
現代のビジネス環境において、AI 技術は業務の効率化や意思決定の質の向上に欠かせない要素となっています。しかし、AI の導入にあたっては、単に技術が優れているだけでなく、その運用が安全かつ迅速に実現できるかどうかが重要です。多様なインフラストラクチャや業界固有の要件に合わせて、最適な AI モデルとその運用環境を構築するには、柔軟性と効率性が求められます。
そこで注目されるのが、Seekr 社の提供する生成 AI プラットフォーム「SeekrFlow」です。SeekrFlow は独自の技術を用いて、企業が信頼できる AI モデルの構築に貢献します。
本記事では、SeekrFlow についてその機能や実際に使ってみた感想を交えながら解説します。
Seekr とは?
Seekr は、アメリカ発の企業として、企業向けに高度な AI ソリューションを提供しています。特に、企業の運用環境やコスト管理、セキュリティ要件に応じた柔軟な導入が可能なプラットフォームを展開している点が特長です。SeekrFlow は、文書理解とその応用により対話 (チャット) ベースの AI アシスタントを構成する、大規模言語モデル (LLM) の運用に注目したプラットフォームです。AI-Ready Data Engine という革新的な技術が統合されており、短時間で有効なデータセットの生成と、それらによる高性能な AI モデルへのファインチューニングを効率的に実現しています。
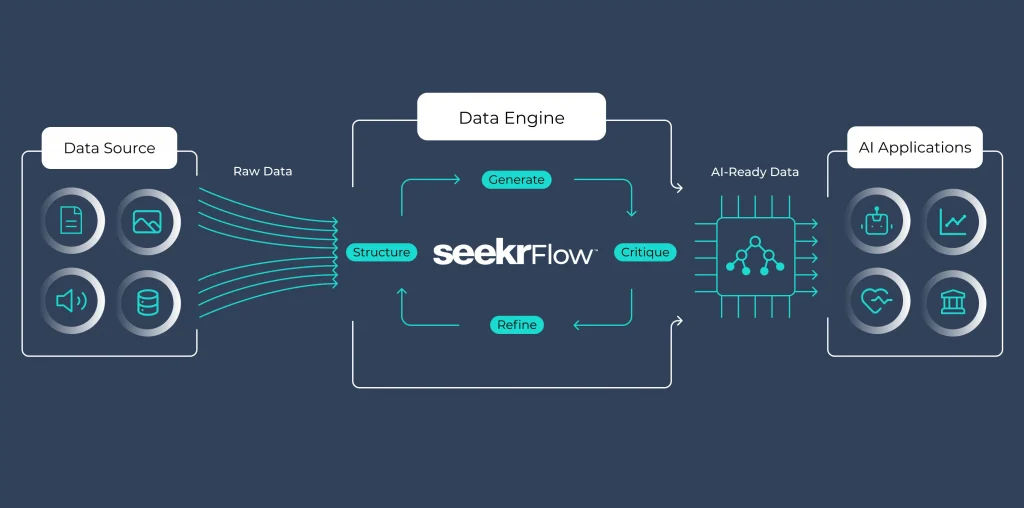
AI モデルの構築方法
