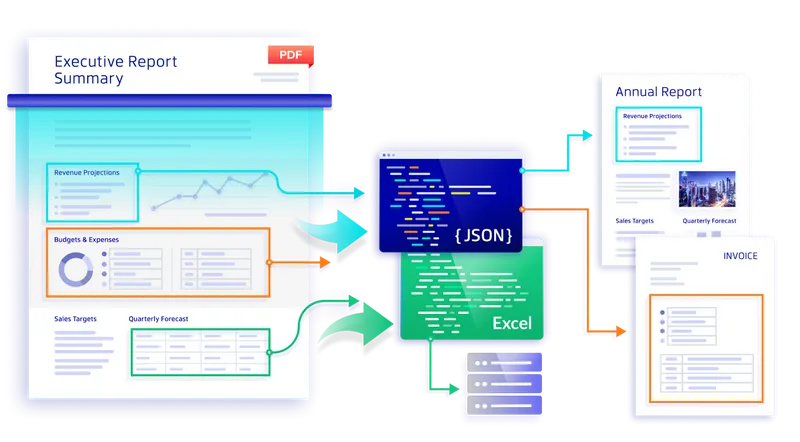
コンテキストを認識した出力で、ダウンストリームのワークフローを強化します。複雑な PDF 文書の構造を自動的に解析し、キーバリューペアやネストされたテーブルを信頼性の高い構造化フォーマットに変換します。
KYC、契約上の義務など、さまざまな規制へのコンプライアンスを証明するために必要なデータとコンテキストを自動的に抽出します。
長大な文書をコンテキスト対応メタデータを含む構造化された検索可能なフォーマットに変換します。
PDF から借り手情報、金利、担保情報を抽出して構造化データセットに正規化します。審査プロセスを加速し、規制レポートにもそのまま活用できます。
静的な法律文書をアクション可能なインテリジェンスに変換します。リスクスコアリングの自動化、更新アラートのトリガー、法的なデューデリジェンスの手作業を削減します。
Apryse の Web SDK と Server SDK を組み合わせることで、
機械的なインテリジェンスと人間による監視および検証を連携させ、
非構造化コンテンツを自動化対応データに変換できます。
埋め込み可能な SDK により、柔軟なデプロイが可能です。拡張性の高いこのツールキットは、増大するデータ アクセス ニーズに応じてスケールしながら、コストを適切にコントロールできます。
データはお客様のインフラストラクチャの外に出ることはありません。オンプレミス、プライベート クラウド、エアギャップ環境を問わず、完全なコントロールを提供します。
セマンティック コンテキストとエンティティ認識を付加した独自モデルにより、コンテキストを理解した高精度な抽出を実現します。ダウンストリーム処理のパフォーマンス向上に貢献します。
PDF から構造を抽出することは容易ではありません。テキストが選択できない場合や、テーブルに基本タグが存在しない場合も多くあります。Apryse はこの課題を、高度なコンピュータービジョンでレイアウトとセマンティクスを理解することで解決しています。リアルタイム物体検出 (YOLO) でテーブルやセクションを識別し、BERT ベースのモデルでテキストの意味を解決します。これらは汎用モデルではなく、契約書やフォームなどの高度な要件が求められる文書向けに目的を絞ってトレーニングされたモデルです。さらに、モデルはパブリック データと合成データのみでトレーニングされており、お客様の文書がトレーニングに使用されることはありません。
QR コード、UPC、Data Matrix など、1D/2D の各種バーコード フォーマットからデータを簡単に抽出します。製品ラベル、配送情報、在庫タグなど、あらゆるバーコード データを高精度でキャプチャします。
バーコード抽出と OCR (光学式文字認識) を組み合わせ、包括的な文書自動化を実現します。バーコード データとテキスト ベースのコンテンツを 1 つのプロセスでキャプチャし、手作業を削減して効率を高めます。
バーコード抽出は精度を犠牲にすることなく高速なデータ キャプチャを実現します。物流、小売、医療などリアルタイムの情報取得が求められる業種に最適です。

スマートデータ抽出とは、AI と機械学習技術を活用して、さまざまな文書フォーマットからデータを自動的に抽出、理解、処理する機能です。非構造化データを構造化されたアクション可能な情報に変換します。
SDK はスキーマ対応の構造化された出力を提供します。通常は JSON、XML、または Excel 形式で出力されるため、手動によるデータのクリーニングなしに、ダウンストリームのアプリケーション、ERP システム、AI/LLM パイプラインに直接統合できます。
はい、対応しています。Apryse のスマートデータ抽出ソリューションは、業種固有の文書フォーマットやデータ タイプを認識して処理できるようカスタマイズ可能です。データ抽出の高精度と妥当性を確保します。
固定座標に依存するのではなく、ビジュアル レイアウト分析とセマンティック理解を組み合わせています。ラベル (キー、例: 「請求書番号」) と対応するデータ (バリュー、例: 「INV-001」) の空間的な関係を「認識」し、空白や複雑なフォーム内にネストされた場合でも正確に抽出します。事前に定義されたゾーンを必要とせず、さまざまな文書テンプレートに対応します。
文書の分類はページ レベルで行われ、ファイル内のすべてのページに対して文書タイプと信頼スコアが割り当てられます。このきめ細かいアプローチにより、請求書、契約書、メモが 1 つの PDF にまとまった「マルチ文書パケット」を正確に識別して分割し、各コンポーネントを適切なダウンストリーム パイプラインや担当者にルーティングできます。
はい、Apryse のバーコード抽出は、損傷、傾き、低品質なバーコードも正確に読み取ることができます。厳しい条件下でも信頼性の高いパフォーマンスを発揮します。
ライセンス、価格、お見積りなど、本製品に関するご質問、ご不明な点は エクセルソフトまでお気軽にお問い合わせください。