小売業や e コマース企業にとって、顧客データを効果的に活用することは、満足度の向上、顧客維持の強化、売上増加に不可欠です。しかし、感情検出、売上傾向の監視、解約予測などの高度な分析には、Excel 以外のツールが必要になることが多く、チームはプラットフォームを切り替えたり、追加のソフトウェアに頼らざるを得なくなります。Python が Excel に統合されたことで、Excel の使いやすさと Python の分析力を組み合わせて、これらの高度な手法をスプレッドシート内で直接利用できるようになりました。
この記事では、感情分析、売上傾向分析、解約予測の実際の応用例を通じて、Python in Excel が顧客データをどのように変革できるかについて説明します。製品に対する顧客の感情の特定から、サブスクリプションを解約する可能性のある顧客の予測まで、各例は、Python の機能により Excel の機能をシームレスに強化する方法を示しています。複雑な分析を簡単に実行し、データに基づく意思決定をこれまで以上に迅速かつ容易に行えるようになります。
Python in Excel を使い始めるには、「=py(」と入力するだけです。これでエディターが開き、スプレッドシートを離れることなく、Python 関数を適用したり、強力なライブラリにアクセスしたり、高度な分析を実行できます。顧客レビューの分析であれ、解約予測であれ、Python in Excel を使えば、どんなスキル レベルのチームでもデータ サイエンスに手が届くようになります。
Python in Excel を使用した顧客レビューの感情分析
毎日、顧客はレビューを残し、彼らの体験、満足度、さらには製品の改善に関する貴重な洞察を提供しています。しかし、大量のレビューを手作業で分析するのは時間がかかり、主観的なものになりがちです。Python in Excel は、スプレッドシート内で直接感情分析を可能にすることで効率的なソリューションを提供し、レビューを簡単に肯定的、否定的、または中立的に分類できます。
この例では、NLTK (Natural Language Toolkit、自然言語ツールキット) のテキスト処理ツールを使用して、顧客レビュー データの感情分析を実行する方法を説明します。このアプローチでは、カスタムの肯定的および否定的な単語リストを活用して感情を正確に分類し、複雑な設定なしで実用的な洞察を明らかにできます。
まず、レビュー データを Excel に読み込み、分析用にクリーンアップする必要があります。テキストと評価スコアなどの追加のメタデータを含む顧客レビューのデータセットがあると仮定します。データセットをインポートしたら、Python の Pandas ライブラリを使用してデータをフォーマットおよびクリーンアップし、感情分析の準備をします。
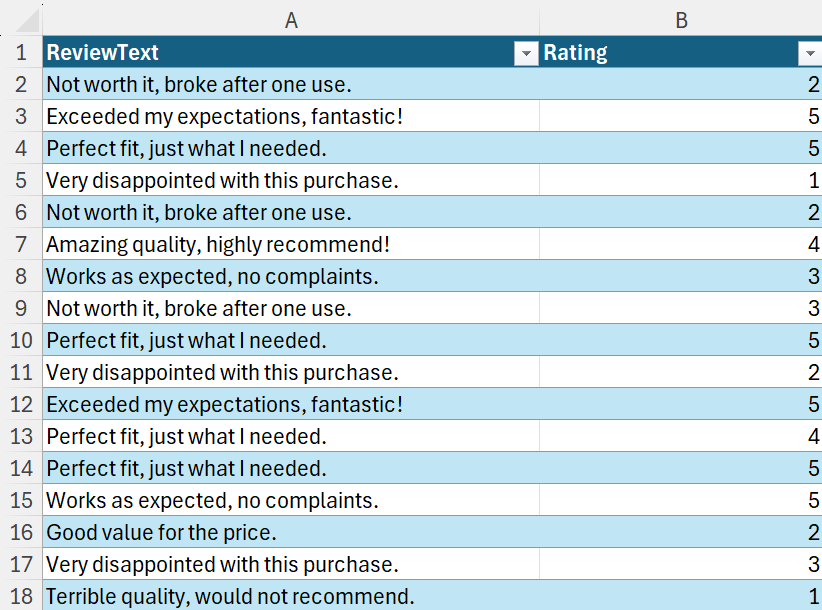
# Load review data from Excel
df = xl("Table3[#All]", headers=True)
# Import NLTK resources
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
# Define stopwords for cleaning
stop_words = set(stopwords.words('english'))
# Function to clean and tokenize text
def clean_text(text):
tokens = word_tokenize(text.lower()) # Lowercase and tokenize
return [word for word in tokens if word.isalpha() and word not in stop_words]
# Apply text cleaning
df['CleanedReview'] = df['ReviewText'].apply(clean_text)この簡単なセットアップにより、レビュー テキストと関連する評価を整理して表示し、感情を分析する基礎データを提供します。
追加のライブラリに依存することなく、肯定的および否定的な単語のカスタム リストを使用して感情を分類します。この方法では、肯定的または否定的な感情を示す単語の存在に基づいて、各レビューに感情が割り当てられます。
