| 詳細 |
|
| ターゲット OS: |
Ubuntu* 16.04 LTS |
| プログラミング言語: |
Python* 3.5 |
| 作業時間: |
50~70 分 |
説明
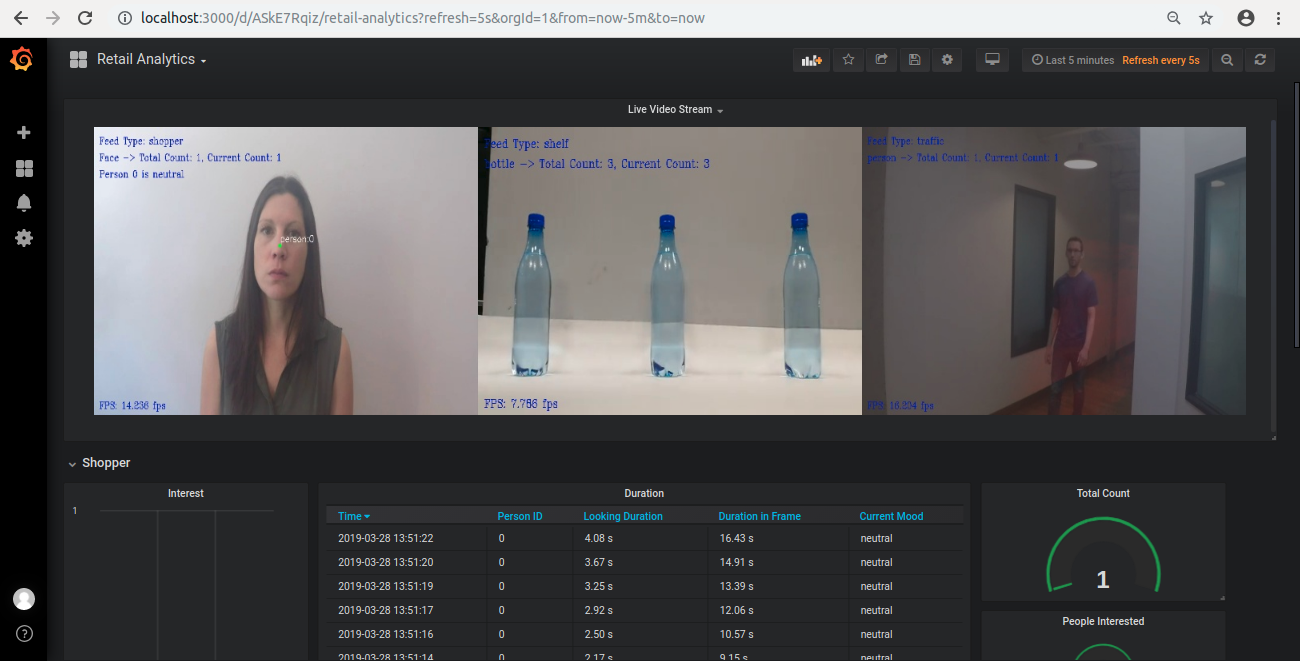
このスマート小売解析アプリケーションは、人々の行動を監視し、小売店内部の人の総数を数えて、ユーザーが指定した商品を検出して在庫を管理します。ビデオおよびカメラリソースを使用して任意の画面数のオブジェクトを検出します。
要件
ハードウェア
- インテル® Iris® Pro グラフィックスまたはインテル® HD グラフィックスを搭載した第 6 世代~第 8 世代インテル® Core™ プロセッサー
ソフトウェア
- Ubuntu* 16.04 LTS (英語)
注: Linux* カーネル 4.14 以降を使用することを推奨します。カーネルのバージョンを確認するには、次のコマンドを実行します。
uname -a
- OpenCL* ランタイムパッケージ
- インテル® ディストリビューションの OpenVINO™ ツールキット 2019 R3 リリース
- Grafana* v5.3.2
- InfluxDB* v1.6.2
仕組み
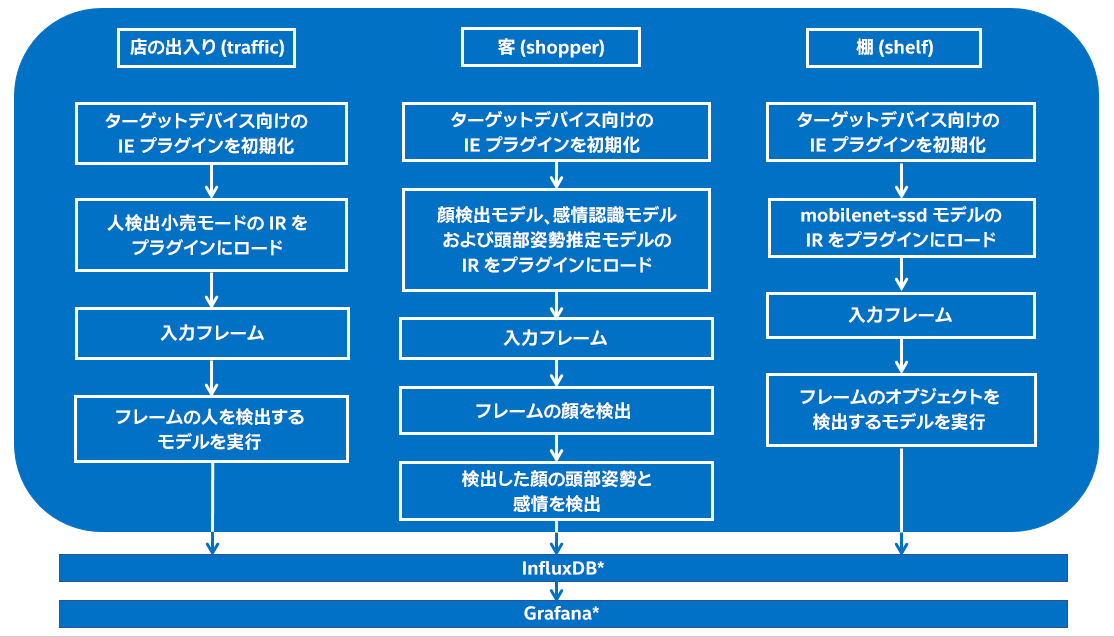
アプリケーションは、インテル® ディストリビューションの OpenVINO™ ツールキットに含まれる推論エンジンを使用します。複数のビデオ入力を利用できます。ユーザーは各ビデオ画像の種類を指定できます。アプリケーションは次の 3 種類の画像をサポートします。
客 (shopper): ビデオ画像の種類が shopper の場合、アプリケーションは入力ストリームからフレームを取得し、人の顔を検出するディープ・ニューラル・ネットワーク・モデルを使用します。フレームに人が含まれる場合、客として数えます。顔が検出されると、アプリケーションは頭部姿勢推定モデルを使用して人の頭の姿勢を確認します。人がカメラを見ている場合、感情認識モデルを使用して感情を検出します。得られたデータを使用して、人が興味を持っているかどうか推論し、検出された人の総数を出力します。また、人がフレームに含まれていた時間とカメラを見ていた時間を測定します。
店の出入り (traffic): ビデオ画像の種類が traffic の場合、アプリケーションはフレームに含まれる人を検出するディープ・ニューラル・ネットワーク・モデルを使用します。店を訪れた人の総数と現在カメラの前にいる人の数を取得します。
棚 (shelf): このビデオ画像の種類は、商品の在庫管理に使用します。ビデオ画像の種類が shelf の場合、このビデオストリームのフレームの客が指定した商品を検出するオブジェクト検出モデルを使用しします。このモデルは、オブジェクトを検出して、フレームに含まれるオブジェクトの数を出力します。
アプリケーションは、画像の種類が異なる、複数のビデオ入力を処理できます。これらのビデオから得られたデータは、解析のために InfluxDB* に格納され、Grafana* で視覚化されます。また、Flask python* ウェブ・フレームワークを使用して、出力ビデオを Grafana* にライブ配信します。
アーキテクチャーの概略図
セットアップ
コードの取得
リファレンス実装のクローンを作成する手順: (smart-retail-analytics)
sudo apt-get update && sudo apt-get install git
git clone https://github.com/intel-iot-devkit/smart-retail-analytics.git
インテル® ディストリビューションの OpenVINO™ ツールキットのインストール