ここからは実際に SeekrFlow 上で信頼できる AI モデルの構築に挑戦してみましょう!
まず、SeekrFlow の WEB ページにアクセスし、ダッシュボードに進みます。ダッシュボードから、AI モデルを構築するためのステップに進むことができます。
データセットの作成
画面左側のメニューから Datasets へ進みます。ここでは、AI モデルのファインチューニングに用いるデータセットの作成と管理を行えます。
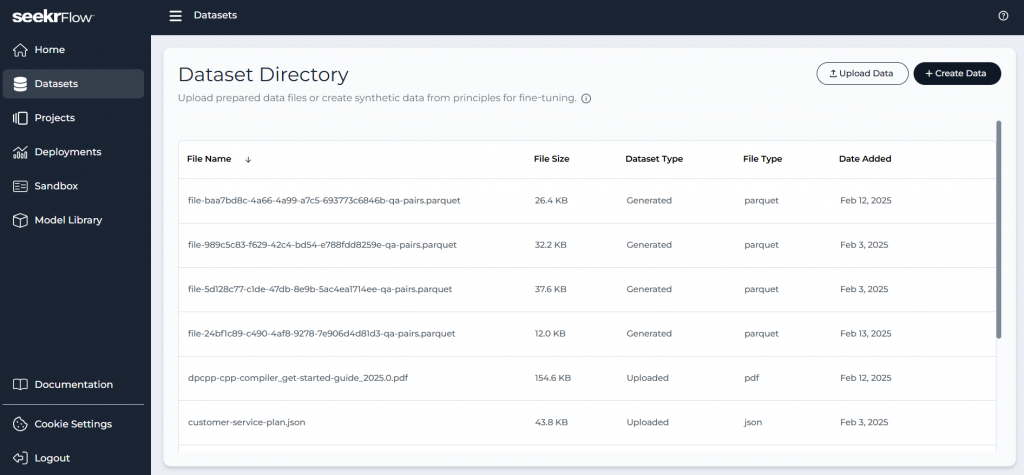
次に画面右上の Create Data ボタンをクリックし、表示された欄にファインチューニング ゴールの入力と、プリンシパル ファイルのアップロードを行います。ファインチューニング ゴールは AI モデルの回答の正確性を向上させるための重要なステップです。例として「I’m developing a chat assistant that must align with the ethical standards and organizational values of my company brand. (私が開発するチャットアシスタントは、わが社のブランドにおける倫理基準と組織の価値観に沿ったものにする必要があります。)」という文が表示されており、この通りであれば、かしこまった受け答えをする企業の担当者のようになってほしい、という意図を伝えています。アップロードするファイルについては、会社のポリシーやガイドラインなど、AI モデルに学習させたい知識の基になる情報が書かれた文書ファイル (PDF、Word、あるいは Markdown 形式) を用意してください。