# Define positive and negative word lists
positive_words = ["good", "great", "excellent", "love", "amazing", "satisfied", "happy"]
negative_words = ["bad", "terrible", "poor", "hate", "disappointed", "unsatisfied", "worst"]
# Function to calculate sentiment based on word lists
def analyze_sentiment(review_tokens):
pos_count = sum(1 for word in review_tokens if word in positive_words)
neg_count = sum(1 for word in review_tokens if word in negative_words)
return "Positive" if pos_count > neg_count else "Negative" if neg_count > pos_count else "Neutral"
# Apply sentiment analysis
df['Sentiment'] = df['CleanedReview'].apply(analyze_sentiment)この分析では、各レビューにその極性を示す感情スコアが提供されます。クイック フィルターを使用すると、感情別にレビューをセグメント化できるため、顧客からのフィードバックの全体的なトーンを特定するのに役立ちます。
感情スコアを計算すると、肯定的、中立的、否定的なレビューの分布を視覚化できます。この概要により、顧客の全般的な感情をすばやく評価できます。
# Reorder the data with specific order and colorssentiment_order = ['Negative', 'Neutral', 'Positive']colors = ['red', 'grey', 'green']
# Plot with ordered categoriesdf['Sentiment'].value_counts().reindex(sentiment_order).plot( kind='bar', color=colors)
plt.title("Sentiment Analysis of Customer Reviews")plt.xlabel("Sentiment")plt.ylabel("Number of Reviews")sns.despine()plt.show()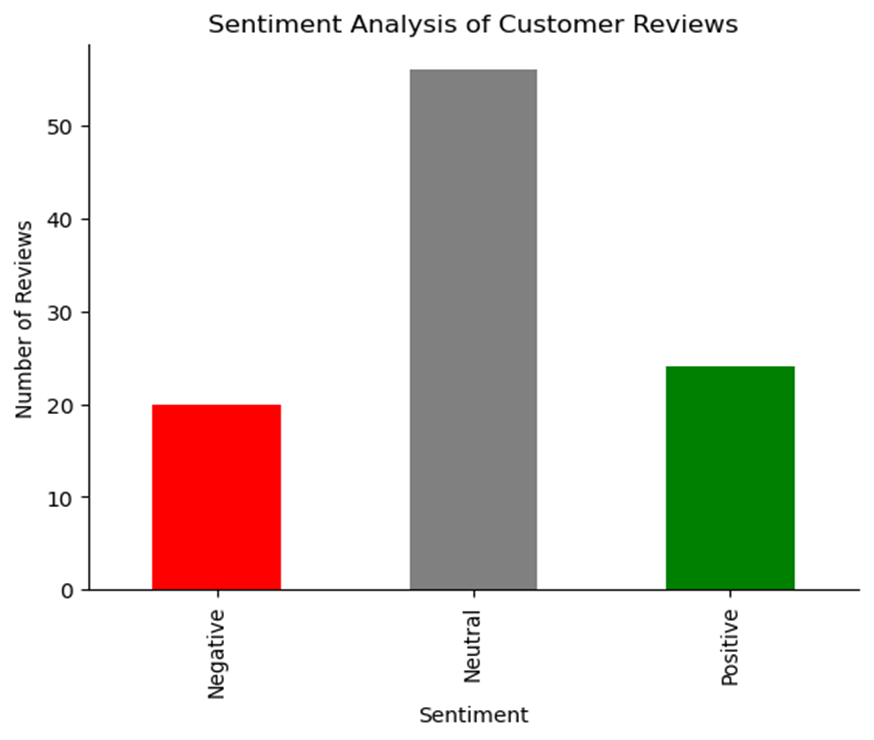
Python を使用して感情分析を Excel に統合することで、小売業や e コマース企業は顧客の感情をすばやく把握し、その情報を製品の改善、カスタマー サポート、マーケティング戦略に役立てることができます。Python のテキスト分析機能を使用すると、手作業で行う場合と比較してわずかな時間で数百または数千件のレビューを分類し、顧客満足度に関するタイムリーな洞察を得ることができます。このシームレスなワークフローにより、強力なテキスト分析が Excel に直接導入され、顧客洞察のための利用しやすい貴重なツールとなります。
Python in Excel を使用した製品カテゴリ別の売上傾向分析
小売業や e コマース企業にとって、製品カテゴリ別の売上傾向を理解することは、戦略的な計画と在庫管理に不可欠です。これらの傾向を分析することで、人気のある製品ラインを特定し、季節的な需要を予測し、それに応じて在庫レベルを調整できます。ただし、詳細な傾向分析を行うには、特に高度なデータ操作のためにツールを切り替える必要があります。Python in Excel を使えば、スプレッドシート内で直接、包括的な販売傾向分析を行うことができ、重要な洞察を簡単に視覚化し、行動に移すことができます。
この例では、Python in Excel を使って、商品カテゴリ別の月次売上傾向を分析し、どのカテゴリが伸びているのか、安定しているのか、あるいは減少しているのかを特定します。このアプローチは、傾向を明らかにするだけでなく、企業が商品の配置、プロモーション、仕入れについてデータに基づいた意思決定を下すことを可能にします。
ステップ 1: 売上データの読み込みと準備
