インテル® C++ コンパイラー・クラシック提供終了に関するご案内:
開発元であるインテル社の方針により、2023 年後半の oneAPI リリースで、インテル® C++ コンパイラー・クラシック (icc) の提供を終了させていただきました。
インテルでは、引き続き Windows* および Linux* サポート、新しい言語サポート、新しい言語機能、最適化をご利用いただくために、LLVM ベースのインテル® oneAPI DPC++/C++ コンパイラー (icx) へ移行することを推奨しています。
今後の対応などの提供終了に関する詳細は、お知らせ/FAQ の「インテル® C++ コンパイラー・クラシックの提供終了」に関する案内をご確認ください。
インテル® Fortran コンパイラー・クラシック提供終了に関するご案内:
現在、インテル® Fortran コンパイラー・クラシック (ifort) は、バージョン 2024 より非推奨とされ、バージョン 2025 のリリースに伴い提供終了となりました。
インテルでは、引き続き Windows* および Linux* サポート、新しい言語サポート、新しい言語機能、最適化のために、今すぐ LLVM ベースのインテル® Fortran コンパイラー (ifx) へ移行することを推奨しています。
今後の対応などの提供終了に関する詳細は、お知らせ/FAQ の「インテル® Fortran コンパイラー・クラシックの提供終了」に関する案内をご確認ください。
概要
高速なプログラムを作成するための C/C++、Fortran コンパイラー

製品紹介資料

コンパイラー日本語版
日本の開発者のためのコンパイラー
インテル® Parallel Studio XE for Windows/Linux に同梱されるインテル® コンパイラーは日本語版が提供されており、以下の項目が日本語化されています。
- コマンドライン上のコンパイラー・メッセージ
- IDE 上のコンパイラー・メッセージ
- 製品マニュアル
2019年 12月 18日、最新インテル® コンパイラー 19.1 日本語版が含まれた、インテル® Parallel Studio XE 2020 for Windows/Linux の提供が開始されました。
インテル ® Parallel Studio XE for Windows/Linux のサポートサービスが有効なお客様は、最新日本語版コンパイラーの提供開始後、最新日本語版が含まれるインテル® Parallel Studio XE 2020 を無料でダウンロードしてご利用いただけます。
ダウンロード可能なバージョンはこちら (英語) からご参照ください。
| 提供開始日 | インテル® Parallel Studio XE | インテル® コンパイラー |
|---|---|---|
| 2019.12.18 | 2020 | 19.1 英語版 + 日本語版 |
| 2018.11.9 | 2019 Update1 | 19.0 Update1 英語版 + 日本語版 |
| 2018.9.13 | 2019 | 19.0 英語版 |
| 2017.11.16 | 2018 Update1 | 18.0 Update1 英語版 + 日本語版 |
| 2017.9.14 | 2018 | 18.0 英語版 |
| 2016.11.2 | 2017 Update1 | 17.0 Update1 英語版 + 日本語版 |
| 2016.9.7 | 2017 | 17.0 英語版 |
| 2015.11.19 | 2016 Update1 | 16.0 Update1 英語版 + 日本語版 |
| 2015.8.26 | 2016 | 16.0 英語版 |
| 2014.11.5 | 2015 Update1 | 15.0 Update1 英語版 + 日本語版 |
| 2014.8.27 | 2015 | 15.0 英語版 |
デベロッパー・ガイドおよびリファレンス、チュートリアルの日本語版を公開中!
インテル® Parallel Studio XE Composer Edition 日本語版は、インテル® コンパイラーおよびライブラリー (インテル ® MKL、インテル® IPP、インテル® TBB、インテル® DAAL) のコンパイル時のメッセージやドキュメントが日本語化されています。
Professional Edition、Cluster Edition にも Composer Edition 日本語版が含まれます。
【デベロッパー・ガイドおよびリファレンス目次】
- コマンドラインまたは IDE からコンパイラーを起動する方法
- OpenMP* サポート
- コンパイラー・オプション
- 組込み関数 (C++ のみ)
- プラグマ (C++ のみ)
- 構文やセマンティクス、さまざまな Fortran 標準への準拠、および各種標準の拡張に関する情報 (Fortran のみ、英語)
- Fortran 言語拡張 (Fortran のみ)
- 言語が混在したプログラミング (Fortran のみ)
- ランタイム・エラー・メッセージのリスト (Fortran のみ)
【チュートリアル】
- 自動ベクトル化の使用
- アプリケーションのスレッド化
- インテル® グラフィックス・テクノロジーの使用
- Co-Array Fortran の使用
『インテル® C++/Fortran コンパイラー 19.1 のデベロッパー・ガイドおよびリファレンス』 の日本語版は、 こちらのページから下記のいずれかの製品の評価版をご登録いただくことで、入手いただけます。
ご登録後にお客様宛に送られるダウンロード方法案内のメール内で、最新日本語版ガイドのダウンロード方法についてもご案内しております。
- インテル® Parallel Studio XE Cluster Edition for Windows
- インテル® Parallel Studio XE Cluster Edition for Linux
製品種類
コンパイラーを利用する
インテル ® コンパイラーは様々な最適化向けコンポーネントを含むスイート製品にて提供されています。

同梱されるコンパイラーは プログラミング言語と OS 毎に分かれており、それぞれ対応したスイート製品に含まれます。
一覧
| コンパイラーを同梱するスイート製品 | コンパイラー | 言語 | |
|---|---|---|---|
| インテル® Parallel Studio XE |
for Fortran & C++ Windows | Fortran コンパイラー for Windows | 英語/日本語 |
| C/C++ コンパイラー for Windows | 英語/日本語 | ||
| for Fortran & C++ Linux | Fortran コンパイラー for Linux | 英語/日本語 | |
| C/C++ コンパイラー for Linux | 英語/日本語 | ||
| for C++ Windows | C/C++ コンパイラー for Windows | 英語/日本語 | |
| for C++ Linux | C/C++ コンパイラー for Linux | 英語/日本語 | |
| for C++ macOS | C/C++ コンパイラー for macOS | 英語 | |