以下の例では、テスト用のファインチューニング ゴールとして「私が開発するチャットアシスタントは、初学者の短い質問に対しても丁寧に解説を行う親切な技術者であってください。」を設定しています。
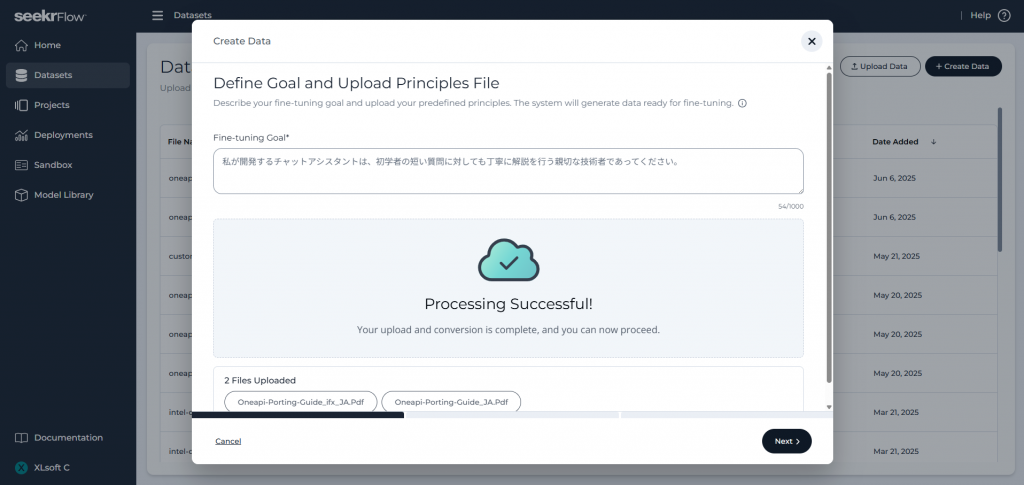
ファインチューニング ゴールの入力とプリンシパル ファイルのアップロードが済んだら、画面右下の Next ボタンをクリックして進め、データセットの自動生成を予約します。生成されたデータセットはパーケット ファイル (.parquet) として保存され、Datasets のリストに表示されます。このパーケット ファイルには、プリンシパル ファイルの内容について質問文と回答文の組が多数格納されており、基となる大規模言語モデルを訓練するためにすぐに使用できる形式です。

これでファインチューニングを実行する準備ができました。
ファインチューニングの実行
データセットが準備できたら、画面左側のメニューから Projects に進み、続いて画面右上の Create Project ボタンをクリックします。
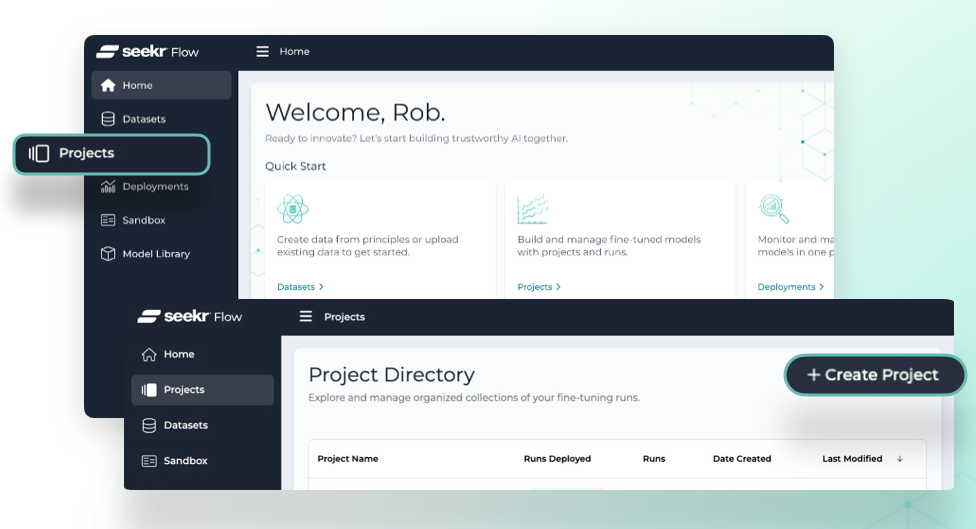
表示された欄にプロジェクトの名前と説明を入力し、Create Project ボタンをクリックし、問題なく設定されたら Go To Project ボタンをクリックして進みます。名前と説明は区別のために入力するもので、モデルのパフォーマンスには影響しません。
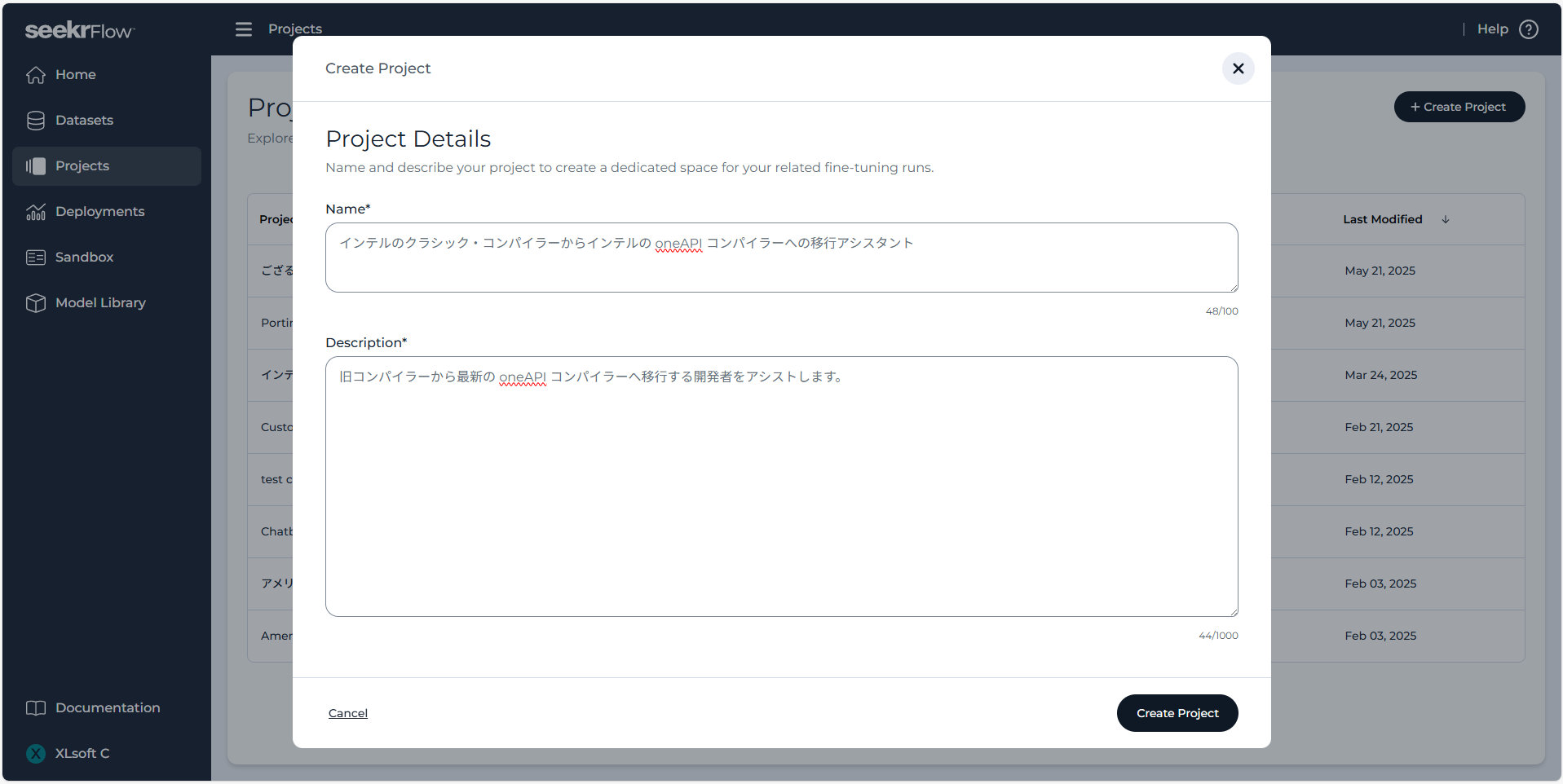
