初めに
AI やデータ サイエンスが急速に進化しており、これにより増え続けるデータの所得や、日々複雑化し続けるアイディアやソリューションを導き出すことができるようになりました。
一方で、これらの進歩は、価値の抽出からシステム エンジニアリングへと焦点を移しつつあることがわかります。また、ハードウェアの性能は、それを正しく活用する方法を学ぶよりも速いスピードで成長しているのかもしれません。
この傾向は、いわゆる “データ エンジニア” という新しいポジションを追加する必要があるか、データ サイエンティストがデータ サイエンスの中核部分であるインサイトの生成に注力する代わりに、インフラ関連の問題に対処する必要があるかのどちらかです。この主な理由の 1 つは、もともとソフトウェア エンジニアではないデータ サイエンティストのために最適化されたデータ サイエンスと機械学習のインフラが存在しないことです。これらは、2 つの別々の、時には重複するスキル セットと考えることができます。
私たちは、データ サイエンティストが習慣で動く人々であることを知っています。彼らは、pandas、Scikit-learn、NumPy、PyTorchなど、Python データ スタックで慣れ親しんだツールを好みます。しかし、これらのツールは、並列処理やテラバイト単位のデータには不向きであることが多いのです。
Anaconda とインテルは、データ サイエンティストの最も重要かつ主要な問題、つまり使い慣れたソフトウェア スタックと API をいかにしてスケーラブルかつ高速にするかという問題を解決するために協力しています。
この記事では、Anaconda のデフォルト チャンネル (および conda-forge) から入手可能になったインテル® oneAPI AI アナリティクス・ツールキット (AI キット) の一部である Modin (別名インテル® ディストリビューションの Modin*) を紹介しています。
Pandas だけでは不十分である理由
“業界標準” とはいえ、pandas は本質的に多くの場合シングル スレッドであり、巨大なデータに対する操作は遅くなります (あるいは、メモリーに収まらないデータ セットに対しては動作しなくなることもあります)。
この問題を解決するための代替案 (Dask、pySpark、vaex.io など) は他にもたくさんありますが、それらのライブラリはいずれも pandas と完全に互換性のあるインターフェースを提供しておらず、ユーザーは自分の作業負荷をそれに応じて “修正” しなければなりません。
