新しい Python in Excel 統合により、Python コードを直接ワークブックに埋め込んでデータを操作することが可能です。この記事では、この新しい統合の便利で革新的な機能の 1 つである、正規表現を使用したデータの検索、置換、検証について説明します。たとえば、正規表現を使用すると、正確な文字列値ではなくテキスト内のパターンを検索したり、特定の部分 (テキスト内のすべての URL など) を見つけて抽出し、チェックおよび検証できます。正規表現は、Excel 内で高度なデータ検証を行える強力なツールです。正規表現を使用して、文字列データが特定の形式や条件に一致するかどうかを判断し、エラーを防ぎ、データの整合性を維持できます。
この記事では、新しい Python in Excel 統合を使用して Excel 内で正規表現を使用する方法を学びます。この記事を読むことで、正規表現についての一般的な理解が深まり、Excel で正規表現を使ってワークブック内のカスタム データ検索や検証ロジックを作成する方法がわかります。
注: この記事で紹介する例を実際に試す場合は、Python in Excel の体験版をインストールしてください。
はじめに
正規表現 (REs、regex、regexp とも呼ばれる) は、テキスト データを操作する強力なツールです。1 つの正規表現は、データ内で想定される構造を表す、1 つまたは複数の文字シーケンス (検索パターン) で構成されます。検索パターンは、文字列検索アルゴリズムがデータ内の一致するシーケンス (部分文字列) をチェックして見つけるのに使用されます。正規表現は一般にデータ検証タスクに採用されており、使用例には、日付形式、メール アドレス、電話番号、および構造内で特定の (正規の) パターンを必要とするその他のデータ フィールドの検証が含まれます。
Microsoft Excel は、データの検索やフィルター処理において正規表現をネイティブにサポートしていません。そのため、正確なテキストベースの検索しかできません。この記事では、新しい Python in Excel 統合により、ワークブックで正規表現を直接使用してカスタム ロジック関数を作成する方法を学びます。
例として、一般公開されている Excel テーブル形式の従業員データセットを使用します。正規表現を使用して選択した列にカスタム検証メカニズムを実装する方法を学びながら、Python in Excel を使用した効率的なデータ処理に関するいくつかのヒントも学びます。実践部分に入る前に、まず正規表現について理解し、Python で正規表現を使用する方法を学びましょう。
Python の正規表現: 入門
正規表現は、特殊文字と演算子からなる所定の構文を使用してパターンを定義する文字列です。パターンは、さまざまな特性に基づいた、テキストの構造と内容の形式的記述です。パターンの例として、「文字列内で許可される文字と許可されない文字のリスト」、「単語または文内で特定の文字列を何回繰り返すことができるか」、または「指定された文字セットの長さ」などが挙げられます。これらのパターンは、正規表現エンジンによって処理および集約され、正規表現の検索パターンになります。
