概要
低い精度でのニューラル・ネットワークの量子化と実行は、精度を維持しつつ大幅な高速化を達成できる最適化手法として幅広く採用されています。ほとんどの場合、計算精度を 8 ビットに下げるためモデルの再トレーニングは不要で、そうでない場合も微調整のみが必要になります。一方、量子化は大幅なスピードアップとシステム・スループットの向上をもたらし、これは展開時の利点となります。
インテル® ディストリビューションの OpenVINO™ ツールキットは、エッジからクラウドまで、ハイパフォーマンスなディープラーニング推論により、アプリケーションとアルゴリズムを高速化するソフトウェア・ツール・スイートです。2019 年 10 月にリリースされた以前のバージョンでは、レイテンシーを向上しつつ、モデルを再トレーニングせずに低い精度へ変換できるように、トレーニング後のモデルを量子化する新しい手法が導入されました (英語)。最新バージョン 2020.1 (英語) では、低い精度の量子化の開発者体験をさらに合理化し、インテル® アーキテクチャー・ベースのプラットフォーム (英語) でディープラーニングのパフォーマンスを最適化するため、引き続き改良が行われています。インテル® ディストリビューションの OpenVINO™ ツールキットは、汎用計算向けのインテル® Xeon® スケーラブル・プロセッサーとインテル® Core™ プロセッサー、メディアおよびビジョン・アプリケーション専用のインテル® Movidius™ VPU、柔軟なプログラミング・ロジックとスケーリングを提供するインテル® FPGA など、広範なインテル® ハードウェア上で推論をスピードアップします。
主な改善点:
トレーニング後の最適化ツール (POT): ランタイム環境への展開時に微調整を必要とせず二度手間にならない、中間表現 (略称 IR、インテル® ディストリビューションの OpenVINO™ ツールキットの推論エンジンと互換性のある組込み表現) 形式でのモデルの量子化を可能にする、完全に再設計されたモデル・キャリブレーション・ツールです。
量子化を考慮したトレーニング (QAT): インテル® ディストリビューションの OpenVINO™ ツールキットと互換性のある量子化モデルを生成するサードパーティー・コンポーネントのセットです。このリリースでは、PyTorch* ベースのソリューションが追加されました。
向上した INT8 ランタイム: インテル® アーキテクチャー (英語) 上で最適なパフォーマンスを引き出すように、トレーニング後の最適化または量子化を考慮したトレーニングを介して取得された IR 表現の量子化モデルを正しく解釈します。
バージョン 2020.1 (英語) のニューラル・ネットワークの量子化と低い精度での実行に関する主な変更について詳しく見ていきましょう。
ニューラル・ネットワークの量子化
量子化は、浮動小数点演算を整数演算に置き換えます。浮動小数点値の範囲は、実際の活性化と重みの範囲と比較して非常に大きいため、典型的な量子化アプローチは、活性化と重みの値の範囲を離散化されたポイントのセットで表します。その結果、INT8 量子化では、値の範囲は 8 ビットで表現可能な値の数に応じて 256 値で表現されます。いくつかの量子化モードが可能であり、そのうちの 2 つが主流と考えられています (図 1)。
この 2 つのモードの主な違いは、対称量子化はハードウェア・フレンドリーでより大きなスピードアップをもたらし、非対称量子化は追加の計算とハードウェア固有の微調整や考慮事項を必要とします。ただし、非対称モードは、潜在的にオリジナルの範囲をより正確に表現して精度を向上します。実際には、対称量子化は CPU と統合 GPU でモデルを高速化するベースラインと考えられており、非対称量子化は非 ReLU モデル (ELU、PReLU、GELU など) の量子化など、特別なケースに使用できます。
