この記事は、Microsoft Excel で Python を使ってデータを視覚的に分析する方法を紹介するシリーズのパート 2 です。
Python in Excel を初めて使用する場合は、このシリーズで想定している多くの概念について説明した「Excel アナリスト向け Python」シリーズから始めることをお勧めします。
このシリーズでは、コードの記述に Microsoft Excel Labs Python Editor を使用します。ただし、Python Editor は必須ではありません。すべてのコードは、数式バーと新しい PY() 関数を使用して入力できます。
このシリーズの各記事には、Microsoft Excel のワークブックが用意されています。パート 2 のワークブックは、こちらからダウンロードできます。
このシリーズは、以下の 5 つのパートで構成されます。
注: この記事で紹介する例を実際に試す場合は、Python in Excel の体験版をインストールしてください。このブログ シリーズが気に入った方は、自己学習型認定プログラム「Anaconda 認定: Python in Excel を使用したデータ分析」もぜひチェックしてみてください。
四分位数を使用した分布の理解
このブログ シリーズのパート 1 で説明したように、生のデータを目視して数値列から洞察を得ることは、列が大きくなるにつれて不可能になります。
パート 1 では、列内の数値の分布をヒストグラムで視覚的に表現する方法を示しました。ヒストグラムを使用すると、数千個の値を含む列から洞察を得ることができます。以下は、パート 1 で説明したヒストグラムの例です。
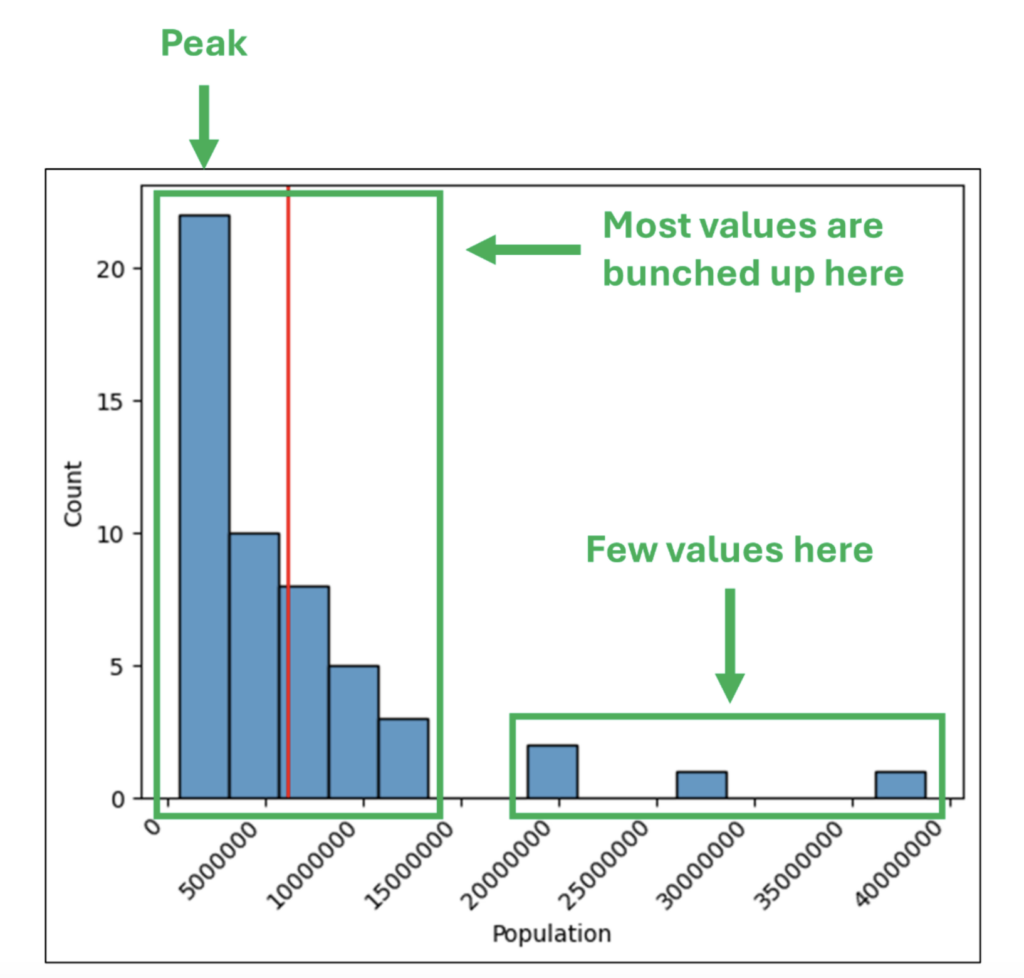
ヒストグラムは便利ですが、数値列から洞察を得るために使用できる唯一のデータ視覚化ではありません。
