

はじめに
oneAPI は、中央処理装置 (CPU)、グラフィックス処理装置 (GPU)、フィールド・プログラマブル・ゲート・アレイ (FPGA)、その他のアクセラレーターにまたがるデータセントリックなワークロードの開発と導入を容易にするために設計された、オープンで統一されたプログラミング・モデルです。ヘテロジニアス計算環境では、開発者は各計算アーキテクチャーの能力と限界を理解し、適切なワークロードを各計算デバイスに効果的に適合させる必要があります。
この記事には以下の内容が含まれています。
- CPU、GPU、FPGA のアーキテクチャーの違いを比較する
- データ並列 C++ (DPC++) の言語構造が各アーキテクチャーにどのようにマッピングされているかを示す
- ライブラリーのサポートの違いを調べる
- 各アーキテクチャーに最適なアプリケーションの特性について
CPU、GPU、FPGA の計算アーキテクチャーの比較
[CPU アーキテクチャー]
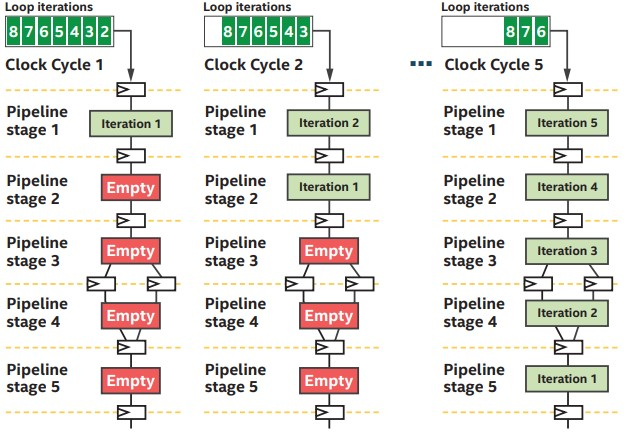
ここで取り上げる計算アーキテクチャーの中で、半世紀以上の歴史を持つ CPU は、最もよく知られており、多く普及しているものです。CPU アーキテクチャーは、シリアル命令を効率的に処理するように設計されているため、スカラー・アーキテクチャーと呼ばれることもあります。CPU は、さまざまな技術を駆使して、命令レベルの並列処理 (ILP) を高めるように最適化されており、シリアルプログラムをできるだけ高速に実行できるようになっています。
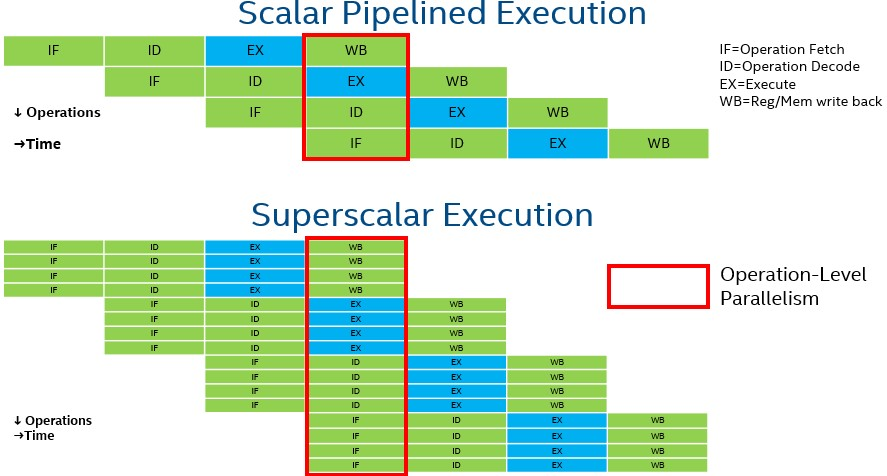
パイプライン化されたスカラー型 CPU コアは、命令の依存関係がない場合、1 クロックサイクルあたり最大 1 命令 (IPC) の割合で、段階的に命令を実行することができます。最近の CPU コアは、性能を向上させるために、命令レベルの並列処理を見つけ、クロックサイクルあたり複数のアウトオブオーダー命令を実行するための高度なメカニズムを備えたマルチスレッド・スーパースカラー・プロセッサーとなっています。一度に多くの命令をフェッチし、それらの命令の依存関係グラフを見つけ、洗練された分岐予測メカニズムを利用して、それらの命令を並列に実行します (通常、IPC の観点から見て、スカラー・プロセッサーの 10 倍の性能を発揮します)。
以下の図は、スカラー・パイプライン CPU とスーパースカラー CPU の簡単な実行例です。
GPU や FPGA などのコプロセッサーにオフロードする場合と比較して、演算に CPU を使用することには多くの利点があります。まず、データをオフロードする必要がないため、データ転送のオーバーヘッドを最小限に抑えてレイテンシーを軽減することができます。また、高周波数の CPU はスカラー実行を最適化するようにチューニングされており、ほとんどのソフトウェア・アルゴリズムはシリアルな性質を持っているため、最新の CPU でも高いパフォーマンスを容易に実現することができます。
ベクトル並列化が可能なアルゴリズムの部分については、最新の CPU はインテル® アドバンスト・ベクトル・エクステンション 512 のような SIMD (Single Instruction Multiple Data) 命令をサポートしています。その結果、CPU はさまざまなワークロードに対応することができます。大規模並列のワークロードであっても、特にデータサイズと計算量の比率が高い場合、分岐が多いアルゴリズムや命令レベルの並列性が高いアルゴリズムでは、CPU がアクセラレーターよりも優れた性能を発揮します。
[CPU の利点]
- アウトオブオーダーでのスーパースカラー実行
- 高度な制御で圧倒的な命令レベルの並列処理を引き出す
- 正確な分岐予測が可能
- シーケンシャル・コードの自動並列処理
- 豊富な対応命令数
- オフロード・アクセラレーションに比べて低レイテンシー
