エクセルソフト株式会社が販売しているデータ アナリティクス製品について、開発元であるアルテア エンジニアリング社のブログをご紹介しています。
アルテアエンジニアリング社は多国籍企業なので、日本でもいろいろな国の方が働いています。日本オフィスで働くイタリア人エンジニアに「私は cars と cards が全く同じに聞こえる」と話したところ、彼は「日本語の箸と橋の違いもよくわからない」と言っていました。特定の人に区別しにくい問題は、機械学習で区別すれば良いじゃないか!ということで、今回は機械学習で音声認識をしてみます。
ちょっと脱線して、なぜ、こういうことが起きるかと言うと、物理的な空気の振動である「音」と、私たち一人ひとりが頭の中で再現している「声」は同じではないからです。cars と cards は舌の動き、位置が違うので、空気の振動である「音」は完全に違います。しかし日本人として生まれ育ち、完全に日本語にチューニングされた私の脳は、どちらも、カーズという「声」を私の頭の中で再生してしまうのです。脳というのは、物理特性をそのまま数値で示してくれず、全部、個人個人の感覚的な何かに置き換えてしまうんですね。詳しく知りたい方はクオリアという言葉を調べてみてください。最終的には哲学に行きついて訳が分からなくなります。脱線終了します。
まずは声を録音
本題に戻って、さっそく音声認識をしていきましょう。
まず、このように箸と橋の音声を25回ずつ録音しました。
箸の音声
橋の音声