ボックスプロット (箱ひげ図とも呼ばれる) は、数値列の分布を視覚化するもう 1 つの方法です。ボックスプロットがヒストグラムと異なる点は、分布を特徴付けるために四分位数を使用することです。
中央値
四分位数について考える最も簡単な方法は、中央値を検討することです。中央値は、数値列の 50 パーセンタイルを表す値として定義されます。言い換えると、中央値は第 2 四分位数です。
概念的には、中央値は数値の集合 (DataFrame の数値列など) の標準値を表します。
次の 10 個の数値について考えてみましょう。これらの数値は、このブログ記事の Excel ワークブックの ResellerSales テーブルから抽出したものです。
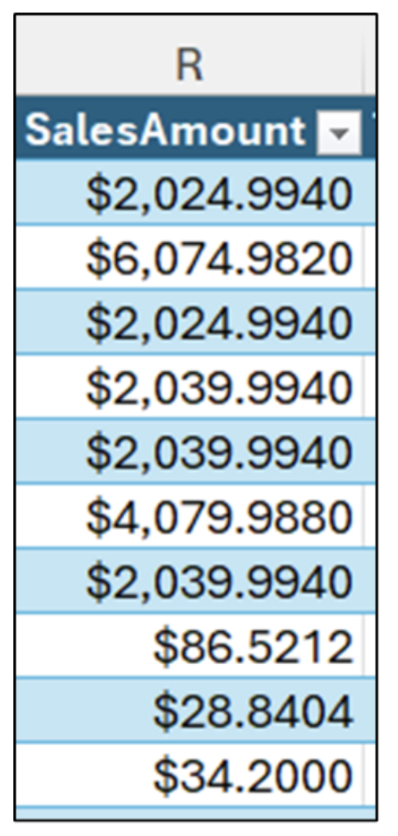
データを目視で確認すると、これらの 10 個の数字の標準値は約 $2,000 であると推測できます。この推測は、これら 10 個の数字の平均 (または平均値) が $2,047 であることからも裏付けされます。
ここで、最後の値が置き換えられ、10 個の数字が次のようになったとしたらどうなるでしょうか。
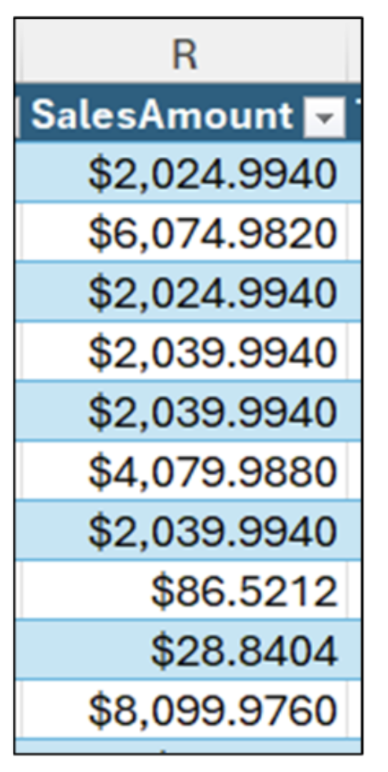
図 3 のデータを目視で確認すると、次のような特徴があります。
- 半分の値は $2,000 ドル前後です。
- 2 つの値は $2,000 未満です。
- 3 つの値は $2,000 を超えています。
おそらく、これら 10 個の数値の標準値の妥当な推測は $2,000 です。
しかし、これら 10 個の値の平均は $2,854 で、$2,000 よりも $3,000 に近くなります。
中央値を使用して、妥当な推測と標準値の平均を比較できます。
中央値を見つける最初の手順は、図 3 のデータを並べ替えることです。
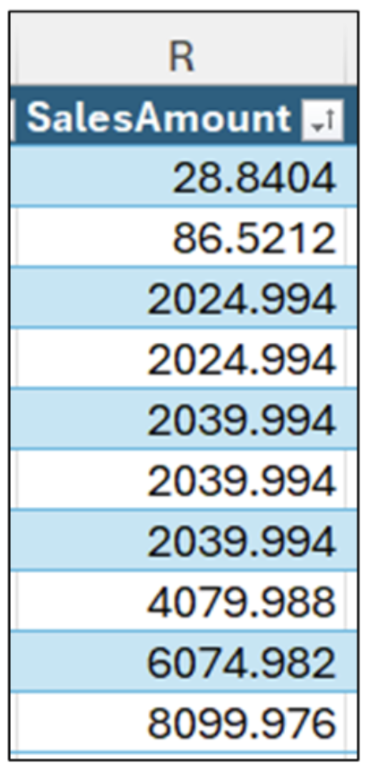
中央値は並べ替えたデータの中央にある値です。
