インテル® Advisor 提供終了の予定に関するご案内
インテル® ソフトウェア開発ツール 2026.0 のリリースに伴い、インテル® oneAPI ツールキットのインストール・パッケージからインテル® Advisor が削除されました。引き続き、スタンドアロン・パッケージとしてダウンロードすることができますが、2026年以降には提供終了となる予定です。
詳細は、お知らせ/FAQ の「インテル® Advisor 提供終了の予定」に関する案内をご確認ください。
概要
ベクトル化の最適化とスレッドのプロトタイプを生成

最近のプロセッサーでは、ベクトル化とスレッド化を行ったコードは非常に高速に実行できます。しかし、コードがベクトル化できない理由を理解することは容易ではありません。
インテル® Advisor は、C、C++、C#、Fortran ソフトウェア・アーキテクト向けの高性能ベクトル化/スレッド化プロトタイプ生成ツールです。ベクトル化を安全かつ効率的に行えるように、反復回数、データ依存性、メモリー・アクセス・パターンなどの必要なキーデータを取得します。インテル® AVX-512 対応ハードウェアがない場合でも、最新のインテル® AVX-512 命令セット向けの最適化を行えます。さらに、スレッドのプロトタイプ生成を利用することで、進行中の開発に影響を与えることなく、設計オプションを素早く評価できます。
詳細・新機能 技術情報インテル® Advisor 2025
バージョン 2025.5 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートやシステム要件、およびインテル社公開の情報を参照ください。
インテル® Advisor に関するその他のドキュメントについては、こちらを参照ください。
詳細
ベクトル化とスレッド化は、現代のプロセッサー上で
パフォーマンスを得るのに重要です
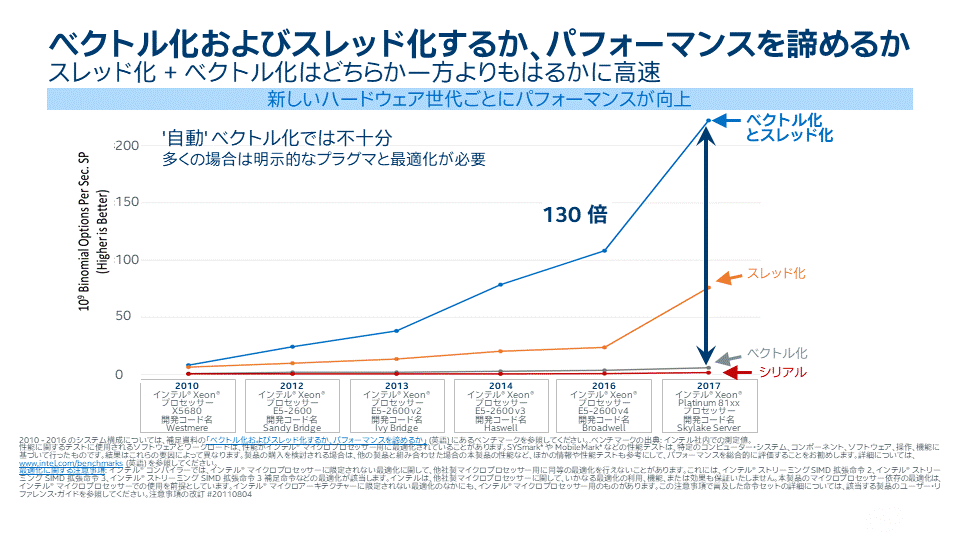
プロセッサーが進化するにつれ、プロセッサーの性能を最大限に引き出すには、ソフトウェアのベクトル化 (インテル® AVX やインテル® SIMD 命令を使用) とスレッド化がますます重要になってきています。
ある例では、ベクトル化とスレッド化が実装されたコードは、ベクトル化とスレッド化が未実装のコードよりも 187 倍も高速化し、スレッド化もしくはベクトル化のどちらか一方が実装された場合よりもおよそ 7 倍高速化されました。このように、ベクトル化とスレッド化されたコードとされていないコードの性能差は、新しいプロセッサーの世代ごとに広まってきています。
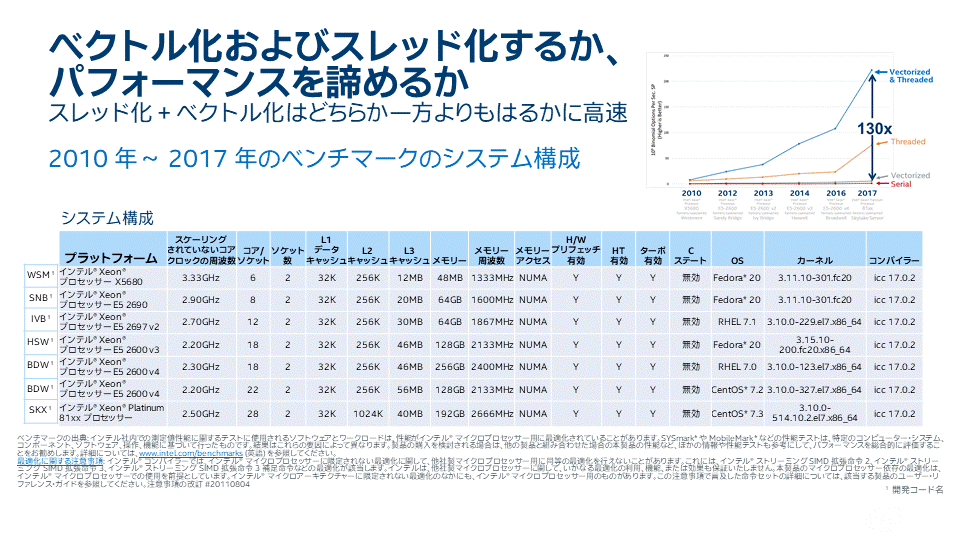
スレッド化とベクトル化両方の実装は、どちらか一方の実装よりも、コードをはるかに高速化できます。この性能差は、新しいハードウェアの世代ごとに広まってきています。
インテル® Advisor によって、実装に多くの時間、コストを費やす前にパフォーマンス向上が見込める箇所を確認でき、効果的な選択肢のみを実装することができます。
データ主導のベクトル化とスレッド化の最適化/設計
適切な設計方法を選択するには、正確かつ豊富なデータが必要です。どのループを最初にベクトル化およびスレッド化すべきでしょう? 労力に対して十分なパフォーマンスは得られますか? スレッドのパフォーマンスはコア数に応じてスケールしますか? ループにはベクトル化を妨げる依存性がありますか? ループの回数とメモリーアクセスのパターンは? 最新のインテル® AVX2 で効率良くベクトル化できるか、もしくは以前のインテル® SIMD 命令を使うべきか?