まず、売上データを Excel に読み込み、Python を使って月ごと、カテゴリごとに整理します。商品カテゴリ、売上金額、日付を含むデータセットがあるとします。Python の Pandas ライブラリを使えば、このデータを時系列分析用にすばやく設定できます。
# Load sales data from Excel tabledf = xl("SalesData[#All]", headers=True)
# Group by month and category and sum the salesdf['Month'] = df['Date'].dt.to_period('M')monthly_sales = df.groupby(['Month', 'Category'])['Sales'].sum().reset_index()monthly_sales.Month = monthly_sales.Month.dt.to_timestamp()monthly_salesDataFrame の monthly_sales がセル E1 からグリッドにスピルするように、この Python セルの出力を「Excel values」に設定します。
これで、Anaconda Toolbox を使用して、売上傾向を視覚化するグラフをすばやく作成できます。
新しいグラフを作成し、Line Chart (折れ線グラフ) を選択して、Setup で次のように設定します。
[Design] タブで、カラー パレット、グラフのタイトル、線の幅などの視覚的な設定を行うことができます。
選択したら、[Preview] タブでグラフをプレビューできます。
オプションで、[Code] タブで生成されたコードを編集してグラフの外観を調整できます。
グラフの設定が完了したら、[Create] ボタンを押して、ワークブックのセルにグラフをロードできます。
完成したグラフは次のようになります。
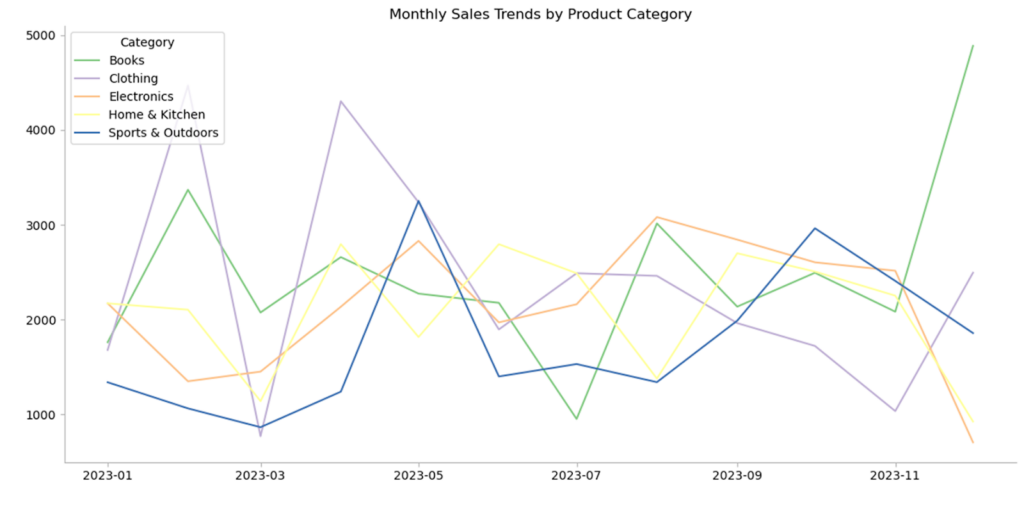
データが準備できたら、各カテゴリの販売動向を視覚化できます。Excel 内から利用できる Python の Matplotlib ライブラリを使用して各製品カテゴリの折れ線グラフを作成し、季節的なパターンや新たな傾向を一目で簡単に識別できます。
# Plot monthly sales trends by category
plt.figure(figsize=(10, 6))
for category in monthly_sales['Category'].unique():
category_data = monthly_sales[monthly_sales['Category'] == category]
plt.plot(category_data['Month'].astype(str), category_data['Sales'], label=category)
plt.title("Monthly Sales Trends by Product Category")
plt.xlabel("Month")
plt.ylabel("Sales")
plt.legend(title="Category")
plt.xticks(rotation=45)
plt.show()傾向を明確に可視化できたところで、どのカテゴリが最も好調かを数値化してみましょう。各カテゴリの総売上高を計算したり、最も成長率の高いカテゴリを特定することで、どの商品ラインが人気を集めていて、どの商品ラインに注意が必要かを正確に特定できます。
# Calculate total sales and growth rate for each category
category_summary = monthly_sales.groupby('Category')['Sales'].agg(['sum', 'mean'])
category_summary['Growth Rate'] = monthly_sales.groupby('Category')['Sales'].pct_change().fillna(0).mean()
# Sort categories by total sales to identify top-performing product lines
top_categories = category_summary.sort_values(by='sum', ascending=False)
top_categories| sum (合計) |
mean (平均) |
Growth Rate (成長率) |