- シーケンシャル・コードを実行することで、開発のしやすさを実現
[GPU アーキテクチャー]
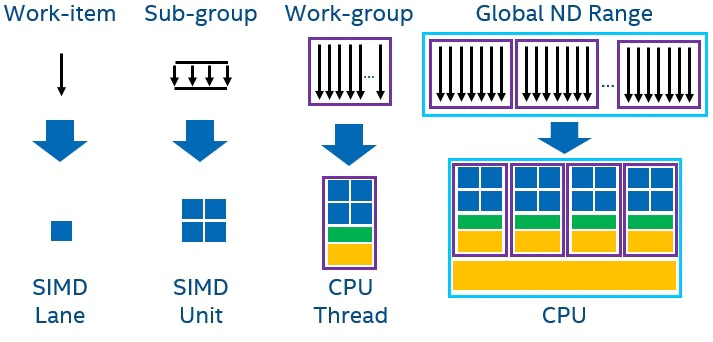
GPU は、一般的な高性能 CPU に比べて、より小型で特殊なコアを大規模に並列化したプロセッサーです。GPU アーキテクチャーは、個々のスレッドのレイテンシーやパフォーマンスを重視し、すべてのコアのスループットを集約するように最適化されています。GPU アーキテクチャーは、ベクトルデータ (数値の配列) を効率的に処理するため、ベクトル・アーキテクチャーと呼ばれることもあります。GPU は、より多くのシリコンスペースを計算に割り当て、より少ないスペースをキャッシュや制御に割り当てます。その結果、GPU ハードウェアでは、命令レベルの並列処理が少なくなり、ソフトウェアによる並列処理に頼って性能や効率を実現しています。
GPU はインオーダー・プロセッサーであり、高度な分岐予測をサポートしていません。その代わり、膨大な数の ALU (算術論理演算ユニット) と深いパイプラインを備えています。パフォーマンスは、大規模で独立したデータのマルチスレッド実行によって実現され、単純な制御と小さなキャッシュのコストが償却されます。GPU は、マルチスレッディングと SIMD を併用する SIMT (Single Instruction Multiple Thread) 実行モデルを採用しています。SIMT モデルでは、複数のスレッド (ワークアイテム、または SIMD レーンの一連の操作) が、同じ SIMD 命令ストリームでロックステップ処理されます。複数の SIMD 命令ストリームが 1 つの実行ユニット (EU) にマッピングされており、GPU の EU は、あるストリームが停止したときに、それらの SIMD 命令ストリーム間でコンテキスト・スイッチを行うことができます。
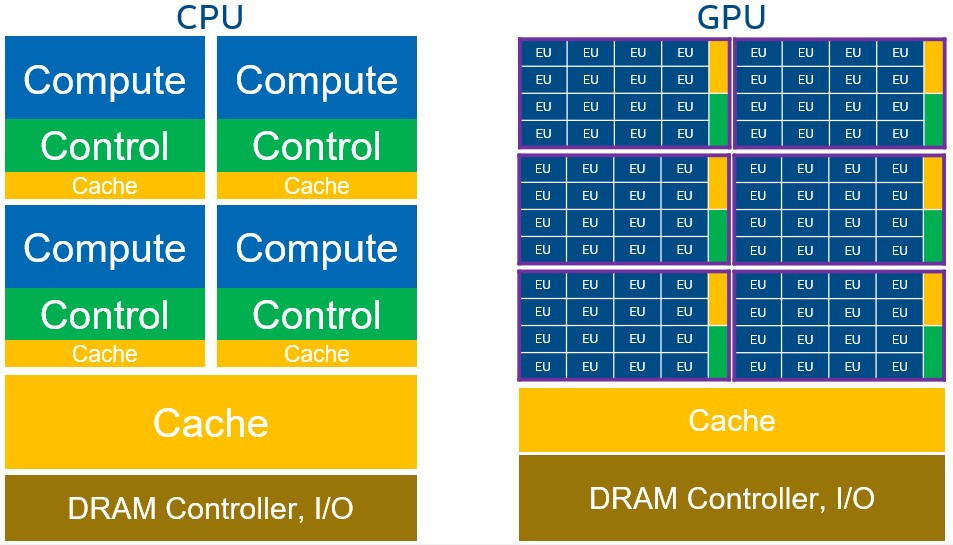
上の図は、CPU と GPU の違いを表しています。EU は、GPU における処理の基本単位です。各 EU は、複数の SIMD 命令ストリームを処理できます。同じシリコンスペースでは、GPU の方が CPU よりも多くのコア/EU が含まれています。GPU は階層的に構成されています。複数の EU が結合して、ローカルメモリーと同期メカニズムを共有する計算ユニットを形成します (サブスライスまたはストリーミング・マルチプロセッサーと呼ばれる、紫色のアウトライン)。その計算ユニットが組み合わされて GPU となります。
[GPU の利点]
- 大規模並列、最大数千もの小さく効率的な SIMD コア/EU
- データ並列コードの効率的な実行が可能
- 高いダイナミック・ランダム・アクセス・メモリー (DRAM) 帯域幅
[FPGA アーキテクチャー]
CPU や GPU がソフトウェアでプログラム可能な固定のアーキテクチャーであるのに対し、FPGA は再構成可能であり、その計算エンジンはユーザーが定義します。FPGA をターゲットとしたソフトウェアを記述する場合、コンパイルされた命令は、FPGA ファブリック上に空間的に配置されたハードウェア・コンポーネントとなり、それらのコンポーネントはすべて並列に実行することができます。このため、FPGA アーキテクチャーは「空間アーキテクチャー」と呼ばれることもあります。
FPGA は、最大数百万個のプログラム可能な 1 ビットのアダプティブ・ロジック・モジュール (ALU、それぞれが 1 ビットの ALU のように機能します)、最大数万個の設定可能なメモリーブロック、可変精度の浮動小数点演算および固定小数点演算をサポートするデジタル信号処理 (DSP) ブロックと呼ばれる数万個の演算エンジンから構成される、小さな処理装置の巨大なアレイです。これらのリソースはすべて、必要に応じて起動できるプログラマブル・ワイヤーのメッシュで接続されています。