高速なコードを素早く開発
インテル® Advisor は、ベクトル化とスレッド化の適切な設計と意思決定に必要なデータやヒントを、素早く簡単に得るためのワークフローを提供します。C/C++、C# および Fortran コードをサポートし、最適化コストの増加と実装を中断させることなく、異なる種類のスレッド化設計によるパフォーマンスのスケーリングを比較し、即座にモデル化できます。インテル ® Advisor で適切な設計を行った後の実装では、スレッド化によるバグを気にすることなく、またいつでもスレッド化を削除できるため、コードの設計段階でコードを単一に保つことができます。
修正が容易な開発の設計段階で、事前にデータ共有の問題を検出し解決します。同期を追加した際のパフォーマンスへの影響と、より多くのコアを搭載するシステムでのスケーリングをモデル化し確認できます。
ベクトル化アドバイス
既存のベクトル化済みのコードをチューニングして、さらに新しいベクトル化を容易に追加できます。潜在的なパフォーマンス向上の可能性で、各ループをソートすることで、ソースに対するコンパイラーのレポートを解釈しやすくなり、効率良いベクトル化のヒントが得られます。また、ベクトル化を安全にかつ効率良く行うために、ループカウント、データ依存性そしてメモリーのアクセスパターンなど重要なデータを確認できます。
ステップガイド
1. 調査 - 並列化すべき箇所を検出し、ループ回数を計測
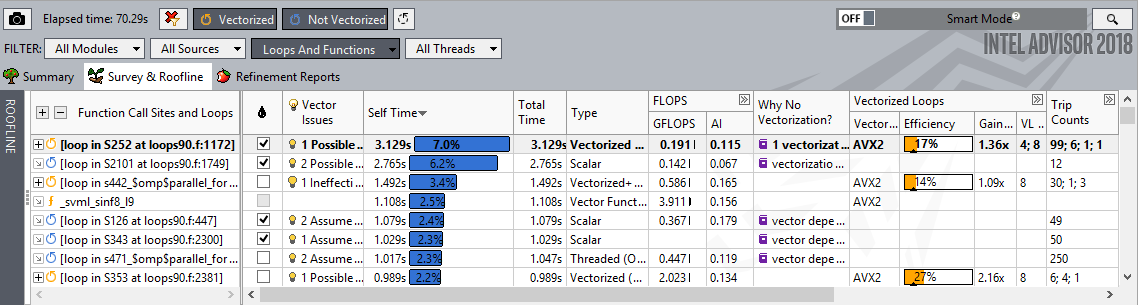
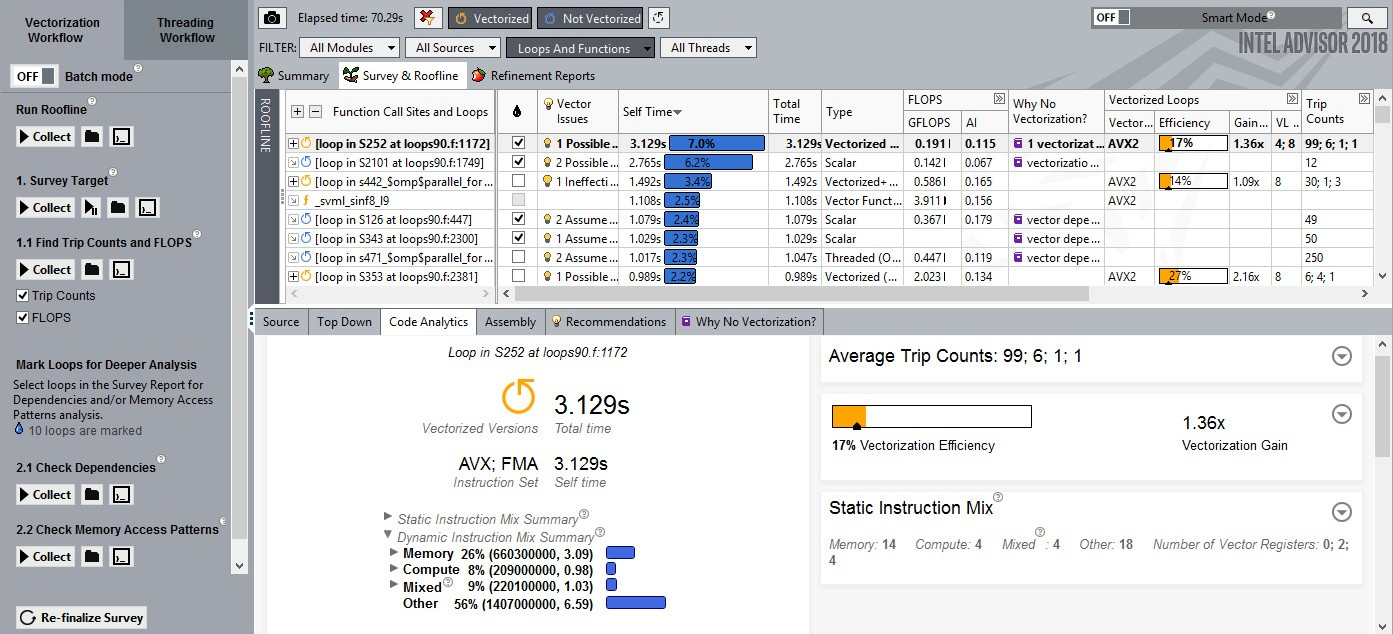
まずはアプリケーションの中から、並列化によってパフォーマンスを向上できる箇所を探すことから始めます。これは、スレッド化とベクトル化の両方で最初のステップとなります – 最も影響のある変更箇所を探します。
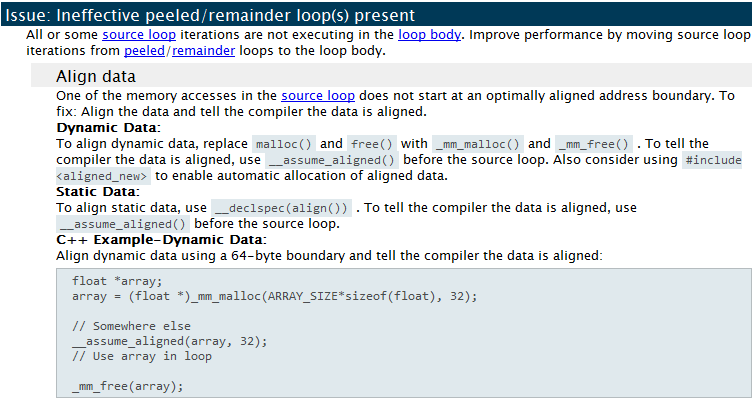
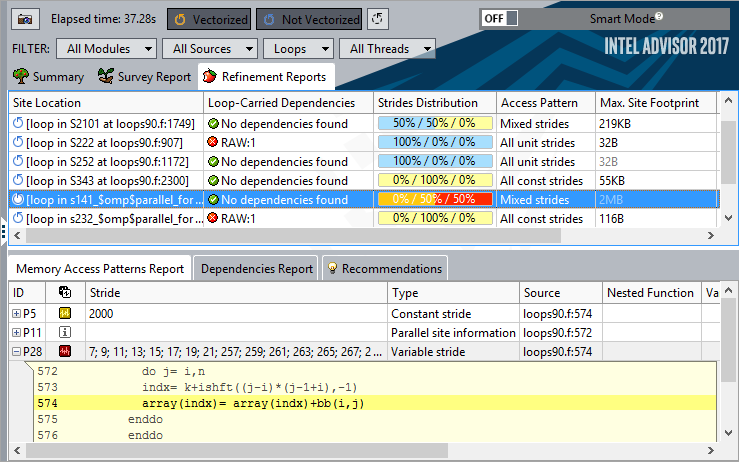
すべてのループの Survey Summary (調査結果の一覧) 推奨を見るにはハイライトされたバルブマークをクリックします (次の図)。コンパイラーのメッセージとともにソースを見るにはループをダブルクリックします (その次の図)。
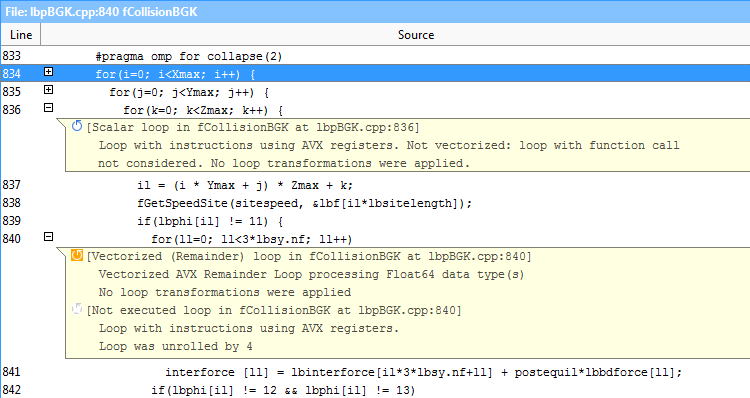
インテル® Advisor はスレッド化とベクトル化のために、有用なヒントを提供します。
コンパイラーのメッセージは、ソースに対応させ確認することが可能です。
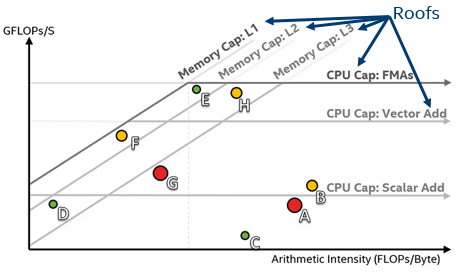
キャッシュ対応ルーフライン
調査ターゲット、トリップ数、および 1 秒あたりの浮動小数点演算(FLOPS) を実行すると、キャッシュを認識するルーフラインのグラフが表示されます。
「キャッシュ対応ルーフライン」を使用して、ボトルネックの原因となる可能性のあるパフォーマンスの低下したループと、各ループのパフォーマンス「ヘッドルーム」
を特定します。
ルーフライン・ダイアグラムの「Roofs (ルーフ)」には、プラットフォームのメモリー、キャッシュ、計算の制限が表示されます。
ドットはループを表します。 最適化すれば、赤いドットが大きくなるほど時間がかかります。
ルーフから遠い点には改善のための「ヘッドルーム」があります
この図では、A および G が最良の候補、B は改善の余地があるが影響は少ない候補、E、C、D、H は改善の余地が見込めない候補です。
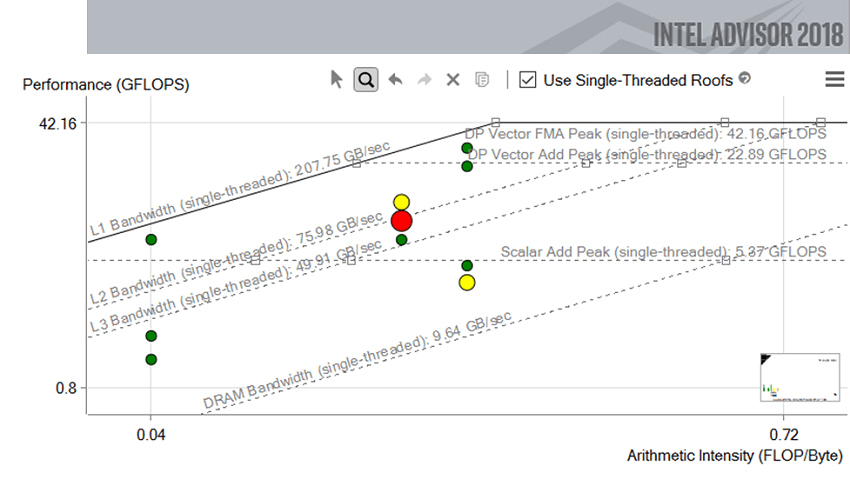
インテル® Advisor のインタラクティブなルーフライン機能を使うことで、個々のループのソースをクリックするだけで簡単に確認することができ、視覚的に確認し易いように、階層的に拡大・縮小することができます。
2. 注目すべき箇所を見つける - ベクトル化またはスレッド化に向けて
ベクトル化
-
マークされたループのループ伝搬依存性をチェックします
サーベイレポートには、コンパイラーが依存性を想定したためベクトル化されなかったループの影響が示されます。チェックボックスにチェックを入れて、依存関係のチェックを行います。チェックの結果、実際に依存関係が検出されなかった場合、ソースにプラグマを挿入してコンパイラーにループをベクトル化しても良いことを知らせます。
