

この記事は、インテルのウェブサイトで公開されている「Smaller is Better: Q8-Chat LLM is an Efficient Generative AI Experience on Intel® Xeon® Processors」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
大規模言語モデル (LLM) は、マシンラーニングの世界に旋風を巻き起こしています。トランスフォーマー・アーキテクチャーのおかげで、LLM はテキスト、画像、ビデオ、音声などの膨大な量の非構造化データから学習する驚異的な能力を備えています。テキスト分類などの抽出型タスク、テキスト要約やテキストから画像生成などの生成型タスクなど、多くのタスクタイプで優れたパフォーマンスを発揮しています。
その名前が示すように、LLM は大規模なモデルであり、通常パラメーター数は 100 億を超え、BLOOM など一部のモデルでは 1,000 億を超えます。検索や会話型アプリケーションなどの低レイテンシーのユースケースで十分な速さで予測するには、通常、ハイエンド GPU などの大量の計算能力を必要とします。残念ながら、多くの組織にとって、関連コストは非常に高額であり、最先端の LLM をアプリケーションで使用することは困難です。
この記事では、LLM のサイズと推論レイテンシーを軽減し、インテルの CPU で効率良く実行できるようにする最適化手法について説明します。
量子化について
LLM は通常、16 ビット浮動小数点パラメーター (FP16/BF16) を使用してトレーニングします。したがって、単一の重みまたは活性化の値の保存には、2 バイトのメモリーが必要です。さらに、浮動小数点演算は整数演算よりも複雑で時間がかかり、追加の計算能力を必要とします。
量子化は、モデル・パラメーターの一意の値の範囲を縮小することで、両方の問題を解決することを目的としたモデル圧縮手法です。例えば、モデルを 8 ビット整数 (INT8) などの低い精度に量子化して縮小し、複雑な浮動小数点演算をより単純で高速な整数演算に置き換えることができます。
簡単に言うと、量子化はモデル・パラメーターをより小さな値の範囲に再スケーリングします。ベストケースでは、モデルの精度に影響を与えることなく、モデルサイズを少なくとも半分に縮小します。
トレーニング中に量子化を適用できる量子化対応トレーニング (QAT (英語)) は通常、最良の結果をもたらします。既存のモデルを量子化する場合は、トレーニング後の量子化 (PTQ (英語)) を適用できます。これは、わずかな計算能力しか必要とせず、はるかに高速な手法です。
さまざまな量子化ツールあります。例えば、PyTorch には量子化 (英語) サポートが組み込まれています。また、開発者にとって使いやすい QAT および PTQ 用の API を含む Hugging Face Optimum Intel (英語) ライブラリーを使用することもできます。
LLM の量子化
最近の研究[1] [2] によると、現在の量子化手法は LLM ではうまく機能しません。特に、LLM はすべてのレイヤーとトークンにおいて特定の活性化チャネルで大きな外れ値を示します。
OPT-13B モデルの例を次に示します。活性化チャネルの 1 つが、すべてのトークンでほかのすべてのチャネルよりもはるかに大きな値を持っていることが分かります。この現象は、モデルのすべての Transformer レイヤーで確認できます。
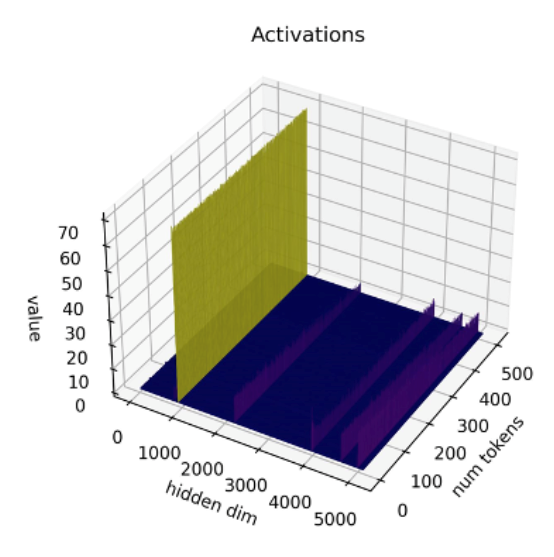
出典: SmoothQuant