| for Fortran Windows | Fortran コンパイラー for Windows | 英語/日本語 | |
| for Fortran Linux | Fortran コンパイラー for Linux | 英語/日本語 | |
| for Fortran macOS | Fortran コンパイラー for macOS | 英語 | |
| インテル® System Studio | for Windows | C/C++ コンパイラー for Windows | 英語 |
| for Linux ※1 | C/C++ コンパイラー for Linux | 英語 | |
| C/C++ コンパイラー for Android | 英語 | ||
| ※1 | インテル® System Studio for Linux には、Linux* 向け機能と Android* 向け機能が両方同梱されています。 各スイート製品に同梱される機能一覧については、 こちらのページを参照ください。 |
C/C++ コンパイラー (インテル® oneAPI)
概要
インテル ® C/C++ コンパイラーは、最新のインテル ® プラットフォーム上で最新の言語標準規格 (C++17 ドラフトまで) を実装します。
開発者は、優れた最適化と SIMD ベクトル化、インテル ® パフォーマンス・ライブラリーとの統合、最新の OpenMP* 5.0 並列プログラミング・モデルの活用により、アプリケーションのパフォーマンスを向上できます。
主要な開発環境とのシームレスな統合により、開発者の生産性を高めます。
Visual C++* コンパイラーおよび GNU* C コンパイラーとソース互換です。拡張された最適化レポートとインテル
® VTune™ プロファイラーおよびインテル ® Advisor の統合により、開発者はコードのプロファイルを制御できます。
バージョン 19.1 新機能
主に以下の変更・機能が追加されました。詳細は、 リリースノートを参照ください。
-
C++20 の機能をサポート
標準規格に基づく並列化により C++ 開発者を支援 -
OpenMP* 5.0 の機能サポートを拡張
最新の並列化仕様によりコードを現代化 -
インテル® C++ コンパイラーの次世代コード・ジェネレーターへのアクセス
/Qnextgen コンパイラー・オプションにより次世代コード・ジェネレーターを起動
標準規格に基づく並列化により C++ 開発者を支援
- C++17 の初期サポート、C++ 14 の完全サポート (一部機能を除く)
- OpenMP* 4.0 およびそれ以降の機能の更なるサポート拡張
- OpenMP* 5 の初期サポート
優れた並列パフォーマンスを実現
- (OpenMP* を使用した) ベクトル化とスレッド化により、インテル® AVX-512 命令を含む最新の SIMD (single-instruction-multiple-data) 対応ハードウェアを最大限に活用
- インテルのベクトル化ツールについて (iSUS)
妥協のないパフォーマンス
アプリケーションのパフォーマンスを向上したいのであれば、開発サイクルにインテル® C++ コンパイラーを導入してください。これは、パフォーマンス向上のため複数のコアと広いベクトルレジスターなどの高度なプロセッサー機能を利用するように最適化されています。
- インテルおよび互換プロセッサー上で、業界をリードするパフォーマンスを提供。
- インテル® Xeon® スケーラブル・プロセッサー、 インテル® Xeon Phi™ プロセッサーを含む最新のインテル® プロセッサー向けの幅広い最適化
使い慣れた開発環境で動作
- 慣れ親しんだ Visual Studio* IDE 上で開発、ビルド、デバッグ、そして実行できます
- Microsoft* Visual Studio* 2013、2015、そして 2017 で動作します
- Visual C++* とソースおよびバイナリーと互換性があります
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
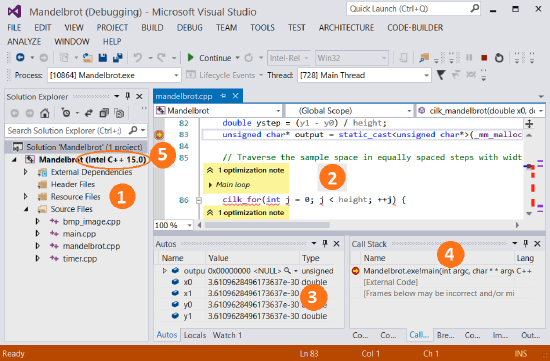
- Microsoft* Visual Studio* のプロジェクトとソース
- C/C++ に対応したテキストエディター
- C/C++ コードのデバッグ
- コールスタック情報
- IDE 上で実際のソースコードにブレークポイントを設定
使い慣れた開発環境で動作
- Eclipse* IDE インターフェイスもしくはコマンドラインを使用して開発、ビルド、デバッグ、そして実行できます
- GCC とソースおよびバイナリーと互換性があります
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
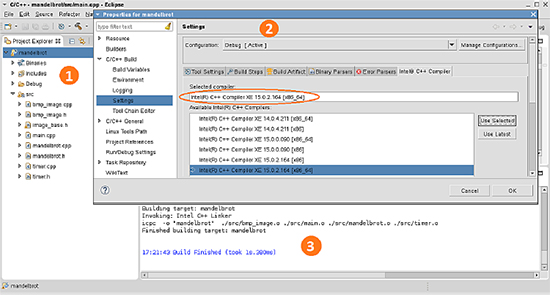
- プロジェクトとソース
- プロジェクト・プロパティーでコンパイラーを選択
- 出力ウィンドウ
使い慣れた開発環境で動作
- 慣れ親しんだ Xcode* IDE 上で開発、ビルド、デバッグ、そして実行できます
- Xcode と動作します
- LLVM-GCC および Clang * ツールチェーンとのソースおよびバイナリーと互換性があります
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
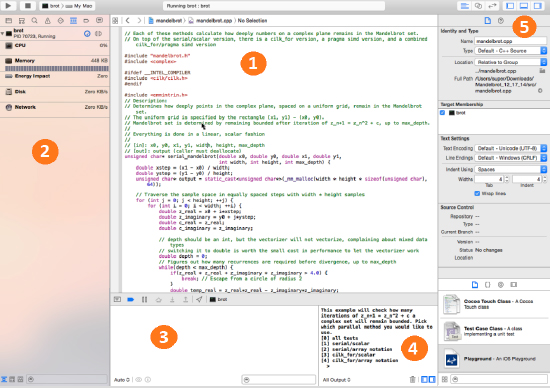
- ソースコード・ウィンドウ
- アプリケーション・デバッグの概要
- 変数とレジスターのデバッグ
- 出力ウィンドウ
- ファイル詳細ウィンドウ
Fortran コンパイラー (インテル® oneAPI)
概要
インテル ® Fortran コンパイラーは、最新のインテル ® プラットフォーム上で最新の Fortran 言語標準規格を実装して、アプリケーションのパフォーマンスを向上します。
Fortran 2008 (および Fortran 2015 ドラフト) 標準規格をサポートし、インテル ® マス・カーネル・ライブラリー (インテル ® MKL) との互換性があります。FORTRAN 77 との互換性もあります。
OpenMP* 並列プログラミング仕様を利用して、スレッド化とベクトル化を行うことでパフォーマンスをさらに向上できます。ツールは主要な開発環境とシームレスに統合され、開発者の生産性を高めます。
また、拡張された最適化レポートとインテル ® VTune™ プロファイラーおよびインテル ® Advisor
の統合により、開発者はコードのプロファイルを制御できます。
バージョン 19.1 新機能
主に以下の変更・機能が追加されました。詳細は、 リリースノートを参照ください。
-
Fortran 2018 の大部分をサポート
-
C との相互運用機能の強化により言語が混在した開発を効率化
-
強化された Co-Array 機能により Fortran モダンコードを並列化
-
OpenMP* 5.0 機能サポートを拡張
ユーザー定義のリダクションによるリダクション操作のカスタマイズ
インテル® Fortran コンパイラーを選ぶ理由
Fortran アプリケーションのパフォーマンス向上を検討していますか?
