検索拡張生成 (Retrieval-Augmented Generation、以下「RAG」)は、モデルが外部のナレッジベースにアクセスして活用できるようにすることで、会話型 AI を強化してきました。この記事では、LangChain と Panel を使用して RAG チャットボットを構築する方法について掘り下げ、以下について追究していきます。
- 検索拡張生成 (RAG) とは?
- LangChain で RAG アプリケーションを開発する方法
- RAG アプリケーションに Panel のチャット インターフェイスを使用する方法
このブログ記事を読み終える頃には、以下のような RAG チャットボットを構築できるようになるでしょう。
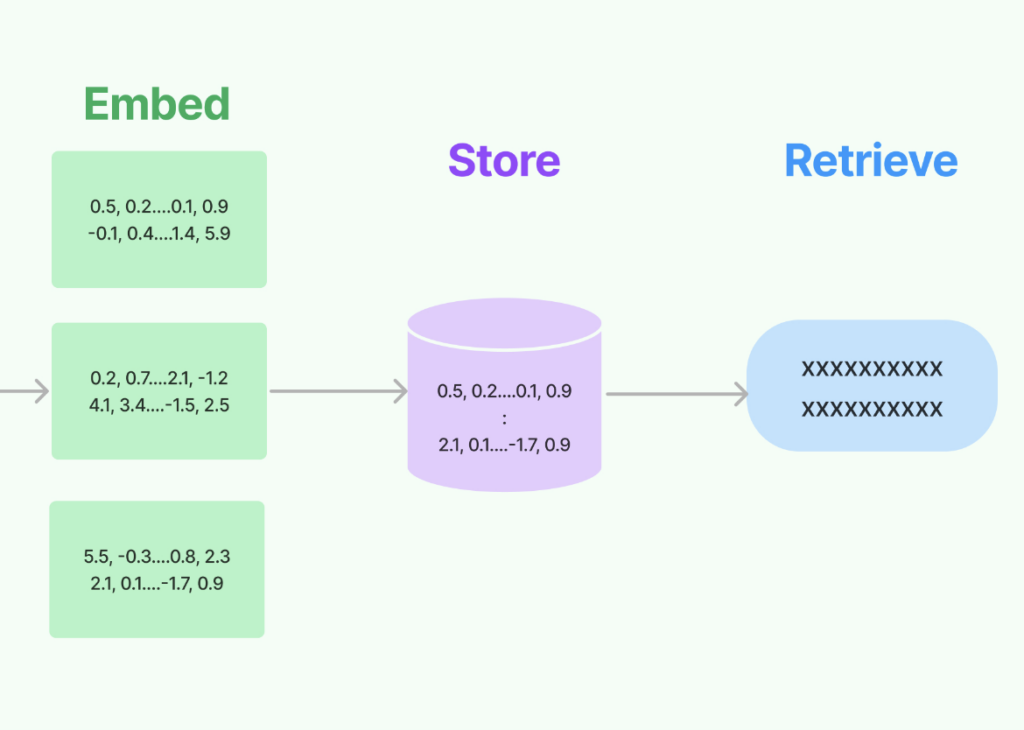
検索拡張生成 (RAG) とは?