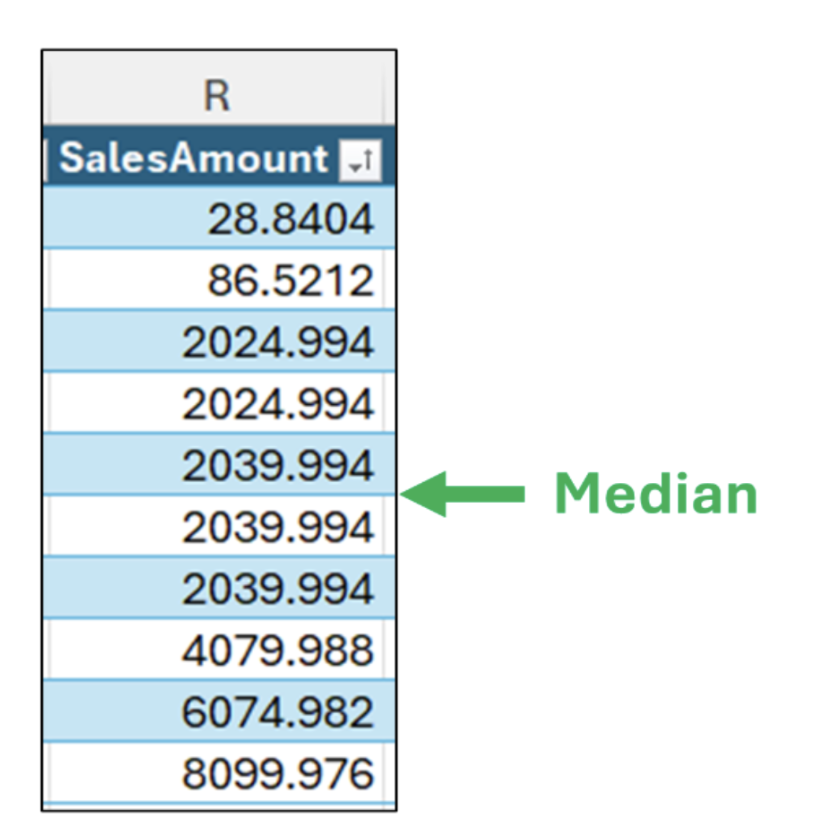
図 5 が示すように、数値の数が偶数 (この例では 10) の場合、中央値は 1 つではありません。
このような状況では、中央値は、並べ替えたデータの中央にある 2 つの値の平均として計算されます。この例では、2 つの値は同じなので、中央値は $2,039.994 です。
これは、中央値が数値列の標準値として有用である理由を示す典型的な例です。
小さい値や大きい値は、平均に比べて中央値にあまり影響しません。
中央値から四分位値へ
前述のように、中央値は数値データ集合の 50% の値、つまり第 2 四分位値を表し、データ集合の標準値を表します。
分布の広がりを特徴付けるために、追加の四分位値を使用することもできます。
たとえば、図 5 に第 1 四分位値と第 3 四分位値を追加すると、データ内の値の分布がわかります。
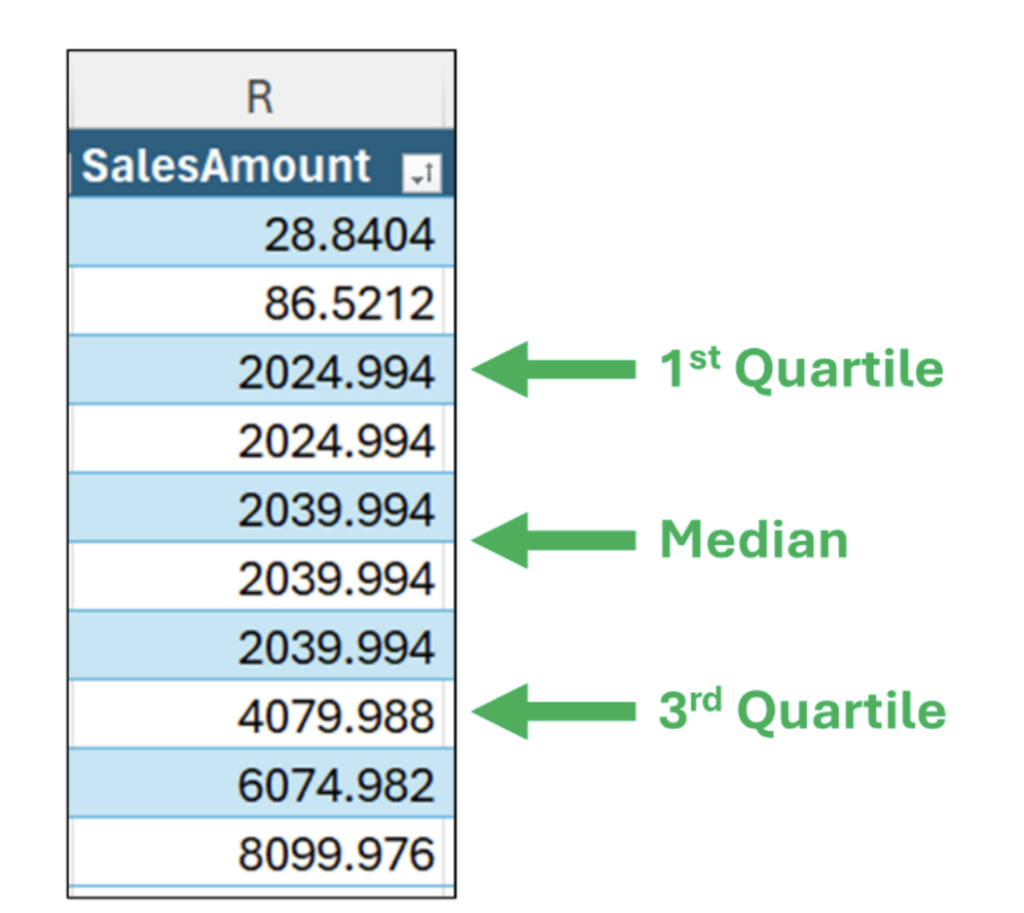
注: 図 6 は、第 1 四分位数と第 3 四分位数の概念を表したもので、正確な計算は少し異なります。
図 6 は、数値データの分布を特徴付けるため、四分位数を使用することの価値を示すのにあまり適していません。
四分位数の有用性は、ボックスプロットを使用して多くの数値の分布を特徴付ける場合に明らかになります。
最初のボックスプロット
ヒストグラムと同様に、ボックスプロットは数値データ列の分布を視覚化する非常に強力な方法です。ボックスプロットは、四分位数を使用して数値データの分布を示します。
ボックスプロットが特に強力なのは、カテゴリ別に分布を視覚化できることです。
ここでは、このブログ記事の Excel ワークブックに含まれる ResellerSales テーブルのデータを使用します。
