この記事は、Microsoft Excel で Python を使ってデータを視覚的に分析する方法を紹介するシリーズのパート 5 です。
Python in Excel を初めて使用する場合は、このシリーズで想定している多くの概念について説明した「Excel アナリスト向け Python」シリーズから始めることをお勧めします。
このシリーズでは、コードの記述に Microsoft Excel Labs Python Editor を使用します。ただし、Python Editor は必須ではありません。すべてのコードは、数式バーと新しい PY() 関数を使用して入力できます。
このシリーズの各記事には、Microsoft Excel のワークブックが用意されています。パート 5 のワークブックは、こちらからダウンロードできます。
このシリーズは、以下の 5 つのパートで構成されます。
- パート 1 – ヒストグラムの使用
- パート 2 – ボックスプロットの使用
- パート 3 – 散布図の使用
- パート 4 – 棒グラフの使用
- パート 5 – 折れ線グラフの使用 (この記事)
注: この記事で紹介する例を実際に試す場合は、Python in Excel の体験版をインストールしてください。このブログ シリーズが気に入った方は、自己学習型認定プログラム「Anaconda 認定: Python in Excel を使用したデータ分析」もぜひチェックしてみてください。
分析シナリオ
この記事では、パート 3 と 4 で使用したプロモーション戦略の効果を分析するシナリオを引き続き使用します。
この記事のワークブックには、次の月次売上データ テーブルが含まれています。
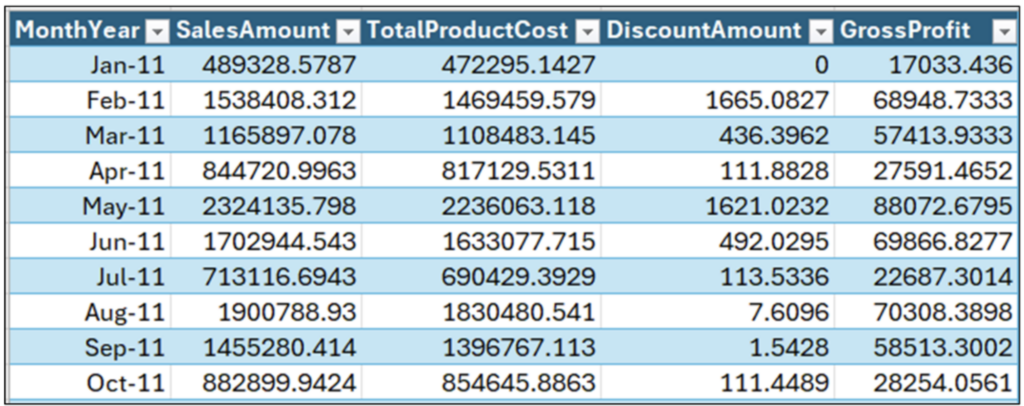
図 1 のテーブルは、ビジネス分析で非常に一般的なシナリオである、経時的なビジネス プロセスのパフォーマンス分析 (時系列分析) を示しています。