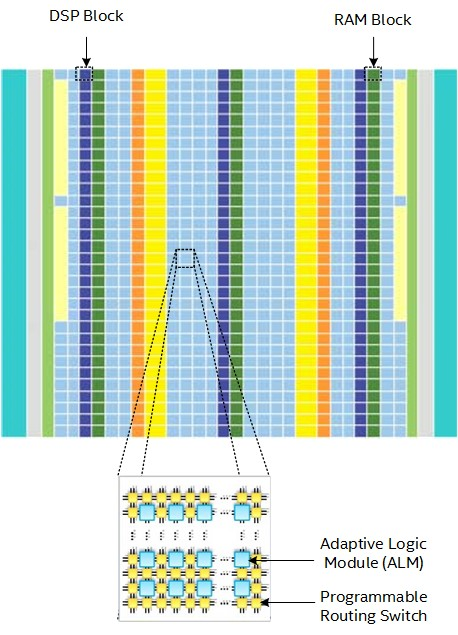
ソフトウェアが FPGA 上で「実行」されるとき、それは CPU や GPU 上でコンパイルやアセンブルされた命令が実行されるのと同じ意味ではありません。代わりに、ソフトウェアで表現された操作に合わせてカスタマイズされた FPGA 上の深いパイプラインをデータが流れます。データーフロー・パイプラインのハードウェアがソフトウェアと一致しているため、制御のオーバーヘッドがなくなり、性能と効率が向上します。CPU や GPU では、命令ステージがパイプライン化されており、クロックサイクルごとに新しい命令が実行されます。FPGA では、演算がパイプライン化されており、異なるデータを扱う新しい命令ストリームが毎クロックごとに実行されます。

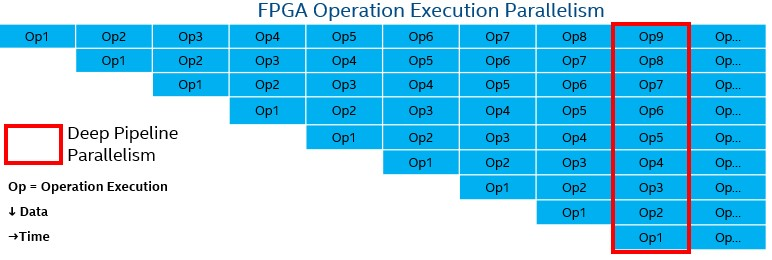
FPGA の並列処理はパイプライン並列処理が主流ですが、ほかの並列処理と組み合わせることもできます。例えば、データ並列処理 (SIMD)、タスク並列処理 (複数のパイプライン)、スーパースカラー実行 (複数の独立した命令を並列で実行) などをパイプライン並列処理と組み合わせて利用することで、最大の性能を得ることができます。
[FPGA の利点]
-
- 効率性: ソフトウェアのニーズに合わせてデータ処理パイプラインをチューニングする。制御ユニット、命令フェッチユニット、レジスター・ライトバックなどが不要で実行時のオーバーヘッドがない。
- カスタム命令: CPU/GPU がネイティブにサポートしていない命令を FPGA に簡単に実装し、効率的に実行することが可能 (ビット操作など)。
- 並列作業中のデータの依存関係を、パイプラインを停滞させることなく解決できる。
- 柔軟性: FPGA は、異なる機能やデータタイプ (非標準のデータタイプを含む) に対応するために再構成が可能。
- アルゴリズムに合わせてカスタマイズされたオンチップメモリーのトポロジー: アクセスパターンに合わせて構築された広帯域のオンチップメモリーにより、ストールの発生を最小限またはゼロに抑えることができる。
- 豊富な I/O: FPGA コアは、さまざまなネットワーク、メモリー、カスタム・インターフェイスやプロトコルと直接やりとりして、低遅延で確定的なソリューションを実現できる。
oneAPI と DPC++ の CPU、GPU、FPGA へのマッピング
このセクションでは、oneAPI および DPC++ の実行が、CPU、GPU、および FPGA の実行ユニットにどのようにマッピングされるかを調べていきます。
NDRange Kernel
auto total = range{N};
auto wg_size = range{256};
queue{}.submit([&](handler& h) {
accessor out{input_buf, h};
accessor in{output_buf, h};
h.parallel_for(nd_range{total, wg_size},
[=](auto i) {
// kernel
out[i] = process(in[i]);
});
});
Singel Task Kernel
queue{}.submit([&](handler& h) {
accessor out{input_buf, h};
accessor in{output_buf, h};
h.single_task( [=] {
// kernel
for (int i=0; i<N; i++) {
out = process(in[i], out);
}
});
});