インテル® Fortran コンパイラーは、高いパフォーマンスのアプリケーションをビルドする業界をリードするコンパイラーです。インテル® Fortran コンパイラーの導入を検討すべきいくつかの理由があります。
- インテル® Xeon® スケーラブル・プロセッサーと インテル® Xeon Phi™ プロセッサーで利用可能なコア数とベクトルレジスターの利点を活用することで、コードをさらに高速に実行することができます。
- 標準仕様に基づいて移植が容易なコードを作成します。
- 任意のプラットフォーム上で、使い慣れたツールセットとともに利用できます。Windows*、Linux*、そして macOS* 間でソース互換がある業界をリードする Fortran コンパイラーです。
妥協のないパフォーマンス
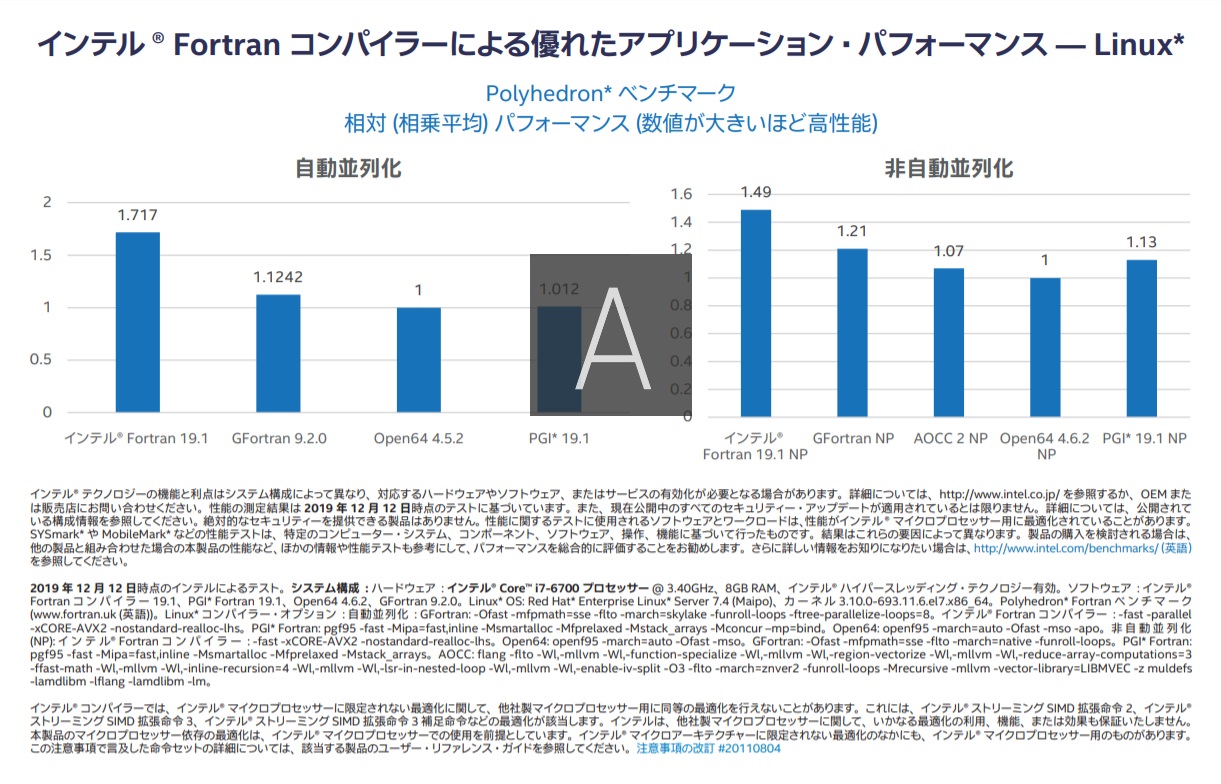
- インテルおよび互換プロセッサー上で、業界をリードするパフォーマンスを提供。
- インテル® Xeon® スケーラブル・プロセッサー、 インテル® Xeon Phi™ プロセッサーを含む最新のインテル® プロセッサー向けの幅広い最適化
- OpenMP* や自動並列化、DO CONCURRENT、Co-Array によるマルチコア、メニーコア、そしてマルチプロセッサー・システムの利点を活用
- 特許取得済みの自動 CPU ディスパッチ機能は、実行中のプロセッサー向けに最適化されたコードを選択します
標準規格に基づく並列化により Fortran 開発者を支援
- Fortran 2008 の完全サポート (一部機能を除く)
- サブモジュール、BLOCK、優れた Co-Array パフォーマンス
- Fortran 2015 (ドラフト) の初期サポート
- C との互換性が向上 (ISO/IEC TS 29113:2012)
- OpenMP* 4.5 の完全サポート、OpenMP* 5 の初期サポート
- 標準 API によるスレッド化とベクトル化
使い慣れた開発環境で動作
- Microsoft* Visual Studio* 2013、2015、そして 2017 で動作
- Visual Studio* をお持ちでない場合。心配ありません。Microsoft* Visual Studio* 2015 Shell 上の Fortran 開発環境が含まれます。追加で何も購入する必要はありません!