時系列分析では、視覚化によく折れ線グラフを使用します。
折れ線グラフの導入
時系列分析では、経時的な測定値の挙動を調べます。時系列分析を実行すると、次の 5 つのパターンから重要な洞察が得られます。
- 傾向 – 期間中に一連の値が増加、減少、または比較的安定しているなどの全体的な傾向。
- 変動性 – 経時的なデータ ポイント間の変化。
- サイクル – 定期的に繰り返されるパターン (例: 時間ごと、週ごと、月ごと)。
- 変化率 – 時系列内のデータ ポイント間のパーセンテージ差。
- 例外 – 特定の時系列の典型的な範囲外にある値。
Python seaborn ライブラリを使用すると、折れ線グラフを簡単に作成できます。必要なのは数行のコードだけです。
データの分析に必要な seaborn 折れ線グラフを作成するには、図 1 に示す Excel テーブルを pandas DataFrame として読み込む必要があります。

注: 上記の Python コードは Excel Labs Python Editor を使用して記述されていますが、これは必須ではありません。
Python Editor のディスク アイコンをクリックすると、コードが実行されます。

最初の折れ線グラフ
分析の開始点として、経時的な SalesAmounts (販売額) の推移を理解することは理にかなっています。次の Python コードは、seaborn ライブラリを使用して折れ線グラフを作成します。
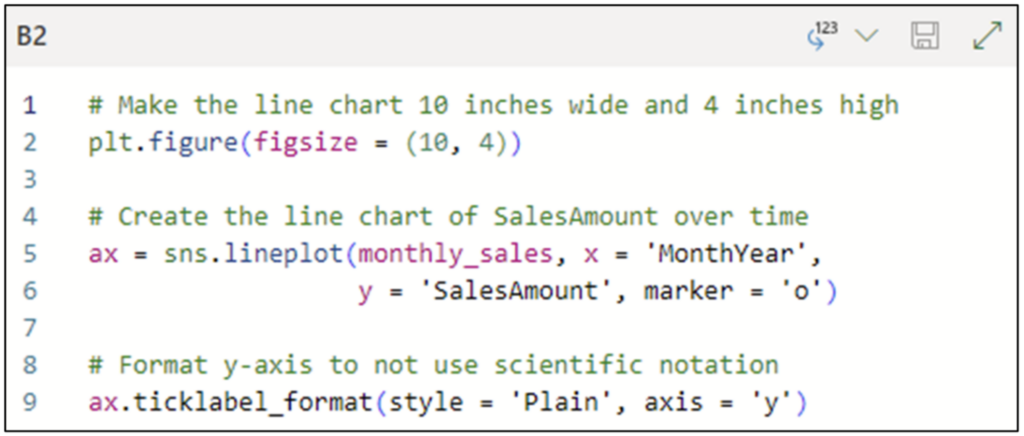
以下は、図 4 のコードの説明です。
- 折れ線グラフは高さよりも幅が広いため、2 行目で pyplot ライブラリの figure() 関数を利用して、折れ線グラフのサイズを 10 x 4 インチに設定しています。