上記は、NDRange と single_task の 2 種類の DPC++ カーネルを示しています。このセクションでは、これらの 2 つのカーネルとその並列処理が、異なるアーキテクチャー上でどのように実行されるかを検証します。左側では、NDRange カーネルのラムダが parallel_for を使用して N 個のワークアイテム (スレッド) にまたがってデータ並列で起動され、それぞれ 256 個のワークアイテムで構成される N/256 ワークグループに分割されています。NDRange カーネルは本質的にデータ並列です。右側では、ラムダ式を実行するために 1 つのスレッドのみが起動していますが、カーネル内部ではデータ要素を反復して実行するループがあります。single_task を使用すると、ループの反復にわたって並列処理が行われます。
[CPU の実行]
CPU の性能を発揮するためには、いくつかの種類の並列処理が必要です。SIMD データ並列処理、命令レベルの並列処理、そして複数のスレッドが異なる論理コア上で実行されるスレッドレベルの並列処理、これらすべてが活用されます。これらのタイプの並列処理は DPC++ では以下の方法で実現できます。
(1) SIMD データの並列処理:
- (同一ワークグループの) 各ワークアイテムは、CPU の SIMD レーンにマッピングすることができる。ワークアイテム (サブグループ) は、SIMD 方式で一緒に実行される。
- ベクトルデータ型を使って、SIMD 演算を明示的に指定することが可能。
- コンパイラーはループのベクトル化を行い、SIMD コードを生成することができる。1 つのループの反復は、CPU の SIMD レーンに対応する。複数のループの反復は、SIMD 方式で一緒に実行される。
(2) CPU コアとハイパースレッドの並列処理:
- 異なるワークグループを異なる論理コア上で並列で実行できる。
- 16 コア、32 ハイパースレッドのマシンでは、32 のワークグループを並列に実行することが可能。
(3) 従来の命令レベルの並列処理:
- 従来のシーケンシャルなソフトウェア実行のように、CPU の高度な制御によって実現される。
[GPU の実行]
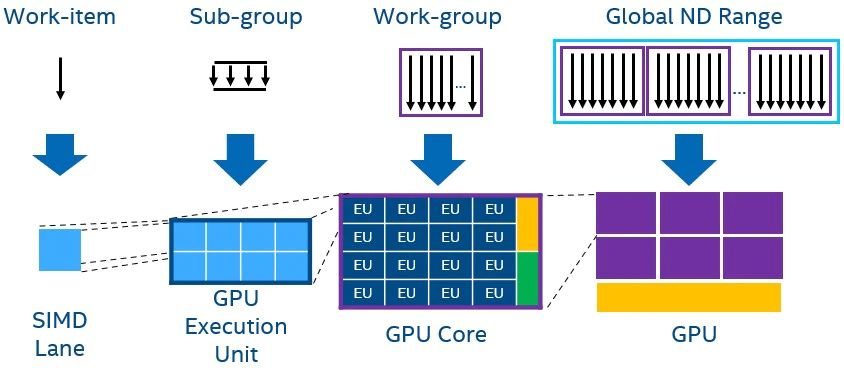
GPU は、大規模データの並列ワークロードに依存して性能を発揮します。そのため、single_task カーネルが利用されることはほとんどなく、GPU の深い実行パイプラインを完全に満たすためには NDRange カーネルが必要となります。GPU 上でカーネルを実行する際には、すべてのワークアイテムが SIMD レーンにマッピングされます。SIMD 方式で実行されるワークアイテムからはサブグループが形成され、サブグループは GPU の EU にマッピングされます。
また、ローカルデータを同期/共有できるワークアイテムを含むワークグループは、計算ユニット (別名: ストリーミング・マルチプロセッサーまたはサブスライス) 上での実行に割り当てられます。最後に、ワークアイテムのグローバル NDRange 全体が GPU 全体にマッピングされます。
[FPGA の実行]
カーネルを FPGA 用にコンパイルする際、カーネル内の演算は空間的にレイアウトされます。依存関係にあるカーネル操作は深くパイプライン化され、独立した操作は並列に実行されます。パイプライン実装の重要な利点は、隣接するワークアイテム間の依存関係を、パイプラインを停止させることなく、あるパイプライン・ステージから前のステージにデータを戻すだけで解決できることです。パフォーマンスの鍵となるのは、ディープ・パイプラインを完全に使用し続けることです。FPGA では、NDRange カーネルでも single_task カーネルでも性能を引き出すことができますが、FPGA で良好な性能を発揮するカーネルは、single_task カーネルとして表現されることが多いです。
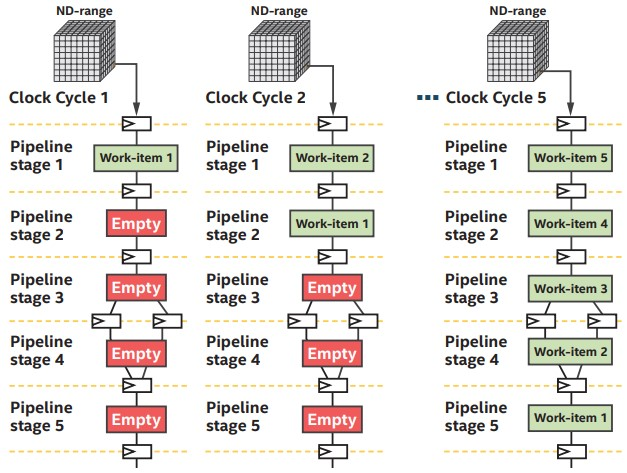