次は、Create Run ボタンをクリックし、Run の設定に進みます。ここで Run は、ファインチューニングの実行予約と、それが完了したモデルの両方の意味を持ちます。各 Run を区別するための名前と説明を入力し、前のセクションで作成したパーケット データセットを選択します。Select from Directory をクリックし、パーケット ファイルを選びます。ファイル名は、<principles-file>-<timestamp>-qa-pairs.parquet のような形式になっているはずです。
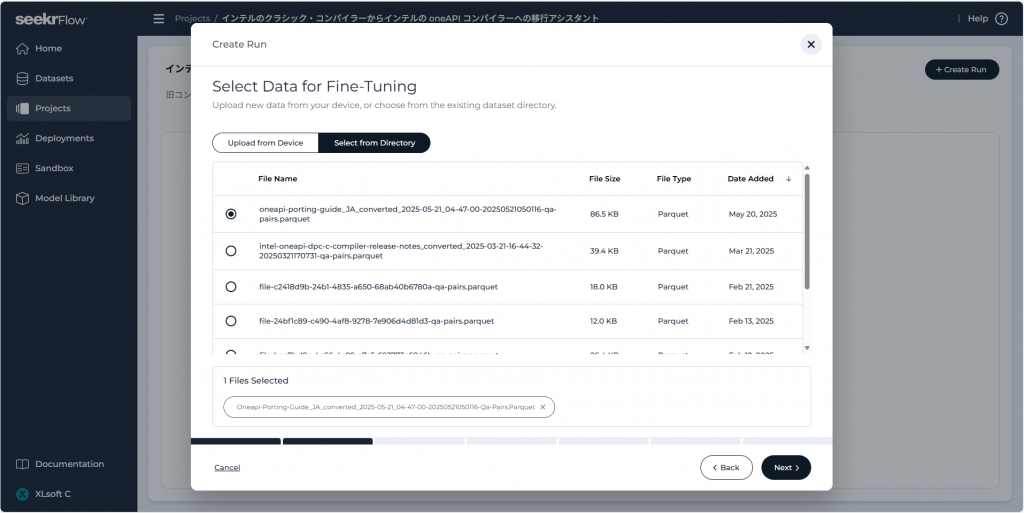
そして、データセットを用いてファインチューニングするベースモデルを選択します。訓練に要する時間と、最終的なモデルの性能のバランスを取りたい場合は meta-llama/Llama-3.1-8B-Instruct から始めてみましょう。
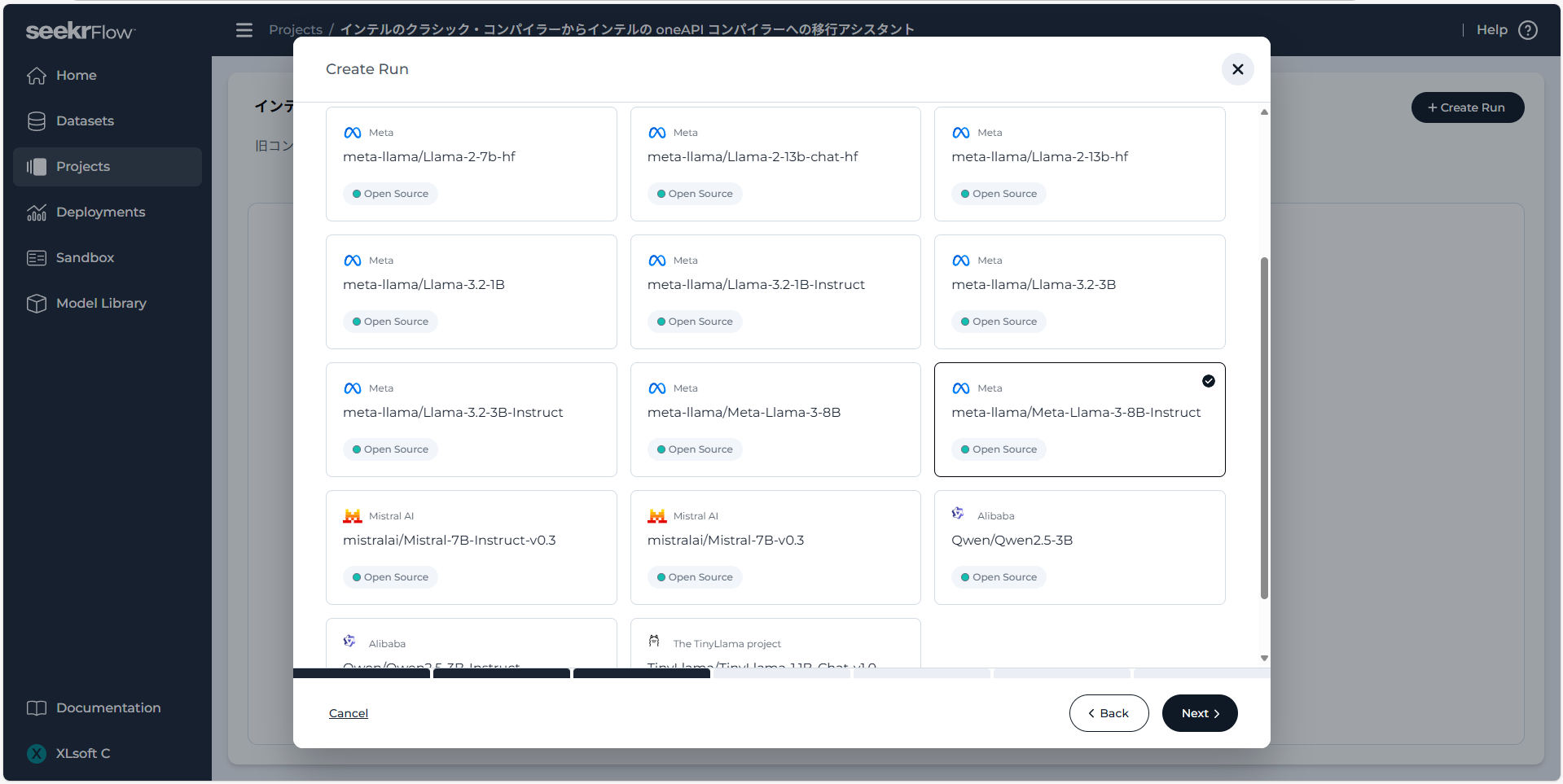
続いて、ファインチューニングに用いるハードウェア構成を選択します。8 instances を選択すると、訓練プロセスを高速化できます。1 つのインスタンスでのファインチューニングは小規模なデータセットと 10B (100 億) 未満のパラメーターのモデルについてコスト効率の良い選択ですが、8 つのインスタンスを使うと並列処理によりファインチューニングを早く完了することができます。
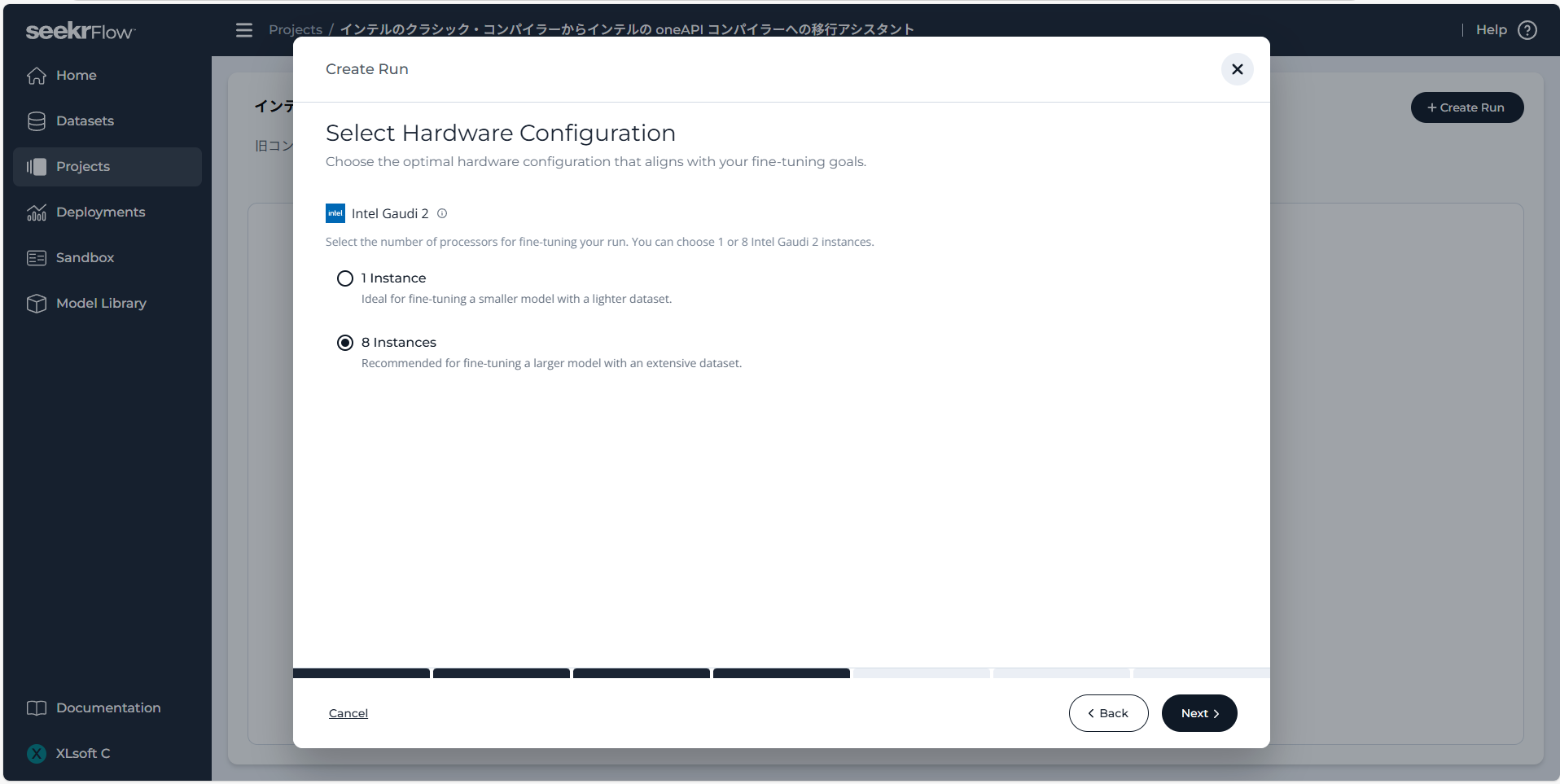