ResellerSales テーブルには、Microsoft の AdventureWorks Data Warehouse サンプル データベースに基づいた仮想販売データが含まれています。
データは 60,855 行と 23 列のデータで構成されています。この記事では、SalesTerritoryGroup、SalesAmount、および OrderDate の 3 つの列を使用します。
ボックスプロットのコーディング
ここでは、ボックスプロットを使用して ResellerSales テーブルの SalesAmount 列の分布を分析します。
ボックスプロットは通常、Excel テーブルの 2 つの列 (数値列 1 つとカテゴリ列 1 つ) を使用して作成されます。
最初に、次の Python コードで pandas ライブラリを使用して ResellerSales Excel テーブルを読み込みます。
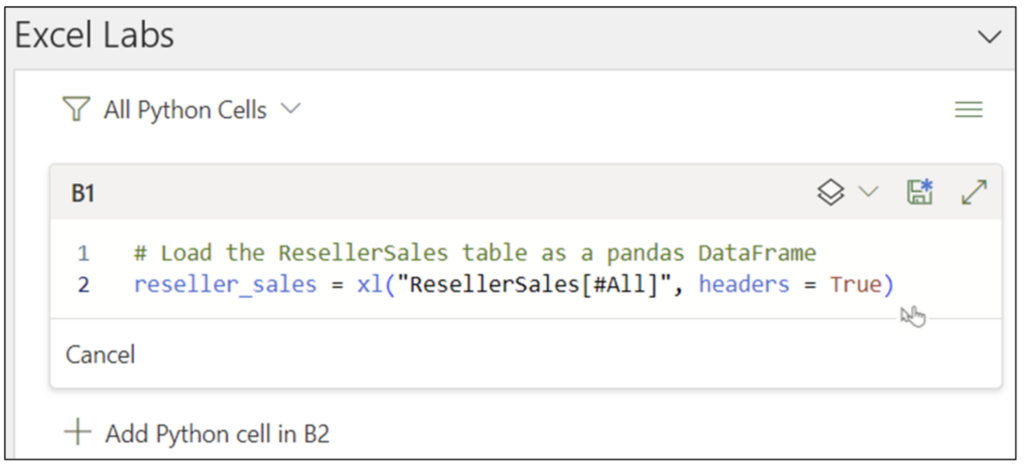
注: 上記の Python コードは Excel Labs Python Editor を使用して記述されていますが、これは必須ではありません。
Python Editor のディスク アイコンをクリックすると、コードが実行されます。
データが DataFrame として読み込まれると、次の Python コードは seaborn ライブラリを使用して、SalesAmount 列と SalesTerritoryGroup 列を使用したボックスプロットを作成します。
セルの Python Editor の下向き矢印をクリックすると、[Convert to Excel values] オプションを選択できます。このオプションを使用すると、ワークシート セル内にボックスプロットが表示されます。
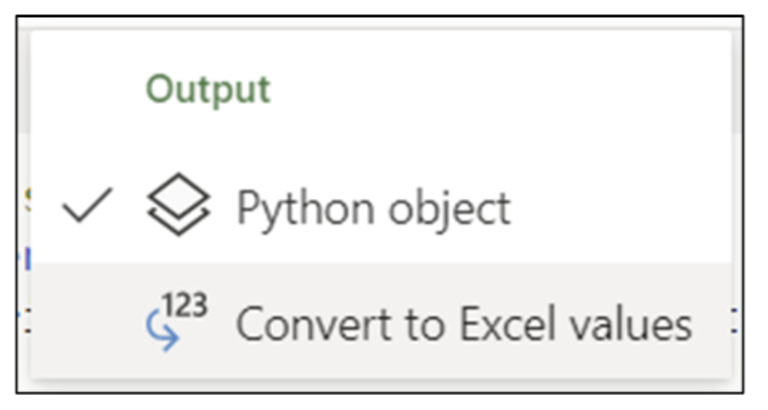
ボックスプロット コードを実行すると、視覚化されたデータが表示されます。