正規表現パターンは、特殊文字 (メタ文字) とカスタム演算子を含む、特殊な構文を使用して定義されます。たとえば、[a-z] は「a から z までの小文字 1 文字」に一致する正規表現です。角括弧は、1 つの照合表現 (文字クラス) を区切ります。最近のプログラミング言語は正規表現をネイティブにサポートしており、サードパーティのパッケージをインストールする必要はありませんが、サポートの範囲や検索パターンを定義する構文は言語により異なります。そのため、この記事では Python in Excel に含まれる re Python パッケージでサポートされている正規表現構文について考えます。
正規表現構文と対応する記号のリストは、初心者には難しく、熟練者でも覚えるのが面倒なことがあります。しかし、心配ありません。高度なデータ検証フィルターの例では、正規表現を作成するステップごとに詳しく説明します。さらに、正規表現に慣れるため、あるいは復習に使える、実用的なチート シートも用意しています。
正規表現を使用した Excel でのデータ検証

従業員データセットには、EEID (従業員 ID)、Full Name (氏名)、Email (メール アドレス)、Phone (電話番号)、Job Title (役職)、Department (部署)、Business Unit (事業部門)、Gender (性別)、Ethnicity (人種)、Age (年齢)、Hire Date (入社日)、Annual Salary (年間給与 US$)、Bonus % (賞与)、Country (国)、City (市)、Exit Date (退職日) の 16 列が含まれており、全体で 1,000 行あるため、データのチェックと検証には自動化された方法が必要です。
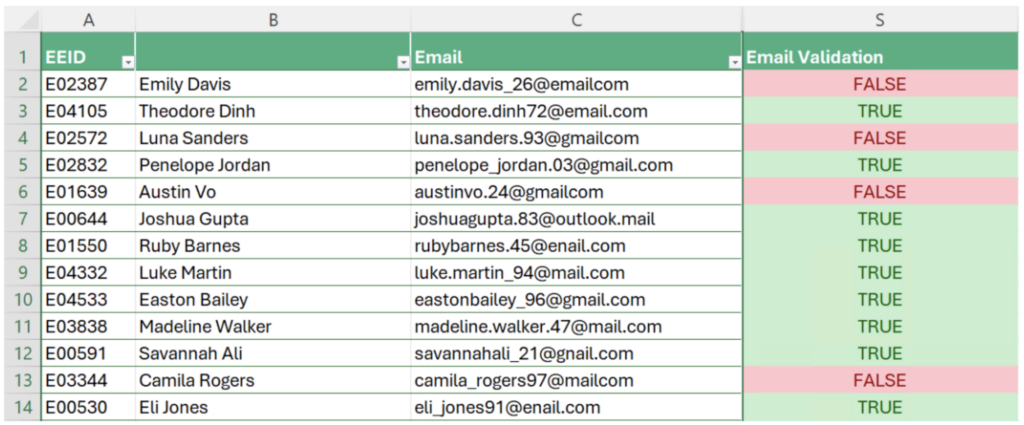
ワークブックから抽出されたデータ例 (図 1) から、正規表現を使用した自動検証によりメリットが得られるいくつかのフィールドを特定できます。
- 従業員 ID を含む EEID 列は、正規表現の使用に適した候補と考えられます。従業員 ID は 6 文字で、大文字の「E」で始まり、その後に 5 桁の数字が続きます。データ内のこのパターンを検索する正規表現を定義し、各セルに対して自動検証を実行します。
Email 列も正規表現による検証に適した候補です。まず、データセット内に無効なメール アドレスがあるかどうかを確認する必要があります。次に、すべてのメール アドレスが正しいかどうか、つまり入力ミスがないかどうかを確認します。例えば、メール アドレスでよくある入力ミスは、mail を nail としてしまうことです。
電話番号の有効性のチェックは、正規表現の観点からは、おそらく最も興味深いケースでしょう。
+1 111 123 4567、+1-111-123-4567、+1.111.123.4567、+11111234567、+1 (111) 1234567は形式は異なりますが、すべて有効な電話番号です。複数の形式があっても、正規表現を使用することで、このデータ フィールドの検証が容易になります。ここで課題となるのは、すべての形式を検索できる 1 つの正規表現を定義することです。
準備
実装に取り掛かる前に、ワークブックで数式の自動計算を無効にすることを推奨します。これにより、コードを (自動) 実行してデータ内の項目を 1 つずつ処理する際の、パフォーマンス・ボトルネック (偶発的なものも含む) を避けることができます。無効にするには、メニューから [ファイル] > [オプション] > [数式] を選択し、[ブックの計算] で [手動] をオンにします。手動計算モードでは、自動モードと計算結果が異なることがありますが、Python コードを実行して各テーブル行を処理する際に環境がフリーズしないよう、このデータセットではこのモードを推奨します。
