さまざまな専門家が異なるスキルを使ってデータを分析しています。Microsoft Excel ユーザーは Excel のピボット テーブルを使用し、データ サイエンティストは統計モデルや機械学習モデルを使用しています。
このように方法は異なりますが、Excel ユーザー、データ サイエンティスト、統計学者は、データを視覚的に分析するという普遍的なデータ分析スキルを共有しています。
この記事は、Microsoft Excel で Python を使ってデータを視覚的に分析する方法を紹介するシリーズのパート 1 です。
このシリーズを通じて、数値データ、カテゴリ データ、時系列データを視覚的に分析する基本的なスキルを身に付けることができます。これらのスキルは、職種や業種を問わず、あらゆる専門家に価値をもたらします。
このシリーズの各記事には、Microsoft Excel のワークブックが用意されています。パート 1 のワークブックは、こちらからダウンロードできます。
このシリーズは、以下の 5 つのパートで構成されます。
- パート 1 – ヒストグラムの使用 (この記事)
- パート 2 – ボックスプロットの使用
- パート 3 – 散布図の使用
- パート 4 – 棒グラフの使用
- パート 5 – 折れ線グラフの使用
このシリーズについて注意すべき点がいくつかあります。
Python in Excel を初めて使用する場合は、このシリーズで想定している多くの概念について説明した「Excel アナリスト向け Python」シリーズから始めることをお勧めします。
このシリーズでは、Python in Excel パブリック プレビューが有効になっていることを前提としています。Python in Excel にアクセスするために必要な情報は、Microsoft の記事に記載されています。
このシリーズでは、コードの記述に Microsoft Excel Labs Python Editor を使用します。ただし、Python Editor は必須ではありません。すべてのコードは、数式バーと新しい PY() 関数を使用して入力できます。
このシリーズでは、データセットのソースに Anaconda Toolbox を使用します。ただし、Toolbox の使用は必須ではありません。すべてのデータは、Excel ワークブックのダウンロードに含まれています。
数値データの要約
最も一般的なデータ分析シナリオの 1 つは、数値の列から洞察を導き出すことです。数値は、注文数、売上高、患者の年齢など、何でもかまいません。
列が小さい場合 (たとえば、値が 10 個の場合)、数値を調べて、次の質問に答えることで、比較的簡単に洞察を導き出せます。
- 最小値と最大値は?
- 値の変動幅は?
- 数値の集合の標準値は?
しかし、これが可能なほど小さな列はめったにありません。数値の列に関する洞察を導き出す人間の能力は、列が大きくなるにつれて急激に低下します。
そこで、数値の列を要約することが重要になります。Microsoft Excel の MIN()、MAX()、STDEV.S()、AVERAGE() などの関数は、数値データを要約して洞察を得るためによく使用されます。