ボックスプロットは、SalesAmounts に関する強力な洞察を提供します。ただし、これらの洞察を得るには、ボックスプロットの解釈方法を知らなければなりません。
ボックスプロットの解釈
次の Python コードは、reseller_sales DataFrame をフィルター処理して、ボックスプロットとして視覚化します。フィルター処理により、視覚化が容易になります。

注: 図 12 は、[Convert to Excel values] オプションで構成されたコード セルを示しています。
上記のコードを実行すると、次のボックスプロットが生成されます。
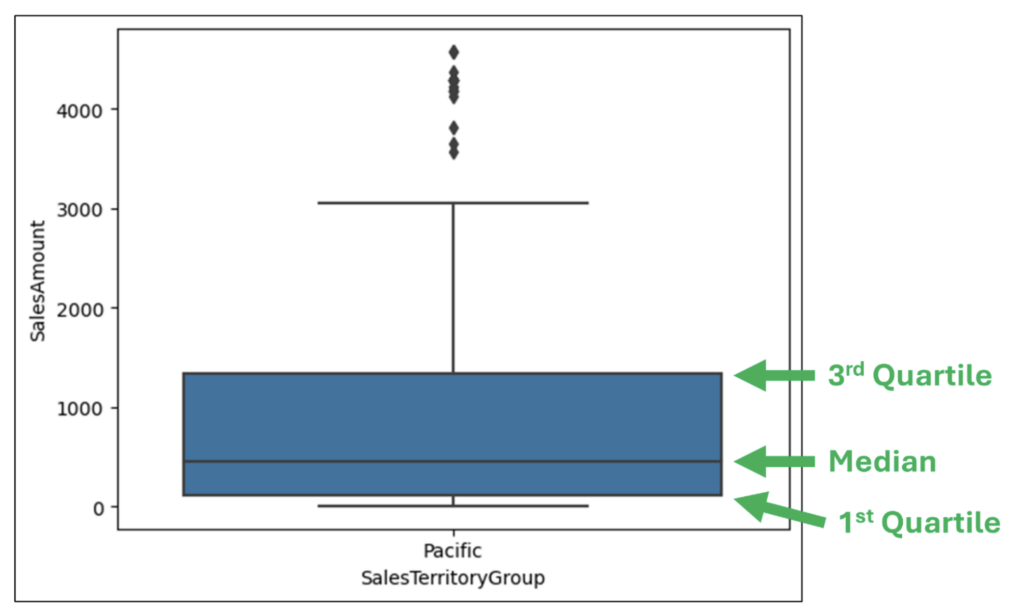
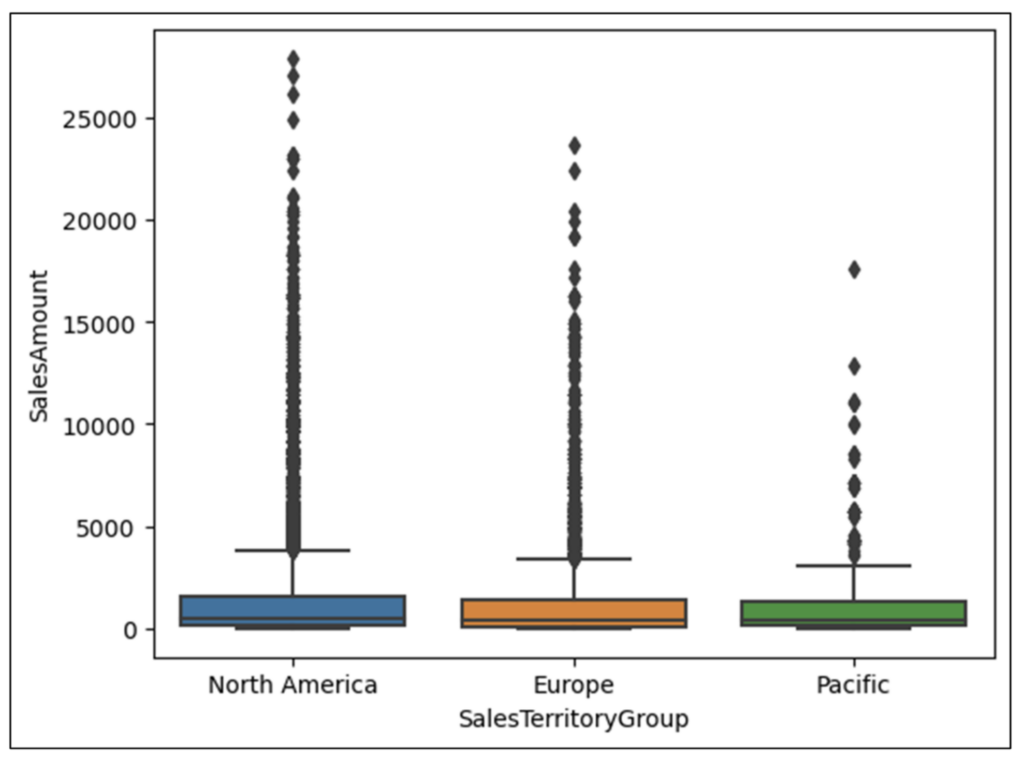
図 13 は、ボックスプロットのボックスの解釈方法を示しています。
- ボックスの上部は、データの 75 パーセンタイルを表します (つまり、データ内の 75% の値がこの線より小さい)。
- ボックスの下部は、データの 25 パーセンタイルを表します (つまり、データ内の 25% の値がこの線より小さい)。
- ボックスの上部と下部の間の線は、データの中央値 (つまり、50 パーセンタイル) です。
図 13 のボックスを調べると、Pacific SalesTerritoryGroup の SalesAmount の分布に関する多くの洞察が得られます。
- ボックスの上部は、SalesAmounts の 75% が $2,000 を大きく下回っていることを示しています。
- 中央線は、SalesAmounts の 50% が約 $500 以下であることを示しています。
- 中央線がボックスの下 1/3 にあることから、SalesAmounts は低い値に偏っています。
分析の観点から、上記のことから以下のような疑問が生じます。
- SalesAmounts が低い値に偏っている製品は?
