長年にわたり、Excel はマーケティング担当者やアナリストにとって頼りになるツールであり、データの整理やレポートの生成に強力な機能を提供してきました。しかし、より高度なデータ分析タスクとなると、Excel だけでは不十分であり、多くの場合、サードパーティのアドインや全く異なるプラットフォームが必要になります。
Python in Excel を統合することで、この状況を変えることができます。Python の高度なデータ処理機能が使い慣れた Excel インターフェイスに直接組み込まれ、マーケティング担当者やデータ アナリストはシームレスなワークフローで Python を使用して、高度な分析 (顧客セグメンテーション、離反率予測、感情分析) を実行できるようになります。プラットフォームを切り替えたり、データをエクスポート/インポートしたり、使い勝手の悪いアドインに頼る必要はもうありません。Python は Excel に全く新しいレベルの機能をもたらし、これまでは手の届かなかった高度な手法を利用できるようにします。
この記事では、Python in Excel がマーケティング分析をどのように変革できるかについて、実際の例をいくつか紹介します。顧客レビューなどの定性的データの分析から、離反率の予測、クラスタリング アルゴリズムによる顧客のセグメント化まで、これらのツールが実際にどのように機能するかを紹介します。Python の強力なライブラリを活用することで、マーケティング担当者はより深い洞察を得て、データに基づく意思決定を行い、最終的には、使い慣れたツールからより良いビジネス成果を達成できます。
Python in Excel を使用するには、「=PY(」と入力するだけです。開き括弧を入力するとすぐに、Excel 内に Python エディターが表示されます。この統合エディターを使用して、簡単にセルを選択し、Python 関数をデータに直接適用し、従来の Anaconda 環境と同じように Python パッケージにアクセスできます。データ操作に pandas、視覚化に Matplotlib を利用している場合も、またはその他の Python ライブラリを利用している場合も、このエディターは Python のパワーを Excel ワークフローでフル活用できるようにします。
Python in Excel を使用した定性的データの分析
Python in Excel の統合により、マーケティング担当者やデータ アナリストは、単に数値を処理したりモデルを作成するだけでなく、より広範なタスクに取り組めるようになりました。たとえば、何百ものレビューを収集するレストランのマーケティング担当者を想像してみてください。好意的なレビューもあれば、批判的なレビューもありますが、いずれにも貴重なフィードバックが含まれています。従来は、これらのレビューを手作業で精査して共通のテーマや単語を見つける必要がありましたが、現在は、このような非構造化データの分析を自動化してプロセスを効率化することができます。