※本製品のバージョン 2019 Update3 以降は、Visual Studio 2015 Shell* が同梱されておりませんので、Visual Studio* を使用して本製品をご利用ください。 - 使い慣れた Visual Studio* IDE から開発、ビルド、デバッグ、そして実行するか、コマンドラインからビルドと実行するかは、開発者が選択できます
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
- 伝統的なコンソール・アプリケーションや QuickWin、OpenGL*、そして Windows* API による高度なグラフィカル・インターフェイスの作成をサポートします
- COM (Component Object Model) と .NET の相互運用が可能です
- C++、Visual Basic*、Microsoft* C# など、ほかの言語が混在するアプリケーションのビルドが可能です (Microsoft* Visual Studio* が必要です)
- Windows* API、OpenGL*、POSIX*、ダイアログ、マルチバイト文字などのサポートのため、ルーチン、型、そして定数の数万もの宣言を提供します
- インテル® MKL と連携できます
Visual Studio* へのインテル® Fortran コンパイラーの統合
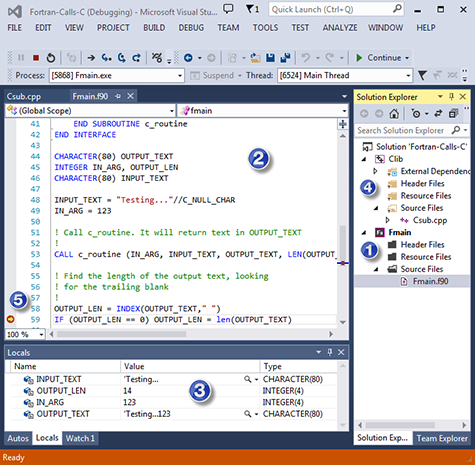
- Visual Studio* 中の Fortran プロジェクトとソースファイル
- Fortran 対応のテキストエディター (コンテキスト・ヘルプ、Go to 定義、テンプレート、色分けなど)
- Fortran の型と配列へのフルアクセスによる Fortran コードのデバッグ
- 単一の Visual Studio* ソリューションで、言語が混在するプログラムのビルドとデバッグ
- Fortran のソース行で、条件付きのブレークポイントを設定
使い慣れた開発環境で動作
- Eclipse* IDE インターフェイスもしくはコマンドラインを使用して開発、ビルド、デバッグ、そして実行できます
- gdb デバッガ=を含む GNU コンパイラー・コレクション (GCC) ツールを使用可能です
- gcc からの C および C ++ とのリンク互換性があります
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
- インテル® MKL と連携します
使い慣れた開発環境で動作
- 慣れ親しんだ Xcode* IDE 上で開発、ビルド、デバッグ、そして実行できます
- GCC からの C および C++ とのリンク互換性があります
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
- インテル® MKL と連携します
C/C++ コンパイラー (インテル® System Studio)
システム/IoT デバイス・アプリケーションのパフォーマンスを向上
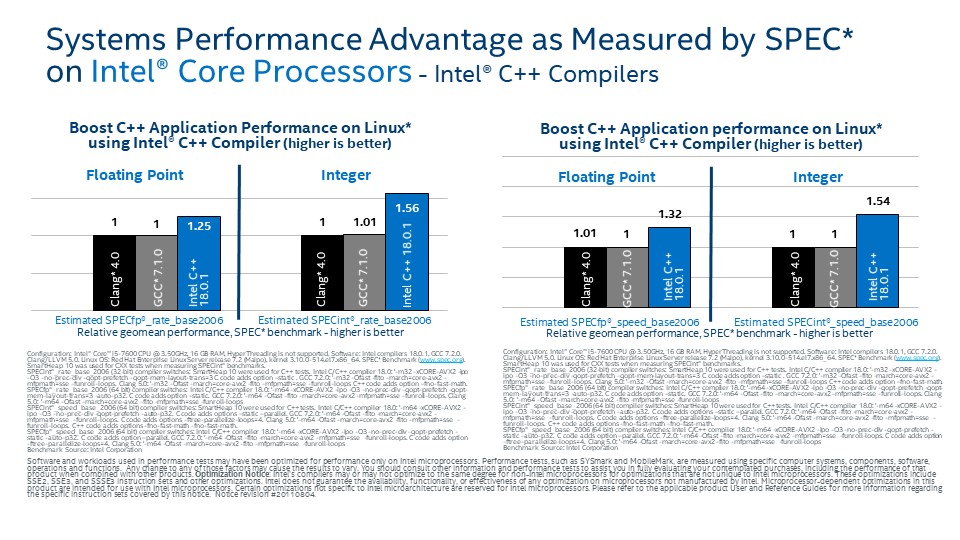
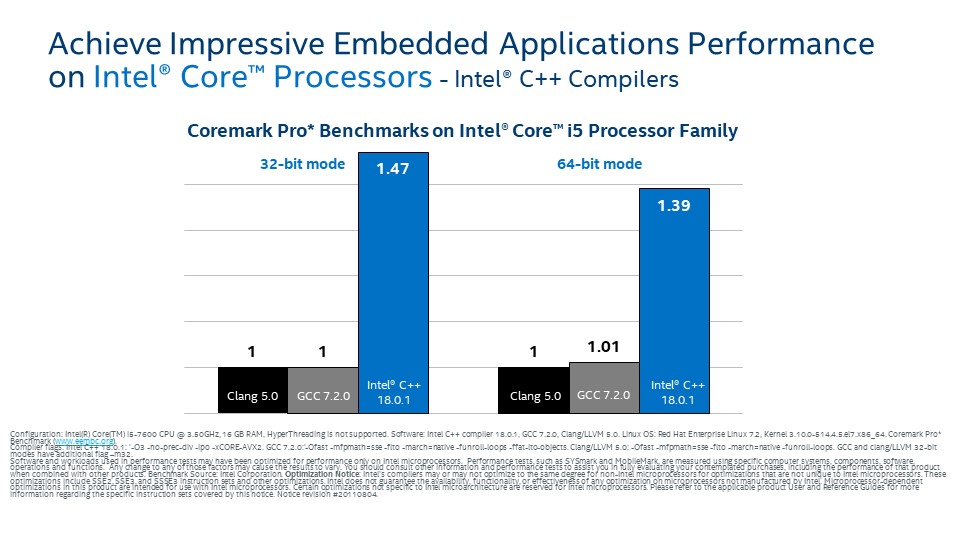
- 高レベルのタスクベース並列処理とデータ並列処理向けのベクトル化を効率良く実装する堅牢な C/C++ コンパイラー
- 多くのコンパイラーと互換性があり、さまざまな OS 間で移植性があります
インテル® C++ コンパイラーは、IoT デバイス・アプリケーションおよびシステムの処理速度向上を支援します。現代のプロセッサーの増加するコア数を活用するため、簡単にコードをビルドするだけで業界をリードするパフォーマンスを提供します。
C/C++ 開発の追加機能に加え、現在および以前の C/C++ 標準を幅広くサポートします。
バージョン 19.1 新機能
主に以下の変更・機能が追加されました。詳細は、 リリースノートを参照ください。
-
OpenMP* 並列プラグマのユーザー定義誘導サポート
-
C++17 新機能のサポート
-
デフォルト設定された Qopenmp-simd
-
cannonlake オプションのサポート
-
C++17 の新機能のサポート
-
プラグマベクトルの nodynamic_align とvectorlength 句のサポート
-
OpenMP* TR6 バージョン 5.0 プレビュー 2 の一部サポートの拡張
最新のおよび以前の C と C++ 標準に加え、注目される拡張機能を幅広くサポート
- C++11、C++17 言語標準化をサポート (一部機能を除く)
» C++11 サポートの詳細 (iSUS)
C と C++ 開発向けのドロップイン追加
- 慣れ親しんだ Visual Studio* IDE 上で開発、ビルド、デバッグ、そして実行
- Microsoft* Visual Studio* 2013、2015、そして 2017 で動作
- Visual C++* とソースおよびバイナリー互換
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
- Microsoft* Visual Studio* のプロジェクトとソース
- C/C++ に対応したテキストエディター
- C/C++ コードのデバッグ
- コールスタック情報
- IDE 上で実際のソースコードにブレークポイントを設定
C と C++ 開発向けのドロップイン追加
- Eclipse* IDE インターフェイスもしくはコマンドラインを使用して開発、ビルド、デバッグ、そして実行
- GCC 4.3 ~ 6.x をサポート
- 本製品は 64 ビット OS のみにインストールすることができ、32 ビット/64 ビット の両方のバイナリーを開発することができます
- プロジェクトとソース
- プロジェクト・プロパティーでコンパイラーを選択
- 出力ウィンドウ
ドキュメント
関連ページ



関連製品


インテル® Parallel Studio XE
- C/C++ コンパイラー for Windows
- C/C++ コンパイラー for Linux
- C/C++ コンパイラー for macOS
- Fortran コンパイラー for Windows
- Fortran コンパイラー for Linux
- Fortran コンパイラー for macOS
インテル® System Studio
C/C++ コンパイラー for Windows* (インテル® Parallel Studio XE)
| ホスト OS |
IA-32 ホスト OS へのインストールのサポートを終了のご案内 |
| 開発環境 |
IA-32 対応アプリケーションまたはインテル® 64 対応アプリケーションのビルドに、Microsoft* Visual Studio* 開発環境あるいはコマンドライン・ツールを使用する場合は、次のいずれか:
インテル® 64 対応アプリケーションのビルドに、コマンドライン・ツールのみを使用する場合は、次のいずれか:
|
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
4GB (すべての機能をインストールする場合) |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
C/C++ コンパイラー for Linux* (インテル® Parallel Studio XE)
| ホスト OS |
次の Linux* ディストリビューションのいずれか (本リストは、インテル社により動作確認が行われたディストリビューションのリストです。その他のディストリビューションでも動作する可能性はありますが、推奨しません。ご質問は、テクニカルサポートまでお問い合わせくださ い。)
IA-32 ホスト OS へのインストールのサポートを終了のご案内 |
| Linux* 開発ツール・コンポーネント (gcc、g++ および関連ツールを含む) |
|
| -traceback オプション | -traceback オプションを使用するには、libunwind.so が必要です。一部の Linux* ディストリビューションでは、別途入手して、インストールする必要があります。 |
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