インテル® ディストリビューションの OpenVINO™ ツールキットのインストールおよびセットアップ方法は、https://software.intel.com/en-us/articles/OpenVINO-Install-Linux (英語) を参照してください。
GPU で推論を実行する場合は、OpenCL* ランタイムパッケージが必要です。CPU で推論を実行する場合は不要です。
その他の依存ファイル
InfluxDB*
InfluxDB* は大量の書き込みとクエリーロードを扱うように設計された時系列データベースで、TICK スタックの必須コンポーネントです。InfluxDB* は、DevOps モニタリング、アプリケーション・メトリック、IoT センサーデータ、リアルタイム分析を含む、大量の時系列データを含むユースケースで外部記憶装置として使用されます。
Grafana*
Grafana* はオープンソースの汎用ダッシュボードおよびグラフ・コンポーザーで、ウェブ・アプリケーションとして動作します。バックエンドとして、Graphite*、InfluxDB*、Prometheus*、Google* Stackdriver*、AWS* CloudWatch、Azure* Monitor、Loki、MySQL、PostgreSQL*、Microsoft* SQL Server*、Testdata、Mixed、OpenTSDB および Elasticsearch* をサポートします。Grafana* を使用すると、メトリックがどこに格納されていても、メトリックを照会、視覚化、アラートおよび把握できます。
AJAX*
AJAX* パネルは Grafana* ダッシュボードに外部コンテンツをロードする一般的な方法です。
使用するモデル
アプリケーションは、画像の種類 shopper には、事前トレーニング済みモデル (face-detection-adas-0001 (英語)、head-pose-estimation-adas-0001 (英語)、emotion-recognition-retail-0003) (英語) を使用します。画像の種類 traffic には person-detection-retail-0002 (英語) を使用します。これらのモデルは model downloader スクリプトを使用してダウンロードできます。
画像の種類 shelf には、mobilenet-ssd モデルを使用します。このモデルは、インテル® ディストリビューションの OpenVINO™ ツールキットに含まれる downloader スクリプトを使用してダウンロードできます。mobilenet-ssd モデルは、オブジェクト検出を実行する Single Shot MultiBox Detector (SSD) ネットワークです。このモデルは、Caffe* フレームワークを使用して実装されています。このモデルの詳細は、リポジトリー (英語) を参照してください。
依存ファイルをインストールし、モデルをダウンロードして mobilenet-ssd モデルを最適化するには、下記のコマンドを実行します。
cd <path_to_the_smart-retail-analytics-python_directory>
./setup.sh
- これらのモデルは下記の場所にダウンロードされます。
- face-detection (顔認識): /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/face-detection-adas-0001/
- head-pose-estimation (頭部姿勢推定): /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/head-pose-estimation-adas-0001/
