2015 年に Kubernetes v1.0 がリリースされてから 6 年が経ち、今やモダンなクラウド ネイティブ アプリケーションを迅速かつ柔軟に開発、展開、拡張するための重要な技術基盤となっています。エコシステムが急成長している中、ツールの発展により、 Kubernetes 上でアプリケーションをデプロイできるようになりました。ステートフル ビッグデータ アプリケーションは、かつて Kubernetes で管理するのは難しいと考えられていましたが、現在では、Kubernetes をファーストクラスのクラスタ オーケストレータとして使用することができるようになりました。ビッグデータ、ML、AI アプリケーションを Kubernetes に移行するお客様が増えている中、Spot は、ビッグデータアプリケーション専用に設計されたサーバーレス コンテナエンジン「Wave」をリリースしました。
なぜ 「Wave」?
Kubernetes は、コンテナやサービスを簡素化、標準化する一方で、 基盤となるクラウドインフラの管理は難しいものとなっています。経験豊富な DevOps チームであっても、インフラのスケーリング、プロビジョニング、管理のための手動で複雑、かつリソースの集約的な作業に苦労しています。これらの作業を正しく行うことで、企業は Kubernetes とクラウドの管理方法を準拠することができますが、間違った方法で行うと、リソースの浪費、管理チームの疲弊、アプリケーションの不具合、クラウドの高額請求につながります。
基盤となるクラウドインフラの管理は難しいものとなっています。経験豊富な DevOps チームであっても、インフラのスケーリング、プロビジョニング、管理のための手動で複雑、かつリソースの集約的な作業に苦労しています。これらの作業を正しく行うことで、企業は Kubernetes とクラウドの管理方法を準拠することができますが、間違った方法で行うと、リソースの浪費、管理チームの疲弊、アプリケーションの不具合、クラウドの高額請求につながります。
ビッグデータチームのための Kubernetes
ビッグデータ アプリケーションでは、DevOps が直面しているのものと同様に、クラウド インフラの課題が存在しますが、データエンジニアやサイエンティストにとっては、Kubernetes の作業を自分で行うことが多いため、ハードルが高く、迅速な知識の習得が求められてきます。クラウド管理の手助けをする EMR のためのサービスである EKS を利用したとしても、 Kubernetes の管理は難しいものとされています。クラスタの初期設定、オート スケーリングの設定、日々のメンテナンス、コンピュートの管理やストレージ、ネットワークのインフラを正しく管理する方法を学ぶということは、チームの活動を遅らせ、データ イニシアチブの推進を遠ざけます。
データ環境のコスト増加
ガーター社によると、2022 年までに 90 % のデータやアナリティクスのイノベーションにパブリック クラウド サービスは必要不可欠なものとなり、2025 年までに、75 % が AI のパイロット化から本番運用へと移行し、ストリーミング データとアナリティクスのインフラが 5 倍に増加すると言われています。ビッグデータはこのようなペースで増え続け、それをサポートするスケーリング クラウドの環境も成長していくと言われています。クラウド プロバイダーはスポット インスタンスやリザーブド インスタンスを使用してクラウド コンピューティングを低コストで利用する方法を提供していますが、これらの価格モデルを効果的かつ確実に適用してコストをコントロールするには、ビッグデータチームの能力を超える膨大な努力が必要となってきます。
Spot はこれらの問題を解決するために Wave を開発し、ビッグデータ アプリケーションを自動化したスケーラブルで信頼性の高いクラウド インフラを提供できるようになりました。Wave を使用することで、ビッグデータ アプリケーションに、より優れた機動力と柔軟性を与え、プラットフォームではなく、データにフォーカスすることができます。Wave は Spot のサーバーレス コンテナ エンジンである、Ocean と同じコア技術で構成されており、ビッグデータに必要なインフラを提供します。
Wave とは?