Python でレストランのレビューを視覚化
架空のレストランのレビューを使った例を見てみましょう。自由形式のコメントから洞察を得る効果的な方法の 1 つは、ワード クラウドを作成することです。ワード クラウドは、最も頻繁に言及される単語を視覚的に強調表示することで、主要なテーマを簡単に特定できるようにします。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(" ".join(xl("Table1[#All]",headers=True)['Comments']))
# matplotlib を使用してワード クラウドを表示
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off") # Hide the axes
plt.show()この例では、Python in Excel のテーブル全体を扱う能力を活用することで、組み込みの wordcloud パッケージと視覚化用の matplotlib を組み合わせて、レビューからワード クラウドを簡単に生成できます。これにより、料理の品質、雰囲気、サービスなど、顧客が最も話題にしていることが一目でわかります。

この方法は、時間の節約になるだけでなく、定性的データのパターンをより客観的に把握できるようにします。サードパーティのアドインや他の回避策を探す必要はもうありません。誰でも Excel から直接これらの強力なツールにアクセスできます。

顧客離反率の分析
マーケティング担当者にとってもう 1 つの価値あるユースケースは、顧客離反率の分析です。つまり、どのくらいの頻度で、顧客が離脱、サブスクリプションのキャンセル、または製品の放棄をしているかを理解することです。SaaS 製品では、離反分析を行うことで、顧客の意思決定に影響する要因を明らかにし、最終的に顧客維持率の向上に役立てることができます。
SaaS 製品の架空のデータセットを使った例を見てみましょう。Python in Excel では、ロジスティック回帰などの統計手法を使用して、どの変数が離反に影響しているかを特定できます。たとえば、サブスクリプションの価格がユーザーを遠ざけているのかもしれませんし、ユーザーが受けたカスタマー サポートのレベルが原因かもしれません。これらの要因を調査することで、顧客を維持するより効果的な戦略を立てることができます。
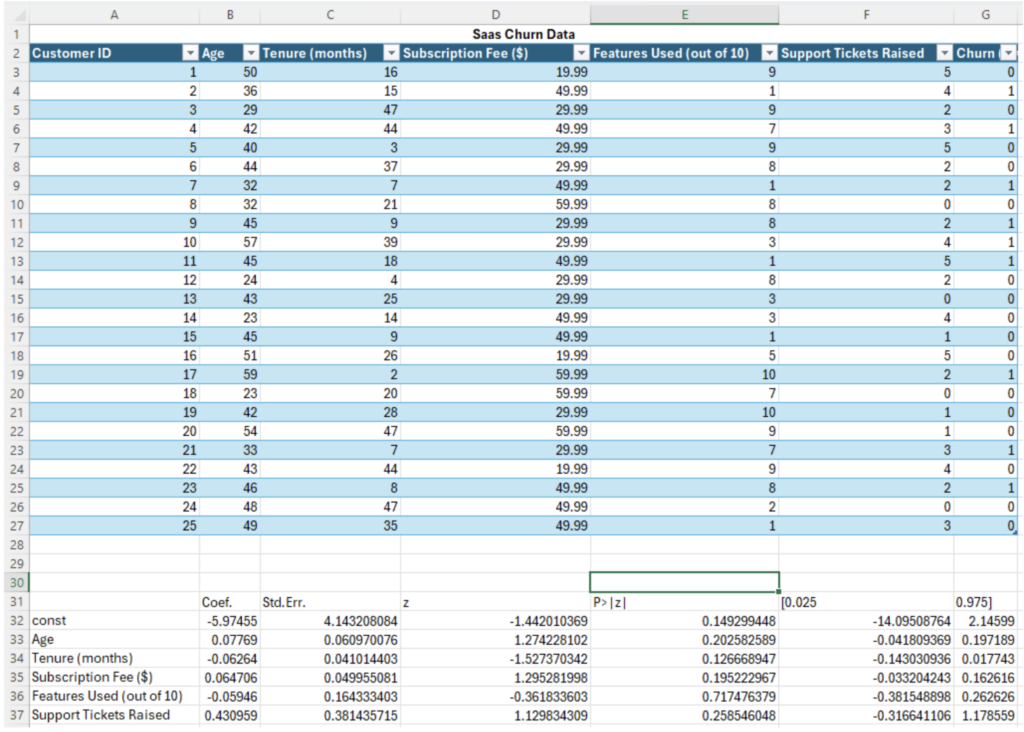
この例では、Excel 内でロジスティック回帰モデルを実行するのに最適な Python の statsmodels パッケージを使用します。ロジスティック回帰は、顧客の製品使用期間、使用している機能の数、発行したサポート チケットの数など、いくつかの要因に基づいて顧客が解約する可能性を予測するのに役立ちます。目標は、どの変数が解約の強力な予測因子であるかを特定し、積極的な対策を講じることです。
import pandas as pd