- emotions-recognition (感情認識): /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/emotions-recognition-retail-0003/
- person-detection-retail (人検出小売): /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/person-detection-retail-0002/
ラベルファイル
アプリケーションの画像の種類 shelf には、検出に使用するモデルに関連付けられた labels ファイルが必要です。すべての検出モデルは文字列ラベルではなく整数ラベル (例えば、ssd300 および mobilenet-ssd モデルでは、数 15 はクラス "person" を表します) で動作するため、各モデルに整数 (アルゴリズムが検出するラベル) と文字列 (人間が読めるラベル) に関連付けられた labels ファイルが必要です。labels ファイルは認識できるすべてのモデルのクラス/ラベルを含むテキストファイルで、訓練された順に指定します (1 行あたり 1 つのクラス)。
mobilenet-ssd モデルの場合、labels.txt ファイルは resources ディレクトリーに含まれます。
設定ファイル
resources/config.json は、ビデオとビデオ画像の種類を含みます。config.json ファイルは、"video": <path/to/video> および "type": <video-feed-type> のように、名前/値ペア形式で記述します。
{
"inputs": [
{
"video": "path-to-video",
"type": "video-feed-type"
}
]
}
path-to-video は、入力として使用するビデオの (ローカルシステムの) パスです。
ビデオの種類が shelf の場合、そのビデオで検出されるクラスのラベル (person、bottle など) を次のカラムに指定します。config.json ファイルで使用するラベルは、labels ファイルに含まれるラベルです。
アプリケーションは検出に任意の数のビデオを使用できます (config.json ファイルに任意の数のブロックを記述できます) が、アプリケーションで並列に使用するビデオの数が増えると、各ビデオのフレームレートが低下します。この問題を解決するには、アプリケーションを実行しているマシンに計算能力を追加します。
使用する入力ビデオ
アプリケーションは任意の入力ビデオで動作します。オブジェクト検出のサンプルビデオは、こちら (英語) を参照してください。
初回は、face-demographics-walking (英語)、head-pose-face-detection-female (英語)、bottle-detection (英語) ビデオを使用することを推奨します。ビデオは、setup.sh により resources/ フォルダーに自動的にダウンロードされます。例えば、config.json は次のようになります。
{
"inputs": [
{
"video": "sample-videos/head-pose-face-detection-female.mp4",
"type": "shopper"
},
{
"video": "sample-videos/bottle-detection.mp4",
"label": "bottle",
"type": "shelf"
},
{