-
マークされたループのメモリー・アクセス・パターンをチェックします
連続するゼロユニット・ストライドのベクトル化は最も高効率です。しかし、ループ中で間接参照が行われている場合、開発者 (とコンパイラー) はベクトル化の可能性を判断できない可能性があります。チェックボックスにチェックを入れ、メモリーアクセスが均一であることを確認するため、メモリー・アクセス・パターン解析を行います。均一であれば、#pragma omp を使用して関数をベクトル化できます。パフォーマンスの改善をチェックするため、調査を再実行します。
メモリー・アクセス・パターン解析は、プラグマを挿入することで容易にベクトル化が可能なメモリーのストライドアクセスをチェックできます。
スレッド化
-
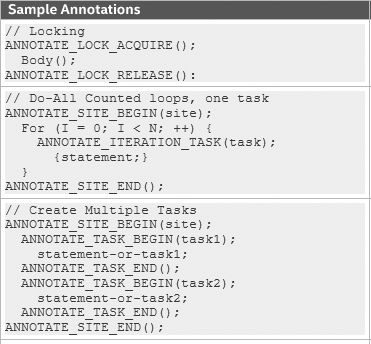
ソースにアノテーションを追加 - スレッドの設計案を "スケッチ"
インテル® Advisor の解析によって並列性の可能性を簡単に見出せるようにするために、ソースコードにアノテーション (注釈) を挿入します。コンパイラーは、挿入したアノテーションを無視します。アノテーションは、設計をモデル化するためインテル® Advisor のみによって使用されます。これにより、シリアルコードのまますべてのテストケースを実行できるため、設計段階でスレッドのバグを洗い出すことが可能になります。
アノテーションによりアプリケーションのスレッド化の設計を記述し、インテル® Advisor がスケーラビリティーを解析して依存性エラーを検出します。アノテーションはコンパイラーによって無視されるため、開発を中断することなく設計を評価できます。
3. パフォーマンスとスケーラビリティーをチェック - 代替設定と比較します
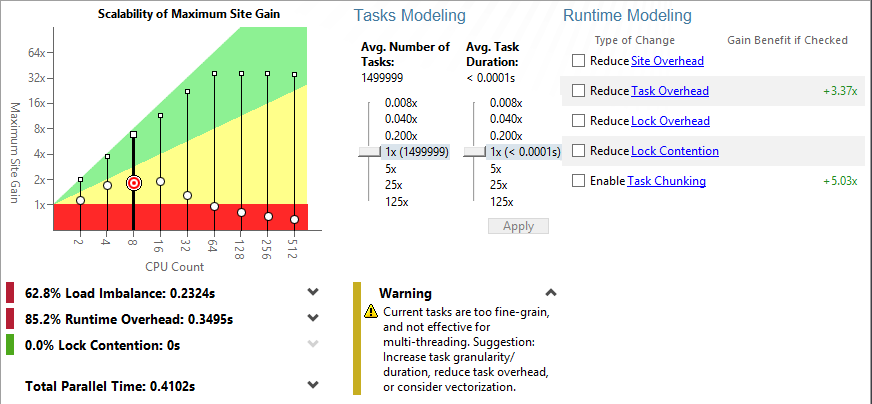
"Check Suitability" で、プロジェクトのパフォーマンスとスケーラビリティーをチェックし、いくつかのスレッド化の候補を評価しましょう。ロードインバランス、ロック競合、そしてランタイム・オーバーヘッドの影響の可能性を確認できます。
時間を節約。効率良く作業。スレッドを実際に実装する前に、コア数が非常に多いシステム上でのスケーラビリティーを評価。
4. 正当性のチェック
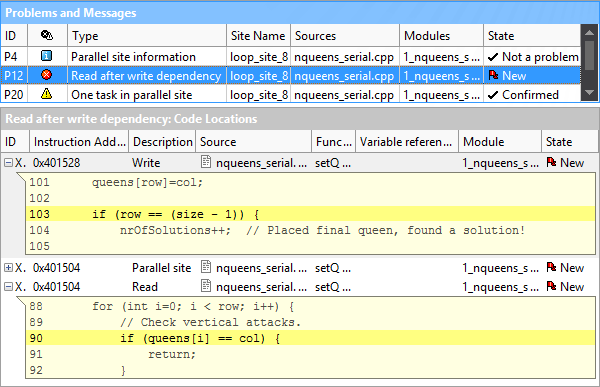
デッドロックや競合につながるデータ共有の問題をお持ちですか? 実際に並列性を実装する前にそれらを検出して解決できます。
インテル® Advisor は、エラーの一覧を示し、実際のソースコードへのリンクと関連するすべてのコードの場所、あるいはコードの断片を表示します。
時間を節約。スレッド化を実装する前に同期問題を検出。
5. 実装 - 並列プログラミング・モデルの選択
インテル® Advisor は、オープンで業界標準の並列プログラミング・モデルを選択できます。OpenMP* は、既存のコードと互換性があります。
インテル® スレッディング・ビルディング・ブロック (インテル® oneTBB) は、豊富な抽象化機能を提供します。 Microsoft* TPL は、C# 向けに設計されています。
| 言語 | 並列プログラミング・モデル |
|---|---|
| C/C++ |
|
| C# |
|
| Fortran |
|
簡略化する
インテル® Advisor が、アプリケーションを自動的にスレッド化し高速に実行できるようにできれば理想的ですが、残念ながらそれを実現するための技術は、現在の技術水準を超えていると言わざるを得ません。インテル® Advisor は、ソフトウェア設計者や開発者のためのツールです。このツールは解析を自動化し、開発者が効率良く既存のアプリケーションをスレッド化するために必要な情報を提供します。
実装の前にいくつかの手法を試す
設計プロセスを繰り返すことで、簡単に代替案とトレードオフを調査できます。インテル® Advisor は、正確なパフォーマンスの予測と同期エラーを事前に特定することで、優れた設計に向けた意思決定を支援します。コストのかかる設計ミスを回避しつつ、より高速な並列化による性能向上を達成できます。
