今、注目されているデータ サイエンスは、分析だけでなく、データの取り込みも大切な作業となってきます。検証したい仮説を立てたとしても、適切なデータを扱いやすい形で拾ってこられるかは分かりません。
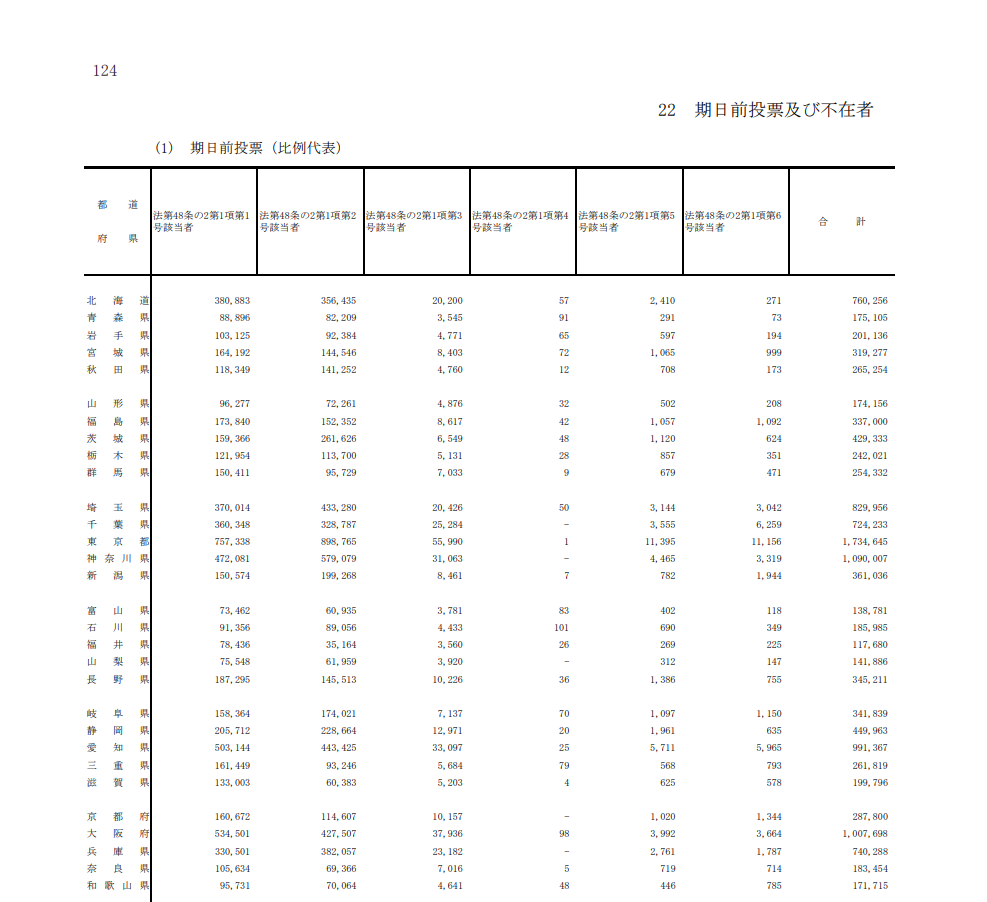
例えば、令和元年 7月 21日執行参議院議員通常選挙結果調(政府統計の総合窓口 e-Stat より)は、実施された選挙に関する様々なデータが掲載されていますが、PDF 形式で配布されていてデータとして扱いにくいです。Excel にコピー & ペーストしていくこともできますが、できるだけスマートに構造化したいものかと思います。
Altair の提供しているセルフサービス型データプレパレーションツール Altair Monarch は非構造化データをノーコードで読み取り、クレンジング、構造化を可能とします。