これまでの最良の量子化手法は、活性化をトークン単位で量子化するため、外れ値が切り捨てられるか、小さな活性化の値がアンダーフローとなり、モデルの品質が大幅に低下します。さらに、量子化対応トレーニングには追加のモデル・トレーニングが必要ですが、これはほとんどの場合、計算リソースとデータの不足により現実的ではありません。
SmoothQuant[3] [4] は、この問題を解決する新しい量子化手法です。これは、重みと活性化に数学的変換を適用し、重みの比率を増やす代わりに、活性化の外れ値と非外れ値の比率を減らします。この変換により、Transformer レイヤーが「量子化に適した」ものになり、モデルの品質を損なうことなく 8 ビットの量子化が可能になります。その結果、SmoothQuant は、インテルの CPU プラットフォームで適切に動作する、より小さく、より高速なモデルを生成します。
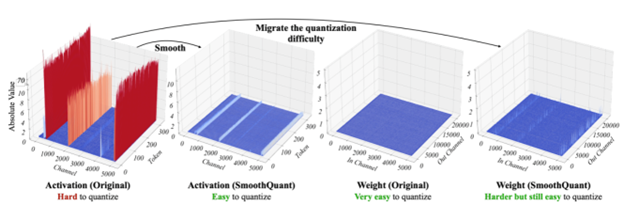
それでは、SmoothQuant を一般的な LLM に適用した場合にどのように動作するかを見てみましょう。
SmoothQuant による LLM の量子化
インテルのエンジニアは、SmoothQuant-O3 を使用して、OPT 2.7B と 6.7B[5]、LLaMA 7B[6]、Alpaca7B [7]、Vicuna 7B[8]、BloomZ 7.1B[9]、MPT-7B-chat[10] を量子化し、Language Model Evaluation Harness (英語) を使用して、量子化したモデルの精度を評価しました。
以下の表に結果の概要を示します。2 番目の列は、量子化後に改善されたベンチマークの比率を示します。3 番目の列は、平均的な性能低下を示します (*負の値は、ベンチマークが改善されたことを示します)。詳細な結果は、この記事の最後にあります。
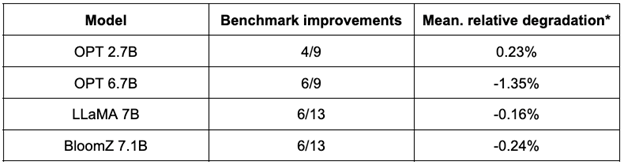
OPT モデルは SmoothQuant 量子化に最適な候補であることが分かります。モデルサイズは、事前トレーニング済みの 16 ビット・モデルと比較して約半分になっています。ほとんどのメトリックが向上し、向上しないものもペナルティーはわずかです。
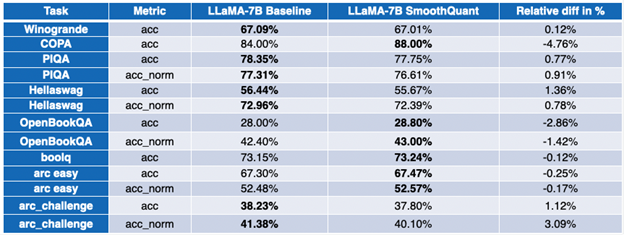
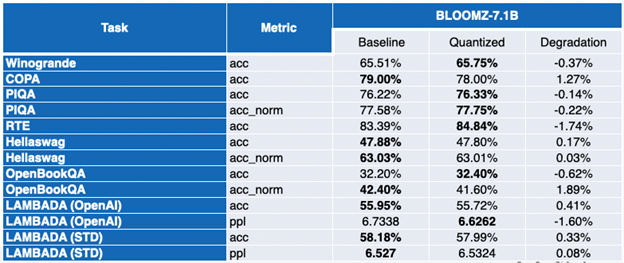
LLaMA 7B と BloomZ 7.1B の結果は対照的です。モデルサイズは約半分に圧縮され、約半分のタスクではメトリックが向上しています。残りの半分では、1 つのタスクで 3% を超える相対的な低下が見られますが、そのほかのタスクへの影響はわずかです。
より小さなモデルで作業することの明らかな利点は、推論レイテンシーが大幅に短縮されることです。シングルソケットのインテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids) 上で 32 コア、バッチサイズ 1 で MPT-7B-chat モデルを使用してリアルタイムのテキスト生成を実演するビデオをこちらから (英語) 視聴できます。
この例では、モデルに「What is the role of Hugging Face in democratizing NLP? (NLP の大衆化における Hugging Face の役割は何ですか?)」と質問しています。これにより、モデルに次のプロンプトが送信されます。
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions.
(好奇心旺盛なユーザーと人工知能アシスタントの間のチャット。アシスタントは、ユーザーの質問に対して、役に立つ、詳細で丁寧な回答を提供します。)USER: What is the role of Hugging Face in democratizing NLP?