スケジュールを遅延することなく並列化を行う
インテル® Advisor を使うことで、スレッドの設計、パフォーマンス予測、エラー解析を通常の開発作業と並行して進めることができるようになります。アノテーションは、インテル® Advisor に、高いパフォーマンスと正当性を得るための設計方針を開発者にアドバイスするために使用されますが、コンパイルされたコードには影響しません。これにより、並列化の設計を行いながら製品版の開発や更新を継続できます。すべてのテストケースで作業を続行できます。並列処理を実際に実装する前に、アプリケーションが安定して正しく動作することを確認しましょう。
生産的な並列プログラミング・モデル
インテル® ソフトウェア開発ツールには、インテル® oneTBB などの並列プログラミングの生産性を高めるコンポーネント、機能が含まれています。拡張性と信頼性が高い生産的な並列プログラミング・モデルによって、数行のコード追加・変更で並列処理を実装します。タスクベースのアルゴリズム、コンテナー、同期プリミティブは、並列アプリケーションの開発を容易にします。インテル® oneTBB のタスクベースのスケジューラは、タスクをスレッドに動的にマップすることで、ロードバランシングが行われ、キャッシュの局所性と高め、パフォーマンスを向上させます。これにより、管理しやすい少ないコードによって、高いパフォーマンスをいち早く実現できます。
ドキュメント
オンライン・コンテンツ
キャッシュを考慮したルーフライン解析を使用してベクトル化とメモリーの最適化を詳しく調査する
完璧なベクトル化およびスレッド化がおこなれている場合でも、開発者は、CPU、ベクトル、スレッドの利用率と、メモリー・サブシステムのデーター・ボトルネックのバランスを調整する必要があります。
この Webinar で紹介されている「ルーフライン・モデル」を使うことで、アプリケーションのパフォーマンスの問題にどのように適切に対象するかを直観的に理解できます。
本コースでは、まず、ルーフライン・モデルとは何かを説明し、その後、インテル ® Advisor によるルーフライン解析、ケーススタディー、そして、現在の最新バージョンおよび次期バージョンの新機能をご紹介します。

AVX-512 ハードウェアを使用することなく AVX-512 を最適化する
インテル ® Xeon Phi™ プロセッサー (Knights Landing) や、今後登場するインテル® Xeon® プロセッサーなど、ますます複雑化する現代、および次世代のハードウェアを最大限に活用するには、ソフトウェアが効率良くスレッド化およびベクトル化されていることが求められます。
本セッションは、2 部構成とっており、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) のハードウェアを使用することなく、インテル ® AVX-512 ソフトウェアを最適化する方法をご紹介します。
- 前半では、ベクトル化の背景と効率の良いベクトル化を支援するツール「インテル® Advisor 2017」の機能について説明します。
- 後半では、AVX-512 の概要についてお話した後、インテル® Advisor 2017 が AVX-512 とそれ以前の命令セットの両方を使用するソフトウェアの最適化に、どのように役立つかを紹介します。

- ベクトル化の背景とインテル® Advisor 2017 機能紹介 (前編)

- AVX-512 の概要とソフトウェア最適化 (後編)
製品トレーニング
- 製品概要と使い方 (前編)
- 製品概要と使い方 (後編)
- ベクトル化アドバイザー機能のチュートリアル
関連ページ


お知らせ
インテル® ソフトウェア開発ツール 2026.0 のリリースに伴い、インテル® oneAPI ツールキットのインストール・パッケージからインテル® Advisor が削除されました。引き続き、スタンドアロン・パッケージとしてダウンロードすることができますが、2026年以降には提供終了となる予定です。
過去にインテル® oneAPI ベース・ツールキットまたはインテル® oneAPI ベース & HPC ツールキットの有償サポートサービス製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、引き続き、通常通りサポートサービスをご利用いただけます。