- 5 行目の seaborn lineplot() 関数は折れ線グラフを作成します。折れ線グラフは次のように構成されています。
- monthly_sales DataFrame はデータ ソースです。
- x 軸は MonthYear (年月) 列です。
- y 軸は SalesAmount 列です
- marker パラメーターは、折れ線グラフ上に各 SalesAmount 値を表すポイントを追加します。
- デフォルトでは、seaborn は大きな値に対して科学的記数法を使用します。9 行目の ticklabel_format() 関数は、グラフでプレーンな数値を使用するように強制します。
コード セルを [Excel 値に変換] オプションで構成すると、折れ線グラフがワークシート セルに直接表示されます。
Python Code Editor でディスク アイコンをクリックすると、コードが実行され、次の折れ線グラフが生成されます。
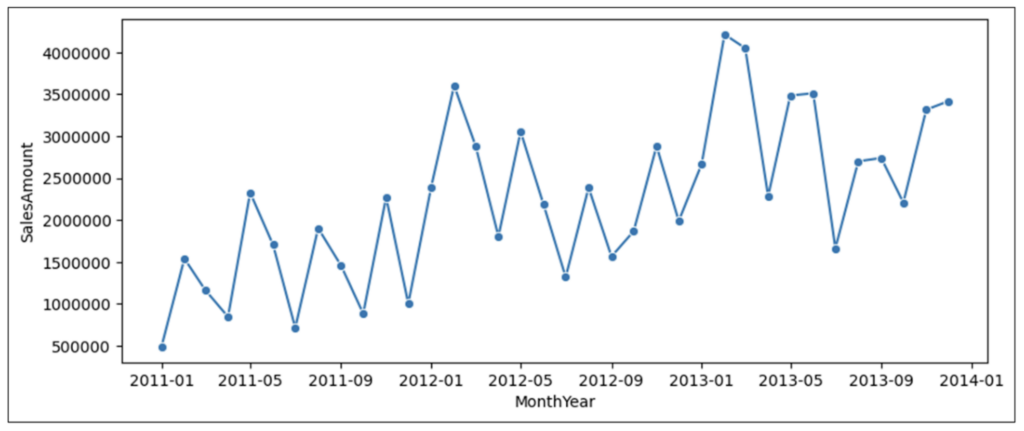
前述の 5 つの時系列分析パターンを図 6 に適用してみましょう。
- 傾向 – 全体的に、売上は 3 年間にわたって上昇傾向にあります。
- 変動性 – 時系列にはかなりの変動性が見られます (多くの上下があります)。
- サイクル – データには 1 つのサイクルが存在し、2011 年 12 月と 2012 年の 12 月に下落し、その翌月 (2012 年 1 月と 2013 年の 1 月) に急上昇したことを示しています。
- 変化率 – データ ポイント間のパーセンテージ差は大きく異なり、変動性によって売上が大きく増減していることがわかります。
- 例外 – 2013 年 2 月/3 月の売上は例外的に高い値である可能性があります。
注: 時系列内の例外的な値の可能性に関して、プロセス動向チャートは、過去のパフォーマンスに基づいて時系列内の値が真に例外的であるかどうかを判断する強力な方法を提供します。
