2024年7月19日、サイバー セキュリティ大手の CrowdStrike が提供したアップデートの不具合が原因で、大規模なコンピューター障害が発生しました。全世界で数百万台の Windows デバイスに影響を与えたこのインシデントは、ソフトウェア エラーが引き起こすドミノ効果を明らかにしました。本シリーズのパート 1 では、将来の障害を防ぐため QA 手法が果たす役割について説明しました。パート 2 では、プログレッシブ配信と強固な監視戦略を導入することで、CrowdStrike がどのようにこの状況を回避できたかについて説明します。
CrowdStrike の障害の原因は?
障害の原因は、Windows マシン上の CrowdStrike の Falcon ウイルス対策ソフトウェアのセンサー設定の更新でした。この更新には、起動時にシステム クラッシュとブルー スクリーン (BSOD) を引き起こすロジック エラーが含まれていました。
CrowdStrike の技術情報によると、設定の更新がロジック エラーを引き起こしたということです。このエラーにより、システム クラッシュが発生し、影響を受けたデバイスが再起動を繰り返して使用不能になりました。
同様の障害を防止できる戦略
バグやエラーは常に存在します。鍵となるのは、バグのあるデプロイメントを (可能な限り) 防止し、本番環境で迅速に解決する戦略を導入して、潜在的なエラーの影響を軽減することです。ここで、強力なオブザーバビリティ戦略が役立ちます。
CrowdStrike がこの障害を回避するのに役立った可能性のあるいくつかのオブザーバビリティ戦略を次に示します。
- プログレッシブ配信: プログレッシブ配信は、コードの開発、テスト、デプロイを行う最新の方法であり、開発チームは計画/設計から運用まで、ソフトウェア開発ライフサイクル (SDLC) 全体を通してデータに基づく意思決定を行うことができます。これは、チームがリリースをロールアウトまたはロールバックするタイミングを決定するのを助け、CrowdStrike の障害では、問題を少数のユーザーに隔離することができたでしょう。
- プロアクティブなエラー監視: 効果的なオブザーバビリティ ツールがあれば、CrowdStrike アップデートの配信と同時に発生したエラーやシステム クラッシュの異常な急増を特定し、エンジニアリング チームにすぐに警告が送信され、問題を切り分けて、影響がより広範囲にわたることを防げたでしょう。
- 詳細なエラー レポート: 明確なスタック トレースを含む詳細なエラー レポートがあれば、CrowdStrike アップデート内のエラーの正確な場所をすばやく特定し、迅速にトラブルシューティングを行い、より短時間で解決することができたでしょう。