14GB (すべての機能をインストールする場合) |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
C/C++ コンパイラー for macOS* (インテル® Parallel Studio XE)
| ホスト OS |
次の macOS*、Xcode*、Xcode SDK の組み合わせのいずれか。
64 ビットインテル® ベースの Apple* Mac* システムホスト (32 ビット用の開発は引き続きサポートされています)。 |
| 開発環境 | コマンドライン開発を行う場合は、Xcode* のコマンドライン・ツール・コンポーネントが必要です。 |
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
14GB |
- インテル® Parallel Studio XE Composer Edition for macOS の対応状況は、FAQ の項目「macOS* および Xcode* 統合開発環境への対応について教えてください。」をご参照ください。
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
Fortran コンパイラー for Windows* (インテル® Parallel Studio XE)
| プロセッサー |
インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) 対応のインテル® 64 アーキテクチャー・プロセッサーをベースとするコンピューター (第 2 世代以降のインテル® Core™ i3/i5/i7 プロセッサー、インテル® Xeon® プロセッサー E3/E5 ファミリー、または互換性のあるインテル以外のプロセッサー) |
| ホスト OS |
IA-32 ホスト OS へのインストールのサポートを終了のご案内 Microsoft* Windows Server* 2012 では、製品は「デスクトップ」環境にインストールされます。Windows* 8 はサポートされていません。 |
| 開発環境 |
IA-32 対応アプリケーションまたはインテル® 64 対応アプリケーションのビルドに、Microsoft* Visual Studio* 開発環境あるいはコマンドライン・ツールを使用する場合は、次のいずれか:
※本製品のバージョン 2019 Update3 以降は、Visual Studio 2015 Shell* が同梱されておりませんので、Visual Studio* を使用して本製品をご利用ください。 インテル® 64 対応アプリケーションのビルドに、コマンドライン・ツールのみを使用する場合は、次のいずれか:
|
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
14GB (すべての機能およびすべてのアーキテクチャー) |
| ドキュメント |
ドキュメントの参照用に Adobe* Reader* 7.0 以降 |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
Fortran コンパイラー for Linux* (インテル® Parallel Studio XE)
| プロセッサー |
インテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) 対応のインテル® 64 アーキテクチャー・プロセッサーをベースとするコンピューター (第 2 世代以降のインテル® Core™ i3/i5/i7 プロセッサー、インテル® Xeon® プロセッサー E3/E5 ファミリー、または互換性のあるインテル以外のプロセッサー)
機能を最大限に活用できるよう、マルチコアまたはマルチプロセッサー・システムの使用を推奨します。 |
| ホスト OS |
IA-32 対応アプリケーションまたはインテル® 64 対応アプリケーションを開発する場合は、次の Linux* ディストリビューションのいずれか (本リストは、インテル社により動作確認が行われたディストリビューションのリストです。その他のディストリビューションでも動作する可能性はありますが、推奨しません。ご質問は、テクニカルサポートまでお問い合わせください。)
IA-32 ホスト OS へのインストールのサポートを終了のご案内 |
| Linux* 開発ツール・コンポーネント (gcc、g++ および関連ツールを含む) |
本リストは、 インテル社により動作確認が行われたコンポーネント・バージョンのリストです。その他のバージョンでも動作する可能性はありますが、推奨しません。ご質問は、テクニカルサポートまでお問い合わせください。
|
| -traceback オプション | -traceback オプションを使用するには、libunwind.so が必要です。一部の Linux* ディストリビューションでは、別途入手して、インストールする必要があります。 |
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
14GB (すべての機能をインストールする場合) |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
Fortran コンパイラー for macOS* (インテル® Parallel Studio XE)
| ホスト OS |
次の macOS*、Xcode*、Xcode SDK の組み合わせのいずれか。
64 ビットインテル® ベースの Apple* Mac* システムホスト (32 ビット用の開発は引き続きサポートされています)。 |
| 開発環境 | コマンドライン開発を行う場合は、Xcode* のコマンドライン・ツール・コンポーネントが必要です。 |
| RAM |
2GB (4GB 推奨) |
| ディスク空き容量 |
14GB |
- インテル® Parallel Studio XE Composer Edition for macOS の対応状況は、FAQ の項目「macOS* および Xcode* 統合開発環境への対応について教えてください。」をご参照ください。
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
C/C++ コンパイラー for Linux* (Windows* ホスト) (インテル® System Studio)
ホストシステム側
| OS |
|
| RAM |
1GB (2GB 推奨) |
| ディスク空き容量 |
4GB (すべての機能とアーキテクチャーをインストールする場合) |
| ドキュメント |
ドキュメントの参照用に Adobe* Reader* 7.0 以降 |
ターゲット・システム側
| OS |
|
| プロセッサー |
|
| ハードウェア容量 |
IA-32: 13 MB |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
C/C++ コンパイラー for Linux* (Linux* ホスト) (インテル® System Studio)
ホストシステム側
| OS |
|
| RAM |
1GB (2GB 推奨) |
| ディスク空き容量 |
4GB (すべての機能をインストールする場合) |
ターゲット・システム側
| OS |
|
| プロセッサー |
|
| ハードウェア容量 |
IA-32: 13 MB |
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
C/C++ コンパイラー for Windows* (Windows* ホスト) (インテル® System Studio)
ホストシステム側
| RAM |
1GB (2GB 推奨) |
| ディスク空き容量 |
4GB (すべての機能とアーキテクチャーをインストールする場合) |
ターゲット・システム側
| OS |
|
- 最新の情報は、製品または評価版に同梱されているリリースノートを参照ください。
お知らせ
開発元であるインテル社の方針により、従来仕様の Fortran コンパイラーであるインテル® Fortran コンパイラー・クラシック (ifort) は、バージョン 2024 より非推奨とされ、バージョン 2025 のリリースに伴い提供終了となりました。