質問に答える際に自分のデータ コレクションを活用できるチャットボットの構築にご興味がおありですか?RAG は、会話型 AI システムで応答を生成したり、外部の知識を活用してコンテンツを作成したりするために、事前に訓練された言語モデルと情報検索システムの長所を組み合わせた AI のフレームワークです。ナレッジソースからの関連情報の検索と、検索された情報に基づく応答の生成を統合しています。
典型的な RAG のセットアップは、以下のようになっています。
- 検索: ユーザーのクエリまたはプロンプトが与えられると、システムはナレッジ ソース (テキスト埋め込みを含むベクトル ストア) を検索し、関連するドキュメントまたはテキスト スニペットを検出します。検索コンポーネントは通常、類似性または関連性スコアリングの形式を採用して、ナレッジ ソースのどの部分が入力クエリに最も適切かを判断します。
- 生成: 検索されたドキュメントやスニペットは、大規模な言語モデルに提供され、言語モデルはそれらをより詳細で事実に基づいた、関連性の高い応答を生成するための追加のコンテキストとして使用します。
GPT-4 のような標準的な言語モデルは、リアルタイムまたは学習後の外部情報に直接アクセスすることができないため、事前に学習された言語モデルだけでは、正確または十分に詳細な応答を生成するために必要な情報を持っていない可能性がある場合、RAG は特に有用となります。
基本設定
RAG アプリケーションのビルドを始める前に、 panel 1.3 ならびに jupyterlab、pypdf、chromadb、tiktoken、langchain、 openai などの必要なパッケージをインストールする必要があります。
この記事にあるコードはすべて GitHub にて参照できます。
LangChain で RAG アプリケーションを開発する方法
実は、LangChain で RAG を行う方法は複数あります。詳細はこちら (英語) をご参照ください。この例では、RetrievalQA chain を使います。このプロセスにはいくつかのステップがあります。
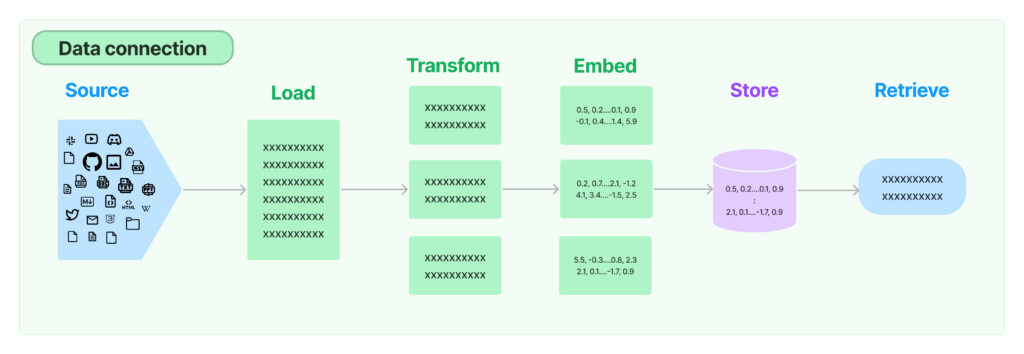
- ドキュメントの読み込み: LangChain は、PDF ファイル、JSON ファイル、ファイル ディレクトリ内の Python ファイルを扱う、複数の組み込みドキュメント ローダーを提供します。 LangChain の PyPDFLoader を使って PDF をシームレスにインポートできます。
- ドキュメントをチャンクに分割: ドキュメントが長い場合、テキストをチャンクに分割する必要がありますが、その方法はいろいろあります。ここでは、最もシンプルな
CharacterTextSplitterを使って文字数を基準に分割し、チャンクの長さを測ってみましょう。
- テキストの埋め込みを作成: テキストのチャンクは埋め込みによって数値ベクトルに変換され、セマンティック検索のようにテキスト データを計算効率の高い方法で扱うことができるようになります。この作業には、OpenAI のような埋め込みモデル プロバイダーを選択できます。
- ベクトル ストアの作成: 次に、埋め込みベクトルをベクトル ストアに保存する必要があります。これにより、クエリ時に関連するベクトルを検索して取得できるようになります。
- 検索インターフェイスの作成: ベクトル ストアを検索インターフェイスで公開できます。テキストを検索するには、類似性検索を使用するための検索タイプ (”similarity” など) を選択できます。検索オブジェクトでは、質問ベクトルに最も類似したテキストチャンクのベクトルを選択します。k=2 は、最も関連性の高い上位 2 つのテキスト チャンクのベクトルを見つけるのに役立ちます。
- 質問に回答するための RetrievalQA チェーンを作成: RetrievalQA チェーンは、大規模な言語モデルと検索インターフェイスをチェーン化します。チェーンのタイプを “stuff”、”map reduce”、”refine”、”map_rerank” の 4 つのオプションの 1 つとして定義することもできます。
- デフォルトの chain_type=”stuff” は、ドキュメントのすべてのテキストをプロンプトに取り込みます。