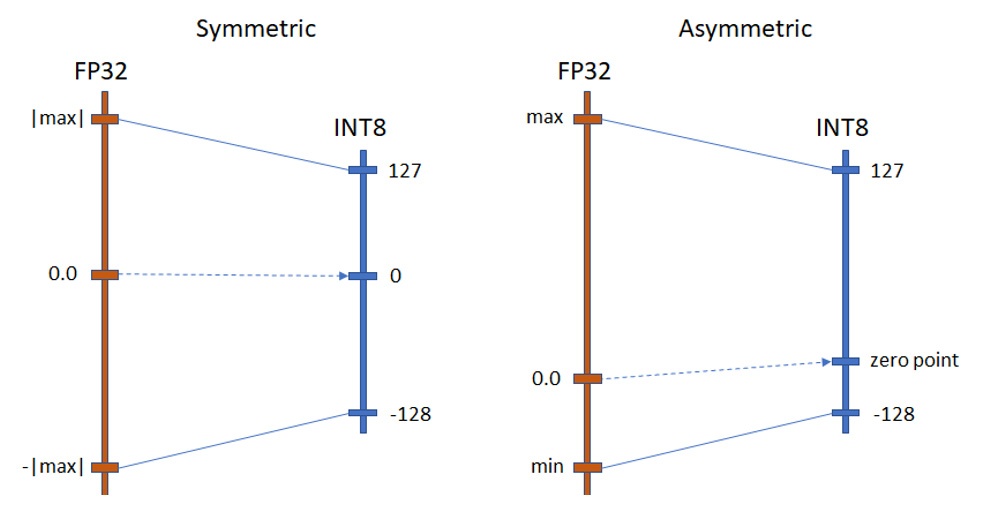
図 1. 量子化モード
トレーニング後の最適化ツール
トレーニング後の最適化ツール (POT) は、以前のキャリブレーション・ツールを再設計したもので、インテル® ディストリビューションの OpenVINO™ ツールキット 2020.1 でリリースされました。このツールの主な目的は、トレーニング後にモデルの最適化を実行することです。以前の記事 (英語) で述べたとおり、トレーニング後の最適化は、微調整を必要しない合理的な開発プロセスであるため魅力的です。
ツールの再設計の主な目的は、次のとおりです。
複数の最新の量子化手法をサポート (以前は単一の手法のみサポート)。
CPU、iGPU、VPU、から FPGA まで、広範なインテル® アーキテクチャーにわたるクロスプラットフォームの柔軟性とスケーラビリティーにより、各ターゲット・ハードウェアで最適なパフォーマンスを実現。ターゲットの性能に応じて、対称と非対称モードの量子化をサポートします。
コンピューター・ビジョン、オーディオ、音声、自然言語処理、推奨システムを含む複数のディープラーニング・ワークロードへのサポートの拡大。
サポートするモデル、パフォーマンスの最大化、メモリーの割り当てと使用のサポートと最適化の開発者体験を合理化。
本リリースの主要目的は、インテル® ディープラーニング・ブースト対応インテル® Xeon® スケーラブル・プロセッサーを含む、次世代のインテル® アーキテクチャーでサポートされる INT8 量子化です。INT8 は、ハードウェアとソフトウェアの両方の改善による複合的なパフォーマンスの向上をもたらします。すべての量子化機能は、コマンドラインまたはディープラーニング・ワークベンチ (英語) と呼ばれるインテル® ディストリビューションの OpenVINO™ ツールキットのビジュアル・インターフェイスから利用できます。一般的なフローは同じです。ツールは、トレーニング済みモデルの中間表現 (IR) とデータセットを入力として受け取り、量子化した IR を出力します。そして、量子化された IR は、ほかの IR と同じ方法で推論エンジンによって処理されます。これにより、低い精度のアプリケーションを容易に展開できます。
トレーニング後の最適化ツールは、重みと活性化を量子化した後に精度を復元するのに役立つ、複数の量子化とアルゴリズムを提供します。潜在的にアルゴリズムは、1 つまたは複数のモデルの量子化に適用可能な独立した最適化パイプラインを形成できます。バージョン 2020.1 では、以下に定義する 2 つの実証済みのアルゴリズムの組み合わせを提供することに重点を置いています。
以下は、この 2 つのパイプラインで使用される手法の説明です。
デフォルトの量子化パイプライン
デフォルトの量子化パイプラインは、ニューラル・ネットワークの高速で正確な 8 ビットの量子化を行うように設計されています。このパイプラインは、モデルに順次適用される 3 つのアルゴリズムからなります。
- 活性化チャネルのアライメント: 量子化の前段階として使用され、量子化誤差を軽減するため、畳み込み層の出力の活性化の範囲をアライメントします。
- MinMax 量子化: 指定されたハードウェア・ターゲットに基づいてモデルグラフに FakeQuantize 操作を自動挿入して、キャリブレーション・データセットで収集された統計を使用してそれらを初期化する量子化手法です。
- バイアス補正: 全体の誤差を不偏にするため、層の量子化誤差に基づいて畳み込み層と全結合層のバイアスを調整します。
精度を考慮した量子化パイプライン