single_task カーネルでは、FPGA はループ実行のパイプライン化を試みます。クロックサイクルごとに、連続するループの反復がパイプラインの最初のステージに入ります。ソフトウェアで表現されたループ反復間の依存関係は、ハードウェアでは、あるステージの出力を依存関係のある前のステージの入力にルーティングすることで解決できます。
NDRange カーネルの実行では、クロックサイクルごとに、異なるワークアイテムがカスタム計算パイプラインの最初のステージに入ります。
ほかのアーキテクチャーとは異なり、カスタム FPGA パイプライン計算ユニットでは、より多くのワークアイテムを並列で処理するためにパイプラインの SIMD 幅を広げることで、FPGA リソースとスループットをトレードオフするオプションが追加されています。例えば、ループの反復をアンロールして、データの並列処理を実現することができます。
ライブラリー・サポート
CPU、GPU、FPGA 上でパフォーマンスの高いソフトウェアを記述するための最速の方法の 1 つは、oneAPI のライブラリーが提供する機能を活用することです。oneAPI は、ディープラーニング、サイエンティフィック・コンピューティング、ビデオ分析、メディア処理など、さまざまな計算やデータを多用する領域向けのライブラリーを提供しています。
ライブラリーのサポートは、アルゴリズムに最適なデバイスを判断するのに役立ちます。一般的に、ライブラリーのサポートが最も充実しているのは CPU で、次に GPU、そして最も手作業での実装が必要なのは FPGA とされています。ライブラリー関数が複数のアーキテクチャーでサポートされている場合、処理されるデータ量やデータの局所性 (処理されるデータが存在するデバイス) などの実行特性によって、使用する最適なデバイスが決まります。
このセクションでは、さまざまな oneAPI のライブラリーとそのデバイスサポートについて説明します。ライブラリーのサポートは常に進化しています。最新情報は、ライブラリーのドキュメント (英語) を確認してください。
oneAPI DPC++ ライブラリー (oneDPL) (CPU、GPU、および FPGA)
oneDPL は、複数のデバイスを対象とした並列アプリケーションの DPC++ 開発者の生産性を向上させます。oneDPL は、並列 C++ 標準テンプレート・ライブラリー (STL) 機能に加え、追加の並列アルゴリズム、イテレーター、レンジベースの API、乱数生成器、テスト済みの標準 C++ API などへのアクセスを提供します。oneDPL は、CPU、GPU、および FPGA に対応しています。
oneAPI マス・カーネル・ライブラリー (oneMKL) (CPU および GPU)
oneMKL は、大規模な計算問題を解決する数学ルーチンでパフォーマンスを向上させます。oneMKL は、BLAS および LAPACK の線形代数ルーチン、高速フーリエ変換、ベクトル化された数学関数、乱数生成関数などの機能を提供します。現在、oneMKL は CPU と GPU をサポートしていますが、将来的にはアクセラレーターのサポートが追加される予定です。
oneAPI スレッディング・ビルディング・ブロック (oneTBB) (CPU)
oneTBB は、DPC++ で利用可能な機能を超えて、CPU 向けアルゴリズムの論理的並列性を指定する機能を提供する C++ テンプレート・ライブラリーです。このライブラリーは、DPC++ と組み合わせて使用することで、CPU と GPU の間でコードを分割して実行することができます。
oneAPI データ・アナリティクス・ライブラリー (oneDAL) (CPU および部分的に GPU をサポート)
oneDAL は、バッチ処理、オンライン処理、分散処理の各計算モードで、データ解析の全段階 (前処理、変換、分析、モデリング、検証、意思決定) に対して高度に最適化されたアルゴリズムの構成要素を提供することで、ビッグデータ解析の高速化を支援するライブラリーです。oneDAL は、基本的には CPU を対象としていますが、一部のアルゴリズムでは GPU の使用を可能にする DPC++ API 拡張を提供しています。
oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (oneDNN) (CPU および GPU)
oneDNN には、ディープラーニングのアプリケーションやフレームワークのためのビルディング・ブロックが含まれています。ブロックには、畳み込み、プーリング、LSTM、LRN、ReLU などがあります。このライブラリーは、CPU と GPU の両方に対応しています。
oneAPI コレクティブ・コミュニケーション・ライブラリー (oneCCL) (CPU および GPU)
oneCCL は、ディープラーニング・アプリケーションで発生する通信パターンに最適化されたプリミティブをサポートしています。これにより、開発者や研究者は、より新しく、より深いモデルをより速く学習することができます。
oneAPI ビデオ・プロセシング・ライブラリー (oneVPL) (CPU)
oneVPL は、メディア・パイプラインを構築するための、ビデオのデコード、エンコード、処理のためのプログラミング・インターフェイスです。現在は、CPU 上での展開をサポートしています。将来的には、ほかのハードウェア・アクセラレーターにも対応する予定です。
現在の oneAPI のライブラリー・サポートのサマリー
| oneDPL | oneMKL | oneTBB | oneDAL | oneDNN | oneCCL | oneVPL | |
|---|---|---|---|---|---|---|---|
| CPU | Y | Y | Y | Y | Y | Y | Y |
| GPU | Y | Y | Partial | Y | Y | ||
| FPGA | Y |
GPU オフロードのコード領域を特定する
ヘテロジニアス・コンピューティング環境では、オフロード・アクセラレーションに適したアルゴリズムの部分を特定することは困難です。アルゴリズムの特性を知っていても、パーティショニングや最適化を行う前にアクセラレーターでのパフォーマンスを予測することは困難です。インテル® oneAPI ベース・ツールキットに含まれているインテル® Advisor のオフロードのモデル化機能は、このような場合に役立ちます。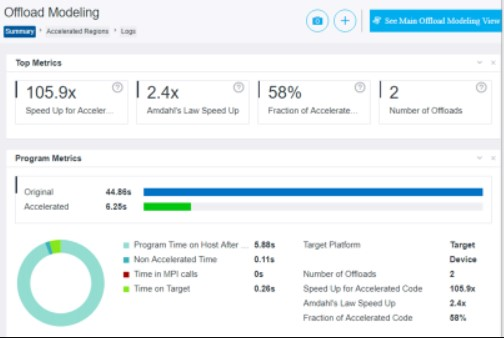
インテル® Advisorは、効率的なスレッド化、ベクトル化、メモリー使用、オフロードなどにより、アプリケーションのパフォーマンスを最大限に引き出すための設計・解析ツールです。C、C++、DPC++、Fortran、OpenMP、Python をサポートしています。インテル® Advisor のオフロードのモデル化機能は、コードのどのセクションが GPU オフロードの恩恵を受けるかを理解するのに役立つように設計されています。GPU での実行のためにコードをリファクタリングする前に、オフロードのモデル化で以下のことができます。
- オフロードの機会を特定する。
- GPU オフロードによる性能向上の可能性を定量化する。
- データ転送のコストを見積もり、データ転送の最適化に関するガイダンスを提供する。
- ボトルネックを見つけ、潜在的なパフォーマンスを推定する。
CPU と GPU は本質的に異なるため、CPU コードを最適な GPU コードに移植するには多大な作業が必要になります。オフロードのモデル化は、移植作業を行う前に、GPU オフロードに適したアルゴリズムを決定する際の貴重な生産性向上ツールとなります。
用途例
このセクションでは、各アーキテクチャーに対応するいくつかのアプリケーションの例を検討します。どのアルゴリズムがどのアクセラレーター・アーキテクチャーに適しているかは、アプリケーションの特性やシステムのボトルネックによって異なります。
GPU ワークロードの例
