モニタリング (監視) とオブザーバビリティ (観測可能性) は混同されがちです。この 2 つの用語の定義は似ていますが、DevOps では大きく異なる意味を持ちます。プロジェクトに最適な品質保証とバグ追跡ソリューションを選択し、リリース前に潜在的なバグをできるだけ潰すためには、これらの違いを理解することが非常に重要です。
モニタリングとオブザーバビリティの類似点と相違点、そしてこの 2 つをどのように組み合わせれば、リリース後に見つかるバグの数と深刻度を最小限に抑えられるかを見ていきましょう。
モニタリングとオブザーバビリティは、定義は似ていますが、DevOps では全く異なる概念です。
モニタリングとオブザーバビリティの定義
モニタリング システムは、事前に定義されたメトリックとログのセットを監視して、既知の障害モードを検出します。たとえば、潜在的なスケーラビリティの問題を発見するため、応答時間のメトリックを確認します。応答時間が長くなったら、新しいサーバーを起動して負荷を軽減できます。また、長期的な傾向から、将来のパフォーマンス問題を予測することも可能です。
オブザーバビリティ システムは、外部出力からシステム内部の状態を理解するのに役立ちます。オブザーバビリティ システムは、モニタリング機能に加え、さらに一歩進んで、アプリケーション スタック内の問題の根本原因を突き止めます。つまり、いつ何が起こったかだけでなく、なぜ起こったか、そしてどのように修正できるかを理解するのに役立ちます。
オブザーバビリティはまた、既知でない問題も特定します。たとえば、モニタリング システムは応答時間の増加を検知しますが、オブザーバビリティはその根本原因がデータベース クエリであることを特定できます。その結果、新たなサーバー容量に投資することなく、単純なクエリ変更の実装だけで済む可能性があります。
オブザーバビリティの「3 つの柱」
オブザーバビリティは、ログ、メトリック、トレース (追跡) という 3 つの柱で構成されています。メトリックを監視して問題を検出する一方、ログとトレースは、ネットワークとアプリケーションの両方を分析してこれらの問題の根本原因を診断するのに役立ちます。バグを効果的に診断し解決するため、オブザーバビリティ システムには 3 つの柱がすべて含まれている必要があります。
- ログ: ログはタイムスタンプと、問題発生時に何が起こったのかについての洞察を提供する個別のイベントの不変の記録です。可視化して簡単にログを解析したり、構造化されたログを使用して情報をすばやく検索できます。
- メトリック: メトリックは、時間の経過とともに集計できるカウントや測定値です。たとえば、メトリックは、メモリ使用量レベルやリクエスト スループットを追跡し、ベースラインを確立し、異常な動作を簡単に見つけられるようにします。
- トレース: トレースは 1 つのリクエストの詳細な概要を提供し、エラーの原因となったコンポーネントを特定します。アプリケーション スタック全体でリクエストを監視することで、何が問題を引き起こしているのかを迅速に診断したり、パフォーマンスのボトルネックを特定できます。
オブザーバビリティ + モニタリング
モニタリングとオブザーバビリティは相互に排他的な概念ではなく、すべてのオブザーバビリティ システムは、モニタリング機能を備えています。モニタリングは問題を検出し、オブザーバビリティはその理由を理解するのに役立ちます。しかし残念なことに、複雑なシステムでは、オブザーバビリティ システムの構築が困難です。
いくつかのベスト プラクティスを以下に示します。
- 主要メトリックの特定: CPU 使用率、ストレージ容量、1 秒あたりのトランザクション数など、アプリケーションの主要なメトリックを特定することから始めます。次に、これらのメトリックと経時的な傾向をモニタリングする追跡システムをセットアップします。