経時的な割引額の推移
monthly_sales の DiscountAmount (割引額) 列は、1 か月間の割引額の合計を表します。次のコードは、DiscountAmount の折れ線グラフを作成します。
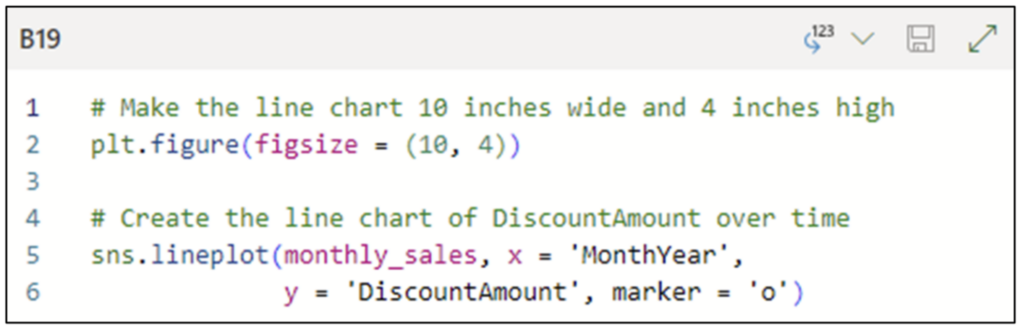
図 7 のコード セルを [Convert to Excel values] オプションで実行すると、次の折れ線グラフが生成されます。
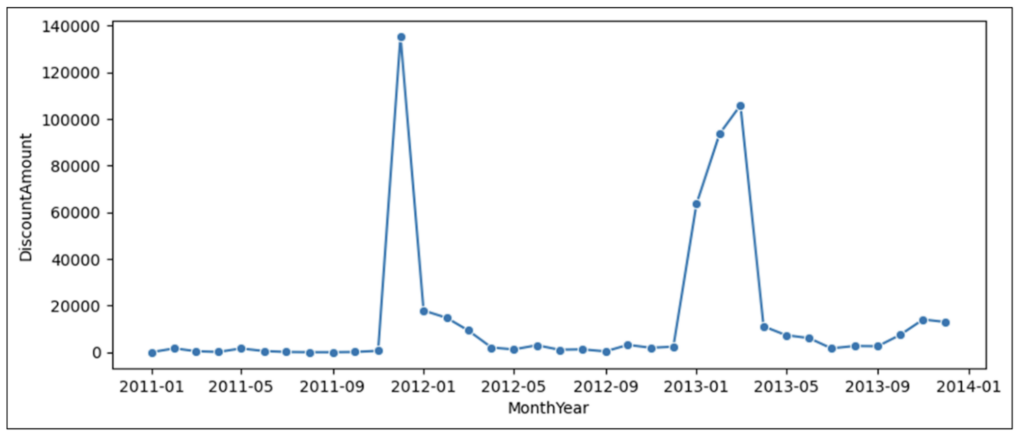
再度、前述の 5 つの時系列分析パターンを図 8 に適用してみましょう。
- 傾向 – 全体的に、3 年間の割引額には強い傾向はありません。
- 変動性 – 時系列には、極端な変動性 (2 つの急上昇など) の領域がいくつかあります。
- サイクル – 時系列には、識別可能なサイクルはありません。
- 変化率 – 2 つの急上昇を除き、全体的な変化率は小さいです。
- 例外 – 2012 年 12 月と 2013 年 1 ~ 3 月に計 4 つの例外的なデータ ポイントがあります。
図 8 の折れ線グラフを分析すると、経時的なプロモーションの動向に関する情報が得られます。図に示されている 3 年間の期間中、一貫したプロモーション戦略は存在しないようです。
複数の時系列分析
上記の折れ線グラフから、時系列分析が非常に便利な手法であることは明らかです。折れ線グラフでできることは他にもたくさんあります。
同じグラフで複数の時系列を視覚化すると、多くの場合、データ内の階層化されたパターンを認識できるようになります。pandas を使用することで、複数系列の折れ線グラフを簡単に作成できます。
データの準備
最初に、既存の monthly_sales DataFrame を「Wide」形式から「Long」形式に変換します。Wide 形式とは、monthly_sales のカードのように、時系列ごとに列が存在する場合です。