- リアル ユーザー モニタリング: 継続的な監視は、アプリケーションの健全性に関する状況認識を維持するのに役立ちます。リアルタイムのパフォーマンス メトリックを追跡することで、開発チームは潜在的な問題をプロアクティブに特定し、大規模な障害に発展する前に対処できます。
リリース管理の重要性
場合によっては、バグがテストで見落とされてしまうことがありますが、強力なリリース管理プロセスがあれば問題ありません。SDLC のこのフェーズでは、新しいアップデートが想定される範囲を満たし、各リリースが安定しており、現在の本番環境の整合性に影響を与えないことを保証します。これは、プログレッシブ配信の実践の一部です。
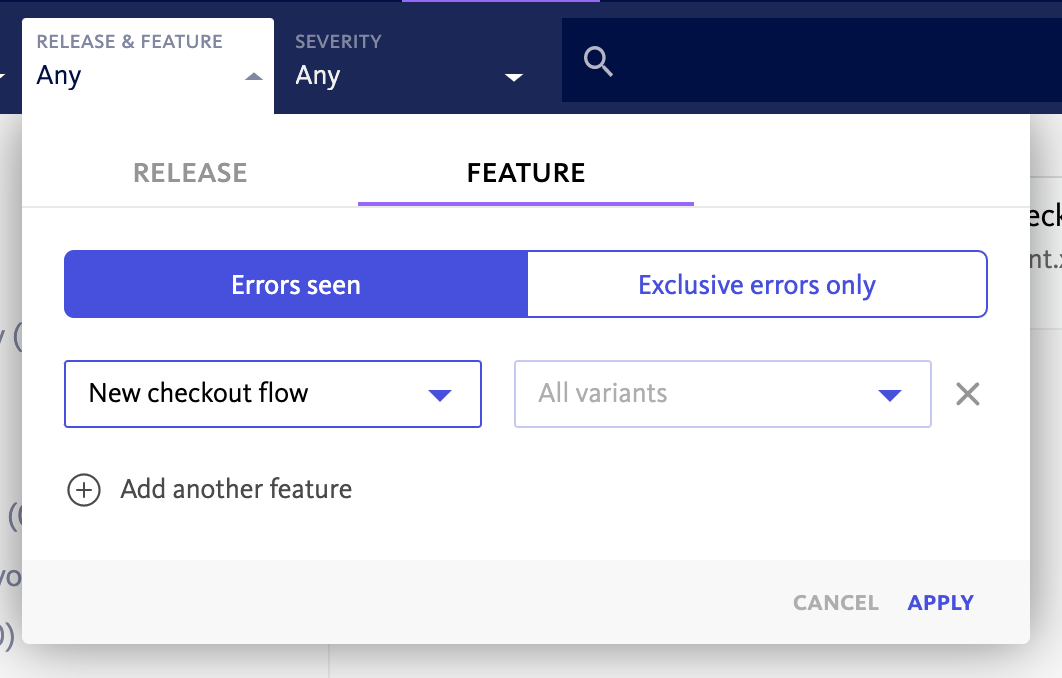
BugSnag が、新しいリリースのデプロイとアプリケーションの安定性の維持にどのように役立つかを見てみましょう。
- 機能フラグと実験: BugSnag の機能フラグを使用すると、開発者は新しい更新を少数のユーザーにプッシュして、更新がアプリケーションの安定性に影響するか、エラーが発生するかを評価できます。これにより、CrowdStrike が直面したような壊滅的な問題を引き起こす可能性のある、ユーザー ベース全体のアプリの更新を回避できます。
- 機能ダッシュボード: 機能フラグだけでは不十分な場合があります。BugSnag の機能ダッシュボードは、フラグが付けられたリリースとすでに実行中の実験に影響を与えるエラーを監視します。フラグまたは実験がアクティブだったときに発生したエラーのみを確認し、新しいリリースの重大な問題を明らかにすることができます。
- バージョン管理とロールバック: BugSnag はリリース管理システムと統合されているため、開発者は必要に応じて以前の安定したバージョンに簡単に戻すことができます。これにより、ダウンタイムが最小限に抑えられ、ビジネスの継続性が確保されます。これは、CrowdStrike の開発者が間違いなく重宝した機能でしょう。
- コミュニケーションとコラボレーションの改善: 全員が同じ認識を持つことが重要です。BugSnag は、組織内の開発者とチーム間のコミュニケーションとコラボレーションを促進します。BugSnag のデータ アクセス API を使用すると、組織全体で安定性スコアを簡単に共有でき、カスタム ルールを実装してチーム間でエラーの自動割り当てを作成することもできます。
重大なエラーを迅速に修正する方法
CrowdStrike の障害は、今日のソフトウェア開発環境において、プロアクティブなアプリケーション監視の重要な役割を浮き彫りにしています。BugSnag の次の機能は、本番環境で重大なエラーが発生するのを回避するため強固な監視戦略を導入するのに役立ちます。