import statsmodels.api as sm
# DataFrame に変換
df = pd.DataFrame(xl("Table13[#All]", headers=True))
# 従属変数 (解約) と独立変数 (年齢、使用期間、サブスクリプション料金、使用した機能、発行されたサポート チケット数) を定義
X = df[['Age', 'Tenure (months)', 'Subscription Fee ($)', 'Features Used (out of 10)', 'Support Tickets Raised']]
y = df['Churn (1 = Yes, 0 = No)']
# インターセプトに定数項を追加
X = sm.add_constant(X)
# ロジスティック回帰モデルを適合
logit_model = sm.Logit(y, X).fit()
# 回帰結果を取得
logit_model.summary2().tables[1]結果は右側の表示パネル、または Excel セルに表示できます。ロジスティック回帰モデルの結果を使用して、解約を減らす方法についてデータに基づいた決定を下すことができます。たとえば、モデルによって、サブスクリプション料金が高い顧客は解約する可能性が高いことが示された場合、価格帯を調整したり、追加の特典の提供を検討できます。発行されたサポート チケットの数が重要な要因である場合は、顧客サービスを改善することで維持率が向上する可能性があります。
これらの分析を Excel で直接実行することで、Python の高度な機能を活用しながら、Excel に慣れているチームと簡単に共同作業を行うことができます。
クラスタリングを使用した顧客セグメンテーション
マーケティング担当者にとって最も強力なツールの 1 つは、顧客セグメンテーションです。顧客を行動や好みに基づいて明確なグループに分けることで、企業はターゲットを絞ったマーケティング戦略を作成し、パーソナライズされたプロモーションを提供し、顧客維持率を向上させることができます。Excel だけでは複雑なクラスタリング アルゴリズムを処理できないため、従来、顧客セグメンテーションには外部ソフトウェアやアドインが必要でした。しかし、Python in Excel の統合のより、マーケティング担当者は K 平均法クラスタリングなどの高度な手法をスプレッドシート内で直接活用できるようになります。
from sklearn.cluster import KMeans
import pandas as pd
# Excel からデータをロード
df = pd.DataFrame(xl("Table5[#All]", headers=True))
# クラスタリングの機能を定義
X = df[['Age', 'Annual Spend ($)', 'Products Purchased']]
# K 平均法クラスタリング モデルを適用
kmeans = KMeans(n_clusters=3)