- “map_reduce” タイプはテキストをグループに分け、各バッチごとにLLM に質問を投げかけ、各バッチからの返答に基づいて最終的な答えを導き出します。
- “refine” タイプは、テキストをバッチに分割し、最初のバッチを LLM に提示し、2 番目のバッチとともに答えを LLM に提出します。すべてのバッチを処理することで、答えが徐々に洗練されます。
- “map-rerank” タイプは、テキストをバッチに分け、それぞれを LLM に提出し、どれだけ包括的に質問に答えているかを示すスコアを返し、各バッチからの最もスコアの高い回答に基づいて最終的な回答を決定します。
import os
from langchain.chains import RetrievalQA
from langchain.document_loaders import PyPDFLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.llms import OpenAI
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
os.environ["OPENAI_API_KEY"] = "Type your OpenAI API key here"
# load documents
loader = PyPDFLoader("example.pdf")
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(
search_type="similarity", search_kwargs={"k": 2}
)
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type="map_reduce",
retriever=retriever,
return_source_documents=True,
verbose=True,
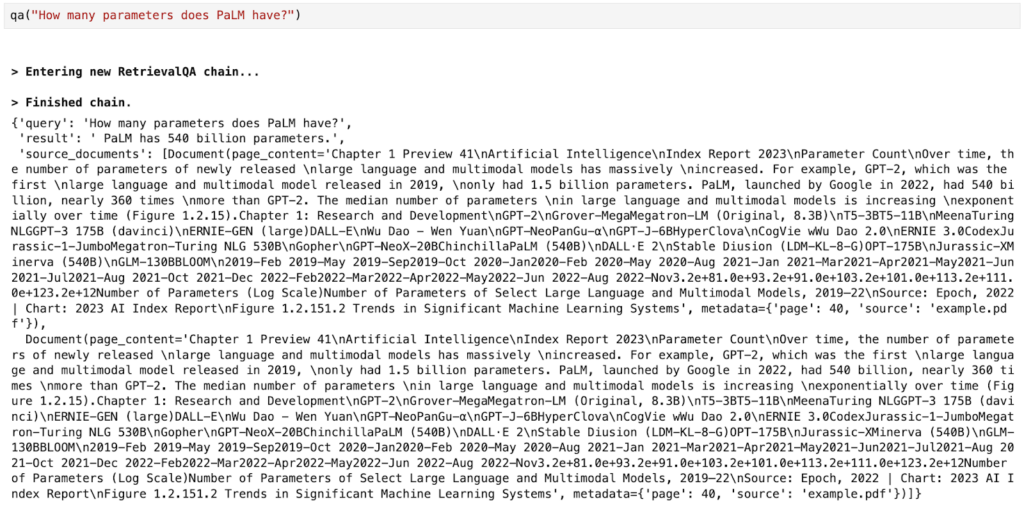
)質問をすると、その結果と 2 つのソース ドキュメントを参照できます。
RAG アプリケーションに Panel のチャット インターフェイスを使用する方法
以前の記事 (英語) では、Panel の新しいチャット インターフェイスと、Panel で基本的な AI チャットボットを構築する方法をご紹介しました。Panel とチャット インターフェイスの詳細にご関心のある方は、このブログ記事をご覧ください。RAG アプリケーション用の Panel チャットボットを作成するには、以下の 4 つの簡単な手順を実行します。
- Panel のウィジェットを定義
- LangChain ロジックを関数にまとめる
- チャット インターフェイスの作成
- テンプレートで外観をカスタマイズ
ステップ 1. Panel のウィジェットを定義
Panel のウィジェットは、ファイルをアップロードしたり、アプリケーションの値を選択したりできるインタラクティブなコンポーネントです。
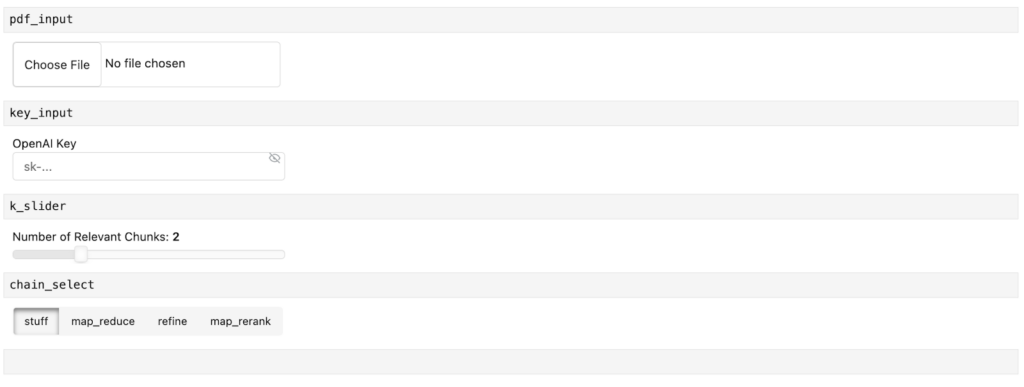
RAG アプリケーションのチャットボットには、4 つの Panel のウィジェットを定義します。
- 1. pdf_input: ユーザーが PDF ファイルをアップロードできるようになります。
- 2. key_input: OpenAI API キーを入力します。
- 3. k_slider: 関連するテキスト チャンクの数を選択します。
- 4. Chain_selection: 検索するチェーンの種類を選択します。
import panel as pn
pn.extension()
pdf_input = pn.widgets.FileInput(accept=".pdf", value="", height=50)
key_input = pn.widgets.PasswordInput(
name="OpenAI Key",
placeholder="sk-...",
)
k_slider = pn.widgets.IntSlider(
name="Number of Relevant Chunks", start=1, end=5, step=1, value=2
