
はじめに
Apryse SDK は長年にわたり PDF から HTML/EPUB への変換をサポートしています。この記事では、作成元の PDF と同じ固定レイアウトの HTML ページのセットを作成する方法を説明します。
Apryse を使用して PDF から HTML に変換する方法は他にもあります。たとえば、構造化出力モジュールを使用して、PDF と同じ内容の HTML ページを作成し、テキストをリフローすることができます (これにより、特に PDF に複数のテキスト列が含まれている場合に、内容が読みやすくなります)。ただし、これらの他のオプションについては、この記事では説明しません。
Apryse SDK とは?
Apryse SDK は PDF やその他の多くの種類のドキュメントを操作する際に幅広い機能にアクセスできるソフトウェア ライブラリです。ファイルの変換、編集、編集、暗号化、その他多くの操作をサポートしています。
macOS、Windows、Linux のいずれをご利用でも、Apryse SDK は、お使いのプラットフォームで、.NET と .NET Core の両方に対応した C/C++、Java、Objective-C、Go、Node.js、Python、Ruby、PHP、VB、C# などのさまざまなプログラミング言語でご利用いただけます。
この記事では、Windows プラットフォーム上の C# と .NET Core について説明します。これが実際の使用方法ではない場合でも、API は十分に一貫性があるため、簡単に別の言語に翻訳できます。
アクション プラン
この記事を読み終える頃には、PDF を HTML ページのセットに変換できるコマンド ライン アプリケーションが完成しているはずです。さらに興味深いものにするために、いくつかの追加要件を追加します。
- 奇数ページのみを変換
- 画像のサイズを 3 メガピクセル (MP) に制限
- 高画質 (DPI)
- JPG の代わりに PNG を使用
- ドキュメント外部の URL への HTML ハイパーリンクを許可しない
前提条件
Visual Studio と .NET Core がインストールされている必要があります。この記事では Visual Studio 2022 と .NET Core 6.0 を使用しますが、他の最新のバージョンの Visual Studio と .NET Core でも同じ結果が得られるはずです。
これらをまだインストールしていない場合、https://visualstudio.microsoft.com/ にアクセスしてください。
Apryse SDK を使い始める
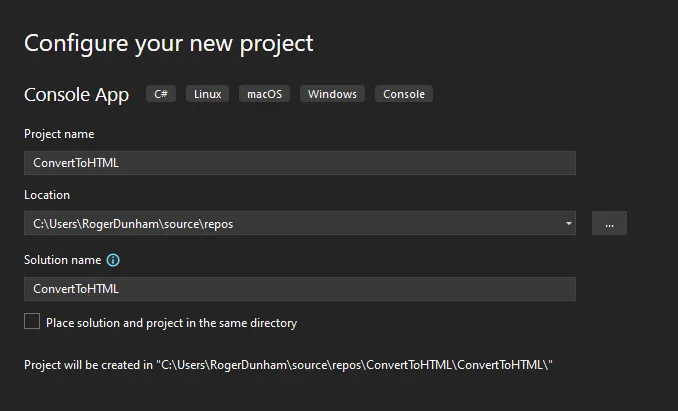
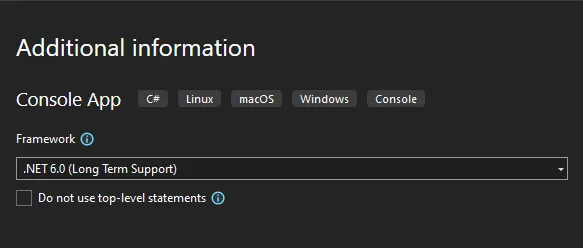
ステップ 1: Visual Studioで新しいプロジェクトを作成
Visual Studio で、 ConvertToHTML という新しいコンソール アプリを作成し、.NET Core 6.0 (または任意の代替バージョン) を対象にします。
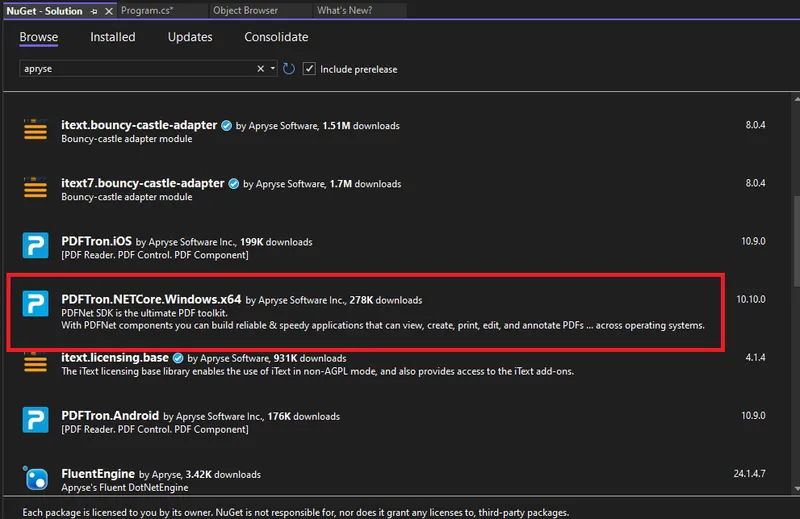
ステップ 2: NuGetパッケージマネージャー経由で Apryse SDK を追加
次に、Apryse SDK への依存関係を追加します。これを行うにはいくつかの方法がありますが、NuGet は最も簡単な方法の 1 つです。Apryse は以前は PDFTron と呼ばれていましたが、ライブラリの名前は今でもそのままです。「apryse」を検索し、PDFTron.NETCore.Windows.x64 をクリックします。
ステップ 3: プロジェクトにコードをコピー
Visual Studio 内で、プロジェクトの Program.cs ファイルを見つけて、その内容を次のコードに置き換えます。この記事の後半で、このコードがどのように機能するかについて説明します。
using System;
using pdftron;
using pdftron.Common;
using pdftron.PDF;
namespace PDF2HtmlTestCS
{
class Class1
{
private static pdftron.PDFNetLoader pdfNetLoader = pdftron.PDFNetLoader.Instance();
static Class1() { }
// Relative path to the folder containing test files.