今回は Monarch を用いて、上部の PDF データを Excel 形式に出力してみようと思います。PDF などから、データを読み込むのに苦労した経験のある方は、是非参考にしてください。
PDF データの読み込み
読み取るのは選挙結果調べの 124 ページにある、「期日前投票(比例代表)」の表です。各都道府県と各理由別投票者数(例えば、「法第 48 条の 2 第 1 項第 1 号該当者」は仕事が理由で期日前投票に来た人です)が記されています。これを表形式で取り出します。
日本語を含むデータを扱う際には Monarch Classic を使用します。起動して、File -> Openから読み取りたいドキュメントを選択します。
読み取ると以下のような画面になります。
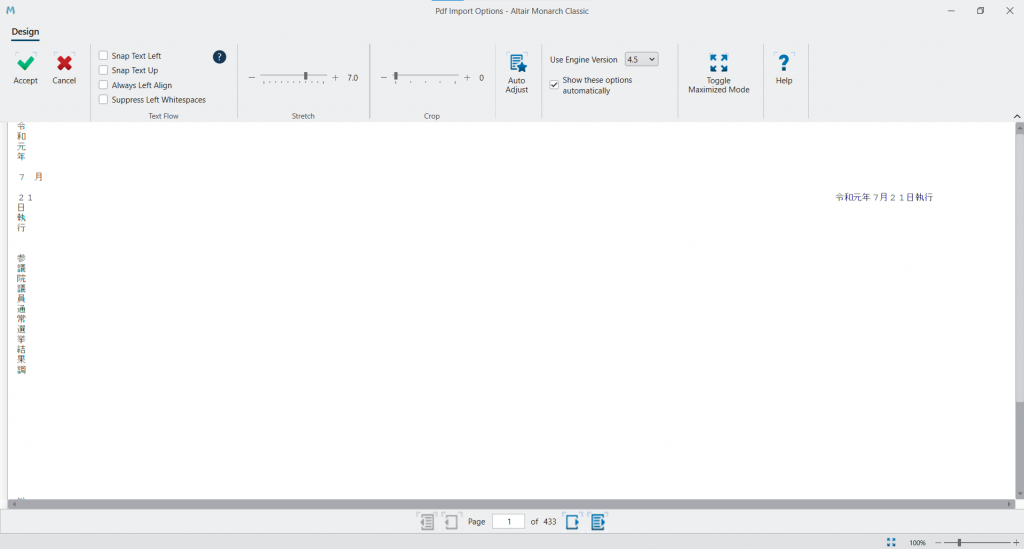