)
chain_select = pn.widgets.RadioButtonGroup(
name="Chain Type", options=["stuff", "map_reduce", "refine", "map_rerank"]
)
chat_input = pn.widgets.TextInput(placeholder="First, upload a PDF!")Jupyter Notebook では、ウィジェットはこのように見えます。
ステップ 2: LangChain ロジックを関数にまとめる
次に、上の LangChain コードを関数にまとめましょう。この関数は見慣れたものとなるでしょう。いくつかの値を先ほど定義したウィジェットに置き換えています。具体的には次のようになります。
- OpenAI API キーを
key_inputウィジェットで定義します。
- ファイルを
pdf_inputウィジェットに読み込みます。
search_kwargs={"k": 2}をsearch_kwargs={"k": k_slider.value}に置き換えて、いくつの関連ドキュメントを取得した以下をコントロールできるようにします。
chain_type="map_reduce"をchain_type=chain_select.valueに置き換えて、4 つのチェーン タイプから 1 つを選択できるようにします。
def initialize_chain():
if key_input.value:
os.environ["OPENAI_API_KEY"] = key_input.value
selections = (pdf_input.value, k_slider.value, chain_select.value)
if selections in pn.state.cache:
return pn.state.cache[selections]
chat_input.placeholder = "Ask questions here!"
# load document
with tempfile.NamedTemporaryFile("wb", delete=False) as f:
f.write(pdf_input.value)
file_name = f.name
loader = PyPDFLoader(file_name)
documents = loader.load()
# split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# select which embeddings we want to use
embeddings = OpenAIEmbeddings()
# create the vectorestore to use as the index
db = Chroma.from_documents(texts, embeddings)
# expose this index in a retriever interface
retriever = db.as_retriever(
search_type="similarity", search_kwargs={"k": k_slider.value}
)
# create a chain to answer questions
qa = RetrievalQA.from_chain_type(
llm=OpenAI(),
chain_type=chain_select.value,
retriever=retriever,
return_source_documents=True,
verbose=True,
)
return qaウィジェットで値を定義した後、この関数を呼び出して、pdf_input ウィジェットにアップロードしたドキュメントについて質問することができます。
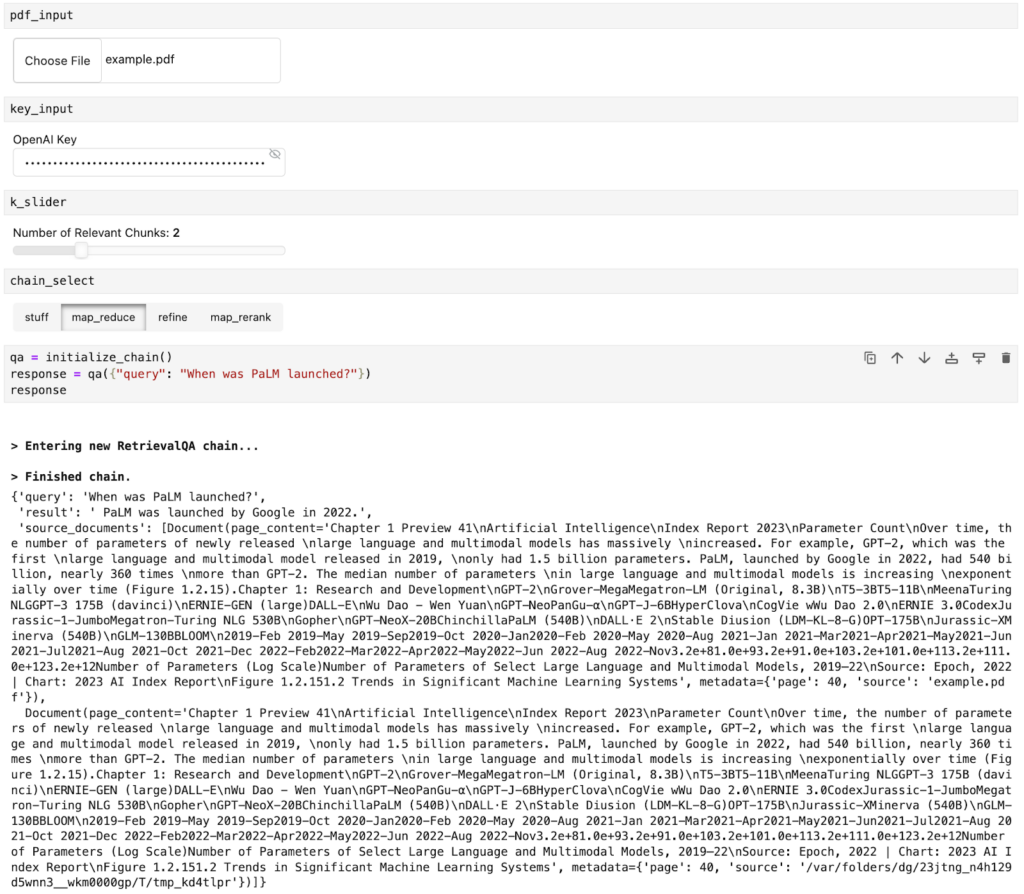
ステップ 3. チャット インターフェイスの作成
チャット インターフェイスでドキュメントを活用し、質問をするにはどうしたらよいでしょうか。ここで Panel の ChatInterface ウィジェットの出番となります!