また、SeekrFlow では、エポック数やバッチサイズ、学習率などのハイパーパラメータを調整できます。これらを変更することで、訓練の効率を高めたり、モデルの性能を向上させたりといった制御が可能です。
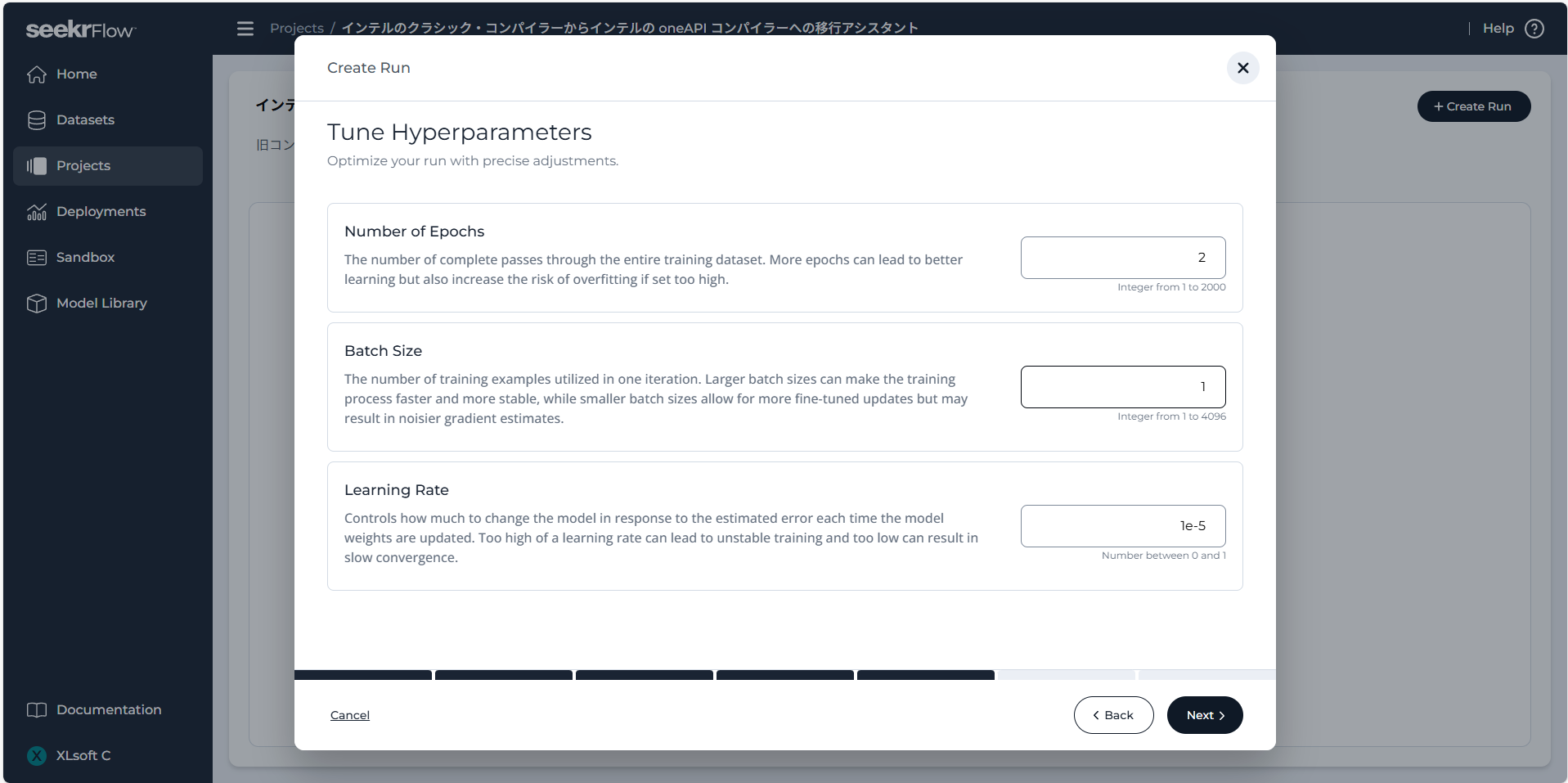
エポック数 (Epochs):
訓練用のデータセット全体を繰り返して学習させる回数です。エポック数を増やすと学習効果は向上しますが、あまり多く設定すると過学習のリスクも高まります。
バッチ サイズ (Batch Size):
1回のイテレーションで使用されるトレーニング例の数です。バッチ サイズが大きいと訓練プロセスが早まり安定しますが、更新ごとの学習効果は低下します。バッチ サイズが小さいときめ細かい更新が可能になるものの、勾配の推定で大きなノイズを含む可能性があります。
学習率 (Learning Rate):
モデルの重みが更新される際に、推定誤差に応じてどの程度変更するかを制御します。学習率が高すぎると学習が不安定になり、低すぎると収束が遅くなる恐れがあります。
以上で、ファインチューニングの実行予約ができました。ファインチューニング完了までは数時間かかる場合がありますが、ウェブ ブラウザを閉じてしまっても問題はありません。後から完了したかどうかを確認しましょう。
ファインチューニングされたモデルのデプロイ
ファインチューニングされたモデルは、デプロイ (配置) することで性能評価や推論のために使用できるようになります。早速、ファインチューニングされたモデルをデプロイしてみましょう!
