この記事は、AMD 社のウェブサイトで公開されている「Accelerating Python Performance with AOCL on AMD “Zen” Cores」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
2026年2月11日

Naina Patil
Advanced Micro Devices, Inc.
はじめに
Python は、科学技術計算、機械学習、データ分析の分野で最も広く利用されている言語のひとつです。しかし、大規模データセットの処理や複雑な数値計算を行う場合、パフォーマンスがボトルネックとなることがあります。この課題に対し AMD は、AMD 最適化 CPU ライブラリ (AOCL) により Python 向けに最適化されたライブラリを提供しています。対象となるのは、NumPy、SciPy、PyTorch、NumExpr、および SciPy Sparse Extension です。
AOCL は、AMD「Zen」コアの性能 (コア数の増加、メモリ帯域の拡張、大容量キャッシュ、AVX-512 など) を最大限に引き出すよう高度に最適化された数学ライブラリです。これにより、AMD EPYC™ および AMD Ryzen™ プロセッサー上で高速なパフォーマンスを実現します。
AOCL 対応 Python ライブラリは、あらかじめビルドされた wheel 形式で提供され、容易にインストールできます。これにより、AOCL の性能を Python 環境で直接活用できます。シンプルさと高性能を両立するよう設計されており、すべてのライブラリは徹底した検証を経て提供されるため、インストール直後からスムーズに利用できます。
どのような点で優れているのか
本ブログでは、NPBench スイートを用いて実施した最適化の効果を紹介します。NPBench は、HPC、データサイエンス、ディープラーニングなど、さまざまな分野を対象とした NumPy コードサンプルで構成される包括的なベンチマーク スイートです。本検証では、このベンチマーク スイートの中から入力サイズ Large (L) を使用したベンチマークの一部を選択しています。SciPy については、AOCL を組み合わせた場合の性能を示す例として、linalg.lstsq ベンチマーク (lstsq source) を使用しています。
NumPy および SciPy の最適化は、いずれも AOCL-BLAS および AOCL-LAPACK により実現されています。
https://www.amd.com/en/developer/aocl.html
図 1 および図 2 のヒストグラムは、AOCL を使用した NumPy と標準の NumPy (BLAS バックエンドとして OpenBLAS を使用) との相対的な高速化を、シングルスレッドおよびマルチスレッドの両方で比較したものです。ベースラインは 1.0 (標準構成の性能) に設定しています。バーが高いほど、性能向上が大きいことを示します。