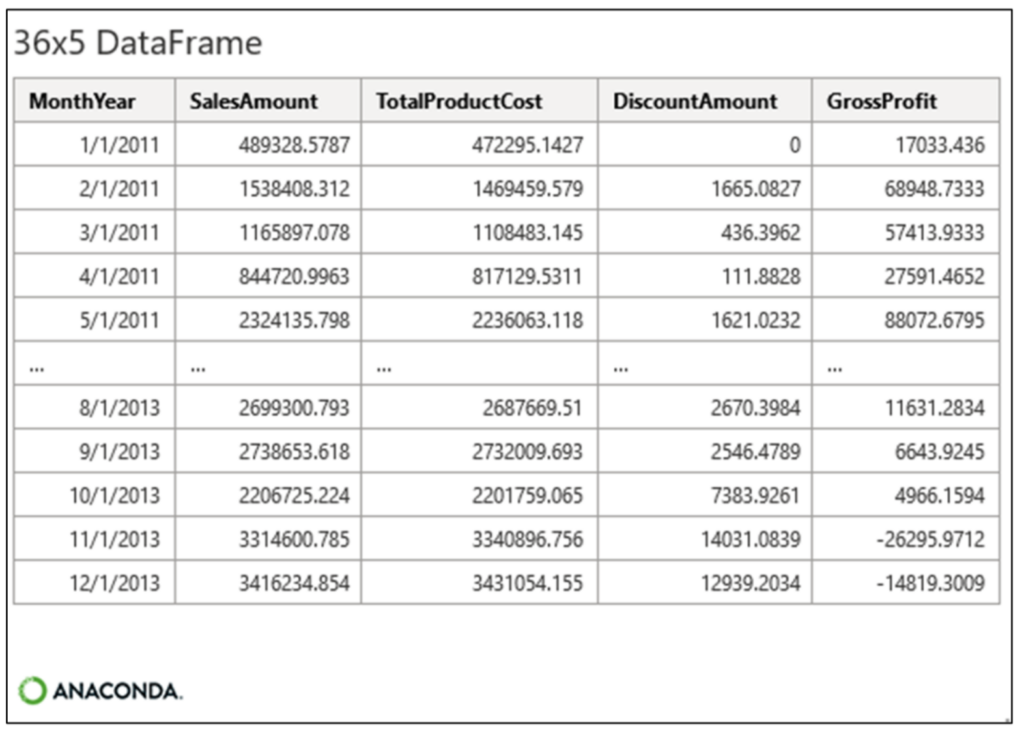
Long 形式の DataFrame には次の 3 つの列があります。
- すべての時系列で共有される日付値の列 (図 9 の MonthYear 列など)。
- 行がどの時系列に属しているかを示す値を含む列 (例: SalesAmount や TotalProductCost (総製品コスト) など)。
- 時系列値を含む列 (例: 17033.436)。
DataFrame を Wide 形式から Long 形式に変換する最も簡単な方法は、DataFrame の melt() メソッドを使用することです。次のコードは、monthly_sales から sales_melted DataFrame を作成します。
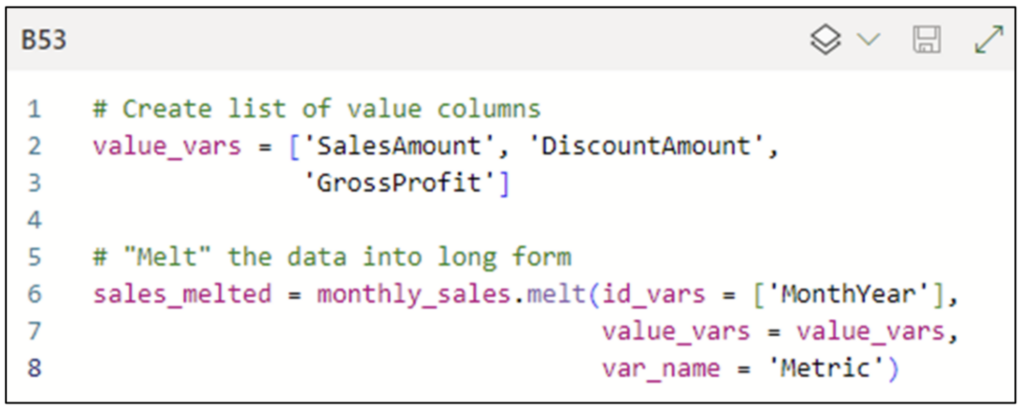
注: 図 10 のコード セルは、[Python object] 出力オプションを使用して実行されます。
以下は、図 10 のコードの説明です。
- 2 行目は、melt する時系列値の列名の Python リストを作成します (たとえば、TotalProductCost 列は含まれません)。
- 6 行目は、monthly_sales で melt() を呼び出して、sales_melted DataFrame を作成します。
- id_vars パラメーターは、すべての時系列で共有される日付を MonthYear 列を使用して提供することを指定します。
- value_vars パラメーターは、melt する時系列を指定します。
- var_name パラメーターは、時系列名を保持する列のカスタム名を指定します。