(ユーザー: NLP の民主化における Hugging Face の役割は何ですか?)ASSISTANT:
(アシスタント:)
この例では、8 ビットの量子化と第 4 世代インテル® Xeon® プロセッサーの組み合わせによって得られる追加のメリットを示しています。これにより、各トークンの生成時間が非常に短くなります。この優れたパフォーマンスにより、CPU プラットフォームで LLM を実行できるようになり、顧客にこれまで以上に IT の柔軟性と優れたコスト・パフォーマンスがもたらされます。
インテル® Xeon® プロセッサー上でのチャット・エクスペリエンス
Hugging Face の CEO である Clement 氏は最近、「トレーニングと実行のコストを安価に抑え、より小規模で特定のモデルに重点を置いたほうが、より多くの企業にとって有益です」と述べました。
Alpaca、BloomZ、Vicuna などの比較的小規模なモデルの出現により、企業が本番環境でファイン・チューニングと推論のコストを軽減する新たな機会が生まれています。前述のように、高品質の量子化により、巨大な LLM や複雑な AI アクセラレーターを実行することなく、インテルの CPU プラットフォームで高品質のチャット・エクスペリエンスを実現できます。
インテルと共同で、Hugging Face は Spaces で Q8-Chat (「キュートチャット」と発音) という新しいエキサイティングなデモを実施しています。Q8-Chat は、シングルソケットのインテル® Xeon® スケーラブル・プロセッサー (開発コード名 Sapphire Rapids) 上で 32 コア、バッチサイズ 1 で実行しながら、ChatGPT のようなチャット・エクスペリエンスを実現します。
次のステップ
現在、これらの新しい量子化手法をインテル® ニューラル・コンプレッサー (英語) を通じて Hugging Face Optimum Intel (英語) ライブラリーに統合する作業が進行中です。この作業が完了すると、数行のコードでこれらのデモを再現できるようになります。
ご期待ください。将来は 8 ビットです!
この記事は、100% ChatGPT フリーです。
謝辞
この記事は、インテル・ラボの Ofir Zafrir、Igor Margulis、Guy Boudoukh、Moshe Wasserblat と共同で作成しました。素晴らしいコメントと協力をいただいた皆様に感謝します。
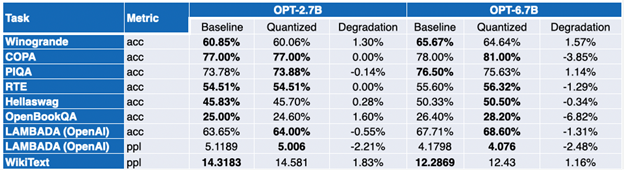
付録: 詳細な結果
負の値は、ベンチマークが改善されたことを示します。

関連情報:
インテルの AI/ML エコシステム – HuggingFace (英語)
Hugging のインテル・ページ (英語)
参考資料:
[1] https://arxiv.org/abs/2206.01861 (英語)
[2] https://arxiv.org/abs/2211.10438 (英語)
[3] https://arxiv.org/abs/2211.10438 (英語)
[4] https://github.com/mit-han-lab/smoothquant (英語)
[5] https://arxiv.org/pdf/2205.01068.pdf (英語)
[6] https://ai.meta.com/blog/large-language-model-llama-meta-ai/ (英語)
[7] https://crfm.stanford.edu/2023/03/13/alpaca.html (英語)
[8] https://vicuna.lmsys.org/ (英語)
[9] https://huggingface.co/bigscience/bloomz (英語)
[10] https://www.databricks.com/blog/mpt-7b (英語)
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
最新のインテル® Xeon® スケーラブル・プロセッサー向けの最適化を支援
エクセルソフトは、最新のインテル® Xeon® スケーラブル・プロセッサーをターゲットとする企業や開発チーム向けに、インテル® ソフトウェア開発ツールを利用したパフォーマンスの最適化支援を提供しています。コンパイラー・オプションの提案、パフォーマンス分析ツールによるアプリケーションの解析やチューニングなどを通して、パフォーマンスと開発効率の向上によるコスト削減を支援します。
最新のインテル® Xeon® スケーラブル・プロセッサーを搭載したクラウドサービス「インテル® Tiber™ AI クラウド」の導入サポートでは、LLM や生成 AI を活用した AI アプリケーションやサービスの開発および運用に携わる企業向けに、POC 構築や最適な価格プランのご提案から国内での購入サポートまで、企業のニーズに合わせたを支援します。また、AI スタートアップ企業の育成に特化したインテルの無料プログラムの推薦なども行っています。
インテル® ソフトウェア開発ツール2025 リリース記念キャンペーン
インテル® ソフトウェア開発ツールの最新バージョン 2025 のリリースを記念して、対象のオンラインイベントに参加いただき、事後アンケートにご回答いただいた方の中から、抽選で合計 18 名様にインテル Arc B580 グラフィックスなどが当たるプレゼント・キャンペーンを実施中です。【締切 : 2025年2月20日 (木)】