チャットボットがどのように応答するかを定義するために、関数 `respond` を作成する必要があります。この関数はステップ 2 からの応答を受け取り、Panel オブジェクト `answers` にフォーマットします。また、この Panel オブジェクトに関連するソース ドキュメントを追加します。そして、pn.chat.ChatInterface の `callback.` でこの関数を呼び出すだけです。
async def respond(contents, user, chat_interface):
if not pdf_input.value:
chat_interface.send(
{"user": "System", "value": "Please first upload a PDF!"}, respond=False
)
return
elif chat_interface.active == 0:
chat_interface.active = 1
chat_interface.active_widget.placeholder = "Ask questions here!"
yield {"user": "OpenAI", "value": "Let's chat about the PDF!"}
return
qa = initialize_chain()
response = qa({"query": contents})
answers = pn.Column(response["result"])
answers.append(pn.layout.Divider())
for doc in response["source_documents"][::-1]:
answers.append(f"**Page {doc.metadata['page']}**:")
answers.append(f"```\n{doc.page_content}\n```")
yield {"user": "OpenAI", "value": answers}
chat_interface = pn.chat.ChatInterface(
callback=respond, sizing_mode="stretch_width", widgets=[pdf_input, chat_input]
)
chat_interface.send(
{"user": "System", "value": "Please first upload a PDF and click send!"},
respond=False,
)ステップ 4. テンプレートで外観をカスタマイズ
最後のステップでは、ウィジェットとチャット インターフェイスをアプリケーションに組み合わせます。Pane には複数のテンプレートが用意されており、見た目の良いWebアプリをすばやく簡単に作成できます。ここでは、BootstrapTemplate を使用して、サイドバーにウィジェットを整理し、アプリの中央にチャット インターフェイスを表示するようにします。
template = pn.template.BootstrapTemplate(
sidebar=[key_input, k_slider, chain_select], main=[chat_interface]
)
template.servable()`panel serve app.py` または `panel serve app.ipynb` を使用すると、この記事の始めに出てきたアプリが活用できるようになります。
おわりに
RAG は、AI の世界における情報検索と生成技術の魅力的な融合です。このブログ記事では、RAG の基本部分を分解し、LangChain を使用した RAG アプリケーションの作成方法を説明し、最後に Panel のユーザーフレンドリーなチャット インターフェイスを統合しました。RAG を理解し、プロジェクトに実装しようとしているすべての人にとっての実用ガイドとなれば幸いです。進化し続けるテクノロジの世界をナビゲートし続ける中で、RAG のようなツールを理解し、活用することは、有益な一歩となります。この説明とガイドに価値を見出していただけますように。Happy coding!
2024 © Anaconda Inc.
「How to Build a Retrieval-Augmented Generation Chatbot」