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2023年11月24日、インテル® Advisor 2024 が同梱されるインテル® ソフトウェア開発ツールに対応する有償サポートサービスの提供を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
2022年12月19日、インテル® Advisor 2023 が同梱されるインテル® oneAPI 2023 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日、インテル® Advisor 2022 が同梱されるインテル® oneAPI 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
2020年 12月 9日、インテル® Advisor 2021 が同梱されるインテル® oneAPI 2021 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2021 を無料でダウンロードしてご利用いただけます。
2019年 12月 18日、インテル® Advisor 2020 が同梱されるインテル® Parallel Studio XE 2020 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2020 を無料でダウンロードしてご利用いただけます。
インテル® System Studio は、システム/IoT デバイス・アプリケーションのパフォーマンス、電力効率、信頼性向上を支援するソフトウェア開発ツールです。
2018年
10月 3日にリリースされたインテル® System Studio のバージョン 2019 より、Professional Edition 以上に新たにインテル®
Advisor が同梱されます。
インテル® System Studio の製品詳細はこちら。
2018年 9月 13日、インテル® Advisor 2019 が同梱されるインテル® Parallel Studio XE 2019 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2019 を無料でダウンロードしてご利用いただけます。
iSUS では、皆様のご要望にお応えして、インテル® Advisor 2019 for Windows* Initial Release および Update 1 の日本語版を提供しています。日本語版では、GUI/CLI メッセージ、およびヘルプやドキュメント類が日本語化されています。こちらの iSUS のページからお申し込みいただけます。
FAQ
インテル® Advisor は、最新のプロセッサーの並列パフォーマンスを向上するソフトウェア・アーキテクトや開発者向けのツールのセットです。次のように開発者を支援します。
- 効率良くベクトル化を追加してチューニングできます。
- スレッド並列処理を安全かつ効率的にアプリケーションに追加できます。プロファイル作成を行いますが、単なるプロファイラーではありません。
はい。ベクトル化アドバイザーには SIMD 命令の非効率的な利用を検出するさまざまな機能が用意されています。典型的な例をいくつか示します。
- 効率メトリックが理想値よりも大幅に低い。
- ハードウェアでサポートされている命令セットより低い命令セットの使用 (例えば、インテル® アドバンスト・ベクトル・エクステンション (インテル® AVX) をサポートしているマシンでインテル® ストリーミング SIMD 拡張命令 2 (インテル® SSE2) を使用している)。
- ベクトル化の特徴の検出 (例えば、ギャザー命令とスキャッター命令の使用)。
- 不均等な/アライメントされていないデータアクセス (メモリー・アクセス・パターン解析を使用)。
- 部分的なループのベクトル化 (スカラーピールやリマインダーが多くの CPU 時間を費やしている場合)。
- その他のボトルネックは [Recommendations (推奨事項)] タブに表示されます。
ベクトル化アドバイザーには次のような機能があります。