上記の関数 (および Python の同等の関数) は間違いなく役立ちますが、それらは全体像の一部しか伝えてくれません。そこで、数字の列を視覚的に分析することが重要になります。
米国の州別人口データ
この記事では、2014 年の米国 50 州、コロンビア特別区、プエルトリコの人口データを使用して、数値の列を視覚的に分析する方法を紹介します。
注 – Anaconda Toolbox を使用してデータをインポートする代わりに、この記事の Excel ワークブックの Raw Data ワークシートに含まれるデータセットを使用することもできます。
米国の州別人口データセットは、Excel のリボンの [数式] タブにある [Anaconda Toolbox] アドインから簡単にアクセスできます。

Toolbox にサインインすると、次の画面が表示されます。
Toolbox には、データセットのソース以外にもいくつかの機能があります。これらの機能は、Anaconda の今後のコンテンツ (ブログやコースなど) で取り上げます。
Anaconda は、Excel ワークブックにインポートできる無料のデータセットを多数提供しています。Toolbox で [Import Data from Cloud] をクリックすると、インポート済みのデータが表示されます。
[Import data] ボタンをクリックすると、以下のオプションが表示されます。
この記事で使用するデータセットは [Public Catalog] です。このオプションをクリックすると、公開されているデータセットの一覧が表示されます。
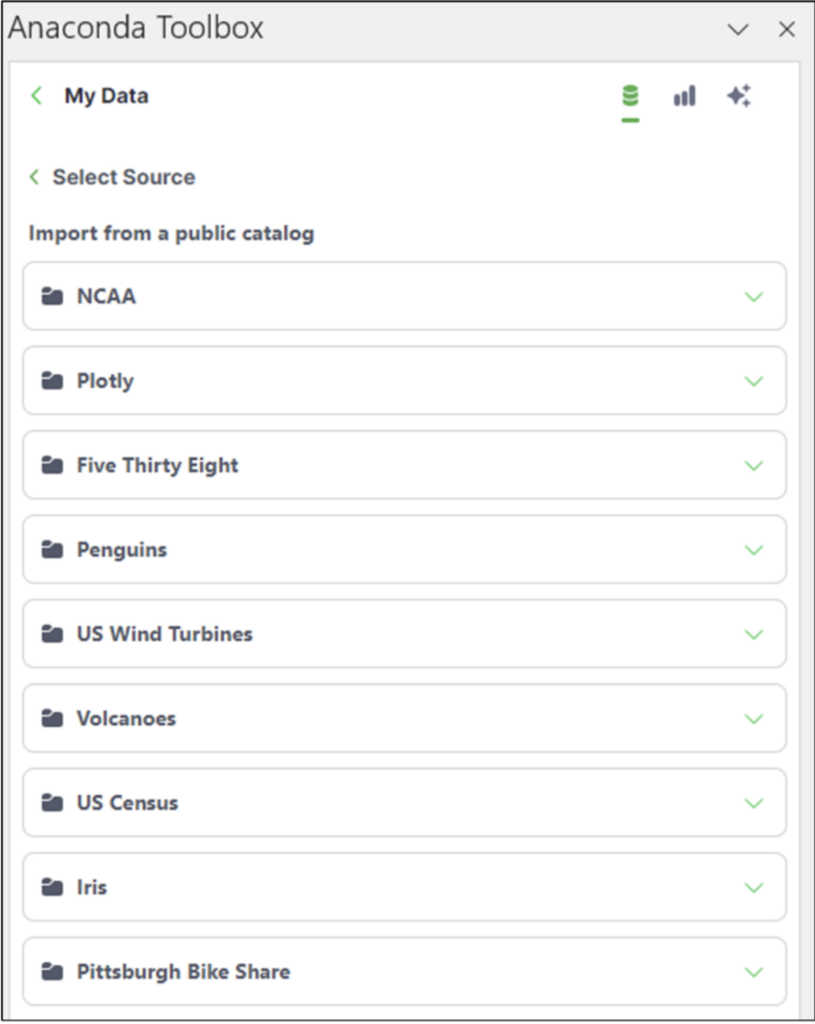
2014_us_states_population データセットは、Plotly フォルダーにあります。フォルダーをクリックすると、Plotly データセットの一覧が表示されます。
リストを下にスクロールして 2014_us_states_population を選択し、[Next] ボタンをクリックします。そして、US State Pop 2014 ワークシートを選択します。
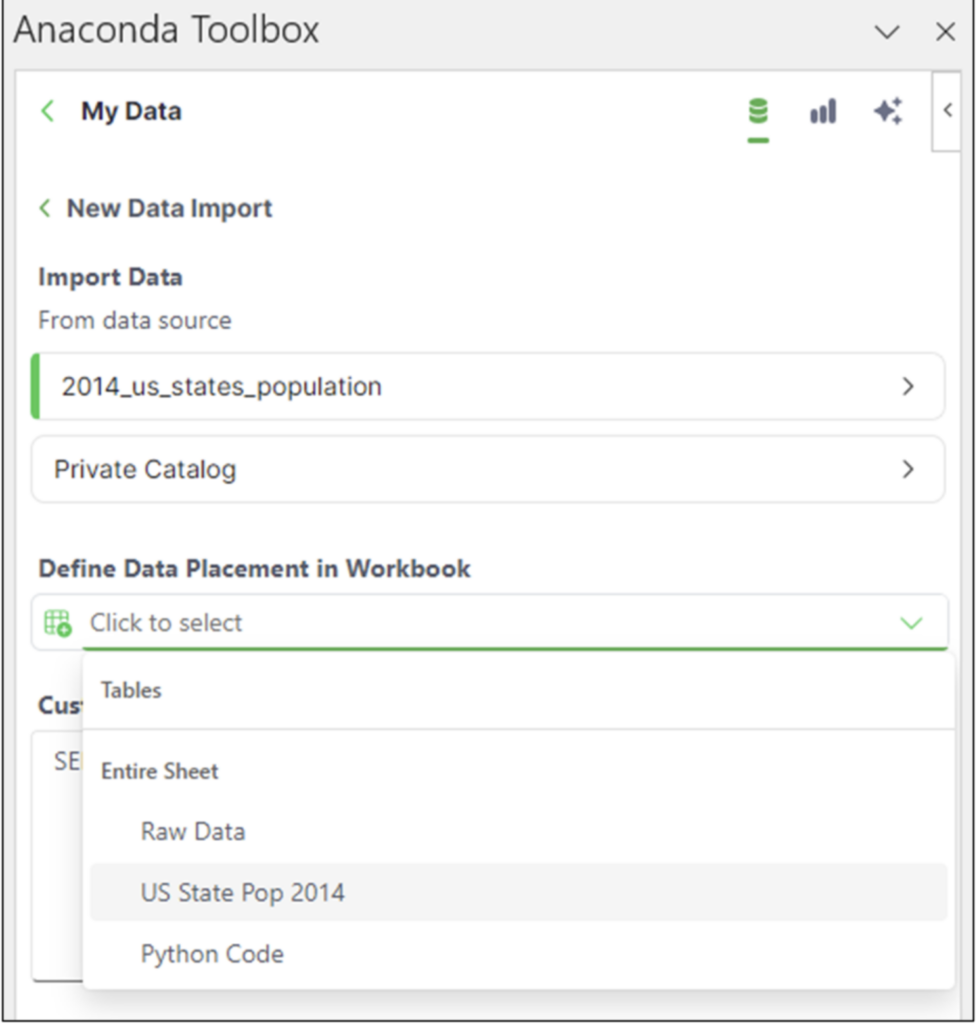
ワークシートを選択したら、[Import] ボタンを選択します。選択したワークシートにデータが読み込まれます。
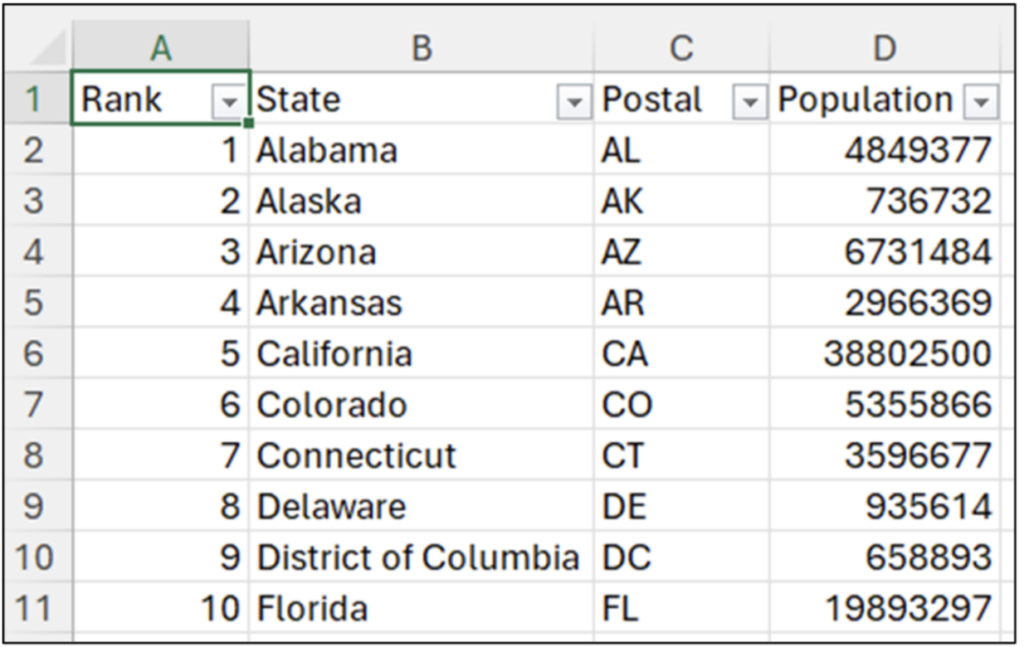
数値の列の集計
データセットの Population 列の平均は約 620 万です。平均は、数値の列の標準値を計算する 1 つの方法です。
平均は確かに便利ですが、データについて完全に把握できるわけではありません。私たちが知りたいのは、データがどのように分布しているかです。
次の質問は、データがどのように分布しているかに関連しています。
- 一般的に値は平均に近いか?
- 平均よりも小さな値が多いか?
- 平均よりも大きな値が多いか?