GPU は大規模なデータ並列アクセラレーターです。データセットがオフロードデータ転送のオーバーヘッドを隠すほど大きく、データ間の依存関係がほとんど回避でき、データフローがほとんど分岐しない場合、GPU は最適なアクセラレーターとなります。
GPU の利点を十分に活かしたワークロードには、次のような特徴があります。
- 当然のことながらデータ並列であり、同じ操作がデータ全体に適用される
- 問題の規模が大きいため、多くの GPU 処理要素が利用されている
- メイン・コンピューターのメモリーから GPU メモリーへのデータ転送時間を隠す
- 処理されるデータ間の依存関係はほとんどない
- あるデータポイントを処理したときの出力は、別のデータポイントの出力には依存しない
- ほとんどが非発散型の制御フローである (分岐やループの分散が少ない)
- 再帰的な関数は、しばしば書き換えが必要になる
- GPU でサポートされているデータタイプと一致する
- 文字列の処理などに時間がかかることがある
- 順序付けられたデータアクセス
- GPU は連続的な読み書きに最適化されている
- ランダムな順序でデータにアクセスするアルゴリズムは、しばしば書き換えが必要になる
例えば、画像処理は、GPU に最適な処理です。処理すべきピクセルの数が多いのが特徴です。各ピクセルでは、同じ基本的な操作が適用され、出力ピクセルは互いに依存しません。
ディープラーニング・アプリケーションも、GPU のワークロードとして人気があります。以下は、コンピューター・ビジョンのアプリケーションで使用される畳み込みニューラル・ネットワーク (CNN) の畳み込み層の 1 つの出力特徴マップを計算する式です。
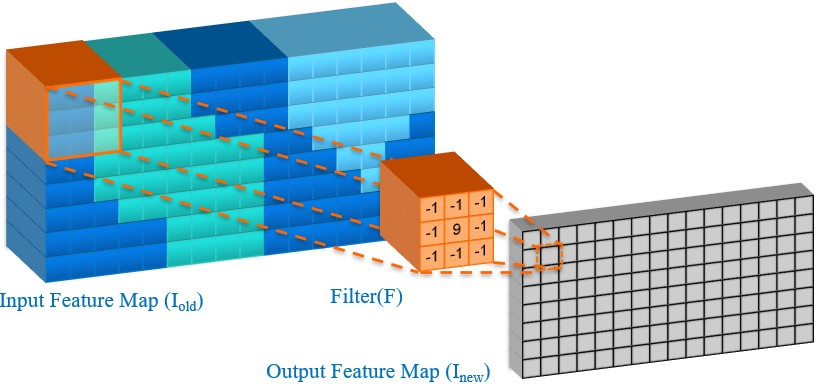
出力特徴マップを計算するために、3D フィルターがマルチチャネルの入力特徴マップの幅と高さにわたって畳み込まれ、スライドしてドット積を計算します。1 つの CNN レイヤーで何百もの特徴マップを計算して、CNN のフォワードパスで何百ものレイヤーを計算する必要があります。GPU が CNN を効率的に処理できるのは、1 つのレイヤーのドット積が独立していること、計算に分岐がないこと、各レイヤーに大量の計算があること、転送が必要な入出力データの量よりも計算量の方が速くなることなどが理由です。
ほかにも、AI、データ解析、気候モデル、遺伝学、物理学など、GPU の代表的な用途は多岐にわたります。
FPGA ワークロードの例
FPGA アーキテクチャーの効率的でカスタム可能なディープ・パイプラインは、シリアルコードで表現しやすく、データ要素間の依存関係があるようなアルゴリズムに適しています。このようなタイプのアルゴリズムは、GPU のデータ並列アーキテクチャーでは適切に実行できません。
その一例が Gzip 圧縮です。Gzip は 3 つのカーネルで処理できます。1 つ目は LZ77 データ圧縮カーネルで、ファイル内の重複するパターンを検索して排除します。2 つ目のカーネルはハフマン・コーディングを行い、LZ77 の出力を符号化して結果を生成します。最後に、CRC32 エラー検出カーネルが、ほかの 2 つのカーネルとは独立して入力を操作します。
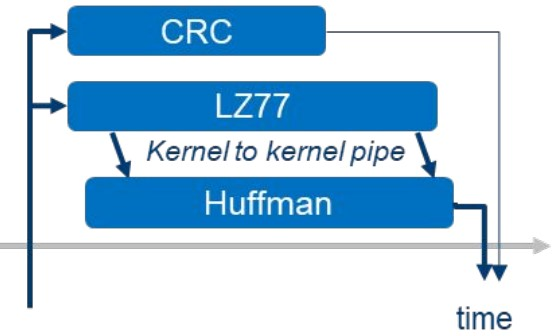
このアルゴリズムが FPGA での実行に適しているのには、いくつかの理由があります。
- FPGA は、3 つのカーネルがそれぞれ専用のカスタム計算パイプラインを持っているため、同時に実行することができます。
- LZ77 の場合、重複のシーケンシャル検索は、依存関係があるため、NDRange カーネルでは容易に並列化できません (例えば、ファイルの後半の検索結果が前半の検索結果に依存する)。これは、ファイル全体をシンボルごとに反復する single_task カーネルで実装することができ、反復の間にカスタム・ルーティングを使用して依存関係を解決します。