自分の声を複数回撮って意味あるのか、と思うかもしれません。私もそう思ってました。しかし、自分で同じように発音したつもりでも、実際のデータは毎回かなり異なります。下に箸の音声波形を3個並べてみましたが、毎回違うということがよくわかると思います。逆に言うと、毎回毎回違うものを、全部一つの「箸」と認識する脳ってすごいですよね。

音声を数値データに変換
さて、機械学習を活用するには、音のままではだめで、何かしらの設計変数と応答という数値データとして扱う必要があります。何か良い方法はないかなあと、Altair Community内を眺めていると「Compose の標準言語 OML から Python の関数を利用するには」という記事を見つけました。
wav ファイルに対して 1/3 オクターブバンド処理をしてくれるものです。これにしましょう。
下図のように、各周波数(私の所有するマイク特性に合わせて 250 – 16000 Hzを採用)の音圧を設計変数、橋であるか箸であるかの判定を応答とします。
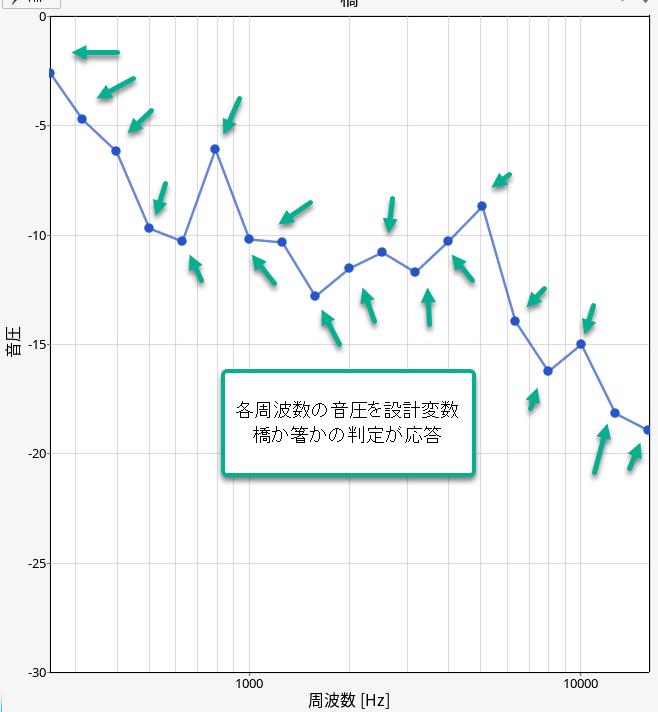
そうすれば、エクセルでこのようなデータセットを作成することができます。
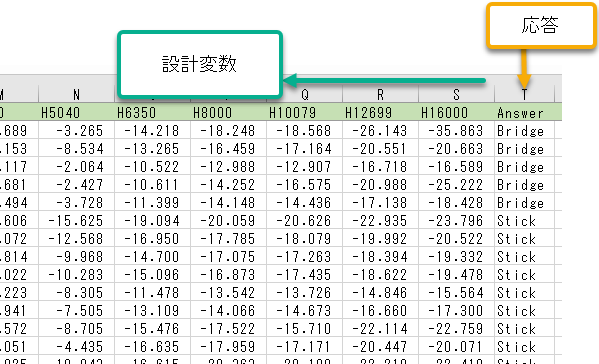
ちなみに全データとしては、こうなっています。全体的には、なんとなく違いがあるような感じがしますが、
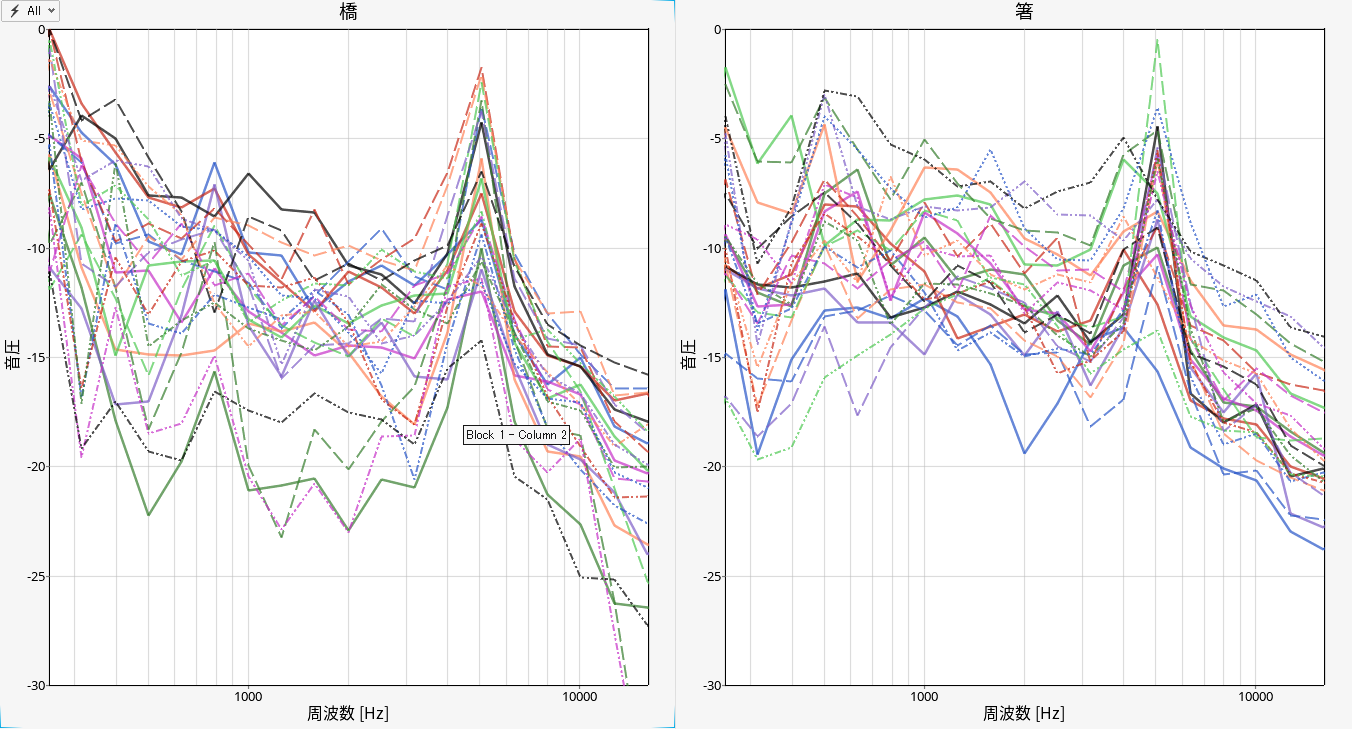
一つ一つだと、それほど明確な違いがあるようには見えず、正直不安です。アルテアの機械学習は、この違いをきっちり見極めてくれるのでしょうか?