これらの質問に答える 1 つの方法は、個々の値を集計することです。Excel の並べ替え PivotTable を使用して集計をすばやく行うことができます。
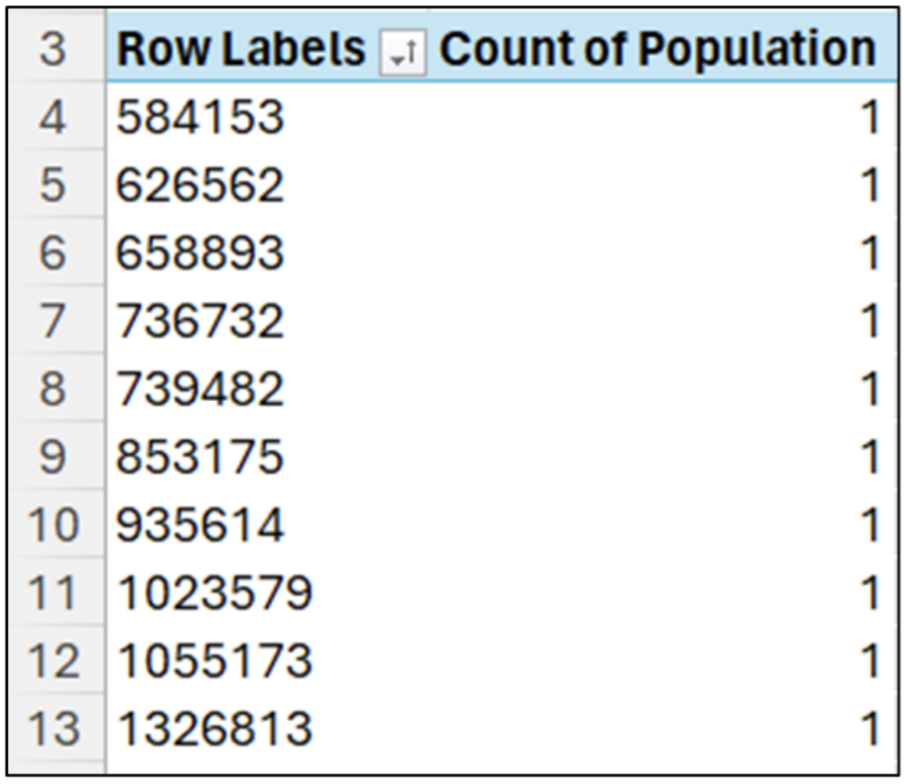
数値データの集計とは、それぞれの一意の値が列に何回現れるかを調べることです。
Population 列の場合、すべての値は一意です (つまり、すべての値が 1 回だけ出現します)。図 9 からわかるように、620 万より小さな値が多数あります。
集計リストを下にスクロールすると、半分以上の値 (52 個の値のうち 34 個) が平均より小さいことがわかります。

Population 列の値を集計すると、次の 2 つのことがわかります。
- Population 列の平均からは、データ内で何が起こっているかがほとんどわかりません。
- 数値の列に一意の値が多数含まれることはよくあることなので、集計はあまり拡張性がありません。
2 つ目は比較的簡単に修正できます。
数値のビニング
数値列のサイズが大きくなると、通常、一意の値が多くなります。個々の値を集計するのではなく、ビンを使用して集計する値の範囲を定義するほうが一般的です。
カウントされるのは、各ビンに含まれる列の値の数です。Excel の PivotTable グループを使用すると、数値の列にビンを実装できます。
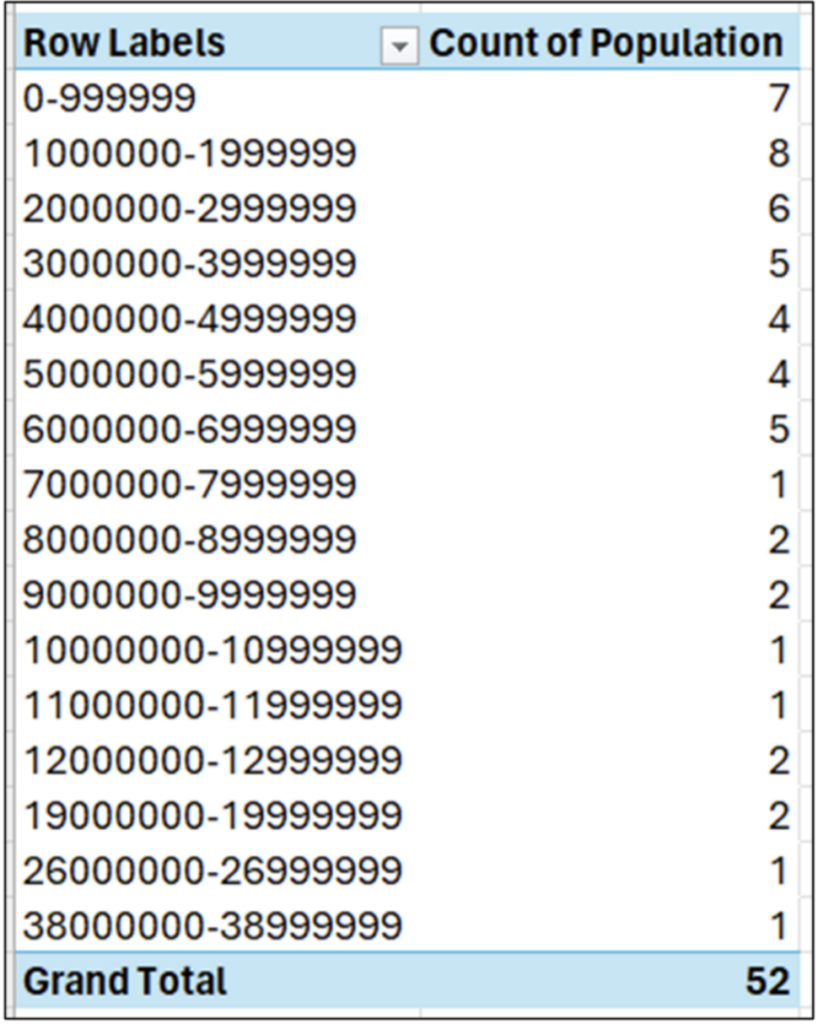
図 11 は、ビニングの威力を示しています。たとえば、データの半分 (つまり、52 個の値のうち 26 個) が、 平均の 620 万を大きく下回る 400 万未満であることがすぐにわかります。
ビニングは便利ですが、数値の分布の分析には、依然として表を使用しています。表は確かに便利ですが、データ パターンを検出するには最適ではありません。