今後も Windows* および Linux* サポート、新しい言語サポート、新しい言語機能、最適化オプションを含む最新の機能を利用される場合は、今すぐ LLVM ベースのインテル® Fortran コンパイラー (ifx) へ移行することを推奨します。
新しいコンパイラーとの相違点など、移行のための技術的な情報については、「インテル® oneAPI ポーティング・ガイド ー ifx へ移行する ifort ユーザー向け」をご参照ください。
※ インテル® Fortran コンパイラー・クラシック (ifort) および LLVM ベースのインテル® Fortran コンパイラー (ifx) については、「インテル® oneAPI ベース & HPC ツールキット」のいずれかの有償サポート製品 (「インテル® Fortran コンパイラー向けサポートサービス」を含む) によりサポートサービスが提供されます。
開発元であるインテル社の方針により、インテル® oneAPI ツールキット 2024 のリリースを以ってインテル® Fortran コンパイラー・クラシック (ifort) における macOS* のサポート終了が予定されています。今後も macOS* サポートをご利用いただく場合、旧製品バージョンのサポートサービスに関するポリシーに沿って、有効なサポートサービスをお持ちのお客様を対象にバージョン 2023 の提供が継続されます。
新しい LLVM ベースのインテル® Fortran コンパイラー (ifx) では macOS* をサポートしておらず、インテル® プロセッサーの搭載に関わらず、現時点で macOS* サポートが追加される予定はありません。
開発元であるインテル社の方針により、2023 年後半の oneAPI リリースで、インテル® C++ コンパイラー・クラシック (icc) の提供を終了させていただきました。今後も Windows* および Linux* サポート、新しい言語サポート、新しい言語機能、最適化をご利用いただくために、LLVM ベースのインテル® oneAPI DPC++/C++ コンパイラー (icx) へ移行することを推奨しています。
インテル® Parallel Studio XE 製品のサポートサービスが有効なお客様は、アップグレード・プロモーション製品を購入いただくことで、インテル® oneAPI DPC++/C++ コンパイラー (icx) が同梱されたインテル® oneAPI ツールキット製品にアップグレードするとともに、アップグレード元製品のサポートサービス期間から、お得な価格でサポートサービスの期間を 365 日分更新いただけます。
インテル® oneAPI DPC++/C++ コンパイラー (icx) への移行などの提供終了に関する詳細は、技術ポータル iSUS の技術記事をご覧ください。
2019年 12月 18日、インテル® コンパイラー 19.1 日本語版が同梱されるインテル® Parallel Studio XE 2020 初期バージョンのダウンロード提供を開始しました。
インテル® Parallel Studio XE for Windows/for Linux のサポートサービスが有効なお客様は、最新日本語版コンパイラーの提供開始後、最新日本語版が含まれるインテル® Parallel Studio XE 2020 を無料でダウンロードしてご利用いただけます。
また、インテル® Parallel Studio XE 製品の評価版をお申し込みいただくことで、インテル® コンパイラー 19.1 の日本語マニュアルを入手いただけます。
開発元インテル社の方針により、インテル® Parallel Studio XE 製品の次期マイナーバージョンとされている 2019 Update3 以降、Windows* 版の Fortran 言語対応製品に含まれていた Visual Studio Shell* の提供終了が予定されています。また、同バージョン以降、Visual Studio 2015 Shell* への統合機能の提供終了も予定されています。
Microsoft 社からの Visual Studio 2015 Shell* のサポートの終了と、Visual Studio* 2015 以降のバージョン (Visual Studio* 2017 など) では Shell が提供されないことを考慮し、提供を終了する方向となりました。
今後の対応などの提供終了に関する詳細は、弊社のブログ記事をご覧ください。
2018年 11月 9日、インテル® コンパイラー 19.0 日本語版が同梱されるインテル® Parallel Studio XE 2019 アップデート版 (バージョン 2019 Update1) のダウンロード提供を開始しました。
インテル® Parallel Studio XE for Windows/for Linux のサポートサービスが有効なお客様は、最新日本語版コンパイラーの提供開始後、最新日本語版が含まれるインテル® Parallel Studio XE 2019 の最新アップデート版を無料でダウンロードしてご利用いただけます。
また、インテル® Parallel Studio XE 製品の評価版をお申し込みいただくことで、インテル® コンパイラー 19.0 の日本語マニュアルを入手いただけます。
2018年 10月 12日、インテル® C/C++ コンパイラー 19.0 が同梱されるインテル® System Studio のバージョン 2019 の発売を開始しました。
インテル® System Studio 製品の有効なサポートサービスをお持ちのお客様は、すぐにインテル® コンパイラー 19.0 が含まれるインテル ® System Studio 2019 を無料でダウンロードしてご利用いただけます。
インテル® System Studio に含まれるインテル® C/C++ コンパイラーは、英語版のみの提供となります。
開発元インテル社の方針により、2018年 10月 10日を以って、インテル® Parallel Studio XE Composer Edition for Fortran with ローグウェーブ IMSL 7.0 for Windows およびローグウェーブ IMSL Fortran ライブラリー 7.0 Windows 版の販売を終息いたしました。新規、SSR 共に販売終了となりました。
今後は IMSL ライブラリーがご入用の際は、ローグウェーブ ソフトウェア ジャパン株式会社へお問い合わせください。 また、インテル社での販売終息に伴い、IMSL ライブラリー製品は、インテル社ではサポートされず、技術サポートの問い合わせはローグウェーブ ソフトウェア社より提供されることになりました。恐れ入りますが、技術サポートをご利用の際にはローグウェーブ ソフトウェア ジャパン株式会社までご連絡ください。
終息に関してご不明な点がある場合は、「IMSL 製品の販売終息に関する FAQ」ページをご参照ください。
ご迷惑をお掛けしますが、何とぞご了承いただきますようお願い申し上げます。
サポートされていないバージョンのコンパイラーおよびライブラリー(インテル社、英語)
上記の WEB ページにて、インテル® コンパイラーおよびライブラリーについて、インテル社でのサポートが終了したバージョンが案内されています。インテル社の意向により、これらのバージョンのインストール用ファイルは サポート終了から約 2 年を経過した時点でダウンロード提供を終了し、インテル® レジストレーション・センターから削除される予定です。弊社(エクセルソフト株式会社)からファイルの再提供は行いませんので、必要に応じてバックアップや物理メディアへの保存などのご対応をお願いいたします。
サポート終了バージョンのご利用について
これらのバージョンは、お客様のご判断において利用することは可能ですが、最新のオペレーティング・システム(OS)では動作しない可能性があります。また最新のプロセッサーをサポートしません。利用されるバージョンのリリースノートにて、対応している OS およびプロセッサーについてご確認ください。 旧バージョン向けドキュメント よりご覧になれます。
これらのバージョンについて、インストールおよび利用には有効な製品ライセンスが必要です。該当製品(またはその後継製品)のライセンスは、付属するサポートサービスの期限までにリリースされたどのバージョンに対しても有効です。製品をインストールする際のアクティベーションには、シリアル番号およびアクティベーションコードではなく、ライセンスファイル(*.lic)を適用してください。