精度を考慮した量子化パイプラインは、事前定義された精度低下の範囲 (例えば 1%) を維持しつつ、正確な 8 ビットの量子化を実行するように設計されています。一部の層がオリジナルの精度に戻される可能性があるため、デフォルトの量子化パイプラインと比較してパフォーマンスが低下する場合があります。一般に、精度を考慮した量子化パイプラインは次のステップで構成されます。
- 最初に、デフォルトの量子化パイプラインを使用してモデルを完全に量子化します。
- 次に、量子化された完全な精度のモデルと検証セットのサブセットを比較して、事前定義された精度条件に一致しないものを見つけ、不一致に基づいてランキングのサブセットを抽出します。
- 各量子化層と精度低下の関連性を取得するため、層ごとのランキングを実行します。
- このランキングに基づいて、最も「問題のある」層をオリジナルの精度に戻します。そして、新しい精度低下を取得するため、完全な検証セットで取得したモデルを評価します。
- すべての事前定義された精度条件が満たされると、アルゴリズムは完了します。そうでない場合は、引き続き、次の「問題のある」層をオリジナルの精度に戻します。
- 精度を戻しても精度が向上しない、あるいは低下する場合があります。その場合は、ステップ 3 のランキングを再度実行します。
ほかのフレームワークとの比較結果とパフォーマンス・ベンチマークは、docs.openvinotoolkit.org (英語) を参照してください。
インテル® ディストリビューションの OpenVINO™ ツールキットと互換性のある量子化を考慮したトレーニング (QAT)
OpenVINO™ コミュニティー (英語) にトレーニング機能を提供するため、インテルは OpenVINO™ Training Extensions (英語) の Neural Network Compression Framework (NNCF) (英語) で低い精度のモデルをサポートしています。これらのトレーニング拡張は、ディープラーニング・モデルの開発を合理化して、推論までの期間を短縮することを目的としています。NNCF は、PyTorch* フレームワーク (英語) 上に構築されており、さまざまなユースケースの広範なディープラーニング・モデルをサポートします。また、異なる量子化モードと設定をサポートする、量子化に対応したトレーニングを実装しています。
NNCF の重要な機能の 1 つは、モデルがラップされており、量子化対応の微調整に必要な追加の層が挿入されている場合の自動グラフ変換です。これにより量子化プロセスが簡素化され、量子化フローのエキスパートでなくても量子化を行うことができます。圧縮ネットワークを生成するためカスタム・トレーニング・パイプラインを変更するには、通常、PyTorch* コードに 10 ~ 15 行を追加する必要があります。ほとんどの場合、いくつかのエポックを微調整した後、モデルはオリジナルの FP32 精度を復元できます。微調整が完了したら、通常のインテル® ディストリビューションの OpenVINO™ ツールキットのフロー (モデル・オプティマイザーと推論エンジン) を介して使用可能な ONNX* 形式にモデルをエクスポートできます。
NNCF QAT とサポートされるモデルの詳細は、GitHub* (英語) にあるフレームワークのドキュメントを参照してください。
低い精度のランタイム
2 つの異なる量子化パスは、統一されたモデル表現と実行の課題を表しています。インテル® ディストリビューションの OpenVINO™ ツールキットは、フレームワークおよび FakeQuantize (英語) プリミティブを使用したトレーニング後の最適化により量子化されたモデルを表します。入力範囲を任意の出力範囲にマップできるため、量子化、逆量子化、再量子化、量子化/逆量子化など、異なるタイプの操作を表すことができます。つまり、QAT またはトレーニング後の最適化によってモデルを取得したかどうかに関係なく、この操作でほとんどの量子化モデルを表現できます。