人間は、視覚化を使用してパターンを検出するほうがはるかに得意です。
ビンの視覚化
ヒストグラムは、ビニングされた数値データを視覚化します。これは、数値の列を視覚的に分析するためのデフォルトです。統計コースを受講したことがある方は、ヒストグラムを目にしたことがあるでしょう。
Microsoft は、ビジュアル データ分析が専門家にとってどれほど価値があるか理解しており、デフォルトで Python の強力なデータ視覚化ライブラリへのアクセスを含めることで、Excel ユーザーが簡単に視覚化できるようにしています。
Excel のリボンにある [数式] タブで、デフォルトで含まれている Python ライブラリを確認できます。
[Python (Preview)] の [Initialization] オプションは、いくつかのライブラリを表示します。
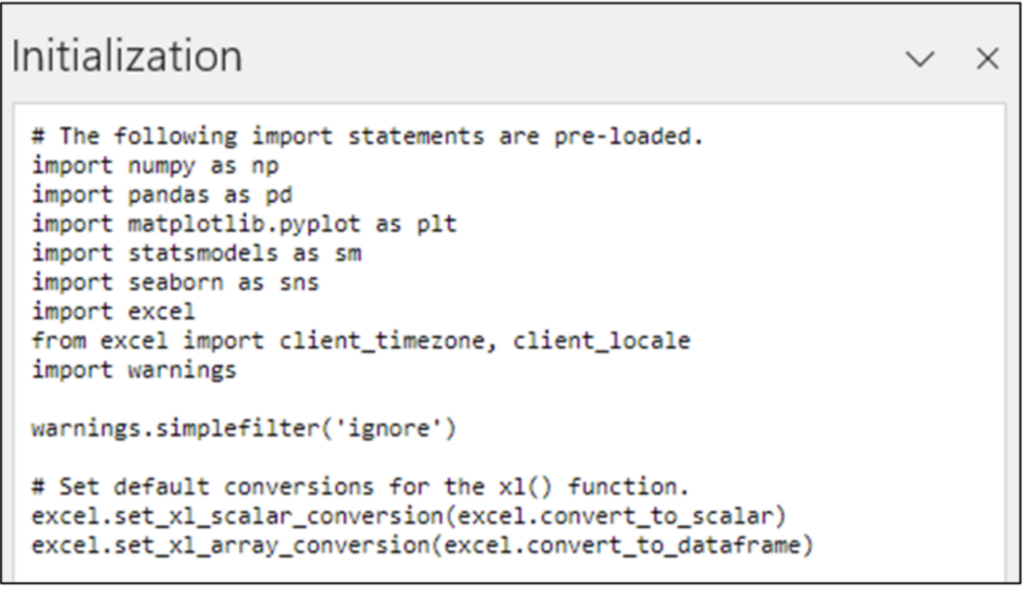
このシリーズでは、データの視覚化に seaborn ライブラリと matplotlib.pyplot ライブラリを使用します。
最初のヒストグラム
seaborn ライブラリは、その使いやすさから、Python データの視覚化に欠かせないものとなっています。
seaborn を使用すると、Excel では作成が困難または不可能な、強力なデータの視覚化をすばやく作成できます。
Microsoft Excel はヒストグラムの作成をサポートしていますが、機能は限定的です。さらに、seaborn を使用すると、Excel の GUI インターフェイスを使用するよりも高速になることがよくあります。
最初の手順は、Excel の リボンの [ホーム] タブから [Excel Labs Python Editor] を開くことです。