左上の Accept を押します。
次のこちらの画面では左上の ReportDesign を押します。
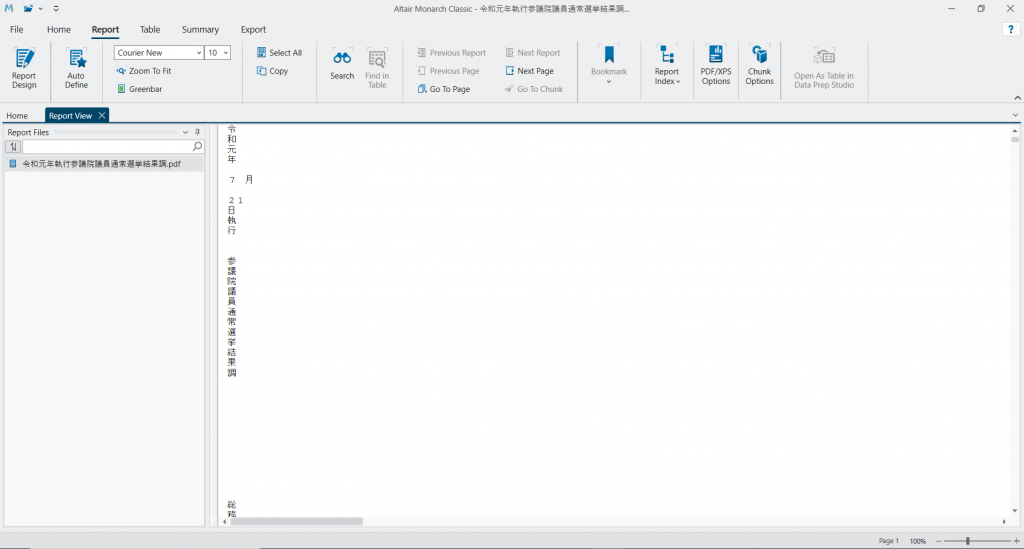
つづいて、New Template をクリックして Detail を選択します。
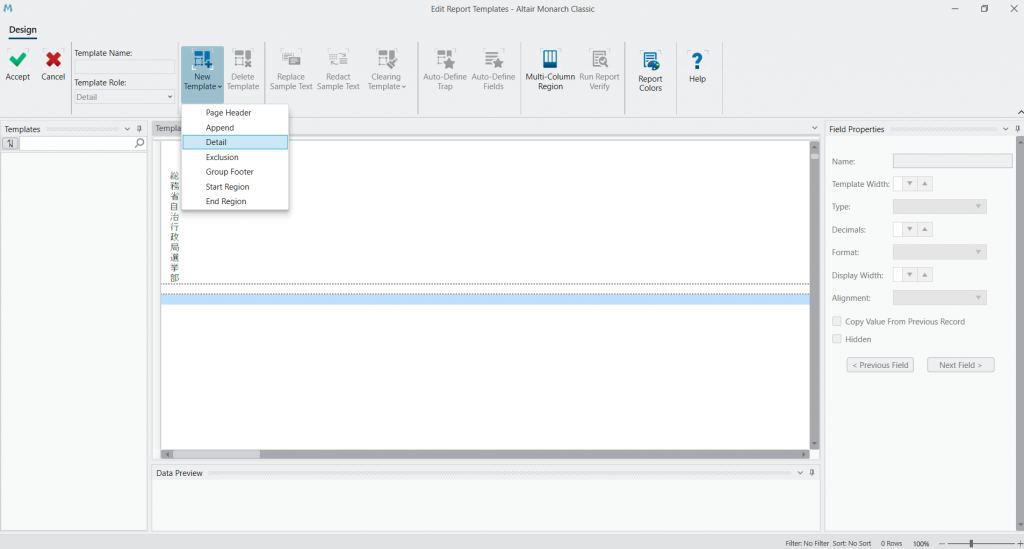
データを取り出したいページ(ここでは 124 ページ)に向かいます。
Monarch ではルールを使ってデータを取り出します。行に対して Trap を用いて規則性を与えて、その規則性に沿った情報を持つ行が選択されていく仕組みです。
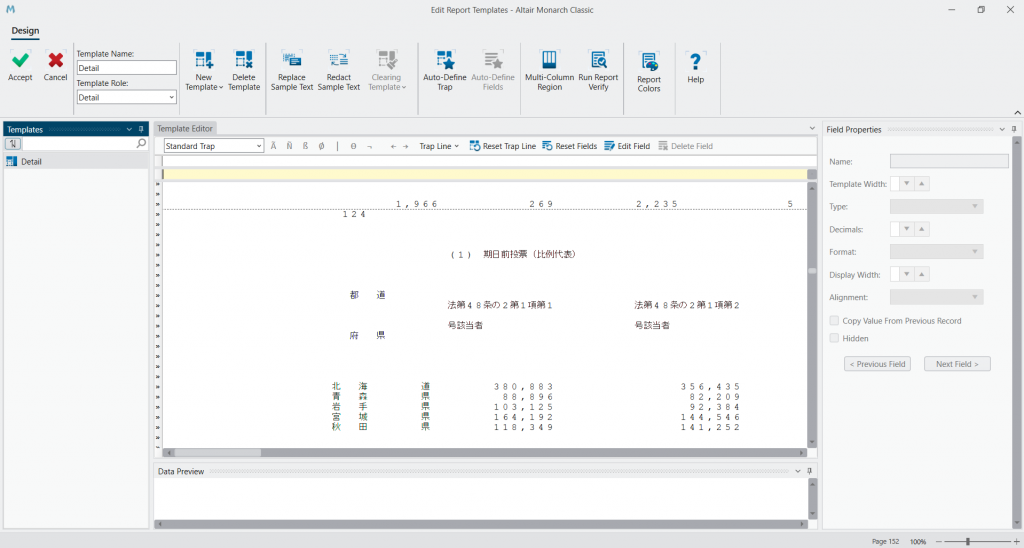