- コンパイラーの最適化およびベクトル化レポートによる CPU 時間とベクトル化メトリックの相関性の表示。
- CPU 時間を含む、関連するループデータ (ループがベクトル化される場合、ベクトル化の制約、命令セット、ソースコード、アセンブリー・コードに関するコンパイラー診断) を 1 つの場所で調査可能。
- ループ伝播の依存性を確認する依存性解析 (プラグマでベクトル化を強制しても安全かどうか判断できます)。
- 非ユニットストライド方式の配列要素のアクセスを識別するメモリー・アクセス・パターン解析。非ユニットストライド方式のメモリーアクセスは、自動ベクトル化を妨げたり、パフォーマンスの低下につながります。
- ループのトリップカウントおよび呼び出しカウント。
- 静的/動的解析データに基づく推奨事項。
いいえ。インテル® Advisor は、コードを安心して効率的に並列化できるように支援します。
いいえ。ただし、インテル® コンパイラーを使用すると、特定のベクトル化アドバイスなどの機能が追加されます。
インテル® Advisor は、並列化 (ベクトル化およびスレッド化) に適したコード領域を識別できるように支援します。また、コード領域を並列化することが適切かどうか判断できるように支援します。多くのユーザーは、この機能を最も大きな利点の 1 つとして挙げています。適切な予測により、最も効果のある場所に開発を集中することができます。もちろん、プロファイラーを使用して手動で決定することもできます。しかし、インテル® Advisor は、大量のコアにおけるスケーラビリティーを予測し、同期のコストをモデル化して、同期エラーを検出できます。そのため、少ない労力で適切な予測を行うことができるのです。
インテル® Advisor には遅延実装ワークフローによるさまざまな利点があるためです。
- より簡単なデバッグ。インテル® Advisor は、シリアルコードにアノテーションを追加してモデル化します。インテル® Advisor で行った変更がアプリケーションの正当性に影響を与えたり、並列化実装の不具合が原因でクラッシュすることはありません。OpenMP* を直接使用した場合、実装の不具合により、プログラムが正しく動作しない、間違った答えが生成される、クラッシュするという可能性があります。正しくない並列プログラムで並列ブレークポイント・デバッガーを使用するのは容易なことではありません。多くの不具合はランダムに発生し、不具合を検出できた場合でも通常は
(根本的な原因ではなく) 問題の兆候が表示されるだけです。
- スケジュール・リスクを追加することなく並列化。アノテーションはコードの設計をインテル® Advisor に示し、パフォーマンスおよび正当性情報を得られるようにしますが、コンパイルされたコードは変更しません。そのため、並列処理の設計中に製品アップデートを継続してリリースできます。また、すべてのテストケースを継続して使用できます。最終ステップ
(並列処理の実装) に移る前に、アプリケーションが安定して正しく動作することを確認します。
- 少ない労力でパフォーマンスを評価。インテル® Advisor は、潜在的なパフォーマンス向上を最初に評価するために必要な作業量を最小化します。アムダールの法則により、最も
CPU 時間を費やしているアプリケーション領域の並列化に注目すべきことが分かっています。インテル® Advisor は、この答えを迅速に提供します。OpenMP*
では、プログラムが (正しく) 動作しない場合、単にアプリケーションを間違った位置で開始しているという答えを得るために多くの時間を費やしてデバッグを行う必要があります。
- 最適化を比較。インテル® Advisor は、5 種類の異なる並列化オーバーヘッドに対するモデルの感度解析に基づいて、並列化モデルを向上する方法を知らせます。デフォルトのプログラミング・モデルに加えて、5
種類の異なる最適化でアプリケーションがどのように動作するか評価します。これらの最適化の 1 つが優れている場合、並列モデルのどの点をチューニングすれば最適化による利点が得られるかが分かります。
- ワークフローで並列設計の初心者をガイド。チームのすべてのメンバーがエキスパートであるとは限りません。インテル® Advisor
は、チーム全体で効率的な並列化戦略に取り組む機会を提供します。エキスパートでない人はエキスパートに質問する代わりにインテル