- FPGA のカスタム・オンチップ・メモリー・アーキテクチャーにより、大量の辞書検索を同時に行ってもストールすることはありません。
- ハフマンコードはバイトアラインされていないため、エンコードにはビット操作が必要ですが、これを FPGA で効率的に実現しています。
- FPGA では、同時に実行されるカーネル間で個々のデータをパイプでつなぐことができます。これにより、LZ77 とハフマン符号化カーネルを同時に実行することができます。
この実装とコードサンプルの詳細については、記事「インテル® FPGA での圧縮の高速化」 (英語) を参照してください。
同様の理由で、ほかの多くのワークロードも FPGA に適しています。画像の可逆圧縮、ゲノムシーケンス、データベース・アナリティクスの高速化、マシンラーニング、金融コンピューティングなど、いずれも FPGA による高速化に適しています。
CPU とヘテロジニアス・ワークロード
CPU は、コンピューターで最も広く使用されている汎用プロセッサーです。GPU や FPGAを利用して計算を高速化するアプリケーションでも、タスクのオーケストレーションには CPU が必要です。CPU は、GPU や FPGA の機能を効率的に活用できないアルゴリズムの場合、デフォルトの選択肢となります。CPU は、GPU ほどの計算密度や FPGA ほどの計算効率はありませんが、ベクトル、メモリー、スレッドの最適化を適用すれば、計算アプリケーションにおいて優れた性能を発揮します。これは、オフロードの要件を満たしていない場合に特に当てはまります。
ヘテロジニアス環境では、メインの計算をアクセラレーターで行ったとしても、ほかのコード部分で CPU がパフォーマンスを向上させることができます。oneAPI を使えば、1 つのアプリケーションでクロスアーキテクチャーの性能を活用し、CPU、GPU、FPGA のメリットを享受することができます。
まとめ
今日の計算機システムは、CPU、GPU、FPGA、その他のアクセラレーターを含むヘテロジニアスなシステムです。それぞれのアーキテクチャーにはさまざまな特徴があり、特定のワークロードに合わせることで最高のパフォーマンスを発揮します。計算アーキテクチャーごとにプログラミングと最適化のニーズは異なります。oneAPI と DPC++ は、それぞれのアーキテクチャーに合わせたソフトウェアを開発するためのプログラミング・モデルを、ダイレクト・プログラミングやライブラリーを通じて提供します。
GPU アーキテクチャーは、最も計算密度の高いアーキテクチャーです。カーネルがデータ並列で、シンプルで、多くの計算を必要とする場合は、GPU 上で最もよく動作する可能性があります。
FPGA アーキテクチャーは、最も計算効率の高いアーキテクチャーです。FPGA と生成されたカスタム計算パイプラインを使用すれば、ほとんどのカーネルを高速化することができますが、FPGA の実装は空間的な性質を持っているため、利用可能な FPGA リソースには限界があります。
最後に、CPU アーキテクチャーは最も柔軟性が高く、最も幅広いライブラリーをサポートしています。最近の CPU は多くの種類の並列処理をサポートしており、ほかのアクセラレーターを補完するために効果的に使用することができます。
この記事で取り上げた各計算アーキテクチャーを体験してみたい方は、インテル® DevCloud (英語) を使って、最新の CPU、GPU、FPGA を含むヘテロジニアス環境で oneAPI と DPC++ をお試しください。最新のインテル® ハードウェアとソフトウェア (英語) のクラスター上で、ワークロードの開発、テスト、実行を無料で行うことができます。
本記事で紹介しているインテル® Advisor はインテル® oneAPI ベース・ツールキットに同梱されています。
参照記事:
Compare Benefits of CPUs, GPUs, and FPGAs for Different oneAPI Compute Workloads