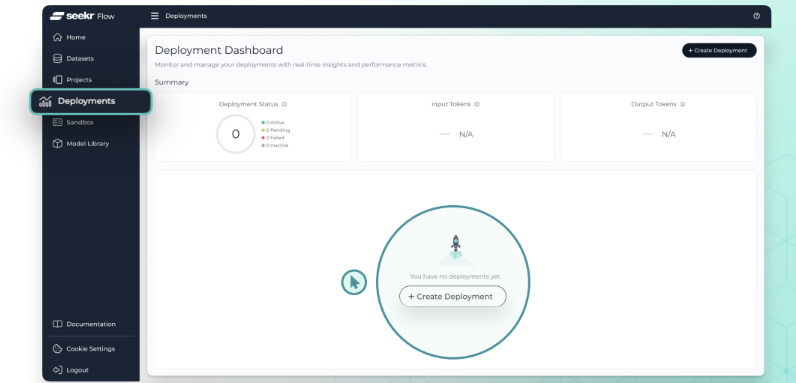
まずは、画面左側のメニューから Deployments へ進み、画面右上の Create Deployment ボタンをクリックします。
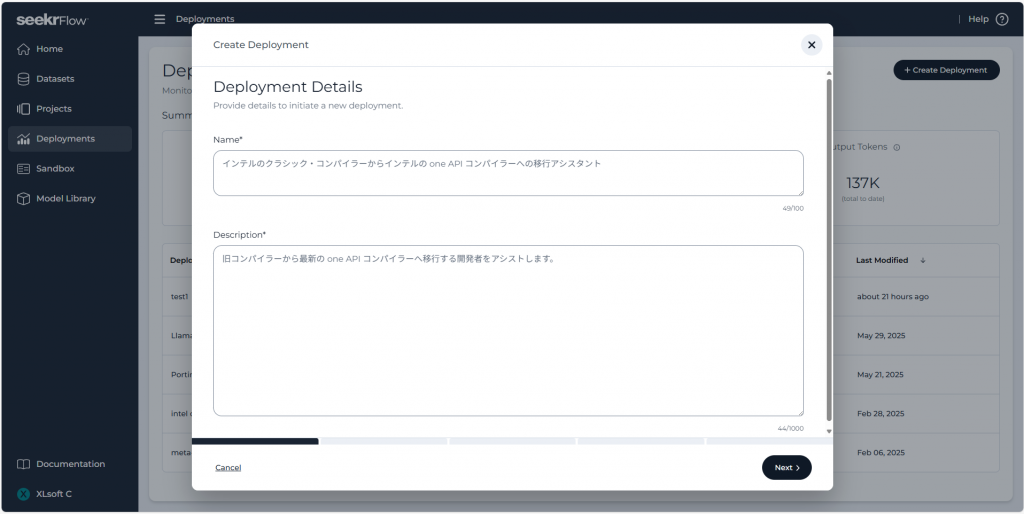
次に、デプロイする AI モデルとしてベースモデルか Run を選択するよう求められます。右側の Run をクリックし、ファインチューニングが完了した Run (モデル) を選んで画面右下の Next ボタンをクリックします。
