メモリー内で十分な距離を保証することです。ここでは、3 つの方法を説明します。
1 つは、コンパイラーの宣言子を使用して、強制的に個々の変数のアライメントを合わせる方法です。以下のソースコードは、コンパイラーの __declspec (align(n)) 文 (n=64、64 バイト境界) を使用して、個々の変数をキャッシュライン境界にアライメントする方法を示しています。
__declspec (align(64)) int thread1_global_variable;
__declspec (align(64)) int thread2_global_variable;
データ構造の配列を使用する場合、配列要素がキャッシュライン境界で開始するように、キャッシュラインの最後にデータ構造をパディングするのも 1 つの方法です。配列がキャッシュライン境界にアライメントされることを保証できない場合には、キャッシュラインのサイズの 2 倍になるようにデータ構造をパディングします。以下のソースコードは、コンパイラーの __declspec (align(n)) 文 (n=64、64 バイト境界) を使用して、キャッシュライン境界に合わせてデータ構造をパディングし、配列のアライメントを保証する方法を示しています。配列が動的に割り当てられる場合、割り当てサイズを大きくして、キャッシュライン境界にアライメントされるようにポインターを調整できます。
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; // Frequent read/write access variable
unsigned long start;
unsigned long end;
// expand to 64 bytes to avoid false-sharing
// (4 unsigned long variables + 12 padding)*4 = 64
int padding[12];
};
__declspec (align(64)) struct ThreadParams Array[10];
データのスレッドローカルなコピーを使用して、フォルス・シェアリングの頻度を減らすこともできます。スレッドローカルなコピーは、頻繁に読み取りおよび編集可能で、完了したときに結果をデータ構造に書き込んで戻します。以下のソースコードは、ローカルコピーを使用してフォルス・シェアリングを回避する方法を示しています。
struct ThreadParams
{
// For the following 4 variables: 4*4 = 16 bytes
unsigned long thread_id;
unsigned long v; //Frequent read/write access variable
unsigned long start;
unsigned long end;
};
void threadFunc(void *parameter)
{
ThreadParams *p = (ThreadParams*) parameter;
// local copy for read/write access variable
unsigned long local_v = p->v;
for(local_v = p->start; local_v < p->end; local_v++)
{
// Functional computation
}
p->v = local_v; // Update shared data structure only once
}
利用ガイド
フォルス・シェアリングは回避する必要がありますが、これらの手法を使用する際には注意が必要です。必要以上にこれらの手法を使用すると、プロセッサーの利用可能キャッシュを効果的に使用できなくなります。マルチプロセッサー共有型のキャッシュ設計でも、フォルス・シェアリングを回避することを推奨します。一般的に、マルチプロセッサー共有型のキャッシュ設計でキャッシュの利用率を最大限に上げることから得られる多少の高速化のメリットよりも、キャッシュ・アーキテクチャーごとに異なるコードパスをサポートするのに必要なソフトウェア保守コストの負担の方が大きくなります。
注)この記事で紹介する、インテル® VTune™パフォーマンス・アナライザーは、旧世代のツールです。同様のことは、インテル® VTune™ Amplifier XE を使用することができます。