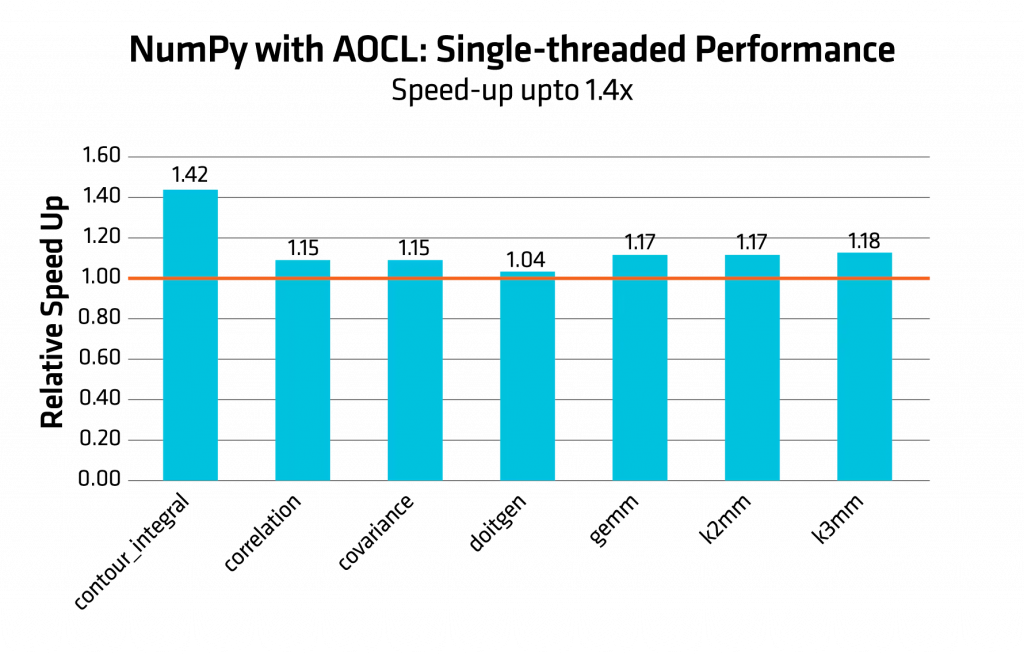
図 1: AOCL を使用した NumPy に対する AMD の最適化 (シングルスレッド時の標準 NumPy との比較)
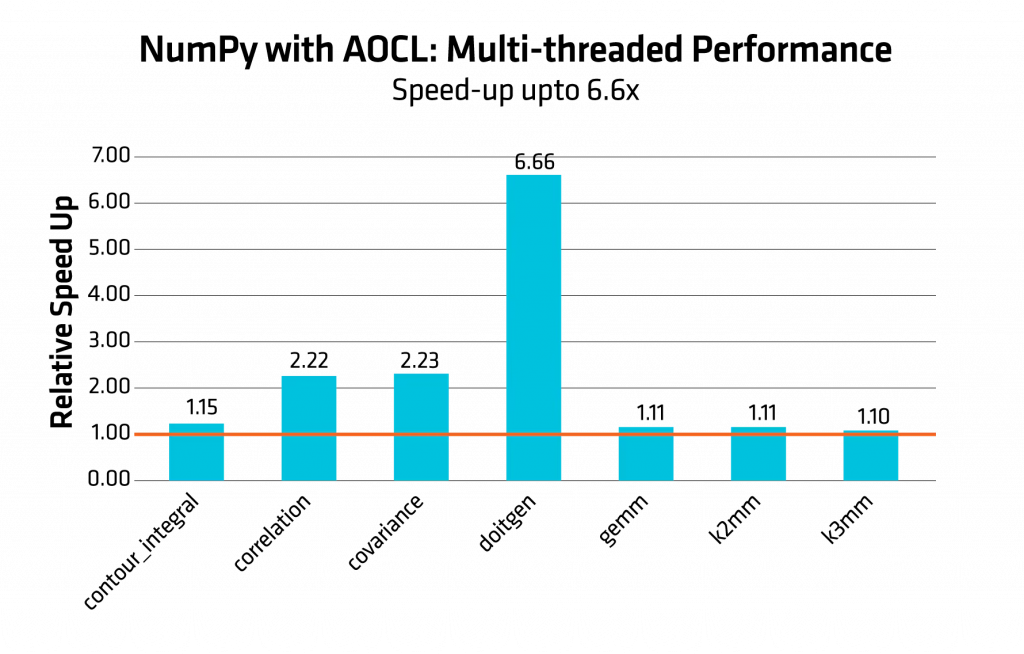
図 2: AOCL を使用した NumPy に対する AMD の最適化 (OMP スレッド数 8 を使用、マルチスレッド時の標準 NumPy との比較)
性能結果は、検証時の構成に基づいています。
図 2 では、doitgen が 6.6 倍という大幅な性能向上を達成していることが確認できます。correlation および covariance も 2 倍以上の性能向上を示しており、その他のベンチマークでも一定の改善が見られます。AOCL は優れた並列処理性能を提供し、計算負荷が高く並列化可能なワークロードにおいて大きな性能改善を実現します。
AOCL-BLAS および AOCL-LAPACK ライブラリでは、スレッド モデルとして OpenMP を使用しています。そのため、AOCL を使用した NumPy および SciPy の並列化は、OpenMP の環境変数によって制御できます。ワークロードに応じて、適切なスレッド数を設定する必要があります。たとえば、8 コアを使用できる場合は、実行環境で環境変数 OMP_NUM_THREADS=8 を設定します。
最適なパフォーマンスを得るための OpenMP スレッド数の選択は、アプリケーションによって異なるため、実際に調整して検証することが重要です。OpenMP のスレッド配置戦略の詳細については、以下を参照してください。
https://www.openmp.org/
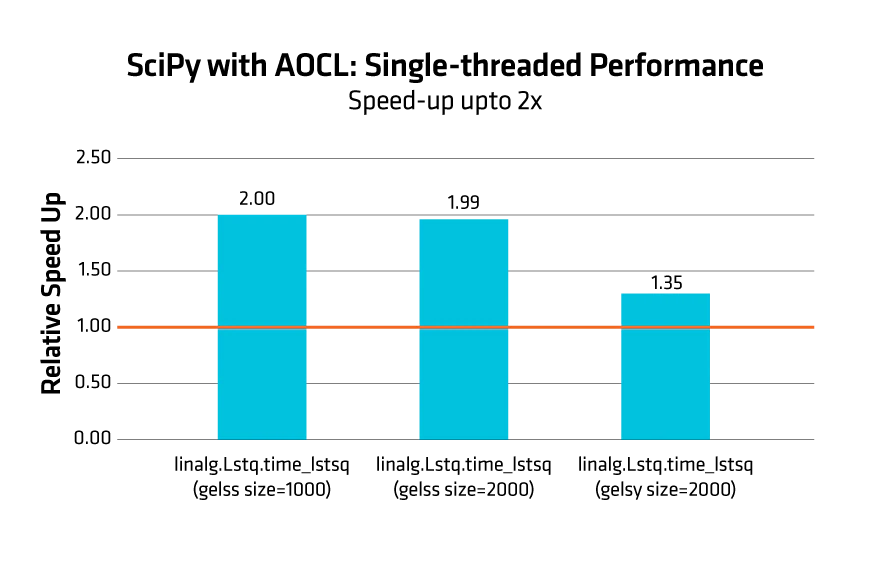
図 3: AOCL を使用した SciPy に対する AMD の最適化 (シングルスレッド時の標準 SciPy との比較)
図 3 は、linalg.lstsq ベンチマークの比較結果を示しており、AOCL を使用した SciPy は標準の SciPy 実装と比較して最大 2 倍の性能向上を達成しています。
AOCL + Python = 高速化の鍵
ここまで性能向上の結果を確認してきましたが、その要因を詳しく見ていきましょう。これらの改善の中核となっているのは、AMD アーキテクチャ向けに特別に最適化された AOCL の高性能カーネルです。AVX-512 命令を選択的に活用することで、AOCL はベクトル化性能とスループットを最大化します。また、カーネルのサイズ設計も AMD Zen コアに合わせて最適化されています。
さらに、内部実装レベルでの幅広い最適化も施されています。具体的には、命令スケジューリングを改善するループ最適化、パイプライン ストールを最小化する分岐予測、CPU パイプラインを最大限に活用する処理設計、読み書きレイテンシを効果的に低減するデータ プリフェッチなどが含まれます。