EEID 列の検証
最初に留意すべき点は、Python in Excel 統合では、ワークブック内のデータを参照するカスタム関数 xl(“range”, headers) が提供されています。この関数は、ワークブック内の特定 (範囲) の値を参照し、それに応じて Python オブジェクト (DataFrame または Series) に自動変換するため、この例全体で役に立ちます。これにより、一度に 1 つのセルを処理する代わりに、Python ベクトル関数を使用して DataFrame 全体を操作できます。これはささいなことのように見えますが、パフォーマンスに大きな影響を与えます。なぜならば、大量のネットワーク トラフィックが発生する小規模な計算を行う代わりに、すべてのデータを独自のデータ構造にまとめて Azure Cloud 上のリモート サンドボックスに送信できるからです。さらに、セルは事前に定義された順序で実行されるため、実行全体が並列ではなく順番に実行されます。これは、処理する項目が少ない場合は問題になりませんが、1,000 行のデータセット全体を処理する場合には、大きなパフォーマンス ボトルネックになります。したがって、常に Python in Excel 実行モデルを念頭に置くことが重要です。実行モデルの詳細とその他のプログラミングのヒントについては、こちらのブログを参照してください。
それでは、Python コードを作成していきましょう。まず最初に、パターンを定義します。正規表現を使用すると、EEID の照合は容易です。実際、すべての EEID は、「大文字の E と 5 桁の数字」を表す「E\d{5}」というパターンで取得できます。ここで、\d 演算子は 0 から 9 までの数字を表し、続く { } で囲まれた数値は文字列の長さ (「量指定子」) を示します。つまり、「\d{5}」は 5 桁の数字を表します。
R1 セルに移動し、新しい =PY() セルを作成し、次のコードを記述します。
df = xl("A1:A1001", headers=True)
pattern = "E\d{5}"
df.EEID.str.match(pattern)まず、xl() 関数を使用して EEID データ列全体を選択します。すると、同じ名前の列を持つ DataFrame として返されます。これは、xl 関数呼び出しで headers=True を渡した結果です。次に、pandas の文字列関数 match を利用して、パターン照合を複数の行に伝播します。これにより、データ ループで pandas の内部最適化を完全に活用し、Python での低速な明示的反復を回避できます。式 df.EEID.str.match(pattern) の結果は、pandas の一連のブール値、つまり、照合が成功したか失敗したかに応じて、それぞれ True または False になります。ワークブック内の値を確認するには、Python セルの出力を「Excel Value」に切り替えます。結果の系列のすべての値は、Excel によって自動的に 1,000 行に分割されます。必要に応じて、これらのセルに条件付き書式を適用して、パターン照合の結果を緑または赤で強調表示することもできます。