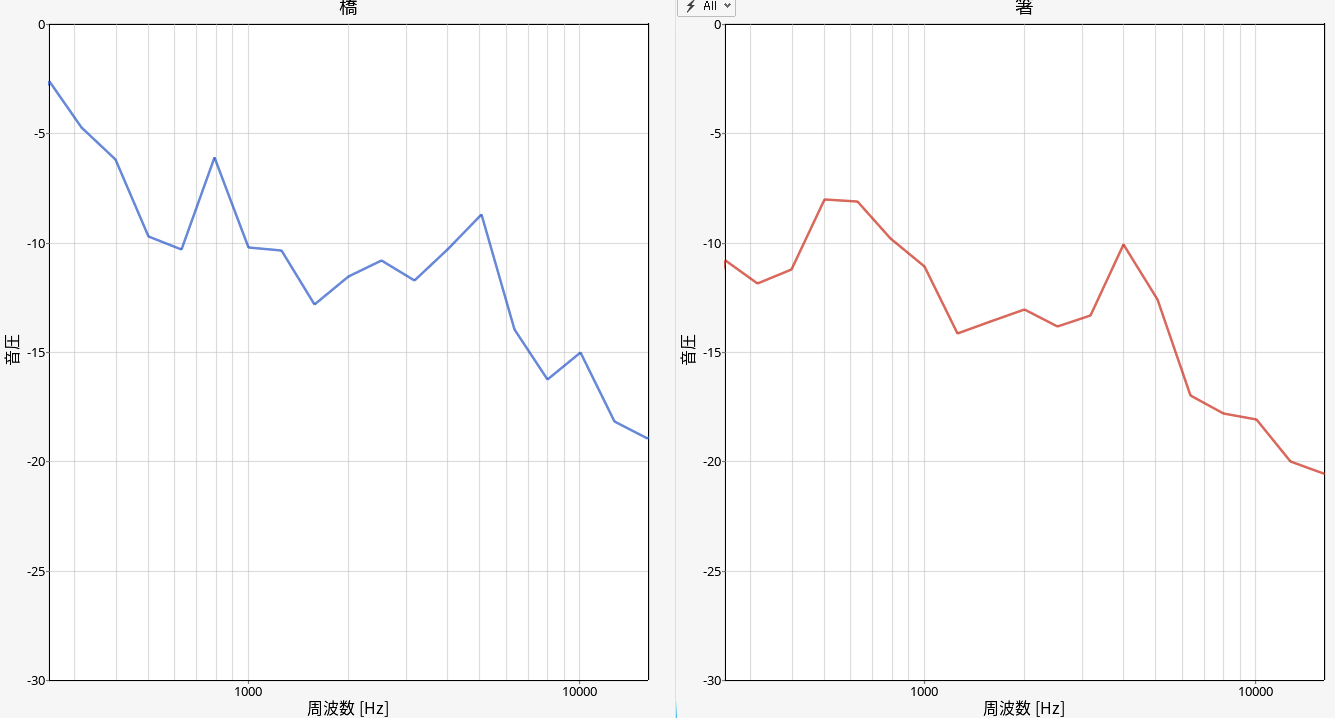
Deep Learning(深層学習)で予測モデルを作成
ここから先は Altair Knowledge Studio(アルテア ナレッジスタジオ)の出番です。はじめに私の大好きな Deep Learning モデルで、下図のように予測モデルを作ります。こういった作業は、Knowledge Studio だと本当に簡単ですね。
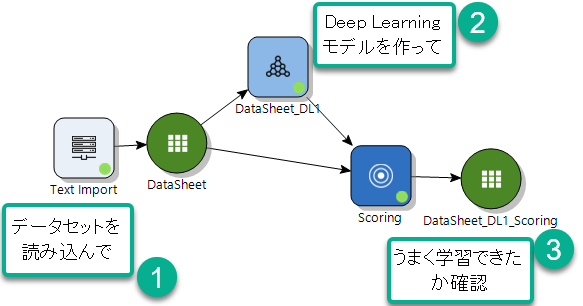
きっちり学習できています。
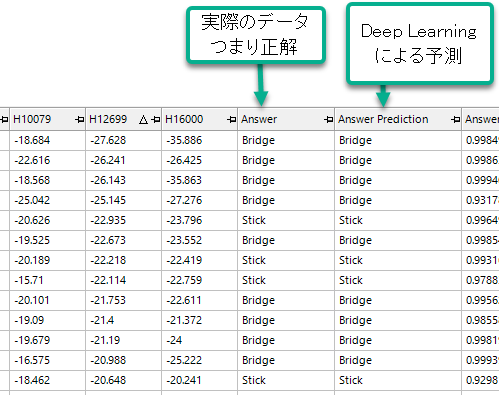
予測モデルが橋と箸を認識できるのか検証
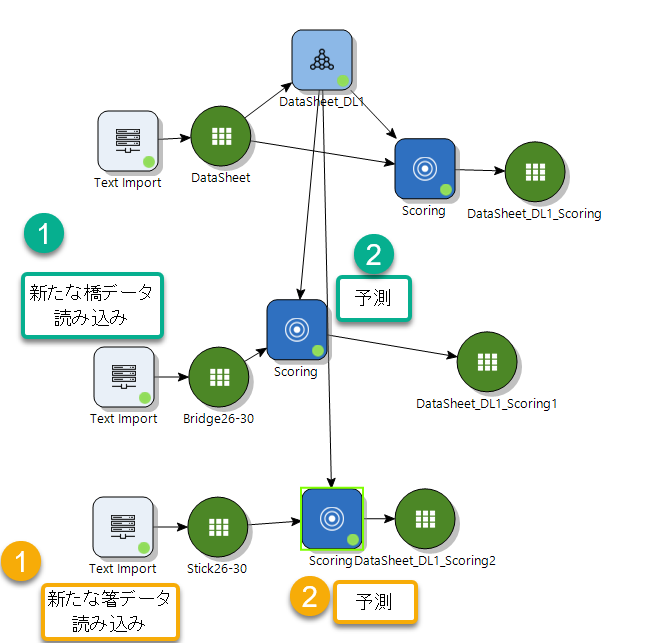
次に、学習データの 50 音声ファイルとは別に、橋と箸 5 回ずつ、合計 10 回の録音を改めて行い、Deep Learning 予測モデルが正解できるかを検証します。やっぱり作業はとても簡単です。