注 – Python Editor がない場合、すべてのコードは PY() 関数を使用して数式バーに入力できます。
この記事では、従来の Excel の数式バーを使用するよりも豊富なコーディング エクスペリエンスを提供する Python Code ワークシートを使用してコードを記述します。
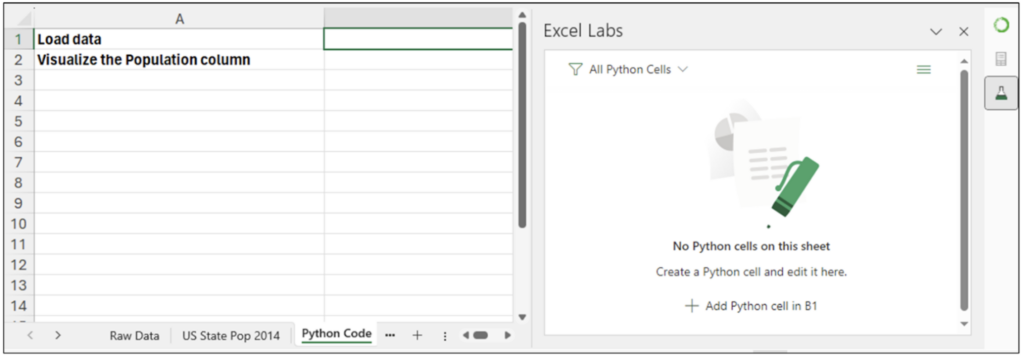
Excel Labs アドインで Add Python cell in B1 をクリックして Python Editor を開きます。以下のコードを入力すると、米国の州別人口データセットが pandas DataFrame として読み込まれます。
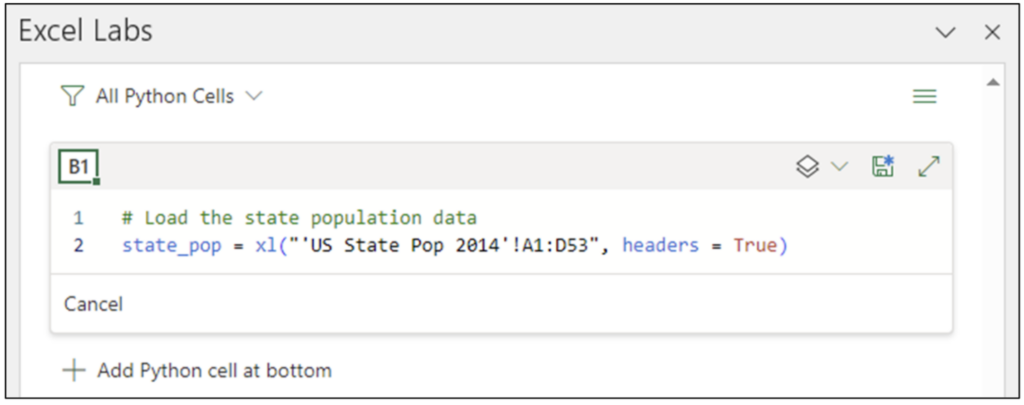
注 – Raw Data ワークシートを使用している場合は、上記のコードの ‘US State Pop 2014’ を ‘Raw Data’ に変更してください。
Python Editor のディスク アイコンをクリックすると、コードが実行されます。
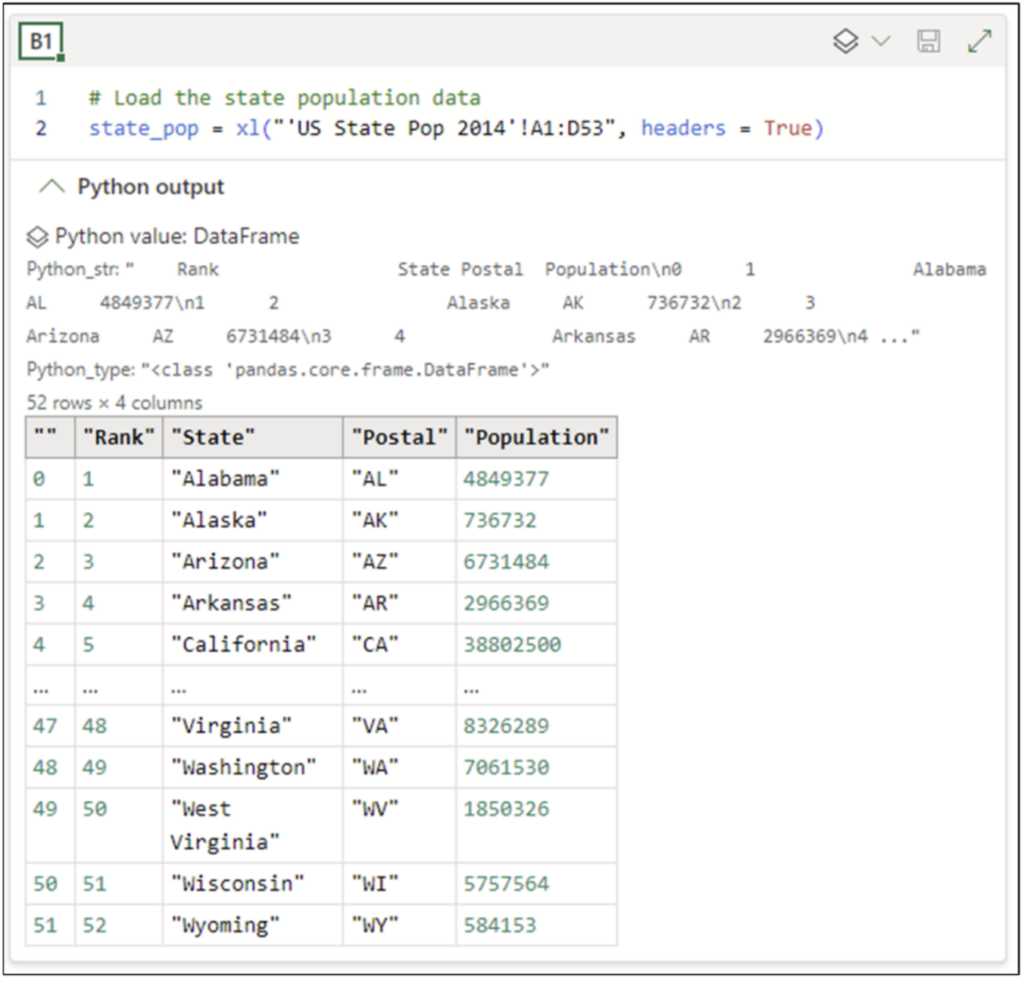
コードの実行が完了したら、Python Editor の [Python output] で DataFrame のプレビューを確認できます。
Python Editor 内で Add Python Cell at bottom をクリックすると、セル B2 用の新しい Python Editor ウィンドウが開きます。次の Python コードは、Population 列のヒストグラムを作成する方法を示しています。
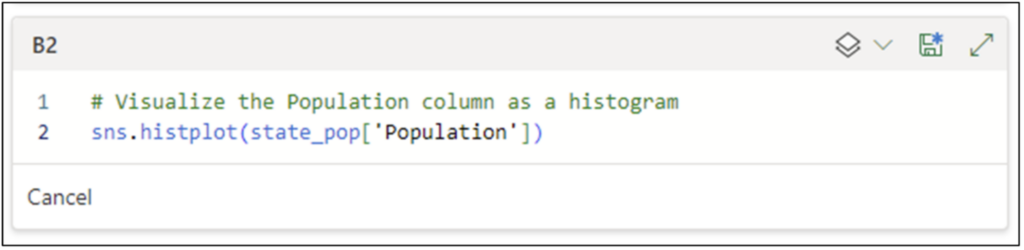
上記のコードは、seaborn ライブラリの histplot() 関数を使用しています。この関数には、Microsoft がデフォルトで提供する sns alias を使用してアクセスします。