ルールの与え方は、その行が文字列をどこに持つか、数字をどこに持つか、空白をどこに持つかといった具合に決めていきます。Trap は、文字列は Ã、数字は Ñ、空白は β、空白ではない文字 (文字列や数字) には Φと いう具合に使用します。まずは都道府県の列を取り出したいので、入力欄に Ã を入力すると以下のようになります。
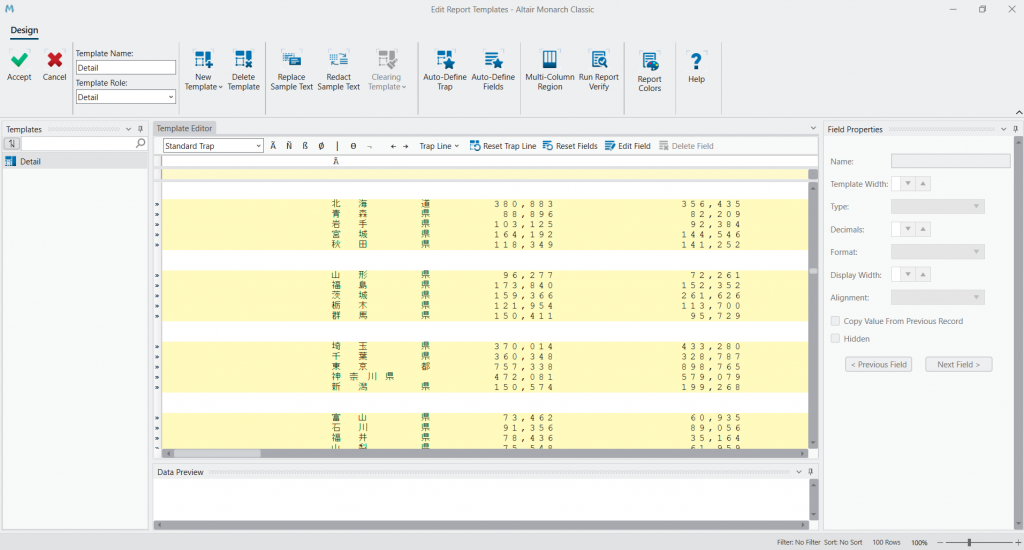
このように Ã を打った列に文字が含まれた行が選択されます。しかしこのままでは他ページの同じ行に文字を持つ、取り出すつもりのない部分も読み込んでしまうので同様にルール決めをしていって絞り込んでいきます。
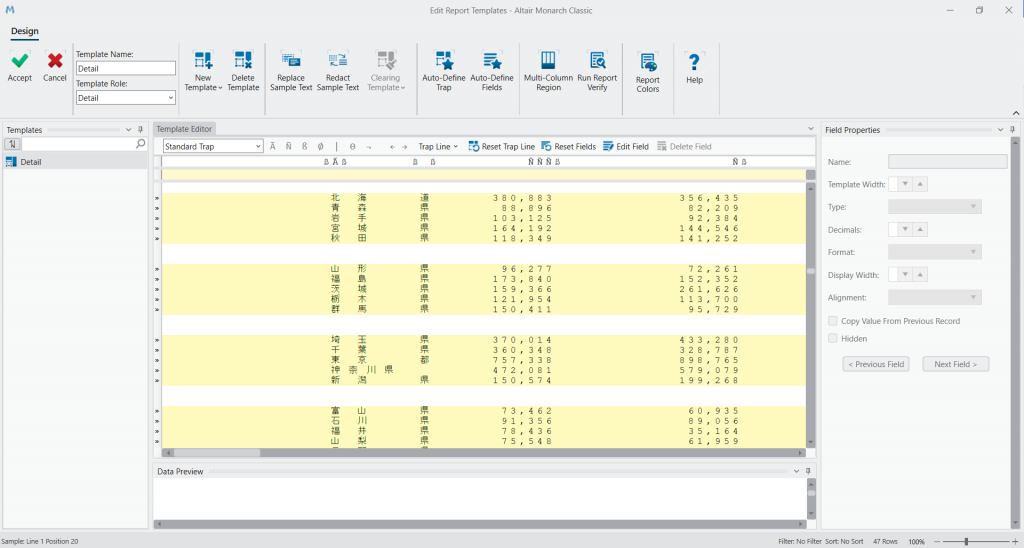
以下のように Trap を打っていきました。これで取り出したい 47 都道府県分の行が取り出せました。