Modin はエンド ユーザーとして何を提供するのか?Modin は、”ツールはデータ サイエンティストのために働くべきで、その逆ではない” という考え方に忠実であろうとしています。”import pandas as pd” ステートメントを “import modin.pandas as pd “に変更するだけで、多くのユース ケースでより良いスケーラビリティを得ることができます。
Modinが提供するもの
“pandas のワーク フローを X フレーム ワークに書き換える” というステップを省くことで、インサイトの開発サイクルを高速化することが可能です。
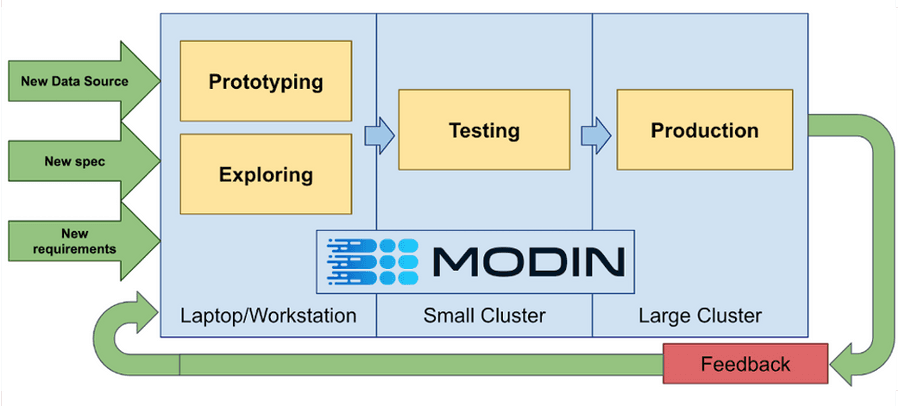
図1. Modinを継続的な開発サイクルで活用する。
Modin でハードウェアをより有効に活用する方法は、データ フレームをグリッド分割することです。これにより、セル単位、列単位、行単位など、特定の操作を並列分散方式で実行することができます。
特定の操作については、OmniSci エンジンの実験的な統合を利用して、マルチコアのパワーをより有効に活用することが可能です。
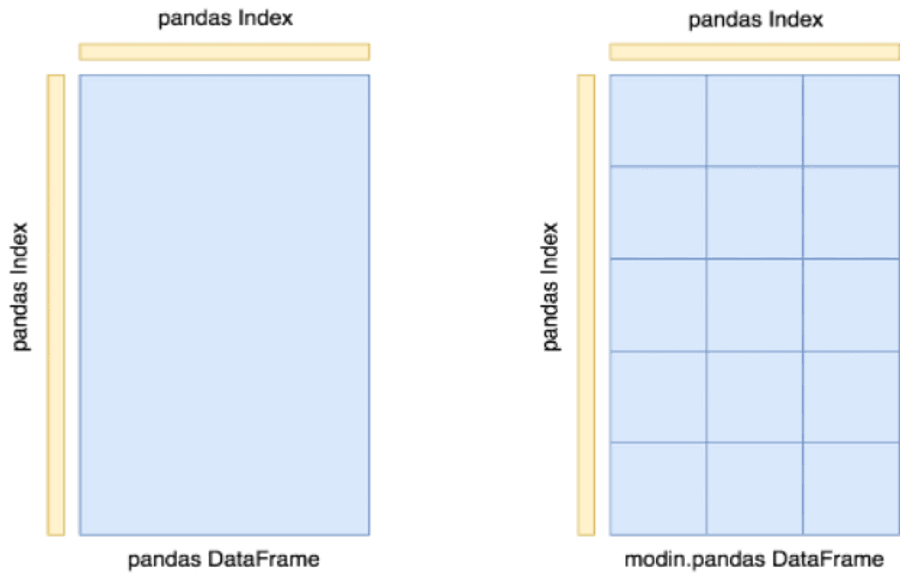
図2. pandas DataFrame と Modin DataFrame の比較。
AI キット または Anaconda デフォルト (または conda-forge) チャネルから Modin をインストールすると、実験的でさらに高速な OmniSci バックエンドも、いくつかの簡単なコード変更で有効化できます。
import modin.config as cfg
cfg.Engine.put('native')
cfg.Backend.put('omnisci')
import modin.experimental.pandas as pd
ベンチマーク
ベンチマークを見てみましょう。
異なる Modin エンジンの詳細な比較については、コミュニティが測定したマイクロ ベンチマークを参照してください。Modin リポジトリへのコミットに対するさまざまなデータサイエンス操作のパフォーマンスを追跡します。
この記事では、インテル® Xeon® 8368 Platinum ベースのサーバー (以下のハードウェア情報を参照) 上で、Modinを介してOmniSci を使用して、よりエンドツーエンドに関連する大規模なベンチマークを実行します。
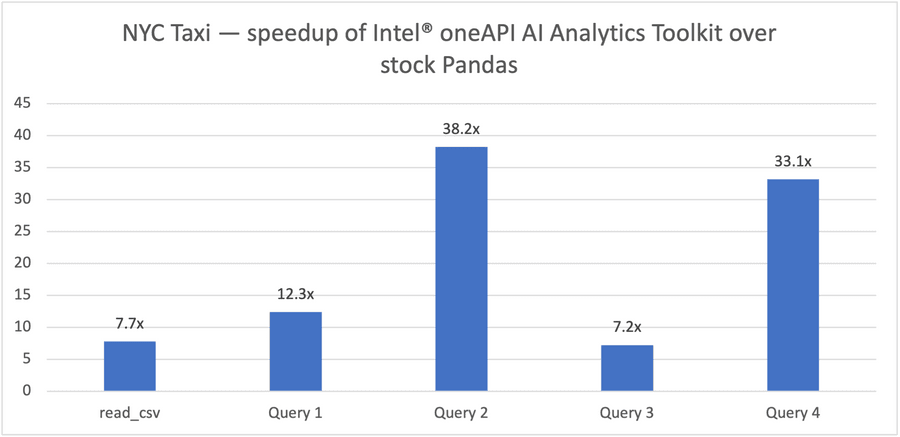