const string inputPath = "../../../TestFiles/";
const string outputPath = "../../../TestFiles/";
/// <summary>
/// The main entry point for the application.
/// </summary>
[STAThread]
static int Main(string[] args)
{
// The first step in every application using PDFNet is to initialize the
// library. The library is usually initialized only once, but calling
// Initialize() multiple times is also fine.
PDFNet.Initialize("Your License Key");
bool err = false;
//////////////////////////////////////////////////////////////////////////
try
{
using (PDFDoc doc = new PDFDoc(inputPath + "newsletter.pdf"))
{
doc.InitSecurityHandler();
// remove all even pages
if (doc.GetPageCount() > 1)
{
PageIterator itr = doc.GetPageIterator();
itr.Next(); // skip first page
while (itr.HasNext())
{
doc.PageRemove(itr); // remove even pages
itr.Next();
}
}
pdftron.PDF.Convert.HTMLOutputOptions options = new pdftron.PDF.Convert.HTMLOutputOptions();
options.SetInternalLinks(true);
options.SetExternalLinks(false);
options.SetPreferJPG(false);
options.SetDPI(300);
options.SetMaximumImagePixels(3000000);
options.SetSimplifyText(true);
options.SetScale(2.0);
pdftron.PDF.Convert.ToHtml(doc, outputPath + "newsletter_odd_pages", options);
}
}
catch (PDFNetException e)
{
Console.WriteLine("Unable to convert PDF document to HTML, error: " + e.Message);
err = true;
}
catch (Exception e)
{
Console.WriteLine("Unknown Exception, error: ");
Console.WriteLine(e);
err = true;
}
//////////////////////////////////////////////////////////////////////////
PDFNet.Terminate();
Console.WriteLine("Done.");
return (err == false ? 0 : 1);
}
}
} ステップ 4: フォルダを作成し、変換したいPDFをコピー
ほぼすべての PDF を HTML に変換できますが、この例では、 testFiles というフォルダーに保存した、newsletter.pdf という PDF を使用します。
別のファイルを選択するか、別のフォルダに配置する場合は、新しいファイルの場所に合わせてコードを更新する必要があります。コードが正しいパスとファイル名を使用していることを確認することは、おそらくプロセス全体の中で最も難しい部分です。
ステップ 5: コードを実行
これで準備完了です。
Visual Studio からコードを実行すると、ほんの数分後に、HTML ページのセットを含む新しいフォルダーが作成されます。
これで完了です。新しいフォルダーをクリックして、存在するファイルを確認できます。

これらのファイルのいずれかをクリックします。元の PDF には 15 ページが含まれていましたが、偶数ページを削除したため、.html ファイルは 8 つだけになっていることに注意してください。
それらのファイルをクリックして結果を確認してください。

コードの仕組み
これでコードが動作するようになりました。どのように動作するかを見てみましょう。いくつかの異なる部分があるので、順番にそれぞれ見ていきます。自由に値を変更してみて、結果としてどのような異なる結果が得られるかを確認してください。
PDFNet の初期化と終了
他の作業を行う前に、試用版または商用ライセンス キーを渡して PDFNet を初期化する必要があります。
PDFNet.Initialize("[Your license key]"); PDFNet.Terminate(); ライセンス キーをまだお持ちでない場合は、https://www.apryse.com/pws/get-key から取得できます。
メソッドの最後に、使用したリソースを解放するために PDFNet.Terminate を呼び出します。
PDF を開いて前処理を実行
コードの次の部分では、PDF ドキュメントをメモリ内オブジェクトとして開きます。
using (PDFDoc doc = new PDFDoc(inputPath + "newsletter.pdf"))
{
doc.InitSecurityHandler();
// remove all even pages
if (doc.GetPageCount() > 1)
{