さらに踏み込むと、AOCL は Zen アーキテクチャ向けに最適化されたキャッシュ ブロッキング技術を採用しています。これにより、低速なメモリへのアクセスを減らし、計算処理を CPU に近い位置に維持したままキャッシュ階層内で効率的に処理できるようになります。この仕組みによりボトルネックが軽減され、ワークロードの複雑さが増しても安定した性能向上が期待できます。
まとめると、アーキテクチャ、マイクロアーキテクチャ、メモリ レベルの最適化が組み合わさることで、ユーザーが体感できる性能向上が実現されています。すなわち、一般的な標準の実装と比較して、低レイテンシかつ高スループットを達成します。
簡単セットアップ: wheel ファイルによるインストール
各 wheel は、AOCL 対応 Python ライブラリから該当バージョンをダウンロードし、pip を使用してインストールできます。
各 Python ライブラリ向けに AOCL 対応の wheel を提供しているため、ユーザーはコードを変更することなく最適化の恩恵を受けることができます。
環境設定とインストール
環境の分離を適切に行うため、Python 仮想環境または Conda の使用を推奨します。本ブログでは、以下のように作成・有効化できる conda 環境を使用しています。
conda create -n <env_name> python=<version>
以下の手順に従って wheel をダウンロードおよびインストールします (例):
- AOCL 対応 Python ライブラリから wheel をダウンロード
- 必要な wheel をインストール — pip3 install /path/to/numpy*.whl
詳細な手順については、以下を参照してください。
https://docs.amd.com/r/en-US/57404-AOCL-user-guide/AOCL-User-Guide
まとめ
AOCL は、ハードウェア特性を考慮した最適化を Python ワークロードにもたらし、AMD Zen アーキテクチャの性能を最大限に引き出します。これにより、計算処理をより高速かつ効率的に実行できるようになります。
データ量が多いアプリケーション、計算負荷の高い処理、またはパフォーマンスが重要なアプリケーションを開発している場合、AOCL を活用する絶好のタイミングです。
ぜひお試しいただき、その違いを体感してください。
AMD Zen Software Studio サポート サービス
エクセルソフトは AMD と提携し、HPC クラスター システムやデータ センター向けに AMD EPYC™ CPU ベースのサーバー上で動作するアプリケーションのパフォーマンスを最適化するためのソフトウェア開発ツール スイート 「AMD Zen Software Studio」 のサポート サービスを提供しています。サポート サービス導入前のご質問やご購入前の見積依頼などございましたら、エクセルソフトまでお気軽にお問合せください。