- ログの構造化: YAML や JSON のような言語を使って、解析しやすい構造化されたログを実装します。そして、必要な情報を見つけるため、ログをすばやく可視化し、検索できる OpenTelemetry のようなソリューションを使用します。
- 効果的なトレース: 問題の根本原因をすばやく突き止めるため、アプリケーション スタックと連携可能な追跡ソリューションを探します。最適なソリューションは、バグ レポートを自動的に作成してチームの他のメンバーに通知できます。
- プロセスの自動化: 継続的インテグレーション/継続的デリバリー (CI/CD) は、オブザーバビリティの自動化を容易にします。たとえば、新しいリリースの最小エラーしきい値を設定し、安定性スコアが基準値を下回る場合はリリースを保留できます。
BugSnag を使用したアプローチ
BugSnag は、強力なフルスタックのオブザーバビリティ ソリューションです。APM ツールのような従来のモニタリング ソリューションとは異なり、豊富なエンドツーエンドの診断を提供し、あらゆるエラーの再現を支援します。さらに、BugSnag のユニークなツールは、バグの優先順位付け、バグ修正と新機能開発のバランス、チームのコミュニケーションの効率化を支援します。
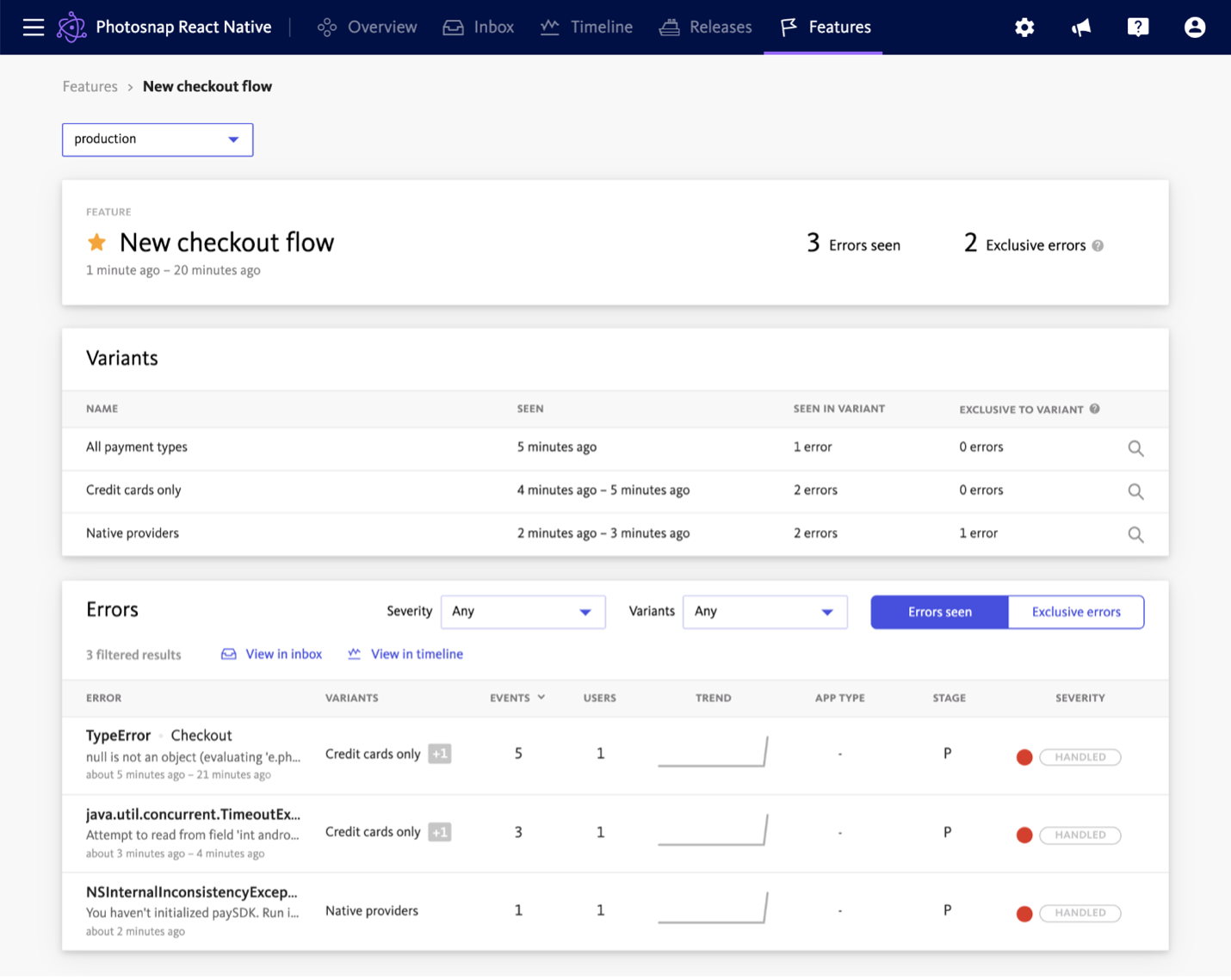
BugSnag の Features Dashboard により、機能フラグや実験が有効なときに発生したエラーを簡単に識別できます。
出典: BugSnag
プロセスには、いくつかのステップがあります。
- 安定性: クラッシュのないリリースにおけるユーザー セッションの割合を測定する安定性目標を設定します。これにより、新しいリリースが最低限の安定性要件を満たしているか、あるいはトラブルシューティングのためにリリースを保留する必要があるかを迅速に判断できます。
- 優先順位付け: 影響を受けるユーザー数を考慮して、深刻度に基づいてバグに優先順位を付けます。さらに、ブックマークを使用して、VIP 顧客に影響するエラーや SLA に影響するエラーを特定できます。これにより、最も重要なバグに集中できます。
- 修正: スタックトレースにより、エラーにつながった可能性のあるユーザー アクションを追跡し、問題を引き起こしているコード行を簡単にピンポイントで特定できます。さらに、ブックマークに基づいて関連チームに自動的に通知します。必要な通知のみを受け取ることで、開発者の通知疲れを防ぎます。
まとめ
モニタリングとオブザーバビリティは DevOps の重要な概念ですが、誤解されがちです。モニタリングが発生したエラーを追跡するのに対して、オブザーバビリティはエラーの根本原因を特定し、問題の解決を支援するのに役立ちます。たとえば、トレースを使用して、ネットワークレベルのスローダウンの原因となっているアプリケーション コードを特定できます。
バグのないアプリケーションはありません。常に何らかの理由で処理に失敗したり、不具合が発生します。成功の鍵は、問題が発生しないことを祈るのではなく、何が問題なのかを理解し、修正する価値のあるものを判断することです。
BugSnag のようなオールインワンツールを使用することで、モニタリングとオブザーバビリティ ツールを組み合わせて、バグの追跡と修正を効率化できます。これは、問題を発見し、バグのトラブルシューティングを行い、ユーザーにとって長期的な価値を構築するため最も影響のある活動に集中できる、最も簡単な方法であると同時に、問題を適切なタイミングで、適切な開発者に通知して修正することを容易にします。
BugSnag 製品に関する詳細、無料評価版は、こちら。
この資料は、Bugsnag の Web サイトで公開されている「What’s the Difference Between Observability & Monitoring?」の日本語参考訳です。