次に、抽出したい列を選択していきます。Trap を打った欄の下に取り出したい部分をドラッグして選択していきます。Data Preview からも 47 行分適切に取り出せているのが分かります。
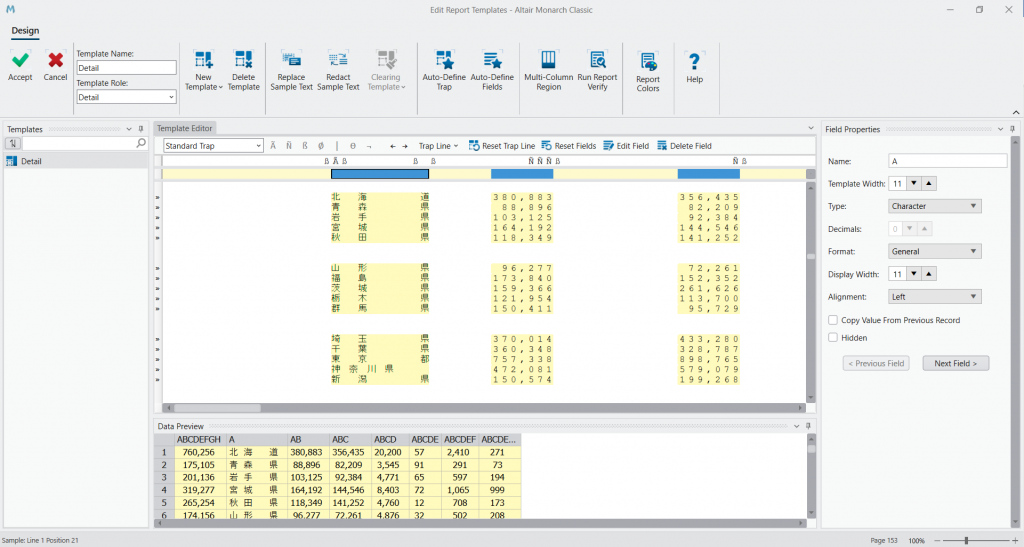
確認出来たら Accept を押して、Open As Table in Data Prep Studio を押して Altair Data Prep Studio でデータを開きます。
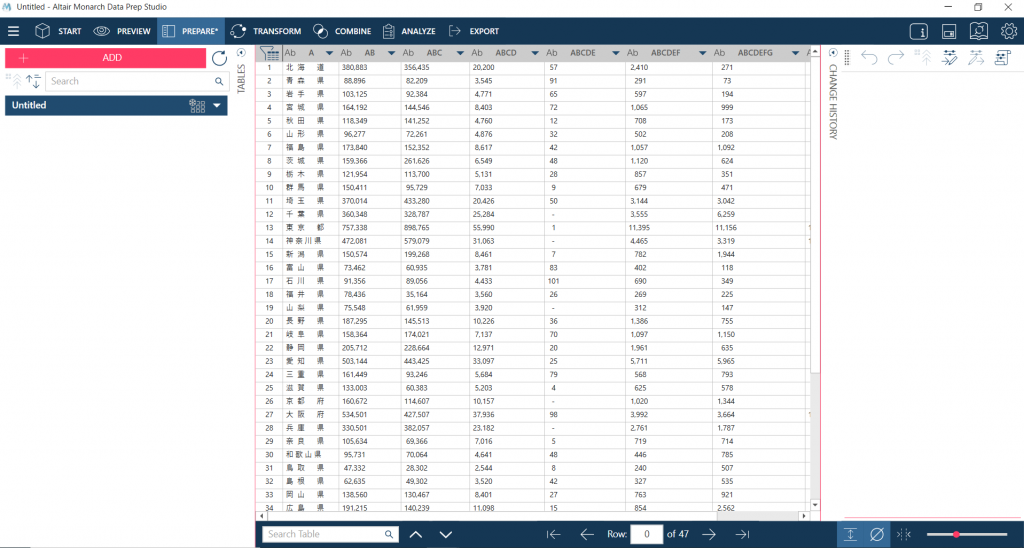
列を右クリックしてから Clean で空白を消す、Convert の Text To Number から投票数を文字型から数字型に変換するなどをして表を整えます。
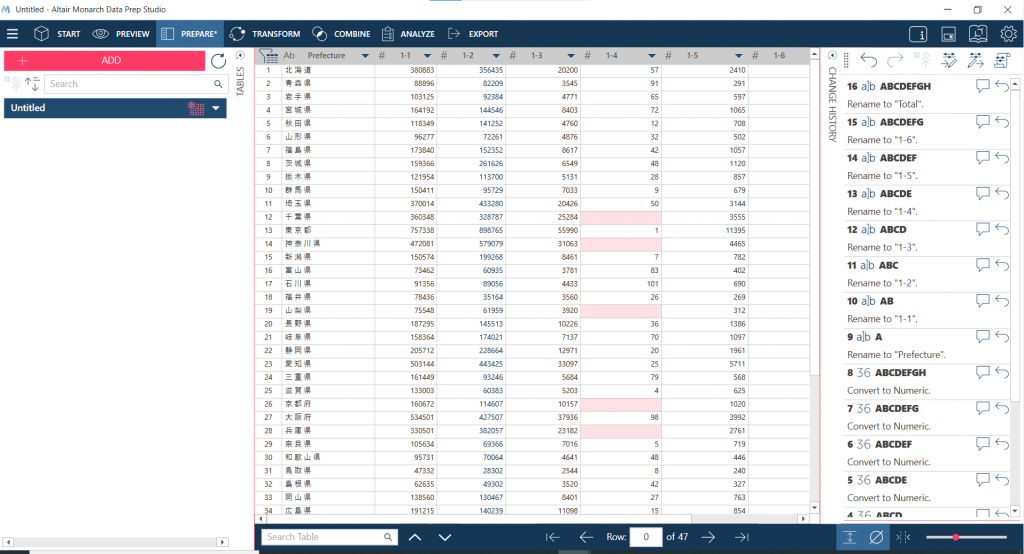