- SalesAmounts が低い値に偏っている顧客は?
- SalesAmounts が低い値に偏っている他の要因 (割引など) は?
次に、ボックスプロットの「ひげ」を考慮します。
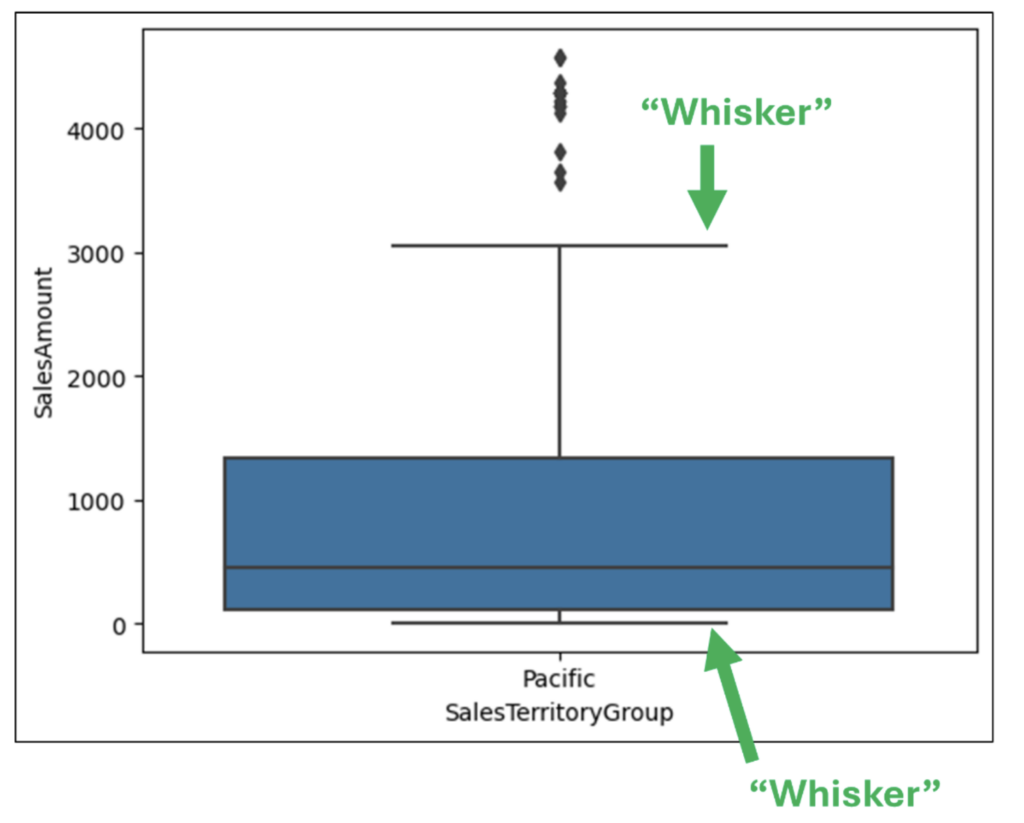
ボックスプロットのひげは、75 パーセンタイルより大きく、25 パーセンタイルより小さい値の分布を視覚的に表示します。
直感的には、ひげが長いほどデータ内の値は分散しており、ひげが短いほどデータ内の値は分散していません。
図 14 を調べると、次のような洞察が得られます。
- 上部のひげは下部のひげよりもはるかに長く、約 $1,200 から $3,000 までの高い SalesAmounts の範囲を示しています。
- 下部のひげは非常に短く、SalesAmounts が $0 から $100 程度であることを示しています。
分析の観点から、これらのひげを調べると、以下のような追加の疑問が生じます。
- SalesAmounts は現在よりも過去のほうが高かったか?
- 時代とともに低価格の新製品が登場し、SalesAmounts を歪めている可能性はないか?
- キャンペーン割引の使い方は時代とともに変化したか?