マイクロソフト社 から 2017年 8月 14日に Visual Studio 2017 のバージョン 15.3 がリリースされましたが、インテル® Parallel Studio XE のバージョン 2017 Update4 には、 Visual Studio 2017 のバージョン 15.3 またはそれ以降のバージョンとの組み合わせでは正常に動作しない問題があります。このため、Visual Studio 2017 のより新しいインストールにおいて、または既にインストールされた Visual Studio 2017 を更新すると、インテル® コンパイラーが使えなくなる場合があります。
インテル社は、インテル® コンパイラーのバージョンと、その公開時点でサポートしている Visual Studio 2017 のバージョン (15.x) の情報を提供しています。
またマイクロソフト社は、Visual Studio 2017 の以前のリリースのインストール方法を提供しています。
インテル® コンパイラーを Visual Studio 2017 と共に利用する場合には、これらの情報を参照して、対応した Visual Studio 2017
をご用意ください。製品の評価を行われる場合は Visual Studio 2015 を代わりに使用することもできます。
Visual Studio 2015 (Community、または
Professional 評価版) のダウンロード方法はこちらのページをご覧ください。
インテル® コンパイラー 17.0 Update 4 より、Microsoft* Visual Studio* 2017 が新たにサポートされます。
インテル® Parallel Studio XE、インテル® SystemStudio の有効なサポートサービスをお持ちのお客様は、無料で最新アップデート版をダウンロードしてご利用いただけます。
- インテル® コンパイラー 17.0 Update 4 は、インテル® Parallel Studio XE のバージョン 2017 Update4 、インテル® System Studio のバージョン 2017 Update 3 に同梱されています。
インテル® Parallel Studio XE Composer Edition 以上には 6 つのコンパイラーが含まれています。
インテル® Parallel Studio XE、インテル® System Studio の有効なサポートサービスをお持ちのお客様は、無料で最新アップデート版をダウンロードしてご利用いただけます。
- インテル® C++ コンパイラー for Windows*、Windows* ホスト用 (IA-32 またはインテル® 64 ホストおよびターゲット向けにコンパイル)
- インテル® C++ コンパイラー for macOS*、macOS* ホスト用 (インテル® 64 ホストおよびターゲット向けにコンパイル)
- インテル® C++ コンパイラー for Linux*、Linux* ホスト用 (IA-32 またはインテル® 64 ホストおよびターゲット向けにコンパイル)
すべてのコンパイラーは、インテル® Parallel Studio XE Composer Edition 以上に含まれています。詳細は、 インテル® Parallel Studio XE 製品ページを参照してください。
「 インテル® C/C++ コンパイラー: 機能とサポートされるプラットフォーム比較ページ」をご覧ください。
一言でいえば、パフォーマンスです。インテル® C++ コンパイラーは、次のような機能を提供する強固な C/C++ コンパイラーです (以下は一部であって、すべての機能ではありません)。
- C++11 のすべての機能、C++14 の一部の機能、C99 のほとんどの機能
- 並列化サポート: OpenMP* 4.1
- 効率良いループの最適化
- 現代のプロセッサーの性能を引き出すデータ並列性を提供する自動ベクトル化
本ページの「 技術情報」タブのリリースノートをご覧ください。
FAQ
最新バージョンの製品ライセンスを購入すると、その製品の旧バージョンについても利用できるようになります。インストール用ファイルの取得については 旧バージョンのダウンロード方法 をご参照ください。
ただし、インテル社の意向により、特定バージョンのインストール用ファイルを提供できない場合があります。本ページ「お知らせ」欄の [サポートを終了したコンパイラーおよびライブラリーの取得について] もご参照ください。
マイクロソフトは 2017 年 3 月 7 日に Microsoft * Visual Studio * 2017 をリリースしました。これに伴い、インテル® ソフトウェア開発製品の下記バージョンより、 Microsoft * Visual Studio * 2017 のサポートを開始しました。
- インテル® Parallel Studio XE for Windows * (すべての Edition、バージョン 2017 update 4 以降)
- インテル® System Studio for Windows * (すべての Edition、バージョン 2017 update 3 以降)
いいえ、単体販売はしておりません。
インテル
® コンパイラーを同梱するインテル® Parallel Studio XE またはインテル® System
Studio をお買い求めください。
» スイート製品に同梱される 製品・機能一覧はこちら
インテル® コンパイラーの英語版には英語の言語環境のみが含まれますが、日本語版には英語および日本語の言語環境が含まれ、ドキュメント、コンパイル時のメッセージ、Visual Studio ® 上での UI を日本語で確認することができます。
日本語版導入後、表示される言語はシステムの言語設定、Visual Studio* の言語設定に依存します。日本語で表示させたい場合は、予め日本語 の OS および Visual Studio* をご用意ください。
インテル® コンパイラー日本語版導入環境下では、以下手段で切り替えを行うことができます。
日本語版が導入されていない環境では英語でのみ表記されます。
Windows*
-
Visual Studio* 上の UI
Visual Studio* の言語設定に依存します。Visual Studio* のオプション設定から切り替えてください。
- コンパイラー診断メッセージを日本語環境下で英語表示
コンパイル時に下記のオプションを付けてコンパイルを行うと、コンパイラー診断メッセージのみ英語で表示されます。
(診断メッセージ以外には適用されません。)
/Qdiag-message-catalog- - 製品全体の英語/日本語切り替え
OS のシステムロケール、言語設定を変更することで、インストーラーや診断メッセージの言語を切り変えることができます。
例: Windows* 10 の場合- システムロケール: [コントロールパネル]-[時計言語および地域]-[地域]の管理タブから変更
- 言語: [コントロールパネル]-[時計言語および地域]-[言語]で、該当の言語を追加し、一覧の一番上に移動させる
Linux*
- コンパイラー診断メッセージを日本語環境下で英語表示
コンパイル時に下記のオプションを付けてコンパイルを行うと、コンパイラー診断メッセージのみ英語で表示されます。
(診断メッセージ以外には適用されません。)
/Qdiag-message-catalog- - 製品全体の英語/日本語切り替え
以下コマンドで LANG 環境変数を変更してからインストールを行うと、インストーラーや診断メッセージの言語を切り変えることができます。
- 日本語 -> 英語 に変更する場合
export LANG=C - 英語 -> 日本語 に変更する場合
export LANG=ja_JP.UTF-8
- 日本語 -> 英語 に変更する場合
インテル® コンパイラーは複数バージョンを共存させることが可能です。
なお、Windows* 環境で Visual Studio* と統合させる場合は、旧バージョンを先にインストールする必要があります。
これは、同時にインストールされる統合モジュールを最新バージョンにする必要があるためです。(最後にインストールしたバージョンの統合モジュールで上書きされるため)
使用するコンパイラーのバージョンの切り替えは、Visual Studio* のオプション・ダイアログから行えます。