"video": "sample-videos/face-demographics-walking.mp4",
"type": "traffic"
}
]
}
ほかのビデオを使用するには、config.json ファイルにパスを指定します。
ビデオファイルの代わりにカメラのストリームを使用する
config.json ファイルの path/to/video をカメラ ID に変更します。ID はビデオデバイスの ID です (/dev/videoX の数 X)。Ubuntu* で、利用可能なすべてのビデオデバイスをリストするには、次のコマンドを使用します。
ls /dev/video*
例えば、上記のコマンドの出力が /dev/video0 の場合、config.json は次のようになります。
{
"inputs": [
{
"video": "0",
"type": "shopper"
}
]
}
環境の設定
インテル® ディストリビューションの OpenVINO™ ツールキットを使用するには、次のコマンドを実行して、セッションにつき 1 回、環境を設定する必要があります。
source /opt/intel/openvino/bin/setupvars.sh -pyver 3.5
注: このコマンドは、アプリケーションを実行する端末で 1 回のみ実行します。端末を閉じた場合、コマンドを再度実行する必要があります。
アプリケーションの実行
ディレクトリーをシステムの git-cloned アプリケーション・コードの場所に変更します。
cd <path_to_the_smart-retail-analytics-python_directory>/application
必要なモデルを指定してアプリケーションを実行します。
python3 smart_retail_analytics.py -fm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/face-detection-adas-0001/FP32/face-detection-adas-0001.xml -pm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/head-pose-estimation-adas-0001/FP32/head-pose-estimation-adas-0001.xml -mm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml -om ../resources/FP32/mobilenet-ssd.xml -pr /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/person-detection-retail-0002/FP32/person-detection-retail-0002.xml -lb ../resources/labels.txt -l /opt/intel/openvino/inference_engine/lib/intel64/libcpu_extension_sse4.so
端末でコマンドを実行したら、次のセクションの説明を使用して Grafana* ダッシュボードを設定し、出力を確認します。
アプリケーションを同期モードで実行するには、コマンドライン引数として -f sync を使用します。デフォルトでは、アプリケーションは非同期モードで実行されます。
異なるハードウェアで実行する
アプリケーションは、異なるモデルに異なるハードウェア・アクセラレーターを使用できます。下記のコマンドライン引数を使用して、各モデルのターゲットデバイスを指定します。