データコミュニティがマイクロサービスへ移行を進める中、ビッグデータ、AI、ML アプリケーションに最適なオープンソース フレームワークである Apache Spark が Kubernetes に対するネイティブ サポートを開始しました。また Spark 2.3 では、ワークロードのデプロイやクラスタの管理を行う Kubernetes のスケジューラーが搭載されました。Kubernetes と Spark の人気上昇に伴い、Spot はこれらアプリケーションを支えるインフラに対するビッグデータチームの考え方を変えるようなツールを作りたいと考えました。
Spark にサーバーレス インフラを導入
Wave は Spark ジョブが Kubernetes 上にデプロイされた際、Ocean がインフラを拡張するために使用するのと同様のコア機能を活用します。リクエストが入ると、Wave はインフラをプロビジョンし、スポット、オンデマンド、リザーブド インスタンスを組み合わせてスマートにコストを最適化します。
Wave はコンテナ要件に基づいてインスタンスのタイプとサイズを Spark ジョブに適合させる自動化スケーリングのメカニズムを備えた Spark 対応のインフラを起動し、アプリケーションが大規模な実行に必要な最適化されたコンピューティングを提供します。クラウド リソースの使用状況をリアルタイムかつ長期的にモニタリングすることで、Wave は繰り返し発生する Spark ジョブの設定を継続的に調整し、パフォーマンスやコストの面でインフラを最適化します。この自律的なシステムは時間の経過とともに、クラウド環境での信頼性と効率性を向上させ、アプリケーションが Kubernetes とクラウドの力を最大限に活用できるようにします。
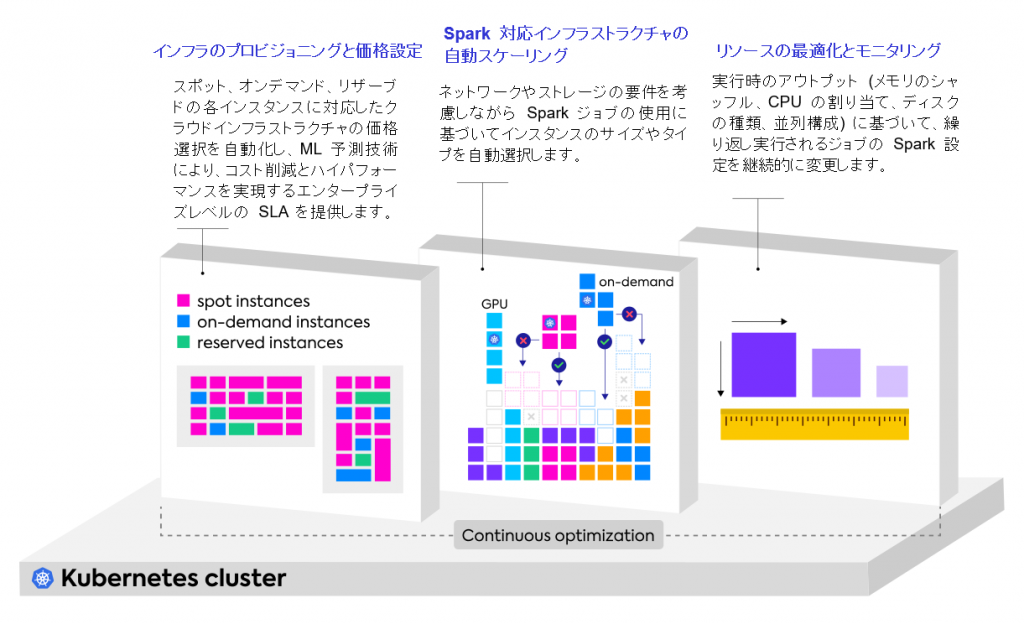
ビッグデータに対応
ビッグデータチームが直面する最大の課題の一つとして、クラウドサービスやコンテナ、Kubernetes のためのツールを使い慣れていない点が挙げられます。Wave では既存のワークフローを活用したり、 JupyterHub、エアフロー、Spark ヒストリー サーバーや Spark サブミットなど事前に構築された統合機器への接続を容易に行うことができます。ユーザーは Kubernetes で Spark アプリケーションをリモートで実行しながら、ローカルで Jupyter のノートブック設定することが可能です。構成の設定、リソースのプロビジョニングと管理まで、Wave はクラウド インフラの複雑さを解消するため、データ エンジニアやサイエンティストはパワフルなデータ アプリケーションの構築や提供にフォーカスすることができます。
Wave の内側
Kubernetes と Wave でクラスタの管理をする
Kubernetes でビッグデータをデプロイメントできるようになる前、ユーザーは Spark のスケジューラー、Apache Mesos もしくは Hadoop YARN でクラスタを管理していました。これらのクラスタ マネージャーは Kubernetes によってリプレイスされ、コンテナの効率化とインフラ一元管理を実現しています。Kubernetes は YARN を使った Spark とは異なり、専用のクラスタを持たずに複数のデプロイメントを容易に行うことができます。
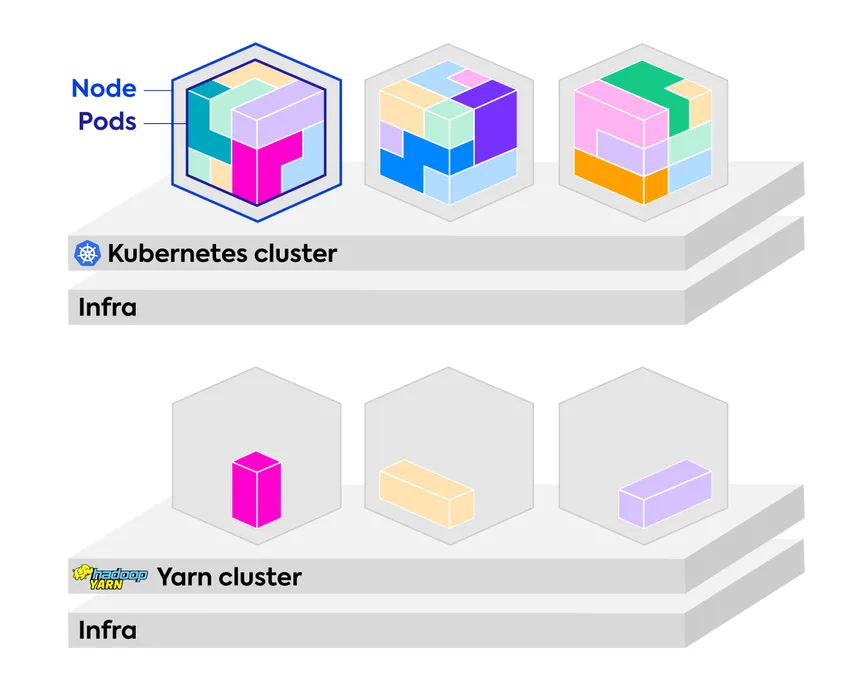
アプロケーションは共有リソースを利用しながら、お互いにそれぞれを切り離して運用することができ、Spark ジョブのノードへの割り当ても Kubernetes が行います。Kubernetes は効率性や管理の簡易化、アプリケーションのスケーラビリティをもたらしますが、Wave は Spark クラスタの完全に管理されたデータ プレーンを用いて様々な方法でこれらのメリットを基盤となるインフラに拡張します。
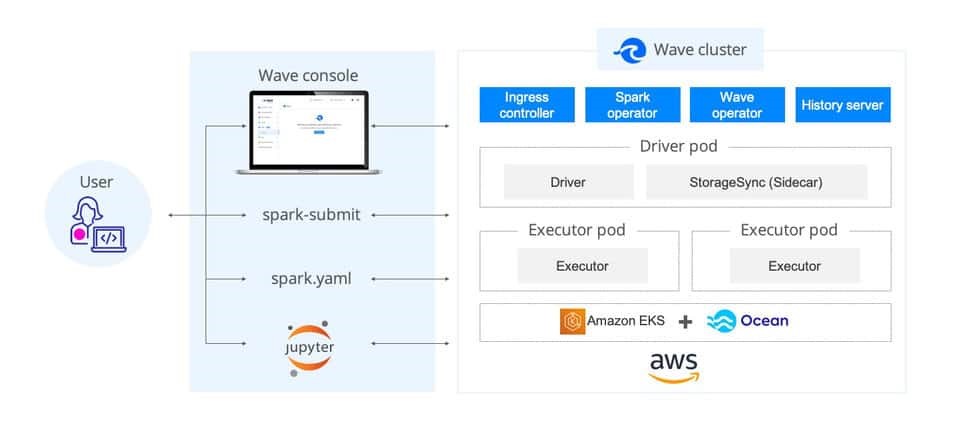
一度、環境に統合されると、Wave が Spark のエグゼキュータ ポッドのスケールアップやデプロイに必要なインフラの設定を行います。Wave はこれらのコア機能を使ってプロビジョニングや自動化スケーリング、管理やインフラクチャの最適化をすべて行います。
エンジンの最適化
Ocean と同様、 Wave はコンテナ駆動型のインフラを採用しています。高度な AI アナゴリズムを活用した、Wave の自動化スケーリング メカニズムはアプロケーションを最高のパフォーマンスで実行するため、自動的にベストなインフラを選択し、入力される Spark ジョブのリソース要件を管理します。入力されたワークロードの特定の要件を考慮しながら、 Wave は CPU や RAM などのリソースを予定されたポッズにリアルタイムで適合させます。
Spark アプリケーションのサイズの最適化
ビッグデータのアプリ―ケーションは多くの場合、リソース集約型であり、インジェストや処理、標準化に多くの計算能力が必要となってきます。しかし、アプリケーションが必要とするメモリや CPU、その他のリソースの量を見積もることは簡単なことではありません。特に、アプリケーションのリソースの消費を見積もったり、計画を立てたりすることに長けていないビッグデータチームにとっては大きな負担となるでしょう。
Wave のサイズ最適化の自動化機能はチームの抱える負担を減らし、デプロイメントとジョブのリソースの構成を改良する方法を提供します。実際の消費量と要求するリソースを長期的に比較することで、Wave は継続的に構成を調整し、ノードの過剰プロビジョンの回避や使用不足を防ぎ、十分なリソースのプロビジョンを実現します。
Spark エグゼキュータ ビン パッキング
高度なアルゴリズムを用いて、Wave は自動的かつ効率的に Spark エグゼキュータをビン パックし、既存のノードを最大限に活用してからインスタンスを追加します。また、Spark ジョブ特有の考慮事項を踏まえ、複数のコンテナが同じインスタンスに配置すべきか、複数のインスタンスに分散すべきかを判断し、リソースの割り当てを最適化します。
自動化されたヘッドルーム
ビッグデータのワークロードでは稼働率が低い時期と迅速なスケールアップが必要な時期があるのが一般的です。インフラは動作するアプリケーションのスケーラビリティに適合させることが重要であり、Wave の自動ヘッドルームの機能により、ユーザーはシステムがインフラのニーズに適応できることを確信できるでしょう。Wave はユーザーが追加ノードのプロビジョニングを持つことなく、追加のワークロードを瞬時にスケーリングできるよう、デフォルトの容量の余剰分を確保しています。
Wave をはじめよう!