続いて、推論用ハードウェアのインスタンス数を設定します。ここでは 1 つを選択してみましょう。
インスタンス数を増やすとスループットは向上しますが、コストも増加します。デプロイ設定を行う際には、パフォーマンス要件と予算のバランスを考慮することが大切です。
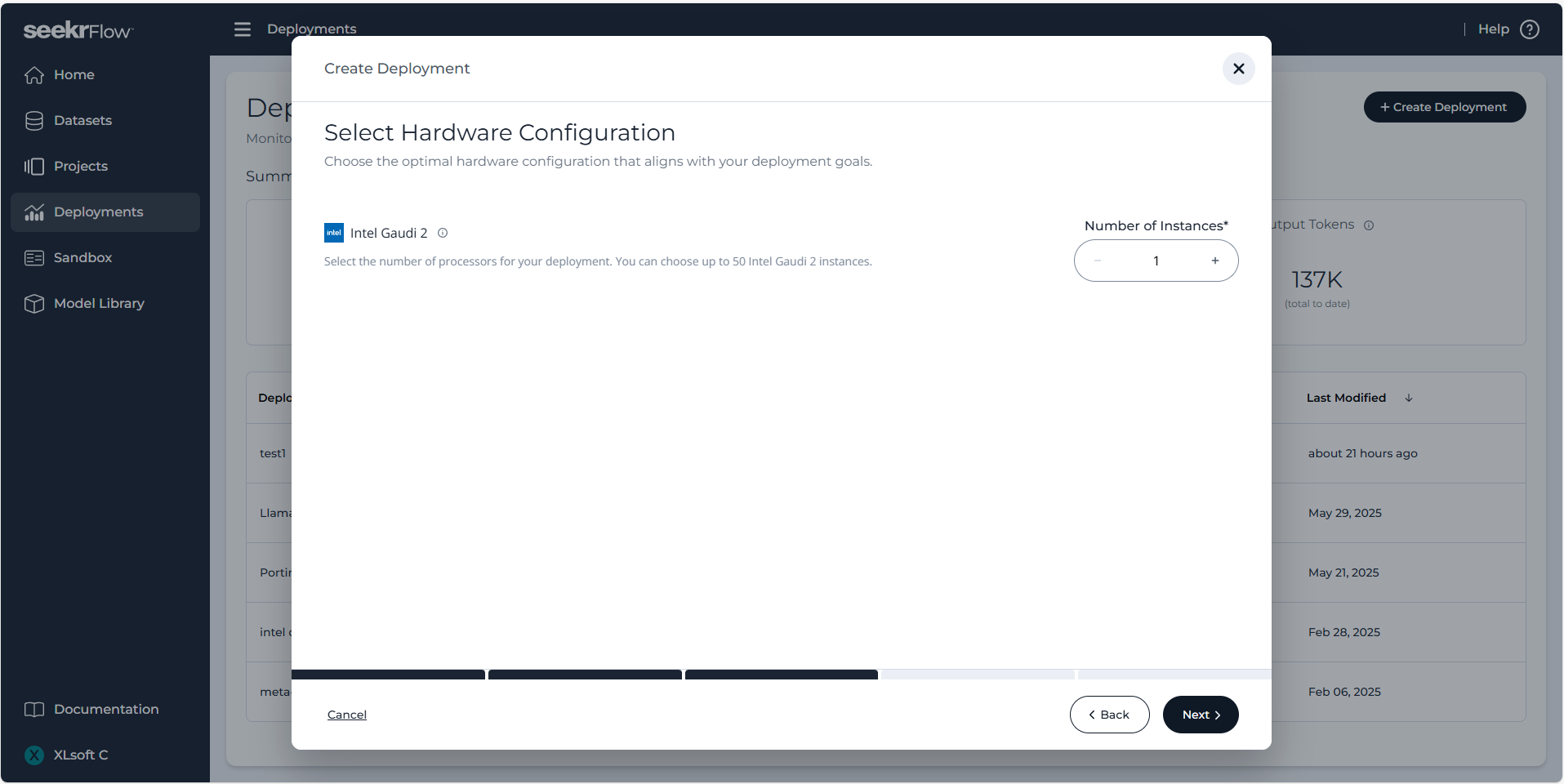
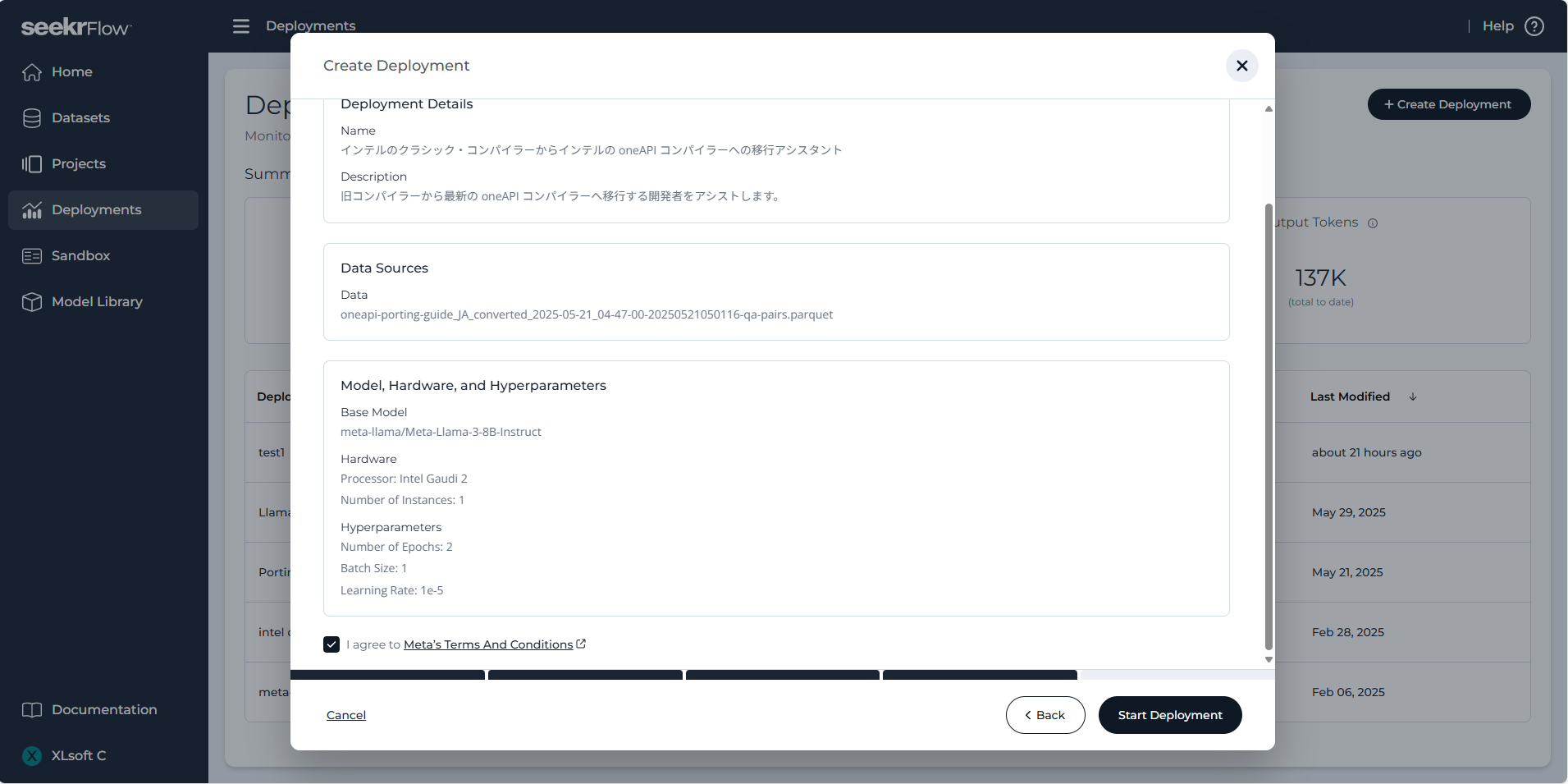
その後、デプロイの詳細を確認し、画面右下の Start Deployment ボタンをクリックします。1 時間以内にデプロイが行われ、ついに AI モデル構築の完了です!