セル B2 で Python コードを実行する前に、下向き矢印をクリックして出力を [Convert to Excel values] に変更する必要があります。
セル B2 で Python コードを実行すると、セル内にヒストグラムが生成されます。セルのサイズを拡大すると、ヒストグラム全体を確認できます。
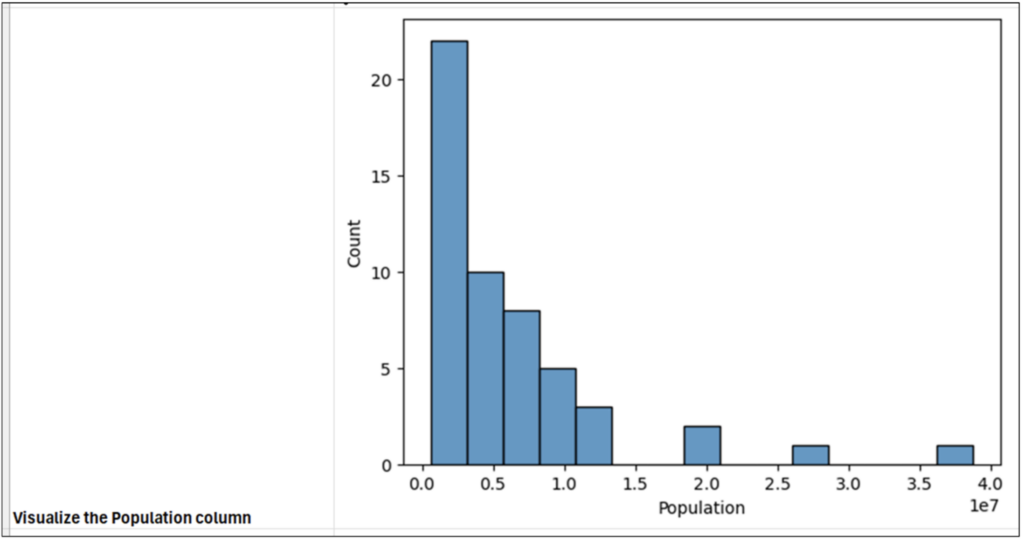
残念ながら、histplot() 関数を使用してデフォルトで生成されるヒストグラムには、いくつかの問題があります。そこで、ヒストグラムを改善するコードをいくつか記述してみましょう。
ヒストグラムの改善
図 21 に示すヒストグラムは技術的に問題ありませんが、次の 2 つの方法で改善できます。
- x 軸の値を理解しやすくします。
- 分析を容易にするため、すべてのデータの平均を表す垂直線をヒストグラムに追加します。
次のコードをセル B2 に追加すると、x 軸の値が科学的記数法から整数に変換されます。このコードでは、plt alias を使用して、pyplot ライブラリの ticklabel_format() 関数を使用します。
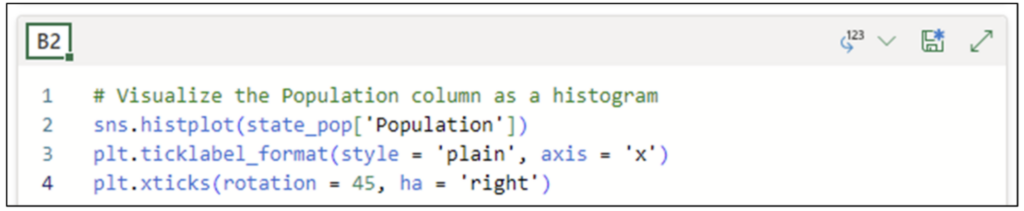
B2 のコードを実行すると、次の更新されたヒストグラムが生成されます。
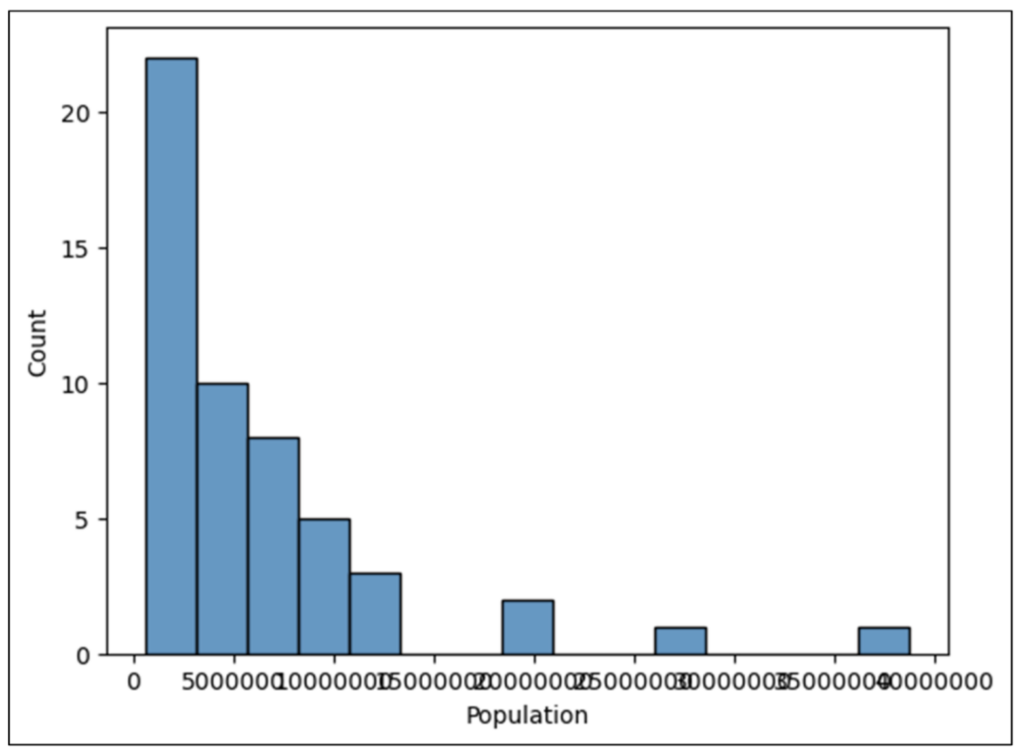
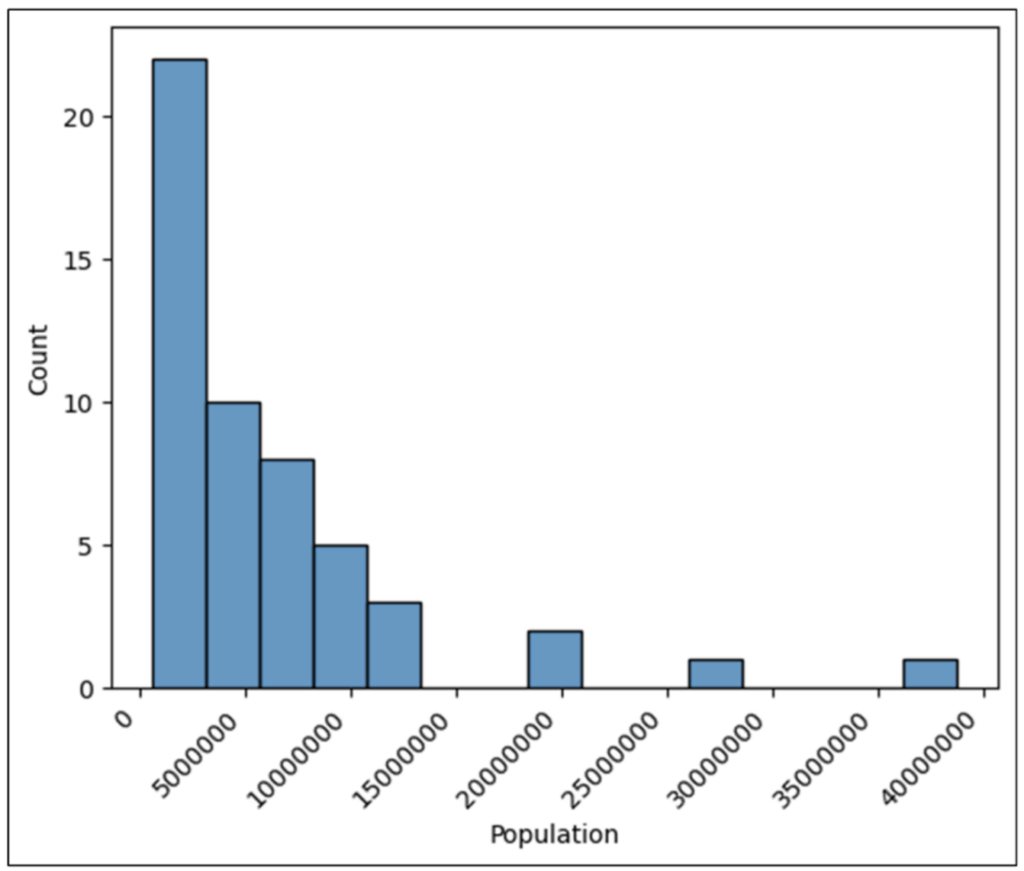
残念ながら、整数が大きく、x 軸が読めません。pyplot の xticks() 関数を使用するコードを追加すると、x 軸ラベルが右に 45 度回転します。
図 24 のコードを実行すると、次のヒストグラムが生成されます。