図 10 のコードを実行後に Excel の sales_melted カードを確認すると、上記のコードが理解しやすいでしょう。
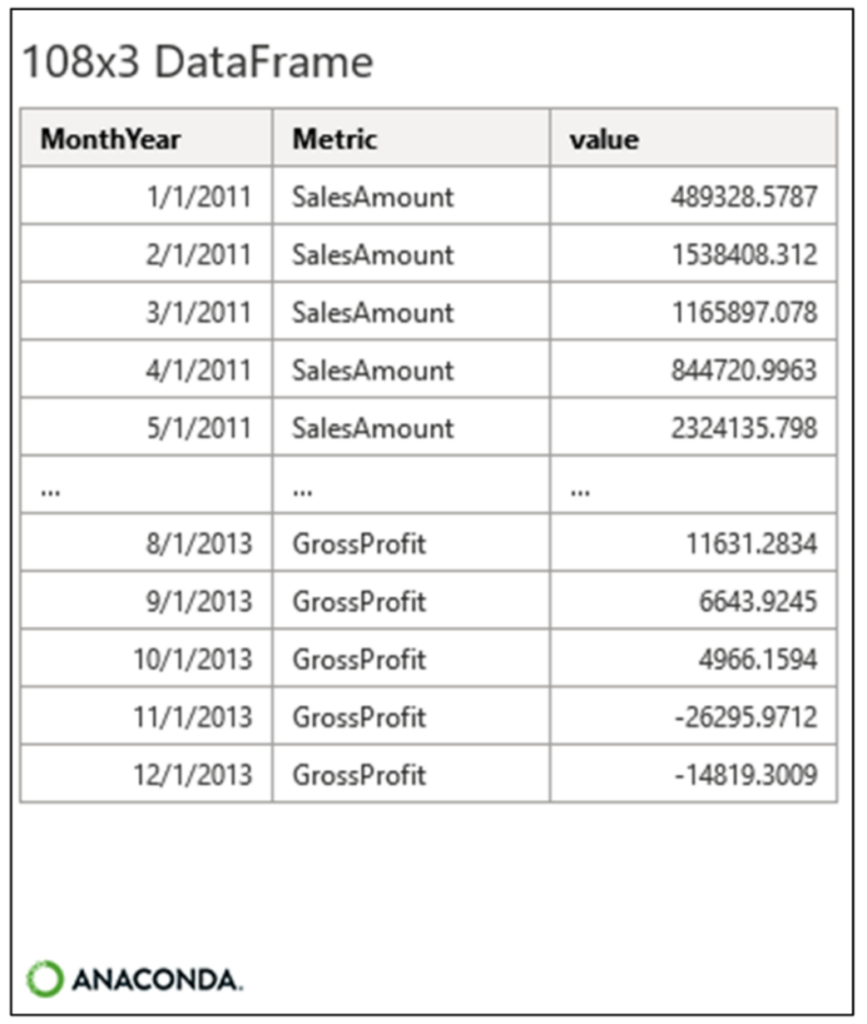
図 11 から sales_melted には 108 行あることがわかります。これを、図 9 の 36 行の monthly_sales DataFrame と比較してみましょう。
行数の違いは、sales_melted には 3 つの時系列があり、それぞれに 36 個の値があるためです (3 × 36 = 108)。
sales_melted DataFrame が作成されたので、折れ線グラフを生成します。
複数系列の折れ線グラフ
次のコードは、複数系列の折れ線グラフを作成します。
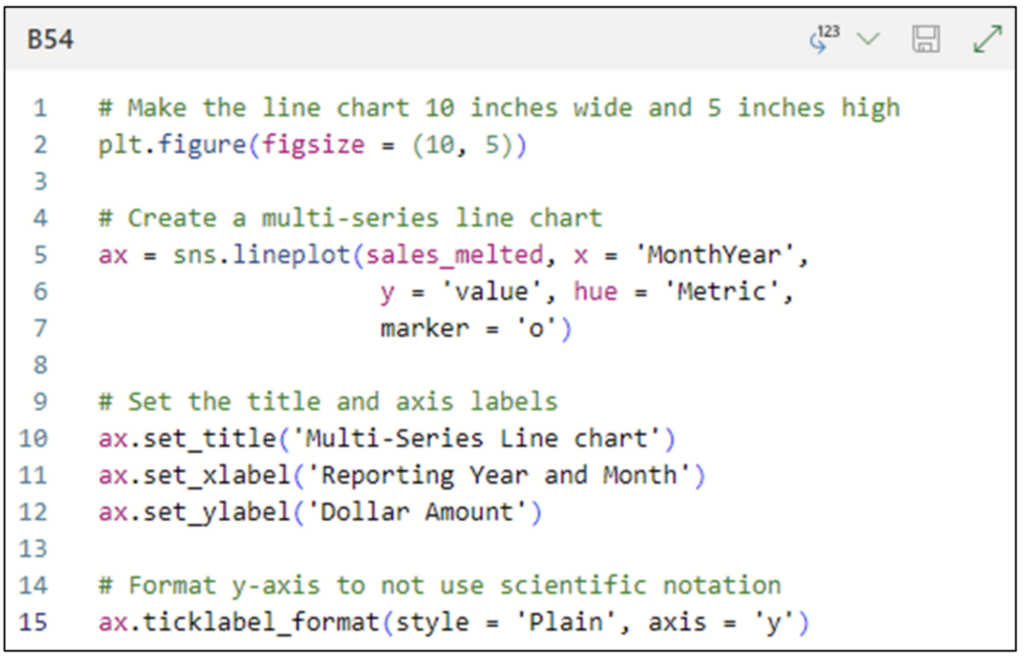
図 12 に示すコードは前のコードと似ていますが、注意すべき点がいくつかあります。
- 5 行目で sales_melted DataFrame をデータ ソースとして使用し、折れ線グラフを次のように構成しています。
- y 軸は、melt() の呼び出しによって作成された value 列にマッピングされます。
- hue パラメーターは、melt() の呼び出しによって作成された Metric 列にマッピングされます。これにより、Metric の一意の値ごとにグラフに線が作成されます。
- 10 ~ 12 行目では、set_title()、set_xlabel()、および set_ylabel() 関数を使用して、折れ線グラフのタイトルと軸ラベルをカスタム値に設定します。
コード セルを [Convert to Excel values] オプションで実行すると、次の折れ線グラフが生成されます。
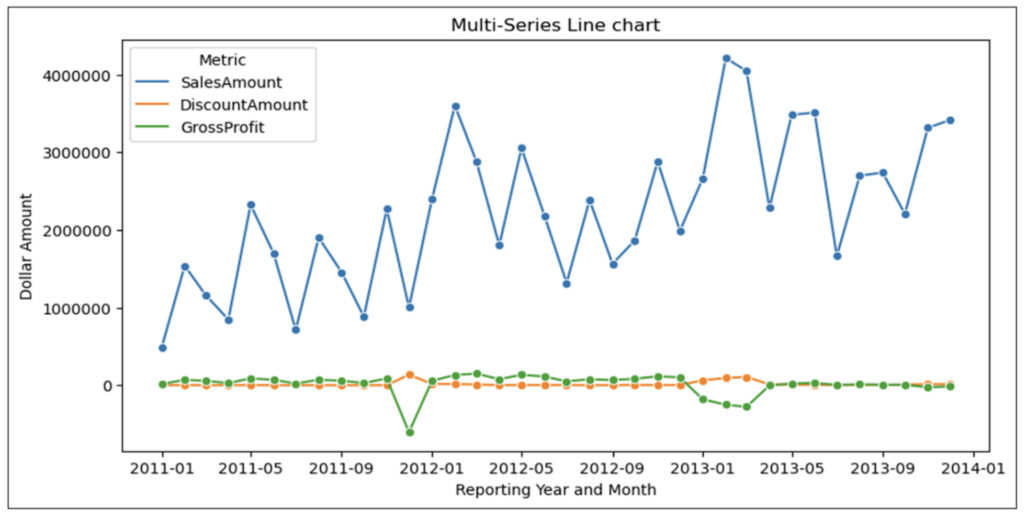
5 つの時系列パターンを図 13 に適用して、グラフを調べると次のことがわかります。