|
| カテゴリ | |||
| 書籍 | 29880.73 | 2490.061 | 0.187185 |
| 衣料品 | 28519.73 | 2376.644 | 0.187185 |
| 電化製品 | 25819.73 | 2151.644 | 0.187185 |
| ホーム & キッチン | 25075.16 | 2089.597 | 0.187185 |
| スポーツ & アウトドア | 21248.69 | 1770.724 | 0.187185 |
Python in Excel を使用すると、製品カテゴリ別の売上傾向分析が合理化されたプロセスになります。Excel のワークフロー内で、どの商品カテゴリが売上を伸ばしているのか、月ごとの傾向を可視化し、成長率や総売上のような指標を計算できます。
Python のデータ分析機能と Excel の使い慣れた機能を組み合わせることで、小売業や e コマース企業は、追加のツールを必要とすることなく、タイムリーな洞察を得て、季節的な需要シフトに適応し、在庫レベルを最適化できます。このシームレスな統合により、アナリストも、技術者でないチーム メンバーも高度な傾向分析を活用できるようになり、全体的なビジネス パフォーマンスを向上させるスマートな意思決定を後押しします。
Python in Excel を使った e コマース顧客の解約予測
e コマース ビジネスにとって、顧客が利用を停止したり、サブスクリプションをキャンセルする顧客解約は重要な課題です。顧客が解約する理由を理解し、誰が解約するのかを予測することは、効果的なリテンション戦略を開発する上で非常に重要です。従来のツールでもある程度の分析は可能ですが、解約の予測にはより高度なテクニックが必要です。Python in Excel を使えば、スプレッドシート内で直接予測モデルを構築して、リスクの高い顧客を繋ぎとめるため積極的な措置を講じることができます。
この例では、Python を使用して、シミュレーションされた顧客データに基づいて、e コマース加入者の解約を予測します。過去の行動、人口統計、購入履歴のデータを組み合わせることで、リスクのある加入者にフラグを立てるモデルを開発できます。このアプローチにより、企業は最も必要とされるところに的確にリテンション活動を集中させることができます。
まず、人口統計、購入頻度、エンゲージメント スコアなどの関連機能を含む顧客データを読み込みます。このデータは、解約予測モデルの入力として使用されます。
# Load subscriber data from Excel
df = xl("SubscribersData[#All]", headers=True)データには、年齢、エンゲージメント スコア、平均購入額、「Churn」列 (加入者の解約状況を示すバイナリ値) などの特徴が含まれている必要があります。このデータが予測モデルの基礎となります。
Python の scikit-learn ライブラリを使用して、解約予測などのバイナリ分類問題でよく使用される基本的なロジスティック回帰モデルを開発できます。ロジスティック回帰は明確な解釈を提供し、各特徴が解約確率に与える影響を理解しやすくします。
from sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import accuracy_score, classification_reportfrom sklearn.preprocessing import StandardScaler
# Separate features and targetX = df[['Age', 'EngagementScore', 'AvgPurchaseValue', 'NumPurchases']] # Feature columnsy = df['Churn'] # Target column
# Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize the scaler and fit it to the training datascaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
model = LogisticRegression()model.fit(X_train, y_train)
y_pred = model.predict(X_test)