作成したデータは EXPORT のタブから以下のような様々な形式で出力できます。
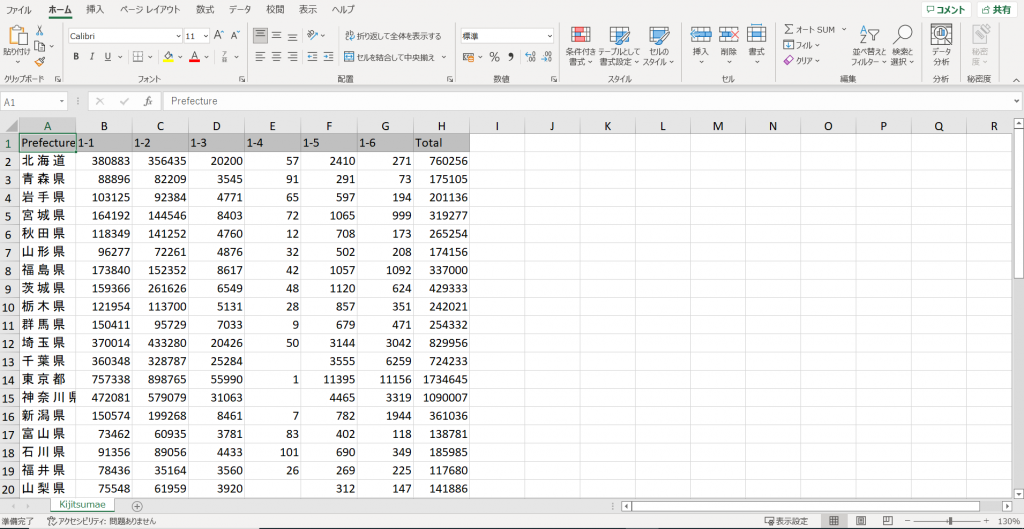
Excel での出力を確認できました。
おわりに
今回は、データの読み取りを行ってみました。PDF からデータを読み込めるのはとても便利で、Trap を使ったルール決めはパズル感覚で楽しくもありました。Monarch では PDF だけでなく、Web ページ上の表など様々な形式のデータを取り込めます。非構造化データの取り込みに苦労した経験のある方はぜひお試しください。
*本記事は、アルテアエンジニアリング株式会社が提供している以下の記事から抜粋・転載したものです。
PDF 形式のデータを分析したい!PDF データを瞬時に取り込むためのデータ準備ツール活用方法