- リアル ユーザー モニタリング: 応答時間、スループット、リソース使用率などのアプリケーション パフォーマンス メトリックに関する洞察が得られます。
- 包括的なエラー監視: 単純な JavaScript エラーから複雑なサーバー クラッシュまで、あらゆる種類のエラーと例外をキャプチャして分析します。
- リアルタイム エラー通知: BugSnag は、エラーとパフォーマンスの問題に関するリアルタイム アラートを、システム クラッシュの直後にチームに通知します。この迅速な通知により、すばやい介入と被害抑制が可能になります。
- 詳細なエラー レポート: BugSnag は、包括的なスタック トレースとパンくずリストを含む詳細なエラー レポートをキャプチャし、エラーの正確な原因を特定します。これにより、開発者は問題をすばやく理解して修正できます。
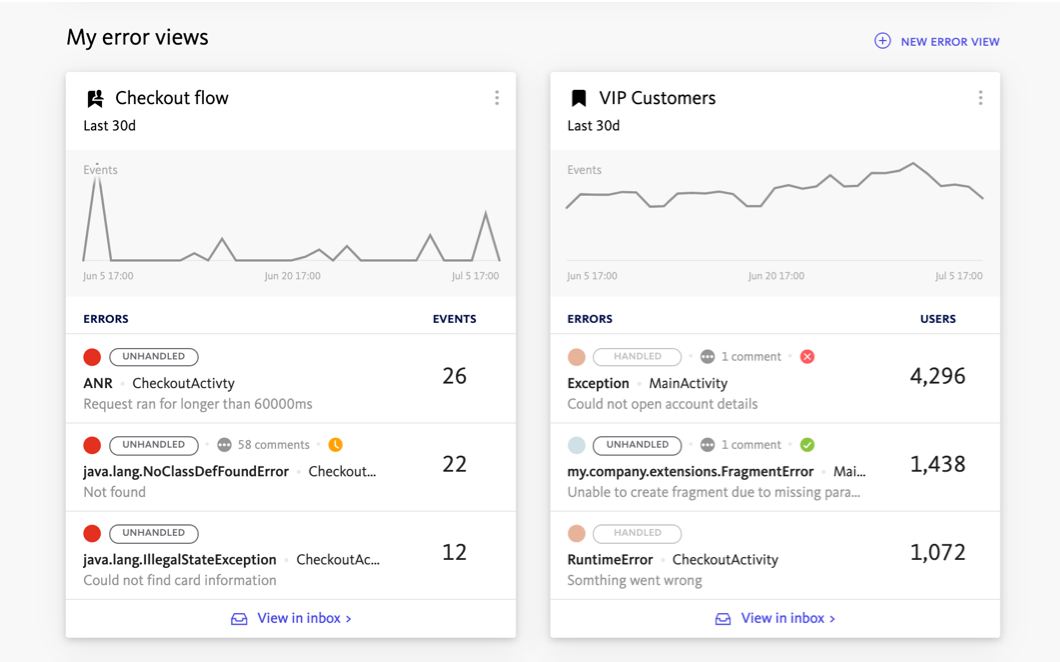
BugSnag のような、エンドツーエンドで開発者に重点を置いたエラーおよびパフォーマンス監視ソリューションを実装することで、組織は障害が広範囲に拡大する前に、プロアクティブに問題を検出して修正できます。これにより、ダウンタイムと経済的損失を最小限に抑えられるだけでなく、ブランドの評判とユーザーの信頼も守ることができます。
CrowdStrike の障害は最近の出来事かもしれませんが、その教訓は時代を超えて受け継がれます。アプリで同様の問題が起こらないようにするには、BugSnag のエラー監視とパフォーマンス監視でアプリの品質を保護する方法を、14 日間の無料評価版でお試しいただくか (クレジットカード不要)、デモをご覧ください。
パート 1 を見逃した場合は…
このシリーズのパート 1 では、QA手法がリリースの品質に与える影響について説明しました。バグと完全に無縁のリリースはありませんが、適切な手順を踏むことで、最も壊滅的なバグからビジネスを守ることができます。
CrowdStrike の障害は、包括的なテストとオブザーバビリティ ソリューションの必要性を明確に示しています。開発者がソフトウェア開発ライフサイクルのさまざまなステージを横断してつながればつながるほど、重大なエラーが発生する可能性は少なくなります。全体として、このような部門間のコラボレーションにより、開発者は高品質のソフトウェアを提供できるようになります。
この資料は、SmartBear の Blog で公開されている「Breaking Down the CrowdStrike Outage Part 2: Observability Strategies to Prevent Application Catastrophes」の日本語参考訳です。