Email 列の検証
メール アドレスを検証する主な目的は 2 つあります。1 つは、無効なメール アドレスを含むすべての項目を特定することです。無効なメール アドレスとは、メール アドレス検索パターンと一致しないデータ内の項目です。まず、検索パターンを定義しましょう。その後説明します。
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"一見すると難しそうに見えるかもしれませんが、要素を 1 つずつ分析すると簡単に理解できます。まず、この正規表現では角括弧 [ ] で識別される文字クラスが使用されています。文字クラスは正規表現構文の非常に便利な機能で、一般的な検索パターン (この例では「メール アドレス パターン」) 内のグループを識別します。理解しやすいように、上記の構文を左から右に、文字クラスごとに分析してみましょう。
最初の文字クラス ([^\s@]+) は、空白と @ 記号を除く空でない (+ 量指定子) 文字シーケンスを識別します (^、+、および \s 演算子の詳細については、チート シートを参照してください)。このパターンは非常に汎用的で、英数字や句読点を含む可能な限り一般的なメール アカウント名を識別できます。データ内のメール アカウント名には使用可能な文字の制限がないようなので、幅広く、さまざまなバリエーションを許容するパターンにしています。パターンで許可されない唯一の文字は空白 (\s) です。空白 (\s) と @ 記号はメール アドレスにおいて特殊な意味を持つため、メール アカウント名に含めることはできません。
メール アドレスでは、アカウント名の後に @ 記号と「ドメイン名.ドメイン拡張子」が続きます。メール アドレス検索パターンでは、ドメイン名と拡張子の両方の照合に同一の文字クラスを再利用します。また、ドット (.) がメタ文字ではなく、文字として解析されるように、バックスラッシュを使用してエスケープ (\.) します。
最終的に S1 Python セルに記述するコードは次のようになります。
df = xl("C1:C1011", headers=True)
email_pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
df["Email Validation"]結果は、わかりやすいように新しい「Email Validation」列として元の df データフレームに保存し、セル出力として返します。Excel の条件付き書式を使用すると、無効なメール アドレスを含む項目をすぐに特定できます。
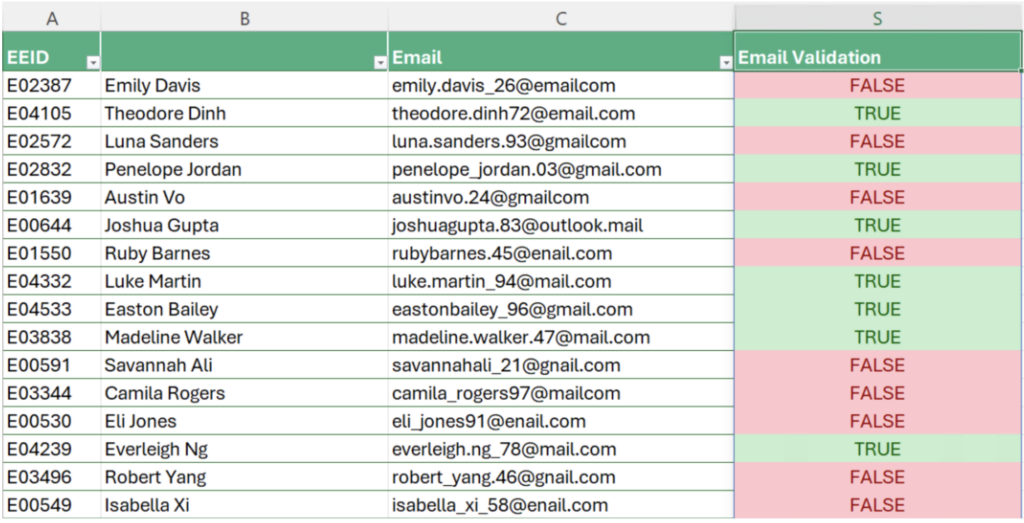
結果を見ると、行 13 のメール アドレスはドメイン名の後にドットがありませんが、無効であると正しく識別されていることが分かります。ただし、このパターンでは、有効ではあるものの間違っているメール アドレスを検出できません。たとえば、行 12 の Savannah のメール アドレスは @gnail.com として保存されています。したがって、これらのケースにも対応するように検証手順を改良する必要があります。
まず、データ内にある一意のメール ドメインをすべて特定するため、Python を使用します。Python セルとして設定された U1 セルに以下のコードを記述します。