ヒストグラムの最後の改善点は、Population 列の値の平均に対応する垂直線を追加することです。pyplot の axvline() 関数を使用すると、ヒストグラムに線が追加されます。
図 26 のコードは、mean() メソッドを使用しています。これは、数値の列の算術平均を計算します。算術平均は、平均を計算することの別名と考えることができます。
図 26 のコードを実行すると、分析に使用するヒストグラムの最終バージョンが生成されます。
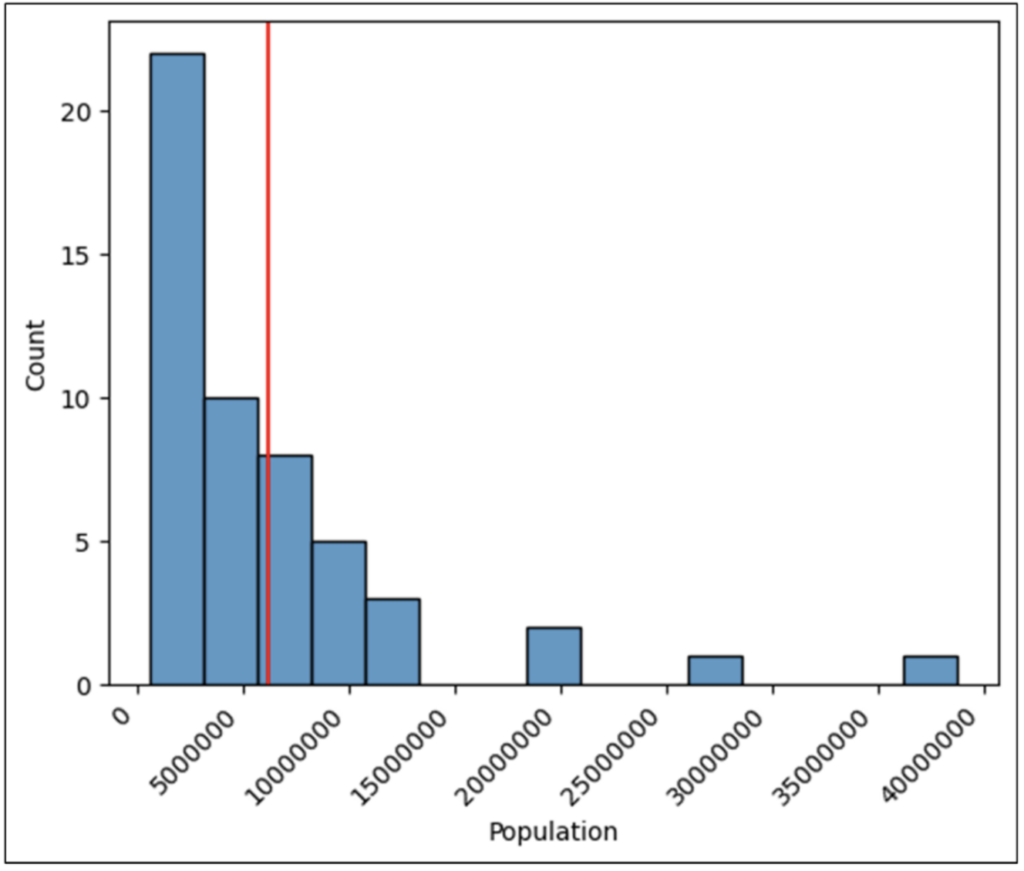
ヒストグラムの分析
ヒストグラムの分析では、視覚化されたデータを調べて次の特性を理解します。
- 分布
- 中央値
- 形状
次のサブセクションでは、ヒストグラムの最終バージョンを使用して、これらの特性について説明します。
ヒストグラムの分布
ヒストグラムの分布とは、最高値から最低値までを表した値の範囲です。
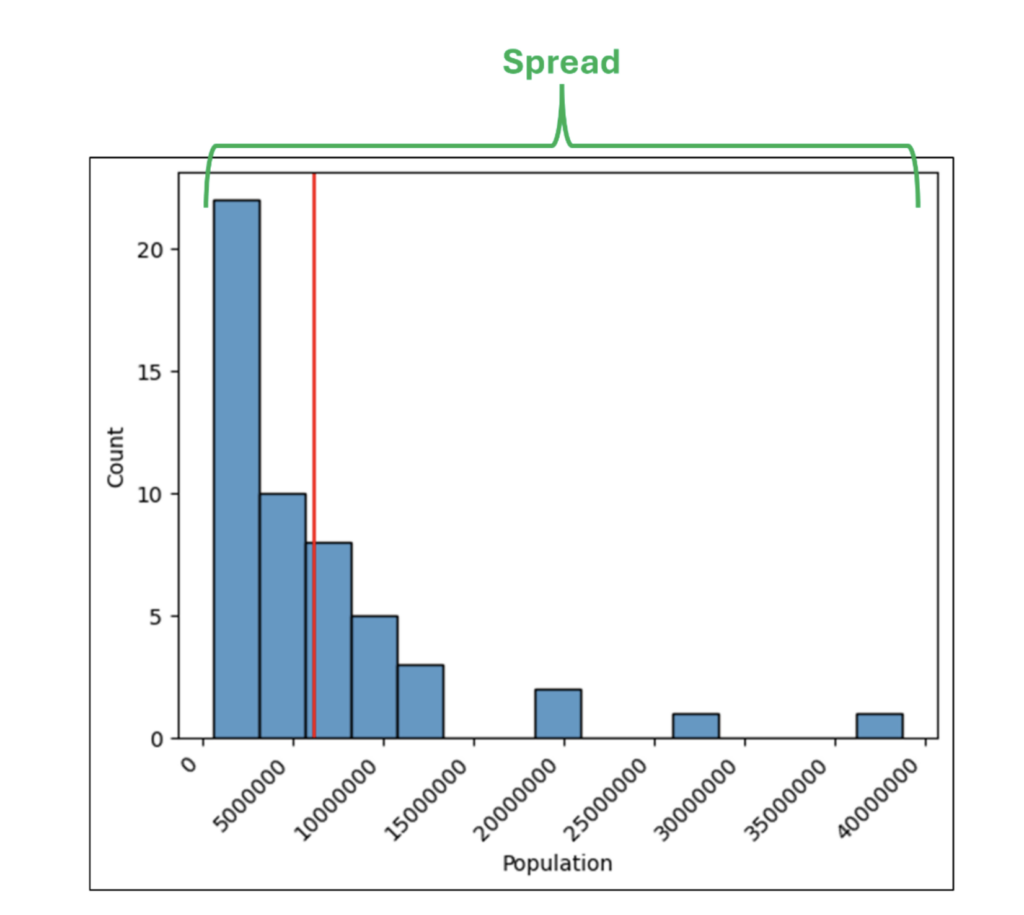
ヒストグラムの分布は、数値データの分布に関する最初の洞察を提供します。
- 最小値と最大値
- 値が存在しない領域 (ギャップ)
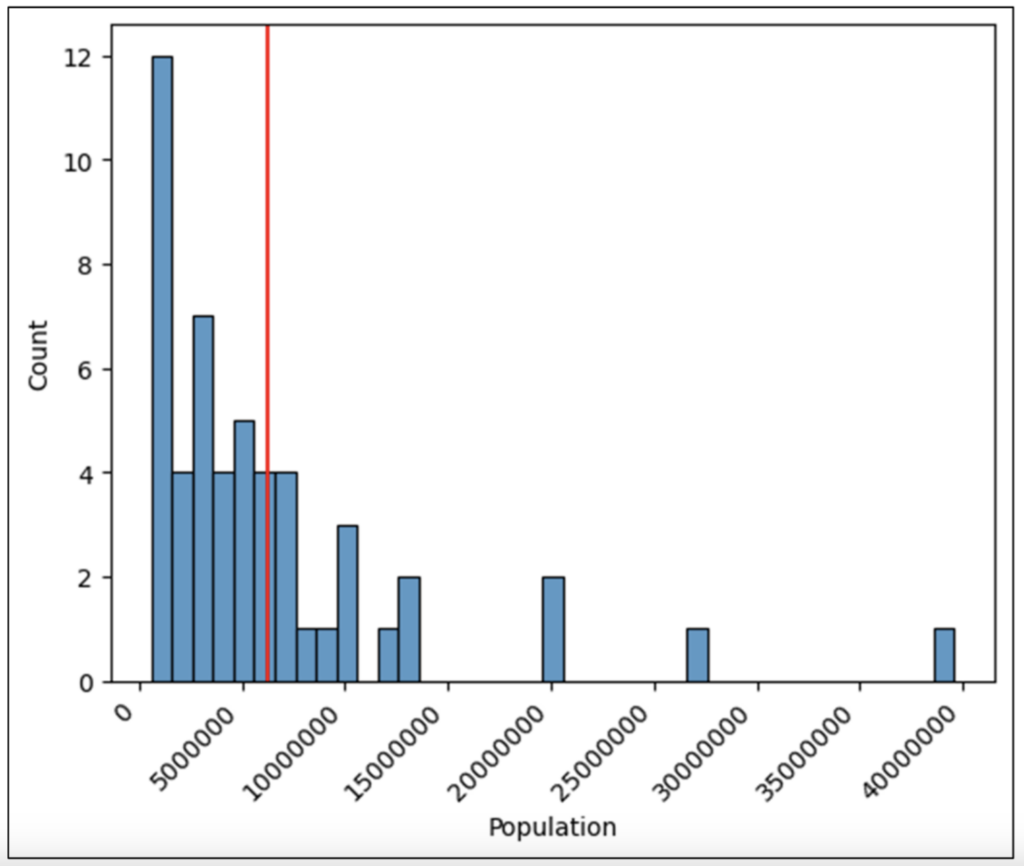
図 28 の分布から、米国の州の人口は 100 万人未満から約 3,800 万人までの範囲にあることがわかります。
また、人口が 1,500 万人を超える州はほとんどなく、分布にはギャップがたくさんあることもわかります (たとえば、人口が 3,000 万人から 3,500 万人の州はありません)。
ヒストグラムの分布を調べると、次の質問に答えることができます。
- 分析対象のデータにおいて最小値と最大値は意味があるか?
- (ギャップが存在する場合) 分析対象のデータにおいてギャップは意味があるか?
