緊急の Slack 通知を受け取ったと想像してみてください。アプリケーションに重大な問題が見つかったことで、次の数時間は不安で緊張したものになるでしょう。
優れた可用性とパフォーマンスは、アプリの成功にとって重要です。アプリから必要なものを効果的に得られない場合、ユーザーは使用を中止して別の方法を探します。本番環境での効果的なインシデント管理は、ダウンタイムを最小限に抑え、顧客満足度を維持するために不可欠です。
インシデント対応に構造化されたアプローチを採用することで、開発チームは問題が発生したときに効率的に対処して解決する能力を向上できます。このプロセスを効率化する基本的な戦略をいくつか紹介します。
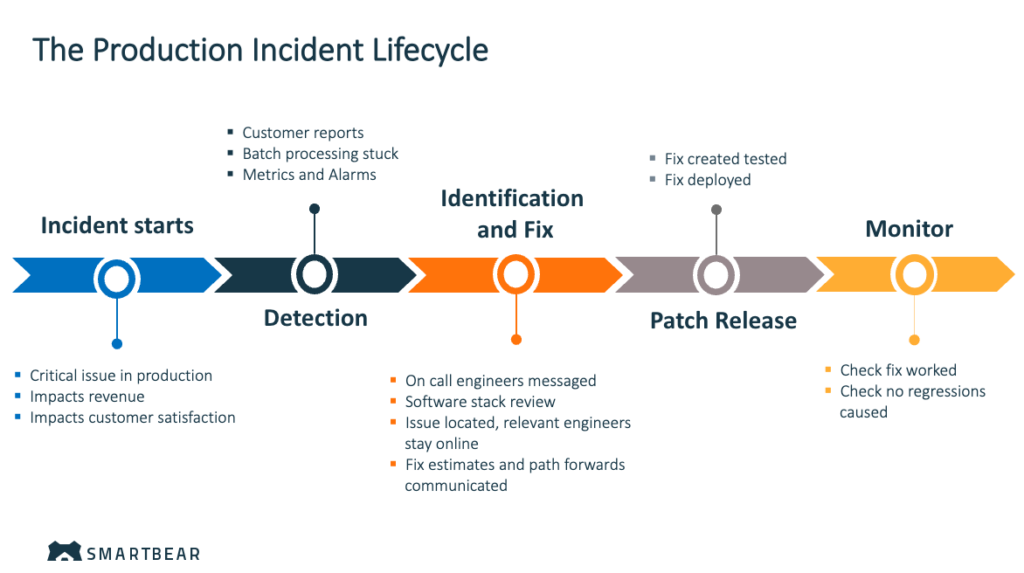
インシデントのライフサイクル
本番環境のインシデントのライフサイクルを理解することは、応答性の高いインシデント管理システムを開発する上で重要です。通常、次の段階が含まれます。
- 検出: 即時の検出が重要です。顧客が問題に気付く前にチームに警告する高度な監視システムを実装すると、応答時間を大幅に短縮できます。
- 診断: 問題が検出されると、エラーの性質と発生源に応じて関連するチームに自動的に警告がルーティングされるため、適切な専門家が遅滞なく動員されます。
- 解決: 迅速な解決には、協調的な取り組みが必要です。多くの場合、「作戦会議」などの共同アプローチを使用して、開発者、データベース管理者、およびその他の関係者を集め、解決策をブレインストーミングして修正を実装します。
- 事後分析と監視: 問題を解決後、問題の原因と今後の防止策を理解するため徹底的なレビューを行うことは、対応戦略を改善する上で重要です。
効率的なインシデント管理のためのツールと戦略
本番環境のインシデントに効率良く対処するには、適切なツールと戦略をワークフローに統合することが非常に有益です。
情報の一元化
ログとシステム データの一元的でアクセス可能なリポジトリを維持して、チームが問題を迅速に診断して対処できるようにします。これにより、アラートとトリアージがより迅速に行われるようになります。
アラート ルーティング
ホワイト ノイズを除去することが重要です。事前にフィルターを定義し、トリガーのしきい値を設定することで、チームがより迅速に作業を開始できます。この集中的なアプローチにより、初動までの時間が短縮され、解決プロセス全体がスピードアップします。
コードの所有権
エラーが発生する前に、誰がエラーを修正するかを明確にします。エラーの場所や種類に応じて、特定のチームに直接アラートを送信する割り当てルールを構成および定義します。タグ付けとフィルタリングのメカニズムを使用して、特定のコード セグメントの担当チームにエラーを割り当てます。これにより、問題がすぐに確認され、デバッグ プロセス全体を通じてチームの連携が保たれます。
機能フラグ
新機能や実験によってもたらされる問題を監視することで、リアルタイムのオブザーバビリティを実現します。新しいデプロイを管理する機能フラグを実装すると、チームは新しいコードをデプロイせずに機能を有効または無効にできます。そして、データに基づいてロールアウトするかロールバックするかを決定できます。
反復的な改善
過去のインシデントから学んだ教訓に基づいて、インシデント対応プロトコルを定期的に更新および改良し、応答時間と有効性を継続的に改善します。
これらのプラクティスを統合することで、組織は本番環境のインシデントに迅速かつ効果的に対応し、運用への影響を最小限に抑え、高いレベルの顧客満足度を維持できます。これらの戦略は、安定した信頼性の高いソフトウェア環境をサポートする回復力のあるインシデント管理システムの基盤を築くのに役立ちます。
エラーやパフォーマンスの問題をシームレスに検出、修正、防止できるツールをお探しの場合は、BugSnag をチェックしてみてください。BugSnag は、アプリケーションの安定性を向上させながら、ソフトウェアのバグに優先順位付けて修正するのに役立ちます。
BugSnag 製品に関する詳細、無料評価版は、こちら。
この資料は、SmartBear の Web サイトで公開されている「Rapid Incident Response: How to Minimize Downtime in Production」の日本語参考訳です。