PageIterator itr = doc.GetPageIterator();
itr.Next(); // skip first page
while (itr.HasNext())
{
doc.PageRemove(itr); // remove even pages
itr.Next();
}
}
// Other code
} この場合、要件の 1 つが奇数ページのみをエクスポートすることであったため、メモリ内のドキュメントは偶数ページを削除することで変更できます。実際、ドキュメント ページに対して、回転、注釈の追加、新しいページの挿入など、要件に合ったさまざまな操作を実行できます。
注: PDFDoc.Save() を呼び出さない限り、行った変更は元のソース ファイルには影響しません。
変換オプションの設定
ハイパーリンクの制御
要件には、ドキュメント外部の URL への HTML ハイパーリンクが存在してはならないことが含まれていました。これは、ユーザーが悪意のあるサイトに移動するリンクをクリックするリスクを防ぐためです。これは、options.SetExternalLinks(false); を呼び出すことで簡単に実現できます。
pdftron.PDF.Convert.HTMLOutputOptions options = new pdftron.PDF.Convert.HTMLOutputOptions();
options.SetInternalLinks(true);
options.SetExternalLinks(false); 一方、ドキュメント内にリンクを保持したい場合は、options.SetInternalLinks(true); を使用します。
画像の品質とサイズの制御
次に、いくつかの画像オプションを設定する必要があります。これは、常に品質と画像サイズの間でトレードオフになります。要件には、最大画像サイズが 3 メガピクセルであること、高画質であること、JPG ではなく PNG を使用することなどが含まれます。これらはすべて次のように制御できます。
pdftron.PDF.Convert.HTMLOutputOptions options = new pdftron.PDF.Convert.HTMLOutputOptions();
options.SetPreferJPG(false);
options.SetDPI(300);
options.SetMaximumImagePixels(3000000); PNG を使用するように明示的に指示することはできませんが、JPG を使用しないように選択することはできます。その場合、PNG 形式が使用されます。
画像品質の指定は、DPI (Dots per Inch) を設定することによって行います。通常、300 DPI の値を設定すると高品質の画像が得られますが、他の値を試して結果がどのように異なるかを確認してください。
最終的な画像要件は、最大画像サイズが 3 メガピクセルであることです。これは、options.SetMaximumImagePixels(3000000); を使用して簡単に実装できます。これにより、指定されたよりも多くのピクセルが画像に含まれる場合、制限 (この場合は 3MP) 内に収まる最高の DPI にダウンサンプリングされます。
明示的な要件ではありませんでしたが、コードにいくつかの追加オプションを含めました。
テキストの最適化
PDF には、それぞれが特定のフォント、サイズ、スタイルを持つ「ラン (run)」と呼ばれる多数の小さなテキストが含まれている場合があります。デフォルトでは、各ランは個別に変換され、元の PDF と非常によく似た結果が生成されます。この方法の欠点は、複雑で大きなドキュメントになることです。
しかし、多くの場合、これらの実行の多くは実際には同じスタイルであるため、それぞれを個別のオブジェクトとして維持しても目に見える利点はほとんどありません。SetSimplifyText を使用すると、SDK に PDF ファイル内のテキスト実行を結合するように指示します。結果の違いは通常、人間の目にはわかりませんが、ダウンロード、レイアウト、およびレンダリングの時間が短縮されます。
options.SetSimplifyText(true); 出力スケールの設定
最後のオプションは、生成されるファイルのスケールを設定することです。
ブラウザには優れたズーム機能がありますが、SetScale オプションを使用すると、ズームしなくてもブラウザで HTML を読みやすくすることができます。
コード サンプルでは、出力を元の PDF の 2 倍のサイズに拡大しています。
options.SetScale(2.0); これらの結果を別の方法で達成
この例では、PDF の前処理 (この場合は奇数ページのみを保持) を実行し、結果のドキュメントを HTML に変換するコマンド ライン ツールを作成しました。
ただし、PDF をそのまま変換するコマンドライン ツールだけが必要な場合は、事前に構築されたツールをご利用いただけます。
DocPub コマンドライン変換ツールは多くの引数をサポートしており、コードで実現したものと同じ出力を提供します (奇数ページを返すこと以外)。
例:
docpub.exe -f html --internal_links --prefer_jpg false --dpi 300 --max_image_pixels 3000000 --simplify_text --scale 2.0 newsletter.pdf さらなる例についてはドキュメントを参照してください。
まとめ
いかがでしたでしょうか。PDF を HTML に変換する場合は、Apryse SDK が役に立つことが良く分かりました。Apryse SDK を使用すると、ファイルの変換方法と内容を正確に制御できます。
Apryse では無償トライアルも提供しています。是非お試しください。
Apryse 製品の詳細は、弊社 Web サイトをご確認ください。
記事参照:
© 2024 Apryse
「Using the Apryse SDK to Convert PDF into HTML」