上記の質問に答えるには、通常、ドメインの専門知識/知識が必要です。
ヒストグラムの中央値
ヒストグラムの中央値は、数値データの集合 (例: DataFrame の列) の標準値を表します。
統計学者は、この標準値の概念を、位置の統計量または中心傾向と呼びます。
最もよく使用される位置の統計量は平均 (算術平均) ですが、他の尺度 (中央値 など) も使用されます。
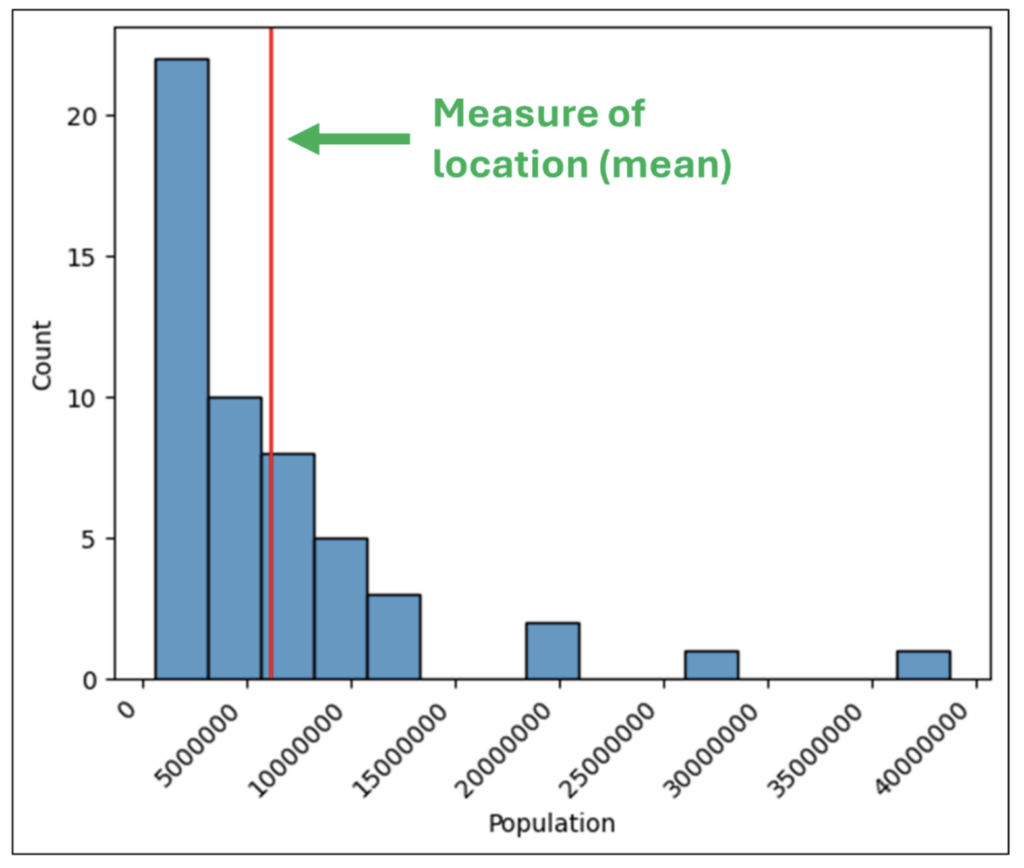
図 29 の形状から、ほとんどの値がヒストグラムの左端に集まっており、平均値よりも低いことがわかります。
つまり、平均値はデータの標準値を表していません (たとえば、カリフォルニア州のような巨大な州が平均値を押し上げています)。
また、米国のほとんどの州では人口が小さい傾向にあり、標準値 (たとえば、中央値) を表すよりよい方法が必要であると結論付けることができます。
ヒストグラムの形状
ヒストグラムの形状 は、ヒストグラムの分布全体にわたる値の密度を表します。
ヒストグラムの形状を調べると、次の質問に答えることができます。
- 多くの値が分布の片端に集まっているか?
- 多くの値が分布の両端に集まっているか (谷のような形状か)?
- 平均を中心に対称な丘のような形状か (ベル曲線か)?
- 複数のピークがあるか?
上記の質問をヒストグラムに当てはめてみましょう。
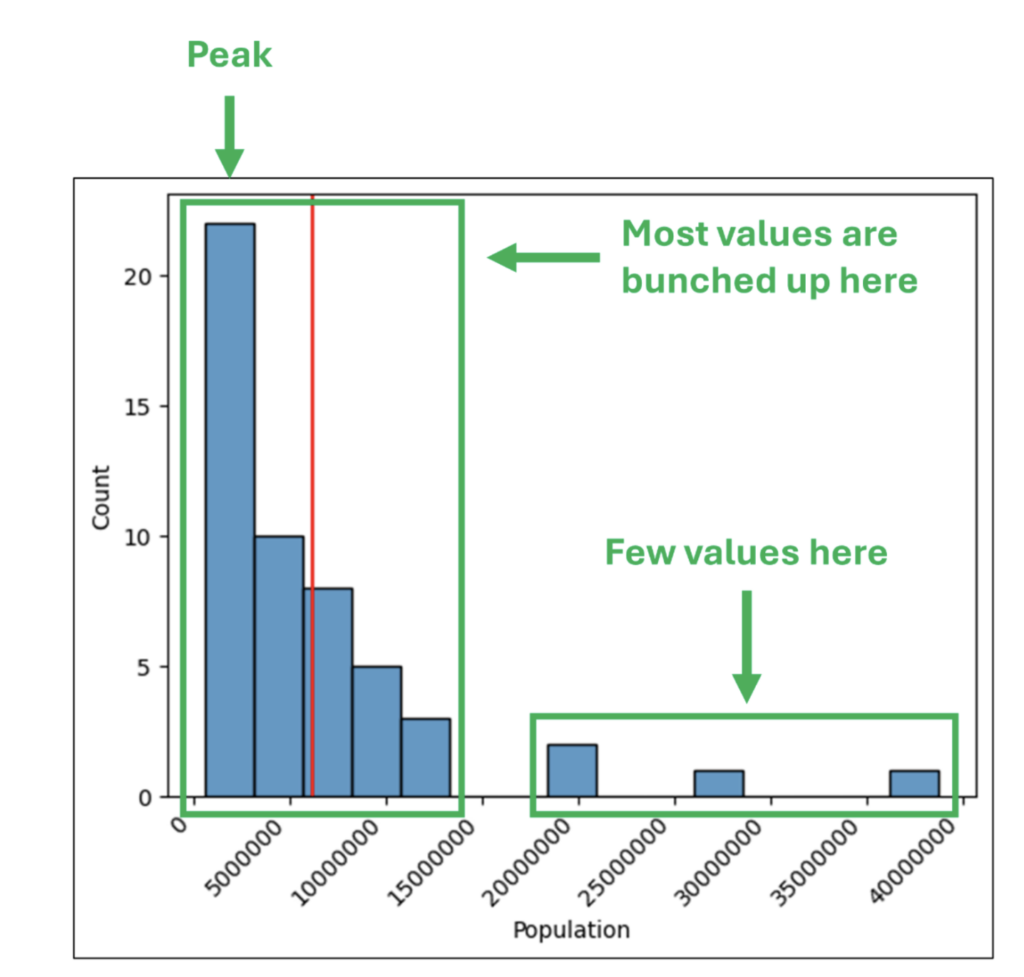
図 30 の形状から、米国の州の人口は大部分が小規模で、少数の州が不均衡であることが分かります。
たとえば、フロリダ州、テキサス州、カリフォルニア州を合わせると、米国全体の人口の 26.6% を占めます。
ヒストグラムの形状は、数値の分布について多くのことを教えてくれるだけでなく、さらに調査を進めるためのヒントも提供してくれます。
データセットの性質を考慮すると、内陸の州は人口が圧倒的に少ないかどうかを評価することが、調査の可能性の 1 つと言えるでしょう。
ヒストグラムの形状の変更
ヒストグラムの形状は、主に使用されるビン サイズによって決まります。
一般に、ビン サイズを小さくすると、通常はそれほど高くないバーの数が増え、ビン サイズを大きくすると、高さのあるバーの数が少なくなります。
binwidth パラメーターを使用すると、ヒストグラム内のビン サイズ (幅) を制御できます。次のコードでは、binwidth を 1,000,000 にしています。

以下は変更後のヒストグラムです。
どのようなデータセットでも、ビン サイズに関する明確なルールはありません。専門知識に基づいていくつかのビン サイズを試してみるのが一般的です。
ヒストグラムのビン サイズを決定するための経験則に興味がある方は、こちらの記事をご覧ください。
次にすべきこと
ヒストグラムは数値データを視覚的に分析する最も基本的な方法ですが、あらゆる状況で常に最善であるとは限りません。
たとえば、製品ラインごとに販売注文額の分布を比較したい場合には適していません。
このシリーズの次の記事では、ボックスプロットを使用してこのタイプの分析を実行する方法を説明します。このブログ シリーズが気に入った方は、自己学習型認定プログラム「Anaconda 認定: Python in Excel を使用したデータ分析」もぜひチェックしてみてください。
次回まで、楽しいデータ調査を続けてください!
2024 © Anaconda Inc.
「Visual Data Analysis with Python in Excel: Using Histograms」