# Evaluate model performanceprint("Accuracy:", accuracy_score(y_test, y_pred))print(classification_report(y_test, y_pred))| Accuracy: 0.66 | ||||
| precision | recall | f1-score | support | |
| 0 | 0.67 | 0.64 | 0.65 | 75 |
| 1 | 0.65 | 0.68 | 0.67 | 75 |
| accuracy | 0.66 | 150 | ||
| macro avg | 0.66 | 0.66 | 0.66 | 150 |
| weighted avg | 0.66 | 0.66 | 0.66 | 150 |
このモデルは、各加入者のデータに基づいて解約の可能性を計算します。accuracy (正確さ) や precision (精度) といった指標は、モデルの有効性を評価するのに役立ち、必要であればさらに改良するための基礎となります。
モデルをトレーニングしたら、データセット全体に適用して、解約のリスクがある加入者を予測できます。このリストにより、企業は最もリスクの高い加入者に対するリテンション戦略を優先できます。
# Predict churn probabilities for all subscribers
df['ChurnProbability'] = model.predict_proba(X)[:, 1]
# Identify subscribers with a high churn probability
at_risk_subscribers = df[df['ChurnProbability'] > 0.5] # Threshold for high risk
at_risk_subscribers.head()| Customer | Age | EngagementScore | AvgPurchaseValue | NumPurchases | Churn | ChurnProbability |
| 0 | 56 | 0.46 | 271.71 | 45 | 1 | 0.930341 |
| 1 | 46 | 0.55 | 231.57 | 18 | 0 | 0.999997 |
| 3 | 60 | 0.39 | 288.63 | 21 | 0 | 1 |
| 4 | 25 | 0.96 | 94.52 | 15 | 0 | 0.662107 |
| 6 | 56 | 0.2 | 433.66 | 35 | 1 | 1 |
ChurnProbability 列には、各加入者の解約リスクを表す 0 から 1 までのスコアが表示されます。確率が 0.5 を超える加入者は、高リスクとしてフラグが立てられます。
Python in Excel を使用することで、e コマース企業はスプレッドシート環境を離れることなく、解約予測を効率よく行うことができます。ロジスティック回帰を使用することで、リスクのある加入者にフラグを立て、ターゲットを絞った介入によってリテンションを向上させる、シンプルでありながら効果的なモデルを構築できます。このアプローチは、時間を節約し、非技術系チームが Excel で直接高度な分析を取り入れることを可能にします。
まとめ
Python を Excel に統合することで、小売業や e コマース企業は、使い慣れた Excel 環境を離れることなく、データ分析を次のレベルに引き上げることができます。顧客からのフィードバックをすばやく把握できる感情分析から、在庫を最適化できる傾向分析、解約リスクの高い加入者を特定する解約予測モデルまで、Python in Excel は、効果的な意思決定を可能にする包括的なツールキットを提供します。
この統合により、外部ソフトウェアの必要性がなくなり、非技術系チームでも高度な分析を簡単に活用できるようになります。両方のツールの強みを組み合わせることで、小売業や e コマース企業は、生データを、マーケティングやカスタマー サービスから在庫やリテンション戦略まで、すべてをサポートする実用的な分析情報に変換できます。Python の初心者も、経験豊富なアナリストも、Python in Excel を使用することで、使い慣れたソフトウェア内でデータを活用して競争上の優位性を獲得できます。
2024 © Anaconda Inc. 「Python in Excel for the Retail and E-Commerce Industry」