® Advisor を使用して答えを得ることができるため、エキスパートの時間を費やすことなく、チーム全体の生産性を高めることができます。
- スケーラビリティーを解析。インテル® Advisor のアノテーションを利用すると、適合性解析により、さまざまなコア数で提案された並列ソリューションのパフォーマンスを確認することができます。並列化の設計段階で、コア数が増えたときにソリューションがスケーリングするか確認できます。OpenMP* やインテル ® スレッディング・ビルディング・ブロック (インテル® oneTBB) を利用して並列化を行う場合、利用可能なハードウェアにおけるパフォーマンスを確認することはできますが、並列実装がどのようにスケーリングするか確認することはできません。
はい。インテル® Xeon Phi™プロセッサーのパフォーマンスを引き出すには、効率的なスレッド化とベクトル化が非常に重要です。インテル® Advisor は、インテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) をサポートするプロセッサーが搭載されている場合でも搭載されていない場合でも、インテル® AVX-512 向けのベクトル化を最適化するために使用できます。
はい。インテル® Advisor は現時点では MPI 並列処理に対応していませんが、スレッドレベルの並列処理を MPI アプリケーションに追加することはできます。インテル® Advisor は、シリアルコードを解析して、並列化による最適化方法を理解できるように支援することを目指しています。MPI プログラムの各ランクは実際にはシリアル・アプリケーションです。そのため、インテル® Advisor を使用することで、並列化の可能性を判断することができます。インテル® Advisor は、MPI API の使用状況を解析しません。基本的に無視します。MPI プログラムでインテル ® Advisor を使用するには、MPI API 呼び出し間のシーケンシャル・コードに、ほかのシリアル・コード・セクションと同じようにアノテーションを追加します。次に、mpirun コマンドを使用して advixe-cl コマンドライン・ツールを起動します。advixe-cl コマンドが適用される各 MPI ランクが個々の出力結果を生成します。この出力結果をホストマシンに手動でコピーした後、advixe-guia を使用して結果を表示できます。
いいえ。インテル® Advisor はメモリー帯域幅やキャッシュの動作をモデル化しません。インテル® Advisor は、シリアル・アプリケーションを並列アプリケーションに再構成するため、シリアル・アプリケーションの構造と動作を理解できるように支援する最初のツールです。このプロセスは複数のステップからなります。適切な結果を得るには、すべてのステップを行う必要があります。最初に、インテル® Advisor を使用して、いくつかのステップを行います。その後、インテル® VTune™Amplifier およびインテル® Inspector を使用して、残りのステップを行います。 実用的な並列プログラムでは、パフォーマンス目標を達成するために並列で実行する計算量を識別する必要があります。
パフォーマンスと正当性の両方を満たす、アノテーションで表現された並列実行のモデルが用意できれば、並列フレームワークで表現することができます。並列フレームワークを利用するように再構成されたコードは、シリアル・アプリケーションではなくなります。この処理には、インテル® Advisor を使用します。この時点で、インテル® VTune™Amplifier を使用して、新しく記述されたアプリケーションを評価し、実際の並列ハードウェアにどのようにマップされるか確認します (メモリー帯域幅およびキャッシュサイズ効果を含む)。また、インテル ® Inspector を使用して、緩和シーケンシャル実行で厳密に定義されたモデルでは存在しない正当性問題と同期問題を評価します。