df['Cluster'] = kmeans.fit_predict(X)
df.head()クラスタリングにより、企業は年齢、年間支出、購入習慣などの主要な特性に基づいて顧客を自動的にグループ化できます。この例では、架空の顧客データセットに K 平均法クラスタリングを適用して、一目ではわかりづらいパターンを明らかにします。アルゴリズムは、顧客を 3 つのグループまたはクラスターに編成します。各グループは固有のセグメントを表します。たとえば、あるグループは支出が少なく、購入する製品が少ない若年層の顧客で構成され、別のグループは支出が多く、さまざまな製品を購入するより年齢層の高い顧客で構成されているかもしれません。これらのセグメントを識別することで、企業はマーケティング活動をより効果的に調整できます。
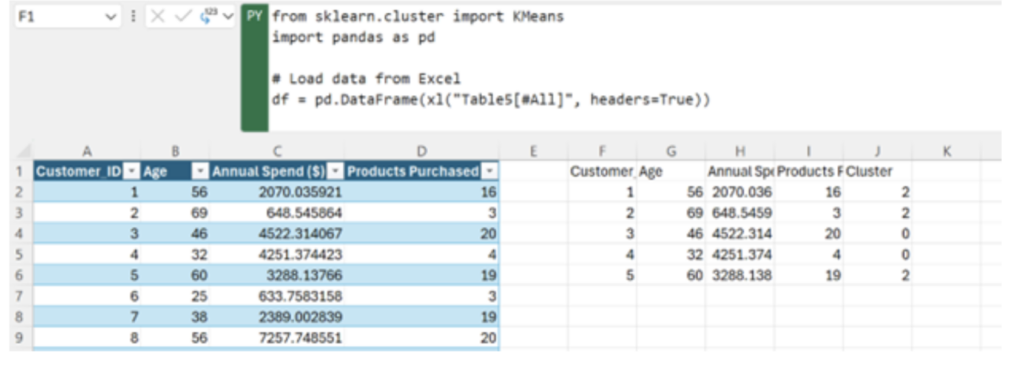
これまでは、サードパーティのツールを使用したり、Python や R などの外部ソフトウェアにデータをエクスポートしない限り、Excel 内でこのようなセグメンテーションを実現するのは困難、あるいは不可能でした。基本的なフィルターとピボット テーブルを使用したデータ分析では、過度に単純化された洞察がもたらされる可能性があります。Python in Excel は、K 平均法クラスタリングなどの高度なアルゴリズムをすぐに利用できるようにし、シームレスなワークフローを実現します。データは Excel 内に保持され、面倒な作業と複雑な計算は Python が処理してくれます。クラスターを視覚化して、顧客と共有することもできます。
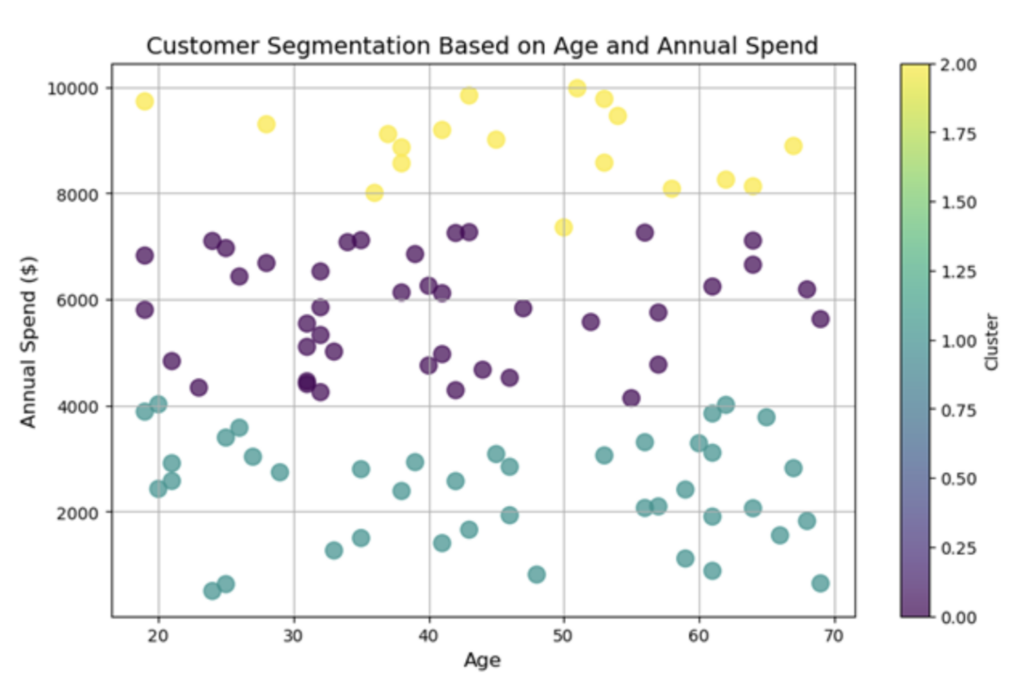
主要なグループを特定することで、企業は特定のオーディエンスに響くマーケティング キャンペーンをパーソナライズして展開し、最終的にエンゲージメントと顧客ロイヤルティを高めることができます。
まとめ
顧客行動の分析、予測モデルの実行、オーディエンスのセグメント化など、どのような作業にも Python の豊富なツール ライブラリが Excel 環境で利用できるようになりました。これにより、使い慣れたインターフェイスを離れることなく、マーケティング分析の従来の限界を超えることができます。
つまり、Python in Excel は単なる追加機能ではなく、マーケティング データ分析を向上させる手段です。複雑なタスクを簡単に処理し、データ主導の環境で一歩先を行き、よりスマートでインパクトのあるマーケティング意思決定を可能にします。マーケティングの世界が進化するにつれて、この統合は、Excel が強力で適応力の高いマーケティング ツールであり続け、より深い洞察を解き放ち、より優れた結果を導き出すようにします。
これらの例を Python と Excel で直接試したい場合は、この記事で使用されているスプレッドシートをこちからダウンロードできます。
2024 © Anaconda Inc. 「Python in Excel for Marketing」