最後に、ボックスプロットの「外れ値」を考慮します。
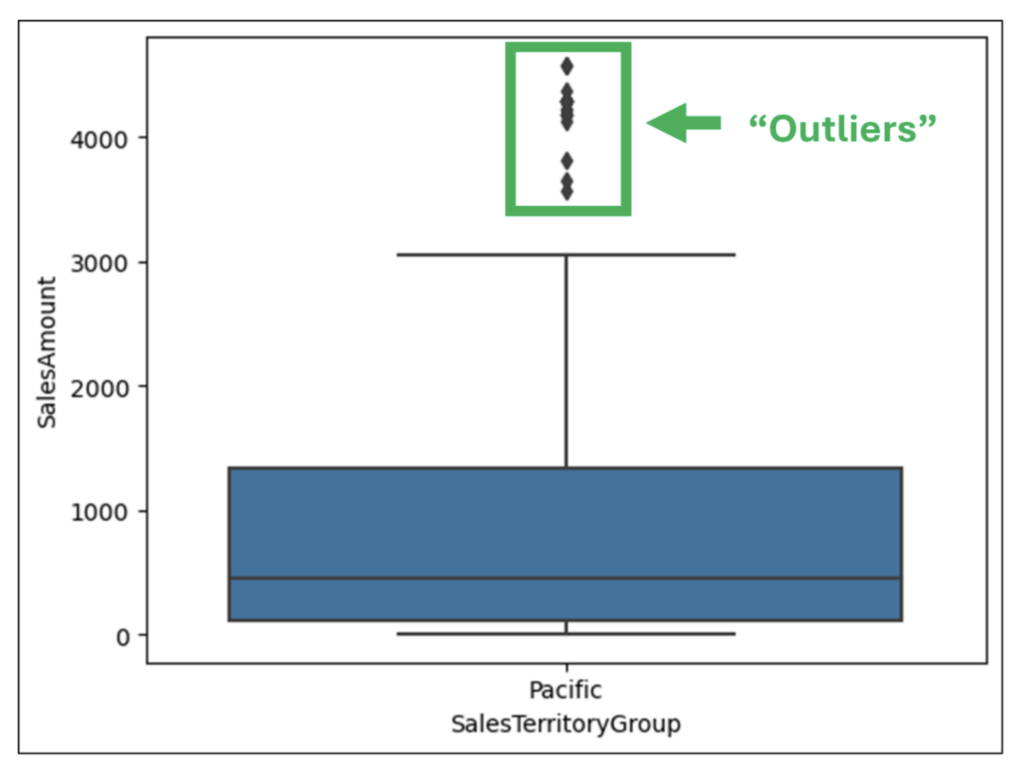
ボックスプロットでは、標準化された計算を使用してひげの長さを決定します (詳細は以下を参照)。ひげの外側にある値は「外れ値」と呼ばれます。
図 15 を調べると、SalesAmounts の外れ値に関する洞察が得られます。
- 大きな SalesAmounts の外れ値が多い
- 小さな SalesAmounts には外れ値がない
これらの外れ値をさらに分析し、関連するデータのパターンを理解する必要があります。以下に例を示します。
- 外れ値の SalesAmounts は少数の大口顧客で発生しているのか?
- 外れ値の SalesAmounts は長期的に一貫しているのか?
上記のような分析の多くは、ヒストグラムを検証することによっても可能ですが、後述するように、ボックスプロットには外れ値以上の分析機能があります。
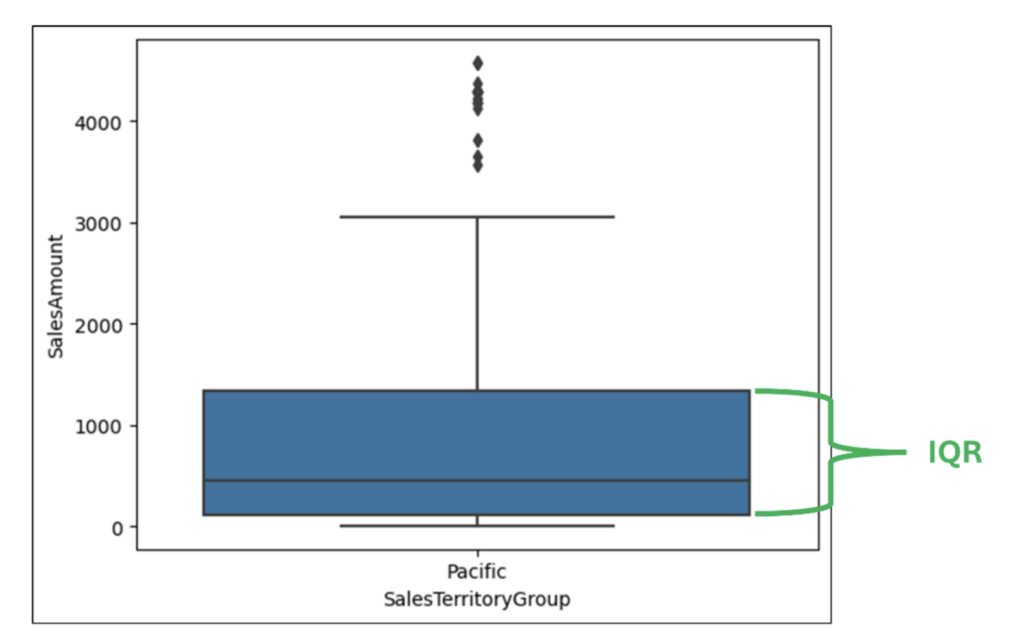
外れ値の計算
ボックスプロットのヒゲの長さを決定する方法は多数ありますが、以下では最も一般的な計算について説明します。
ボックスプロットのヒゲを作成する際に最初に使用する計算は、四分位範囲 (IQR) です。ボックスプロットの場合、IQR は第 3 四分位と第 1 四分位の差 (つまり、ボックスの高さ) です。
上部のひげの計算には、次のロジックを使用します。
- データの最大値または…
- 75 パーセンタイル + (1.5 * IQR)…
- どちらか小さいほう
下部のひげの計算には、次のロジックを使用します。
- 最小値または…
- 25 パーセンタイル + (1.5 * IQR)…
- どちらか大きいほう
長期間のボックスプロット
ボックスプロットを使用してデータを分析する場合、時間に関連する分析の質問を生成するのが一般的です。たとえば、SalesAmount 値の分布は年ごとに変化しているのか? などです。