量子化ネットワークでいくつかのグラフ変換パスを実行して、低い精度の推論に適した形式に変換する必要があります。FakeQuantize プリミティブは、2 つの連続する操作 (量子化と逆量子化) を表します。量子化は [0, 255] の範囲の整数値を生成し、逆量子化はこれらの値を浮動小数点範囲に戻した値を返します。最初の段階では、ランタイムは FakeQuantize をこの 2 つの連続する操作に分割します。第 2 段階では、逆量子化を実行パスに渡し、同等の数学的変換を使用してほかの層と融合することで、逆量子化の最適化を試みます。最後の段階では、パターン固有の最適化が適用されます。変換パス・コンポーネントは、すべてのターゲットデバイスに共通ですが、特定のデバイスの機能を考慮して構成できます。
まとめ
インテル® ディストリビューションの OpenVINO™ ツールキット 2020.1 の新しいトレーニング後の最適化ツールは、モデルの量子化により精度をあまりあるいは全く損なうことなく、パフォーマンスを大幅に向上できます。この強化されたパイプラインは、モデルサイズを縮小し、モデルの再トレーニングや微調整を必要としない合理的な開発プロセスを実現します。インテル® ディストリビューションの OpenVINO™ ツールキットを使用して、インテル® アーキテクチャー・ベースのプラットフォームでディープラーニングの推論を高速化してください。
著作権と商標について
インテルは、明示されているか否かにかかわらず、いかなる保証もいたしません。ここにいう保証には、商品適格性、特定目的への適合性、および非侵害性の黙示の保証、ならびに履行の過程、取引の過程、または取引での使用から生じるあらゆる保証を含みますが、これらに限定されるわけではありません。本資料は、明示されているか否かにかかわらず、また禁反言によるとよらずにかかわらず、いかなる知的財産権のライセンスも許諾するものではありません。
インテル® テクノロジーの機能と利点はシステム構成によって異なり、対応するハードウェアやソフトウェア、またはサービスの有効化が必要となる場合があります。詳細については、OEM または販売店にお問い合わせいただくか、http://www.intel.co.jp/ を参照してください。絶対的なセキュリティーを提供できる製品はありません。
最適化に関する注意事項: インテル® コンパイラーでは、インテル® マイクロプロセッサーに限定されない最適化に関して、他社製マイクロプロセッサー用に同等の最適化を行えないことがあります。これには、インテル® ストリーミング SIMD 拡張命令 2、インテル® ストリーミング SIMD 拡張命令 3、インテル® ストリーミング SIMD 拡張命令 3 補足命令などの最適化が該当します。インテルは、他社製マイクロプロセッサーに関して、いかなる最適化の利用、機能、または効果も保証いたしません。本製品のマイクロプロセッサー依存の最適化は、インテル® マイクロプロセッサーでの使用を前提としています。インテル® マイクロアーキテクチャーに限定されない最適化のなかにも、インテル® マイクロプロセッサー用のものがあります。この注意事項で言及した命令セットの詳細については、該当する製品のユーザー・リファレンス・ガイドを参照してください。注意事項の改訂 #2010804
Intel、インテル、Intel ロゴ、Intel Core、Xeon、Movidius、OpenVINO は、アメリカ合衆国および / またはその他の国における Intel Corporation またはその子会社の商標です。
* その他の社名、製品名などは、一般に各社の表示、商標または登録商標です。
© 2020 Intel Corporation.