図3. NYCタクシーの走行 (200Mレコード、79.2GBの入力データセット)

図4. 国勢調査の実行 (21Mレコード、2.1GB入力データセット)
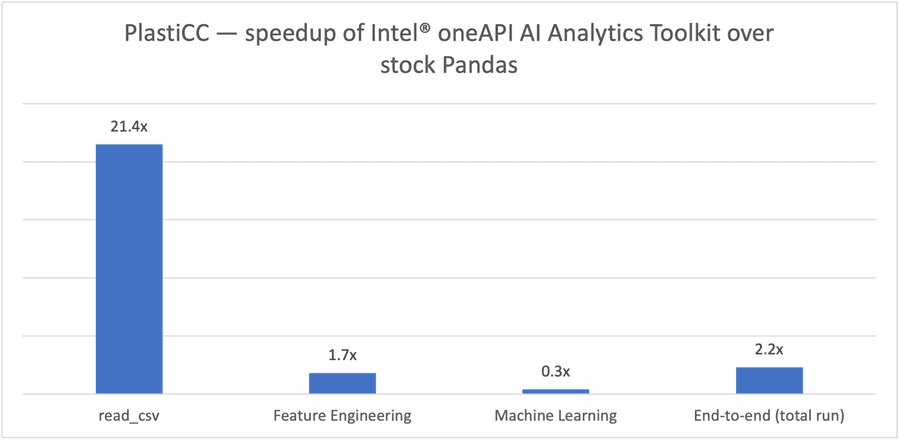
図5. PlastiCC の実行 (460M レコード、20GB 入力データセット)
ハードウェア情報:
1x node, 2x 第3世代 インテル® Xeon 8368 Platinum on C620 board、512GB (16 slots/ 32GB/ 3200) トータル DDR4 メモリー、microcode 0xd0002a0、HT on、Turbo on、Centos 7.9.2009、3.10.0-1160.36.2.el7.x86_64、1x インテル® 960GB SSD OSドライブ、3x インテル® 1.9TB SSD データドライブ
ソフトウェア情報:
Python 3.8.10、Pandas 1.3.2、Modin 0.10.2、OmnisciDB 5.7.0、Docker 20.10.8,
インテルによるテストは 2021年 10月 5日に行われました。
1 つのノードで動作させるだけではデータ量が足りない場合、Modin は比較的簡単な設定でクラスタでの動作をサポートしています(Ray-driven クラスタの設定はこちらを参照、Dask の設定はこちらを参照してください)。
実験的な XGBoost の統合も利用でき、特別な設定なしに自動的に Ray ベースのクラスタを利用できます。
これらの新しい情報をもとに、今すぐ Anaconda で Modin とインテル® oneAPI AI アナリティクス・ツールキットのインストールをお試しください。
Anaconda について詳細はこちら から。
インテル® ディストリビューションの Modin* を含むインテル® oneAPI AI アナリティクス・ツールキットについてはこちらからご覧いただけます。
お知らせ・免責事項
- 性能は使用状況や構成などにより異なります。詳しくは、こちらをご覧ください。
- パフォーマンス結果は、コンフィギュレーションに示された日付でのテストに基づいており、公開されているすべてのアップデートが反映されていない可能性があります。詳細については、コンフィギュレーションの公開をご覧ください。
- 絶対的に安全な製品・部品はありません。
- お客様の費用と結果は異なる場合があります。
- インテルのテクノロジは、ハードウェア、ソフトウェア、またはサービスのアクティベーションが必要な場合があります。
参照記事: