
このブログでは、Arm Allinea Studio 21.1 で追加された新機能とパフォーマンスの改善について紹介します。Arm Allinea Studio (AAS) は、Forge (DDT、MAP、パフォーマンス レポート)、Linux 用 Arm コンパイラ (ACfL)、Arm パフォーマンス ライブラリ (ArmPL) を組み合わせたものです。
Linux 用 Arm コンパイラ (ACfL) 21.1
Linux 用 Arm コンパイラ は、HPC およびクラウド ワークロード向けの「ベンダー コンパイラ」パッケージです。C、C++、Fortran コンパイラと Arm パフォーマンス ライブラリが含まれています。
LLVM12 アップデート
今回の ACfL のリリースでは、LLVM のバージョン 11 からバージョン 12 へのアップグレードが含まれています。もちろん LLVM 自体は常に改良されていますので、バージョン 11 からバージョン 12 への機能、パフォーマンス、安定性の全般的な向上が期待されます。
例えば、コードを素早くコンパイルし、それが正しいことを確認し、あらゆる状況で高速に動作することを確認する、ということなどです。
LLVM12 ベースの ACfL の内部ベンチマークでは、いくつかの業界標準ベンチマークで 1~ 2% の改善と、マイナーな性能後退が僅かに見られましたが、全体としては良好な結果となりました。
VLS (Vector Length Specific) SVE ACLE のサポート
Linux 用 Arm コンパイラは、ACLE (Arm C Language Extensions) コードとオート ベクタライズ コードの両方に SVE (Scalable Vector Extensions) のサポートが確立されていますが、どちらも SVE が許容するVLA (Vector Length Agnostic) パラダイムを使用しています。VLA SVE コードは一度コンパイルすれば、どの SVE 実装で実行してもうまくベクトル化されます。VLS (Vector Length Specific) SVEパラダイムは、コンパイル時に指定された固定ベクター幅の SVE 命令をターゲットとするもので、Linux 用 Arm コンパイラでは新しく採用されています。このタイプの SVE コードは、固定ベクター幅がコードに内在し、アルゴリズムで必要とされる場合、またはコードが固定幅ベクター用に大きく最適化されている場合に使用されます。新しいベクター幅に直面するたびにリコンパイルすることを気にしないユーザーにとっては、VLS SVE の方が VLA より望ましい場合もあります。場合によっては、(本質的に固定幅の) Neon ターゲットからの移行が容易になることもあります。
VLS SVE ACLE のサポートは LLVM 12 で完了したため、ACfL はアップストリームのマージの機能としてこの機能を継承しています。この新機能により、新しい ACLE 機能マクロと型属性 arm_sve_vector_bits が利用可能になり、これを使用して通常の SVE ACLE データ タイプを特定のベクトル幅に特化させることができるようになりました。この幅の値は、同等のコンパイラ コマンドライン オプション -msve-vector-bits=<number> によって設定されます。ユーザーはこれらの型を通常の SVE ACLE コードで使用することができますが、ベクトル幅については仮定します。
Arm パフォーマンス ライブラリ 21.1
Arm パフォーマンス ライブラリは、私たちの「ベンダー」である数学ライブラリ ソリューションです。主に高密度データを扱うベクトルや行列計算のための高性能ソリューションとして、HPC やクラウドのユース ケースで展開されています。さらに、ArmPL は、スパース線形代数、FFT、および libm 関数のためのソリューションを提供します。ArmPLは、無料のスタンドアロン製品としても、Arm Allinea Studio の Linux 用 Arm コンパイラの一部としても提供されています。
インターリーブ バッチ関数のための SVE カーネル
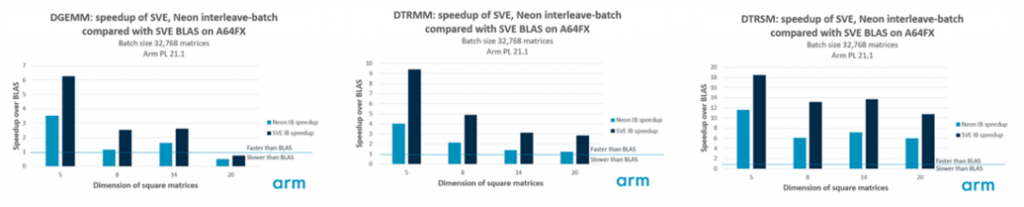
21.1 リリースでは、21.0 リリースで紹介したインターリーブ バッチ関数の一部に SVE カーネルを追加しています。インターリーブ バッチ関数は、画像信号処理、計算流体力学、流体力学、深層学習など多くの分野で適用可能な、大量の小さな行列を効率的に処理するのに役立ちます。これらの関数の設計の詳細については、このトピックのブログを参照してください。今回の変更点としては、Neon カーネルの改良と、一般的な行列-行列乗算 (armpl_dgemm_interleave_batch)、三角行列-行列乗算 (armpl_dtrmm_interleave_batch) および三角行列解 (armpl_dtrsm_interleave_batch) の新しい SVE カーネルがあります。これらの関数の SVE カーネルは、インターリーブ係数 ninter が SVE ベクトル長の 8 倍の倍数のときに最適化されます (ただし、関数は ninter のどの値でも正しく機能します)。例えば、A64FX でベクトル長 512 ビットの場合、倍精度実数データのベクトル長は 8 要素なので、ninter の推奨値は 64 ということになる。Neon カーネルでは、一般的にninter=16 の値が最も良い性能を発揮しました。