-d_fm <device>: 顔検出ネットワークのターゲットデバイス (CPU、GPU、MYRIAD、HETERO:FPGA,CPU または HDDL)。-d_pm <device>: 頭部姿勢推定ネットワークのターゲットデバイス (CPU、GPU、MYRIAD、HETERO:FPGA,CPU または HDDL)。-d_mm <device>: 感情認識ネットワークのターゲットデバイス (CPU、GPU、MYRIAD、HETERO:FPGA,CPU または HDDL)。-d_om <device>: mobilenet-ssd ネットワークのターゲットデバイス (CPU、GPU、MYRIAD、HETERO:FPGA,CPU または HDDL)。-d_pd <device>: 人検出小売ネットワークのターゲットデバイス (CPU、GPU、MYRIAD、HETERO:FPGA,CPU または HDDL)。
例:
顔検出モデル (FP16) および感情認識モデル (FP32) を GPU、頭部姿勢推定モデルを MYRIAD、mobilenet-ssd および人検出小売モデルを CPU でそれぞれ実行するには、下記のコマンドを使用します。
python3 smart_retail_analytics.py -fm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/emotions-recognition-retail-0003/FP32/emotions-recognition-retail-0003.xml -om ../resources/FP32/mobilenet-ssd.xml -pr /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/person-detection-retail-0002/FP32/person-detection-retail-0002.xml -lb ../resources/labels.txt -l /opt/intel/openvino/inference_engine/lib/intel64/libcpu_extension_sse4.so -d_fm GPU -d_pm MYRIAD -d_mm GPU -d_pd CPU -d_om CPU
複数のデバイスで実行するには、-d MULTI:device1,device2 を使用します (例: -d MULTI:CPU,GPU,MYRIAD)
デフォルトでは、アプリケーションは CPU で実行されます。
注:
- インテル® ニューラル・コンピュート・スティックおよびインテル® Movidius™ VPU は FP16 モデルのみ実行できます。アプリケーションに渡されるモデルは FP16 データ型でなければなりません。
FP32: FP32 は数の表現に 32 ビットを使用する単精度浮動小数点演算です。大きさ (仮数部) は 8 ビット、精度 (指数部) は 23 ビットです。詳細は、ここをクリックしてください。
FP16: FP16 は 16 ビットを使用する半精度浮動小数点演算です。大きさ (仮数部) は 5 ビット、精度 (指数部) は 10 ビットです。詳細は、ここをクリックしてください。
インテル® Movidius™ VPU で実行する
アプリケーションをインテル® Movidius™ VPU で実行するには、下記の手順に従って hddldaemon を設定します。
下記のコマンドを使用して hddl_service.config を開きます。
sudo vi ${HDDL_INSTALL_DIR}/config/hddl_service.config
"device_snapshot_mode": "None" を "device_snapshot_mode": "full" に更新します。
タグの HDDL 設定を更新します。