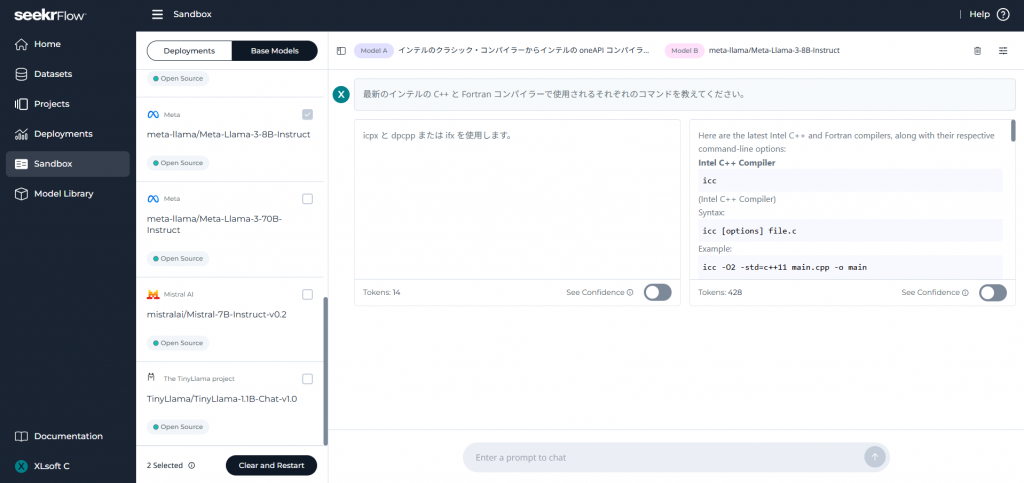
デプロイが完了すると、画面左側のメニューの Sandbox からモデルの性能テスト インターフェイスを開くことができます。ここであなたの企業向けにファインチューニングされたモデルと、任意のベースモデルに同じチャットメッセージを送り、どのような回答が行われるかを比較できます。
また、デプロイした AI モデルは、Seekr API と SDK、あるいは OpenAI 互換のクライアント (ライブラリーまたはツール) を通じて、ユーザーのアプリケーションから利用できるようになります。
SeekrFlow を使ってみた感想
良かった点
操作のシンプルさ
実際に SeekrFlow を使用してみると、そのシンプルな UI と直感的な操作性により、従来の複雑な手順が大幅に簡略化されている点に驚かされました。初心者でも迷うことなく、データのアップロード、モデルの訓練、デプロイメントまでをスムーズに進めることができるため、導入のハードルがとても低くなっています。特に、複数の設定やオプションを一元管理できる点は、大きな利点であると感じました。実際、初めて AI プラットフォームを触る方でも、画面上の指示に従うだけで容易に作業を開始できるので、業務の迅速なスタートが可能になるでしょう。
短時間で結果が出る
SeekrFlow の導入により、従来は数日以上かかっていたであろうデータセットの生成やモデルのファインチューニングが、数時間で完了する点が非常に印象的でした。これまでのプロセスでは、大量の手作業が必要で、また専門のデータ エンジニアによる調整が求められていましたが、SeekrFlow の自動化されたプロセスにより、迅速に新しいモデルを構築して評価することができます。さらに、このワークフローの高速化は、業務上の急な変更や市場の変化に対して柔軟に対応するための大きなアドバンテージとなっています。
柔軟な環境対応
SeekrFlow のもう一つの大きな魅力は、企業が自社のインフラストラクチャに合わせたプランを選択できる点です。マネージドサービス (AIaaS) に留まらず、オンプレミス、自社管理のクラウドといった柔軟な導入形態に対応しており、企業のデータと計算資源の場所を特定できます。これにより、システム全体のリスクを管理しながら、効率的な運用が可能となります。
使用上の注意点
日本語サポートが不足している
SeekrFlow および Seekr のサービスは現在、英語および英語話者を中心に提供されており、日本語でのサポートが不十分です。公式サイトやドキュメントが英語で提供されているため、英語に不安があるユーザーにとっては少しハードルが高いと感じるかもしれません。
モデル精度と安全性のバランス
SeekrFlow を使うことで短時間でファインチューニングされたモデルを構築できますが、実際のビジネス要件やリスク管理を踏まえた上でモデルを評価する必要があります。AI モデルの精度を追求しすぎると、計算リソースやコストが大きくなり、ROI (投資対効果) は悪いものとなるでしょう。テスト環境を整備し、ステークホルダーを含めた検証を開発段階から意識することで、ビジネスの安全性とモデル精度のバランスを保つことが重要です。
まとめ
Seekr は、企業向けに強力な AI プラットフォームを提供しており、特に AI モデルの作りやすさと扱いやすさが際立っています。また、ノーコードで簡単に AI 技術を導入できるため、AI の専門知識がなくても使い始めることができます。今後、日本語サポートの強化が進めば、さらに多くの企業が利用するようになるでしょう。
エクセルソフトは、日本初となる Seekr 社の販売代理店として、エンタープライズ向けの専門性の高い RAG システムの構築やファインチューニングされたアプリケーションのデプロイを支援し、SeekrFlow を通した国内の企業による AI 技術のさらなる導入を支援します。エクセルソフト経由でご購入いただいた場合、日本語による導入前後の利用支援、トレーニング、日本語ドキュメントをご利用いただけます。
販売開始に関するプレスリリースは、こちらからご参照ください。
導入前のご質問やご購入前の見積依頼などございましたら、エクセルソフトまでお気軽にお問い合せください。