以下のグラフは、Arm PL 21.1 において、シングル A64FX コアを使用して、正方行列の次元の選択に対して32,768 個の行列のバッチを操作したときのインターリーブ バッチ関数の性能を示しています。この結果は、Arm PL の SVE BLAS 実装を使用して、同等のBLAS関数を繰り返し呼び出すよりも高速化されていることを示しています。それぞれのケースで、推奨されるインターリーブ係数を使用するようにインターリーブ バッチ レイアウトを適応させました。すなわち、Neon では ninter=16 および nbatch=2048、SVE ではninter=64 および nbatch=512 です。DGEMM の結果、A64FX ではサイズ 20 の行列に対してのみインターリーブ バッチ方式が有効であることがわかりました。それ以外のケースでは、インターリーブ バッチ方式は BLAS よりも数倍速く、我々の新しい SVE カーネルは Neon の同等品と比較して大幅に性能が向上しています。
Arm PL と Python
Numpy と Scipy を含む Python ホイールで使用するために Arm PL をパッケージ化することを許可するには、パッケージがどの Linux ディストリビューションにもインストールできることが条件となります。私たちのライブラリのビルドは、いくつかの一般的なLinux ディストリビューションに対して別々に行われ (例えば、無料の Arm PL のダウンロードリストを参照)、それぞれのビルドは特定のコンパイラと libgfortran や glibc などの関連ランタイム ライブラリに結び付いています。
Numpy の開発者から、Python パッケージを移植可能に構築するための manylinux 標準を指摘され、それに準拠した Arm PL のシリアル バージョンを構築することに成功しました。この作業の一部として、私たちは Arm PL が Fortran ランタイム ライブラリに依存していることを取り除く必要がありました (Python ユーザーが libgfortran を別途ダウンロードする必要がないようにするため)。その結果、移植可能なライブラリのシリアル ビルドができ、Numpy や Scipy と一緒にパッケージングすることができるようになりました。
Arm Forge 21.1
Arm Forge 21.1 のリリースにより、プラットフォームを問わず、HPC アプリケーション開発者向けのツールを更新しました。このリリースでは、GPU メモリ転送の可視化を通じて、アプリケーションのプロファイリングが強化されています。
GPUメモリ転送の可視化
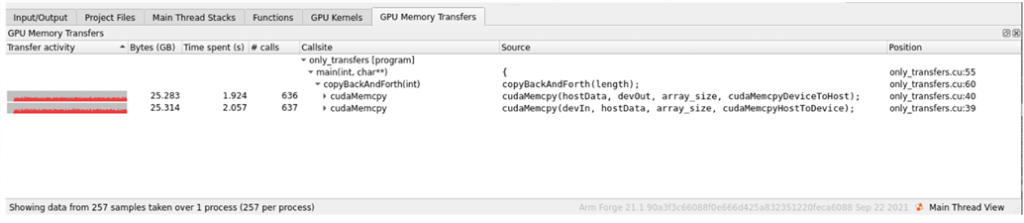
GPU のメモリ転送は、インターコネクトの帯域幅を大量に消費することがあります。異なる GPU に対してソフトウェアを最適化するユーザーは、特に大規模な場合、このトラフィックを可視化することで利益を得ることができます。現在、Arm MAP は、アクセラレータの待ち時間を表示しますが、実際の GPU 処理とメモリ転送のどちらに時間がかかっているかを簡単に表示することはできません。MAP の新しいメモリ転送プロファイリング機能は、有用な GPU 計算とメモリ転送のオーバーヘッドを区別し、ユーザーがソフトウェアを最適化するタイミングとヒントを与えることができます。
また、新しいMAP機能により、転送の種類を区別することができます。
- Host → GPU
- GPU → Host
- GPU → GPU
MAP はオプションで、メモリ転送が行われたスタック トレースとソース コードの位置を追跡して表示することができます。
その他の Forge の改善
- デフォルトの DDT デバッガーを GDB 10.1 にアップグレードしました。
- DDTのオプションデバッガとしてGDB 11.1を追加しました。
- ライブラリパスが不明で共有ライブラリをデバッグできない場合に、デバッガーがそれを通知する警告を追加しました。
- Linux 用 Arm コンパイラ 21.1 に対応しました。
- GCC 11のサポートを追加しました。
- BLAS の性能を向上しました。
その他のリソース
最新の Arm Allinea Studio リリースノート (英語) はこちらをご覧ください。
Arm Allinea Studio に関しての詳細はこちらからご覧いただけます。
参照記事: Arm Allinea Studio 21.1