"graph_tag_map":{"tagFace":1,"tagPose":1,"tagMood":2,"tagMobile":2,"tagPerson":2}
ファイルを保存して閉じます。
hddldaemon を実行します。
${HDDL_INSTALL_DIR}/bin/hddldaemon
アプリケーションをインテル® Movidius™ VPU で実行するには、-d HDDL コマンドライン引数を使用します。
python3 smart_retail_analytics.py -fm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -om ../resources/FP16/mobilenet-ssd.xml -pr /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/person-detection-retail-0002/FP16/person-detection-retail-0002.xml -lb ../resources/labels.txt -d_pd HDDL -d_fm HDDL -d_pm HDDL -d_mm HDDL -d_om HDDL
インテル® Arria® 10 FPGA で実行する
アプリケーションを FPGA で実行する前に、環境変数を設定して AOCX (ビットストリーム) ファイルをプログラムします。
ボードの次の環境変数に適切なディレクトリーを設定します。
export AOCL_BOARD_PACKAGE_ROOT=/opt/intel/openvino/bitstreams/a10_vision_design_sg<#>_bitstreams/BSP/a10_1150_sg<#>
注: ボードのバージョンが不明な場合は、ファンカバー側の製品ラベルまたは製品 SKU を確認してください: Mustang-F100-A10-R10 => SG1; Mustang-F100-A10E-R10 => SG2
ボードの次の環境変数に適切なディレクトリーを設定します。
export QUARTUS_ROOTDIR=/home/<user>/intelFPGA/18.1/qprogrammer
残りの環境変数を設定します。
export PATH=$PATH:/opt/altera/aocl-pro-rte/aclrte-linux64/bin:/opt/altera/aocl-pro-rte/aclrte-linux64/host/linux64/bin:/home/<user>/intelFPGA/18.1/qprogrammer/bin
export INTELFPGAOCLSDKROOT=/opt/altera/aocl-pro-rte/aclrte-linux64
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$AOCL_BOARD_PACKAGE_ROOT/linux64/lib
export CL_CONTEXT_COMPILER_MODE_INTELFPGA=3
source /opt/altera/aocl-pro-rte/aclrte-linux64/init_opencl.sh
注: これらの環境変数を設定する、システム独自のスクリプトを作成することを推奨します。環境変数は、新しい端末を開く、またはシステムを再起動するたびに設定する必要があります。
HDDL-F のビットストリームは /opt/intel/openvino/bitstreams/a10_vision_design_sg<#>_bitstreams/ ディレクトリーに含まれています。
ビットストリームをプログラムするには、下記のコマンドを使用します。