- 興味深いことに、SalesAmount は上昇傾向を示していますが、GrossProfit (粗利益) は比較的横ばいのようです。
- DiscountAmount が高い月は GrossProfit がマイナスになっています。これは非常に興味深い関連性であり、割引が損失の原因になっているかどうかを理解するには追加の分析が必要です。
- 全体的に、売上はプロモーション戦略とは無関係のようです。
- 2013 年 2 月/3 月は SalesAmount が高く、DiscountAmount も高いです。この関連性についても、理解するには追加の分析が必要です。
図 13 に示すような折れ線グラフは、ビジネス分析の早期警告システムであることがよくあります。
たとえば、折れ線グラフは、エグゼクティブ ダッシュボードなど、データ視覚化にもよく使用されます。よくあるシナリオは、上層部が折れ線グラフで「問題 (あるいはその予兆)」を見つけ、それを説明するために分析の実施を要求することです。
このブログ シリーズで取り上げた分析手法は、これらの説明を作成する際によく使用されます。
次にすべきこと
この記事では、折れ線グラフを使用して、ビジネス分析における最も基本的なスキルの 1 つである、経時的なビジネス メトリックのパターンを認識する方法を示しました。
折れ線グラフは、主要業績評価指標 (KPI) の分析に特に効果的です。上層部に説得力のあるデータを示したい場合、KPI 分析は強力なツールです。
seaborn ライブラリを使用してデータを視覚化する方法について詳しく知りたい場合は、「seaborn について」を確認してください。
今後も楽しいデータ調査を続けてください!
2024 © Anaconda Inc.
「Visual Data Analysis with Python in Excel: Using Line Charts」