df = xl("C1:C1001", headers=True)
pattern = "[^\s@]+@[^\s@]+\.[^\s@]+$"
df["Email Validation"] = df.Email.str.match(pattern)
emails = df[df["Email Validation"] == True].Email.values
emails = set([e.split("@")[-1] for e in emails])
emailsこのコードはすべてのメール アドレスを選択し、以前の検索パターンを使用して無効なメール アドレスをすべて除外し、@ 記号文字でメール アドレスを分割し、最後の (右端) 部分を保持します。結果を Python セットとして返すと、すべての一意の値を確実に取得できます。セルを実行すると、次の結果が得られます。
mail.com
outlook.mail
gnail.com
enail.com
gmail.com
email.com
このデータセットには合計 6 つの一意のドメインがあり、予想どおり、そのうちのいくつかは mail の入力ミスであることがわかります。以前の検索パターンを調整して、すべてのドメインが正しいドメインに一致することを確認します。
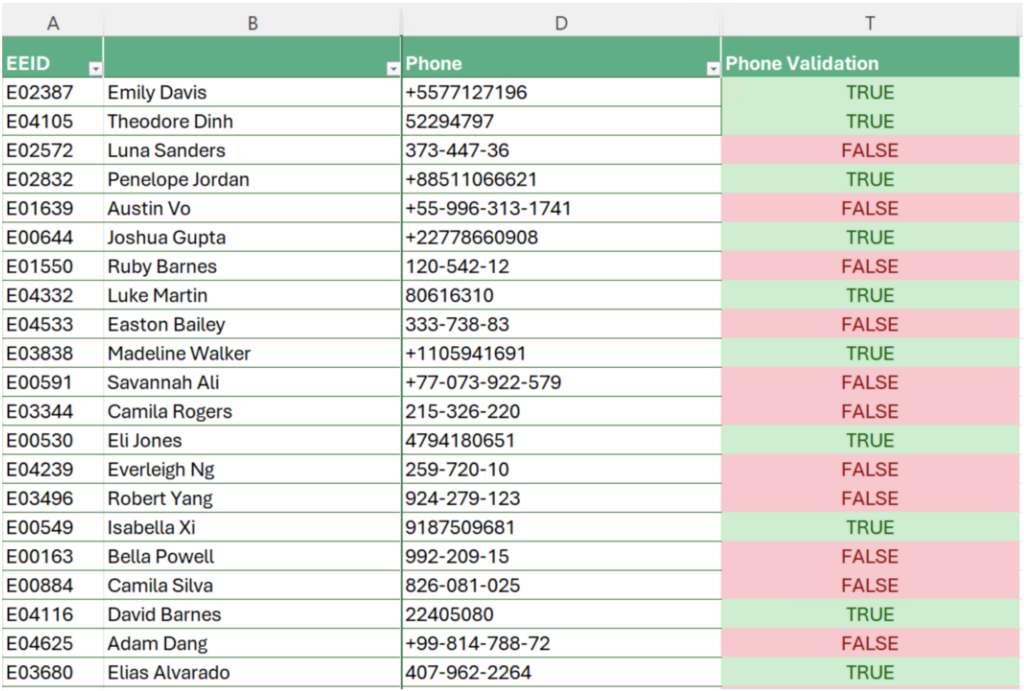
email_pattern = "^([^\s@]+)@((outlook\.mail)|([e|g]?mail\.com))$"今回は、丸括弧で囲まれた正規表現グループを利用して、メール アドレス パターンのすべての部分を照合します。具体的には、最初のグループはアカウント名と照合し、@ 記号とドメイン グループが続きます。ドメイン グループは 2 つのサブグループに分けて照合します。1 つは outlook.mail ドメイン用で、もう 1 つは残りの 3 つ (mail.com、email.com、gmail.com) 用です。クラスと量指定子の完璧な組み合わせを使用して、1 つのグループ内で 3 つのドメインを照合できる、つまり、? 論理量指定子を使用して email、gmail、mail のいずれかの単語を照合できることに注目してください。この新しいメール アドレス パターンをメール アドレス検証コードで使用すると、単一の正規表現で無効なメール アドレスと正しくないメール アドレスが特定され、エラーのある項目が増えます。
Phone 列の検証
電話番号の検索パターンは、これまでに使用したすべての正規表現ツールと手法を利用できる興味深いものです。まず、電話番号の主な構成要素は、国番号、市外局番、市内局番です。メール アドレスの検証と同様に、分割統治方式で一度に 1 つのグループずつ作業して、電話番号の一般的な検索パターンを構築します。
国番号はオプションの要素であり、1 つ以上の数字で構成され、通常は先頭に「+」記号が付きます。データ形式に関するすべての知識と考慮事項を正規表現に組み込む必要があります。国番号グループは次のように表現できます。
country_code_pattern = "(\+\d{1,3})?"最初の「\+」は、「+」記号が量指定子としてではなく、文字として解析されるようにバックスラッシュ文字を使用してエスケープしています。次の「\d{1,3}」は、国番号の 1~3 桁の数字を示します。最後の「?」論理演算子は、このグループ全体がオプション (省略可能) であることを示します。