aocl program acl0 /opt/intel/openvino/bitstreams/a10_vision_design_sg<#>_bitstreams/2019R3_PV_PL1_FP16_MobileNet_Clamp.aocx
ビットストリームのプログラムの詳細は、このリンク (英語) を参照してください。
FPGA で 16 ビットの浮動小数点精度 (FP16) でアプリケーションを実行するには、-d HETERO:FPGA,CPU コマンドライン引数を使用します。
python3 smart_retail_analytics.py -fm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/face-detection-adas-0001/FP16/face-detection-adas-0001.xml -pm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml -mm /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml -om ../resources/FP16/mobilenet-ssd.xml -pr /opt/intel/openvino/deployment_tools/open_model_zoo/tools/downloader/intel/person-detection-retail-0002/FP16/person-detection-retail-0002.xml -lb ../resources/labels.txt -l /opt/intel/openvino/inference_engine/lib/intel64/libcpu_extension_sse4.so -d_pd HETERO:FPGA,CPU -d_fm HETERO:FPGA,CPU -d_pm HETERO:FPGA,CPU -d_mm HETERO:FPGA,CPU -d_om HETERO:FPGA,CPU
Grafana* での視覚化
Grafana* サーバーを開始します。
sudo service grafana-server start
ブラウザーで、localhost:3000 に移動します。
ユーザー admin およびパスワード admin でログインします。
[Configuration] をクリックします。
[Data Sources] を選択します。
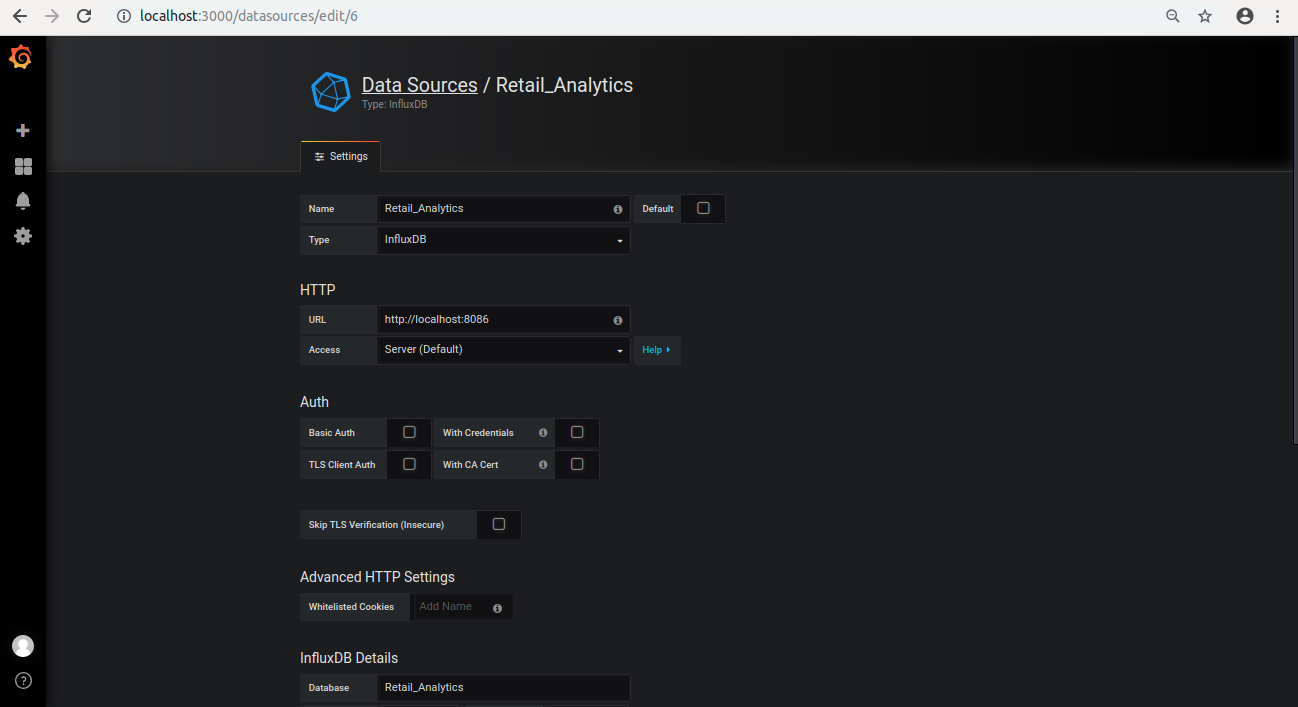
[+ Add data source] をクリックして下記の情報を設定します。
- Name: Retail_Analytics
- Type: InfluxDB
- URL: http://localhost:8086
- Database: Retail_Analytics
- [Save and Test] をクリックします。
ブラウザーの左側の + アイコンをクリックして、[Import] を選択します。
[Upload.json File] をクリックします。
smart-retail-analytics-python ディレクトリーから retail-analytics.json を選択します。
Select a influxDB data source で [Retail_Analytics] を選択します。
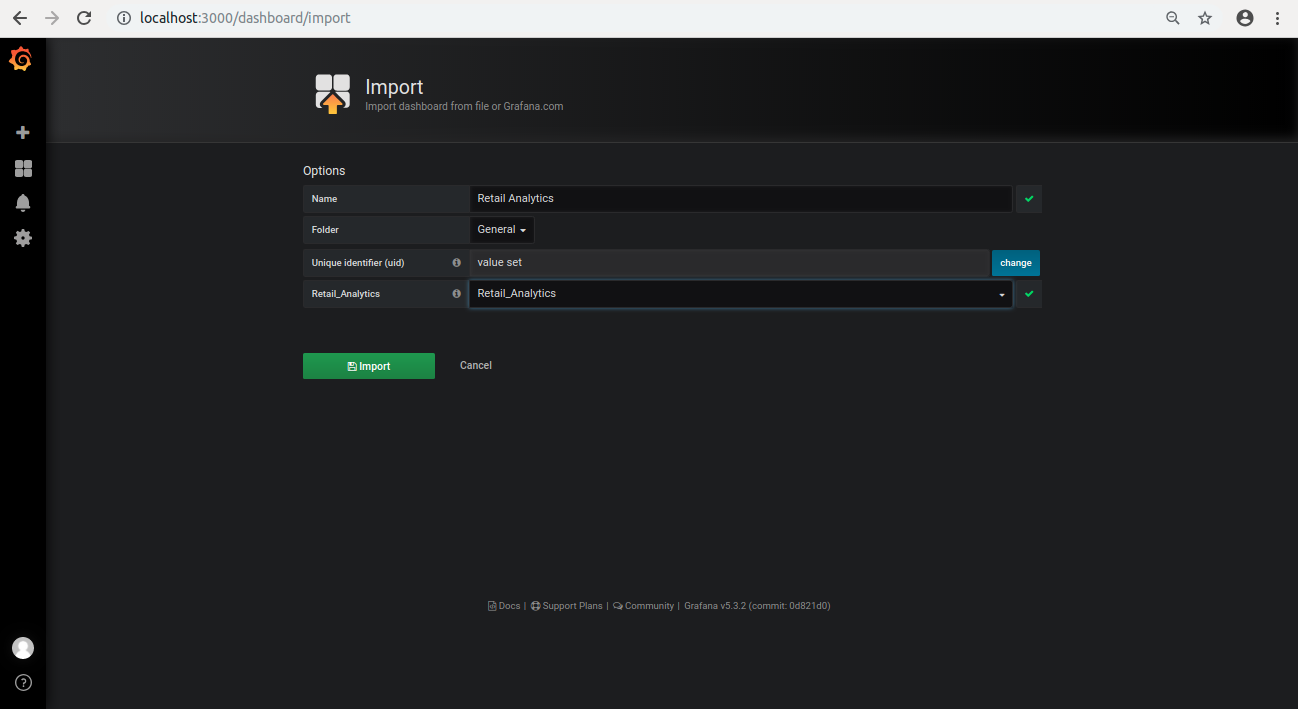
[Import] をクリックします。
アプリケーションのコンテナー化
Docker* コンテナーを使用して smart-retail-analytics-python アプリケーションをコンテナー化するには、ここ (英語) の指示に従ってください。