詳細は インテル社の Web サイト(英語) を参照ください。
以下の表の通りです。
詳細は インテル社のページ (英語)を参照ください。
| インテル® コンパイラー | インテル® Parallel Studio XE |
|---|---|
| 17.0 | 2017 |
| 16.0 | 2016 |
| 15.0 | 2015 |
| 14.0 | 2013 SP1 |
| 13.1 | 2013 Update2 |
| 13.0 | 2013 |
| 12.1 | 2011 SP1 |
| 12.0 | 2011 |
インテル® Parallel Studio XE Composer Edition for macOS の対応状況について以下に記載します。
最新の情報については、リリースノート、および
Compatibility of Intel® Compiler for macOS* and Xcode* (インテル社、英語) も参照ください。
|
Xcode* 12.0 |
バージョン 2020 update1 までの時点ではサポートされていません。 旧バージョンの Xcode* は、Apple 社 Web ページ (Downloads for Apple Developers) よりダウンロードすることができます。 ※ この Web ページへのアクセスには、Apple ID が必要になります。 |
|
Xcode* 11.x |
バージョン 2020 Initial Release で統合、動作のサポートがされました。 バージョン 2020 update1 以降の変更点:Fortran コンパイラーでは Xcode* への統合機能は廃止されました。 製品をインストールおよび使用するには、引き続き以下の手順にて「Command Line Tools」のインストールが必要です。
|
|
Xcode* 10.3 |
バージョン 2019 update5 で統合がサポートされました。 |
|
Xcode* 10.2 |
バージョン 2019 update4 で統合がサポートされました。 |
|
Xcode* 10.1 |
バージョン 2019 update3 で統合がサポートされました。 |
|
Xcode* 10 |
バージョン 2019 update1 で統合、動作のサポートがされました。 注意: Xcode* 10 以降でインテル コンパイラーを使用する Xcode プロジェクトをビルドするには、Xcode のアプリケーションメニュー、File > Project Settings... より設定ダイアログを開き、Build System について "Legacy Build System" に切り替える必要があります。以下インテル社のページ (英語) もご参照ください。 |
|
Xcode* 9.4 |
バージョン 2019 Initial Release、バージョン 2018 update4 で統合がサポートされました。 |
|
Xcode* 9.3 |
バージョン 2018 update3 で統合がサポートされました。 |
|
Xcode* 9.2 |
バージョン 2018 update2 で統合、動作のサポートがされました。 |
|
Xcode* 9/9.1 |
バージョン 2018 update1 で統合、動作のサポートがされました。 |
注意事項
-
Xcode* 6.3.2 以降
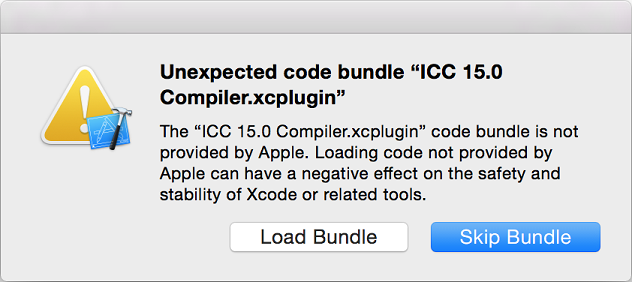
Xcode* 6.3.2 より、Xcode* への統合をインストールした後で Xcode* を起動すると、初回のみダイアログが表示されます。
インテル® コンパイラーの Xcode* への統合を利用するには [Load Bundle] をクリックしてください。[Skip Bundle] を選択してしまった場合には、以下の手順でダイアログを再表示させ、[Load Bundle] を選び直してください。
- アプリケーションメニューより Xcode* を終了させてください。
- macOS* 標準のターミナル(Launch Pad より "その他" 項目)を開き、次のコマンドを入力してください。
defaults delete com.apple.dt.Xcode DVTPlugInManagerNonApplePlugIns-Xcode-6.3.2 - Xcode* を起動すると、ダイアログが表示されます。
-
Xcode* 5.1 以降
Xcode* 5.1 より [Command Line Tools] のインストール方法が変更されております。製品をインストールする前に、以下の手順にてインストールしてください。
- Xcode* をインストールした後で、macOS* 標準のターミナル(Launch Pad より "その他")を開き、次のコマンドを入力します。
xcode-select --install - コマンド入力により表示されたダイアログから Install ボタンをクリックし、インストールします。
- Xcode* をインストールした後で、macOS* 標準のターミナル(Launch Pad より "その他")を開き、次のコマンドを入力します。
-
Xcode* 5.0
製品を利用いただくには、以下の手順にて「Command Line Tools」もインストールする必要があります。 インストールされていない場合には、製品のインストール時に次のようなメッセージが表示され、インストールを続行できません。手順に従い作業を進めてください。
Command Line Tools for Xcode were not found.
- Xcode* のアプリケーションメニューより [Xcode] > [Preferences...] を開きます。
- 表示されたダイアログから Downloads タブを選択し、"Components" より「Command Line Tools」の (↓) ボタンをクリックしてインストールします。
- 手順 2. の段階にて Apple Developer ID の入力が必要になることがあります。Xcode* をダウンロードする際に登録(または入力)した ID およびパスワードを入力してください。
-
製品の旧バージョンを利用されているお客様
製品バージョン 2013 SP1 以前では、現在 Mac App Store よりダウンロード、またはアップデート可能な Xcode* をサポートしていません。対応する旧バージョンの Xcode* は、Apple 社 Web ページ ( Downloads for Apple Developers) よりダウンロードすることができます。 ※ この Web ページへのアクセスには、Apple Developer ID が必要になります。登録されていない場合には、 Register as Apple Developer (無料会員登録) にてご登録ください。
例として、製品バージョン 2013 (Initial Release) は "Xcode* 4.4.1" との組み合わせでインストールできます。ダウンロードした .dmg ファイルを開き、中にある Xcode* (Xcode.app) を "アプリケーション" フォルダ (/Applications) にコピーしてください。Xcode* 4.3 以上とともに利用する場合には「Command Line Tools」のインストールも必要になります。 -
旧バージョンの Mac OS X* および Xcode* を利用されているお客様
- Mac OS X* 10.8.x と Xcode* 4.6.x から 5.1.x まで
製品バージョン 2015 および以降のリリースでは、上記の環境はサポートされなくなりました。 有効なサポートサービスをお持ちのお客様は、製品バージョン 2013 SP1 をダウンロードして利用いただけます。
- Mac OS X* 10.8.x と Xcode* 4.6.x から 5.1.x まで
リリースノートおよび インテル社のページ (英語)を参照ください。
いいえ、インテル® System Studio に同梱されるインテル® コンパイラーは英語版のみです。
インテル
® コンパイラーの日本語版は、インテル® Parallel Studio XE for Windows/Linux にのみ提供されます。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。