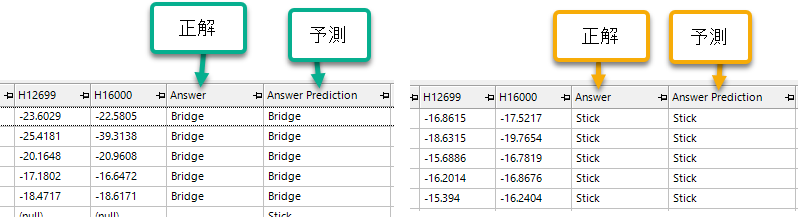
それでは、答え合わせです。全問正解!Deep Learning が見事な予測を行ってくれました。
このようなことをもっと大規模に、もっと高精細に行った予測モデルを埋め込んだのが、スマホや AI スピーカーの音声認識ということになるのでしょう。
いかがでしたか。今回は音声という切り口で機械学習を活用してみましたが、大事なことは、人が区別できなさそうなことを、機械学習で区別できる可能性を示せた点だと思います。いろんな使い道があると思いますので、ぜひ使い道を考えていただければと思います。

詳細・事例は、Knowledge Studio の製品ページ、またはお気軽に弊社までお問い合わせください。
*本記事は、アルテアエンジニアリング株式会社のブログ投稿文を抜粋・転載したものです。