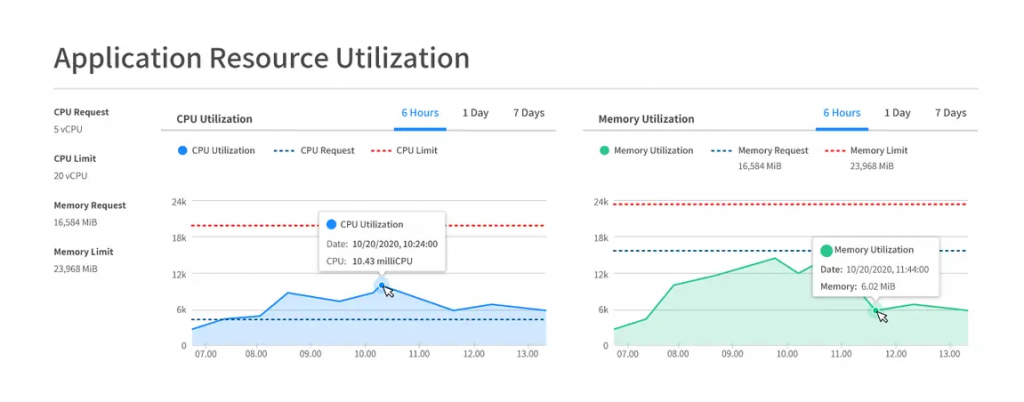
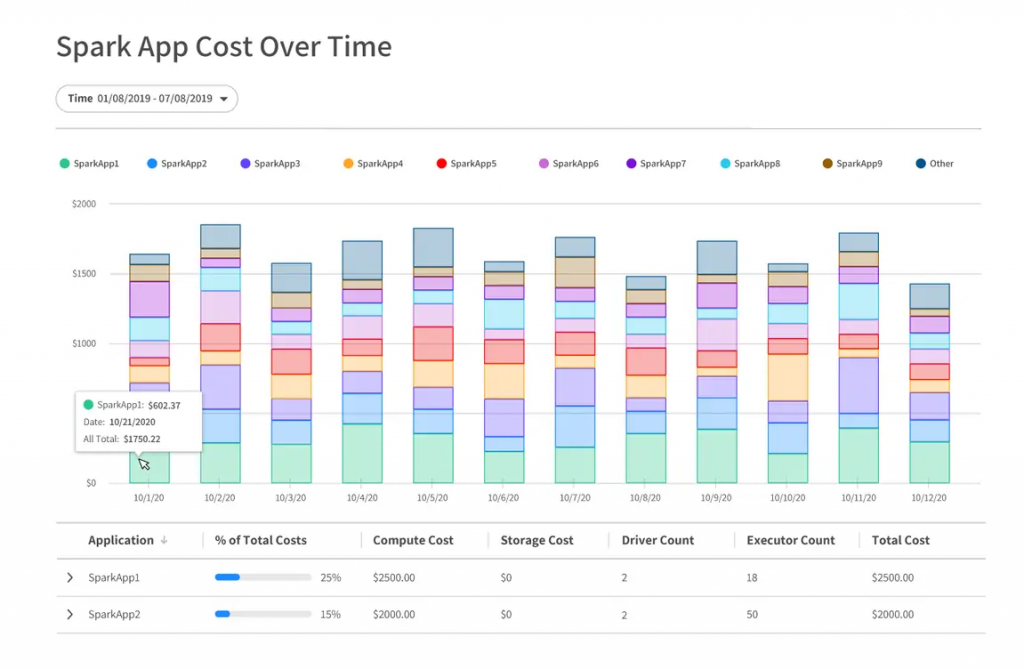
Wave の環境は Wave のインストールしたすべてのコンポーネントとインストールした Kubernetes のクラスタで構成されています。Wave のユーザーはコマンド ラインでのクラスタの作成や既存のクラスタを容易に Wave にインポートすることが可能です。ユーザーは Spot コンソールから直接 Wave にアクセスし、使用可能量やコスト分析、クラスタの状態などのメトリクスを確認することができます。
コストをかけず無償で Spot の製品を体験できるフリープランのご用意がございます。また有償プランにも無償評価版のご提供がございます。ぜひこの機会にお試しください。
無償体験に関するお問い合わせはこちらから。
Wave に関する詳しい情報は Wave 製品ページから、Spot のその他製品に関する情報はこちらからご覧いただけます。
記事参照 :
The Spot.io blog