インテル® Advisor はシリアルコードをモデル化します。シリアル・アプリケーションでも、並列アプリケーションでも、実行されるコードの大半はシリアルです。例えば、マルチスレッドのアプリケーションでは、各スレッドはシリアルプログラムと同じです。インテル® Advisor は、これらの「同時」実行スレッドを個別のシリアル解析に分けます。 通常、インテル® Advisor を使用する前に、アプリケーションの明示的な並列化を無効にしておくと良いでしょう。この場合、スレッド数を 1 に設定して、既存の並列化されているコードを 1 つの実行スレッドにマップします。 この処理を行うことができれば、そのプログラムはシリアルです。次に、インテル® Advisor を使用してまだ並列化されていない新しいコード領域を識別します。それは 2 つのすでに並列化されている領域間のシリアルコード領域かもしれません。あるいは、すでに並列化されている領域に別のレベルの並列処理を追加している、階層的並列処理かもしれません。例えば、関数の内部ループを並列化した後、外部ループを並列化することで関数のスケーラビリティーが向上することに気付くこともあります。
いいえ。インテル® Advisor はすでに並列化されている領域をモデル化しません。プログラムがすでに並列化されている可能性を考慮せず、各シーケンシャル実行スレッドを別々に扱います。
いいえ。しかし、インテル® Advisor は、取得した情報を使用してスケジューリングと同期のオーバーヘッドを推定します。インテル® Advisor の仕事は、再構成終了後の最終的な並列プログラムのパフォーマンスを正確に予測することではありません。インテル® Advisor の目的は、効果的な並列プログラムを作成するためのパスに沿って開発者をガイドし、開発者が適切な判断を下せるように支援することです。具体的には、インテル® Advisor は常にヒューリスティックを使用して、仮定を現実的なものへ単純化します。適合性のため、クリティカルな部分 (通常は大きなタスク) のみに注目するようにタスク構造を変更し、統計を使用して小さなタスクをモデル化します。そして、正しい処理を行っているかどうか知らせるため、並列マシンの理論的な「理想」モデルを使用してプログラムの迅速な評価を行います。
インテル® Advisor のモデル化言語の利点は、完全に正しい並列アプリケーションを表現するための要件が並列フレームワークよりも単純なことです。段階的にアノテーションを使用できるため、一度にすべてのことを行う必要はありません。不完全で正しくない並列モデルから開始しても、完全で正しくなるまで時間をかけて改良できます。インテル® Advisor では、インテル® oneTBB で必要とされる広範な再構成は不要です。適切なソリューションが提案されたと確信できるまで再構成を遅らせることにより、アプリケーションに最適なソリューションを選択する前に、さまざまなソリューションを調査することができます。アノテーションはコードの設計をインテル® Advisor に示しますが、コンパイルされたコードは変更しません。そのため、並列処理の設計中に製品アップデートを継続してリリースできます。また、すべてのテストケースを継続して使用できます。最終ステップ (並列処理の実装) に移る前に、アプリケーションが安定して正しく動作することを確認します。
いいえ。これは自動コード再構成の良い研究対象になるでしょう。インテル® Advisor の目的は、解析を自動化して開発者が生産的に並列化を行えるように支援することです。いずれはすべての処理を自動化したいと考えていますが、現時点では開発者が行ったほうが適切な処理がまだいくつかあります。
通常、最高レベルの解析ではアプリケーションの実行コードパスに存在するメモリーエラーやスレッド化エラーが発見されますが、インテル® Advisor がプログラムのスレッド化エラーをすべて発見できるという保証はありません。
いいえ。解析関連のコード/データはランタイムにプログラムのアドレス空間に追加されます。
いいえ。現時点ではインテル® Advisor はプロセスのアタッチやデタッチはサポートしていません。プロセスのマルチスレッド・バグを検出するには、インテル® Advisor がプログラムの開始時点から同期イベントと関連するアノテーションを監視する必要があります。もちろん、解析を開始した後、いつでもインテル® Advisor を手動で停止できます。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。