一方、市外局番はオプションの括弧で囲まれた、国や地域により長さの異なる数字です。市外局番が 1~4 桁の場合、次のように表現できます。
area_code_pattern = "\(?\d{1,4}\)?"バックスラッシュ文字を使用して括弧をエスケープし、「?」論理演算子により括弧の照合をオプション (省略可能) にしています。
市内局番は一連の数字で構成され、空白、ハイフン (-)、ドット (.) などのオプションの区切り文字でグループに分けられます。
local_number_pattern = "\d{3}[\s.-]?\d{4}"このパターンの量指定子の使用方法は、前の例と異なることに注意してください。このパターンでは、各グループで想定される文字の正確な長さ、つまり 3 と 4 を指定しています。これらの数字は、クラス [\s.-]? で検出されるオプションの空白、ドット (.)、またはハイフン (-) で区切られています。
この 3 つのグループを 1 つの検索パターンにまとめ、文字列の先頭 (^) と末尾 ($) を表す区切り文字を追加すると、電話番号の検索パターンが得られます。
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"従業員データセットを使ってこのパターンをテストしてみましょう。T1 に新しい Python セルを作成し、次のコードを記述します。
df = xl("D1:D1011", headers=True)
phone_pattern = "^(\+\d{1,3})?\s?\(?\d{1,4}\)?[\s.-]?\d{3}[\s.-]?\d{4}$"
df["Phone Validation"] = df.Phone.str.match(phone_pattern)
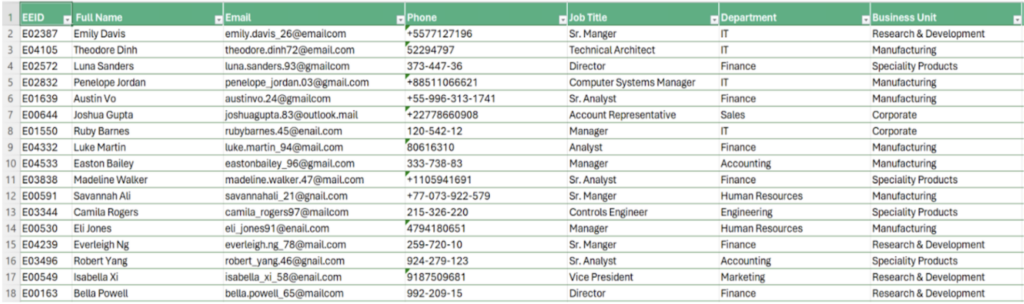
df["Phone Validation"]図 5 は、テスト結果の抜粋です。セルの条件付き書式設定で結果を強調表示しています。正規表現が電話番号形式の複数のバリエーションをどのように取得して検証できるかは注目に値します。図 5 から、さまざまな形式の正しい電話番号が、一見するとどのように異なって見えるかがわかります。
まとめ
正規表現は、文字列データを検証する非常に強力なツールです。正規表現を使用すると、特殊な演算子と一連の文字の組み合わせとして定義された検索パターンにデータが準拠しているかどうかを確認できます。この記事では、Python in Excel 統合によってこの新しい機能をワークブックで直接使用し、自動データ検証を行う方法について説明しました。まず、主要な概念と、メタ文字、文字クラス、グループなどの正規表現の演算子を紹介しました。次に、1,000 件の従業員データセットで使用法を実証しました。正規表現を使用することで、メール アドレス、従業員 ID、電話番号を照合し、データ内の入力ミスや不一致を特定することができました。ここで使用した例の Python コードを含む Excel ワークブックの完全版は、こちらで公開されています。
2024 © Anaconda Inc.
「Advanced Data Validation using Regular Expressions with Python in Excel」