これは、ボックスプロットがヒストグラムよりも優れている領域です。時間 (年など) をカテゴリとして考えることができます。
次のコードは、reseller_sales DataFrame に OrderYear 列を追加し、新しい列を使用して OrderYear 別の SalesAmounts のボックスプロットを作成します。
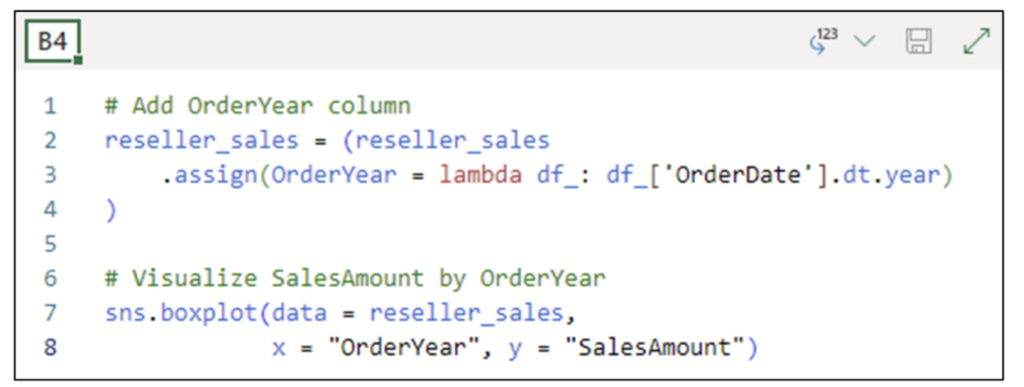
注: 図 17 は、[Convert to Excel values] オプションで構成されたコード セルを示しています。
図 17 に示すコードを実行すると、ワークシート セル内にボックスプロットが表示されます。
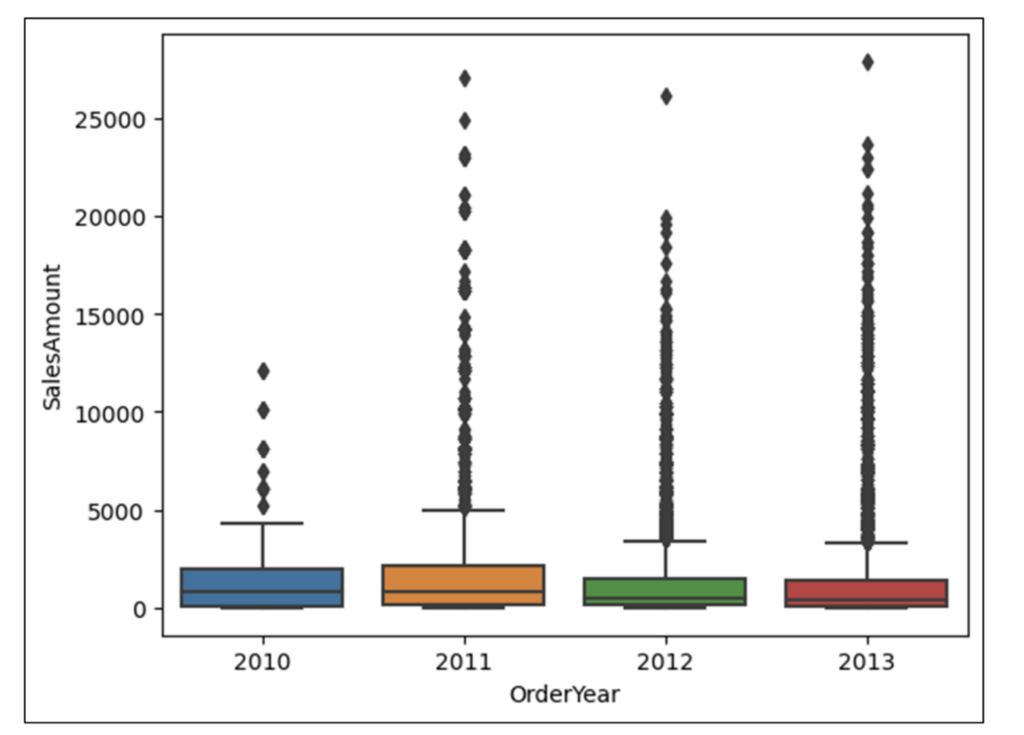
図 18 のボックスプロットを調べると、興味深い洞察が得られます。
- 2012/2013 年のボックスの高さは、2010/2011 年のボックスの高さよりも低くなっています。これは、後年のほうが SalesAmounts の分布がより小さく偏っていることを示しています。
- 2012/2013 年の上部のヒゲは、2010/2011 年のヒゲよりも短くなっています。これも、後年のほうが SalesAmounts がより小さく偏っていることを示しています。
- 後年のほうが、外れ値が大きい SalesAmount 値が多くなっているようです。
図 18 のボックスプロットから、さらに詳しい洞察を得るためには、追加の分析 (上記の質問など) が必要であることが確認できます。
次にすべきこと
この記事では、カテゴリと時間を分析に組み込むなど、ボックスプロットを使用して数値データを分析する方法を説明しました。
このシリーズの次の記事では、散布図を使用して 2 つの数値列の関係を調べることで、この分析シナリオを継続します。
次回まで、楽しいデータ調査を続けてください!
2024 © Anaconda Inc.
「Visual Data Analysis with Python in Excel: Using Boxplots」
