

C と MPI アプリケーションを DPC++ に移植するステップバイステップのケーススタディー
熱の方程式は、並列計算のチュートリアルでよく使われる問題です。実際、ここでは Partnership for Advanced Computing in Europe (PRACE) が公開しているような問題から始めます。オリジナルのコード1は、2 次元熱方程式をシングル・ポイント・ステンシルに離散化したものを、C 言語とメッセージ・パッシング・インターフェイス (MPI) で実装したものです (図 1)。2 次元平面はセルに分割され、各セルおよび隣接する 4 つのセルの以前の値に基づいて時間ステップごとに更新されます。この問題の詳細な説明は PRACE のリポジトリー2でご覧いただけます。
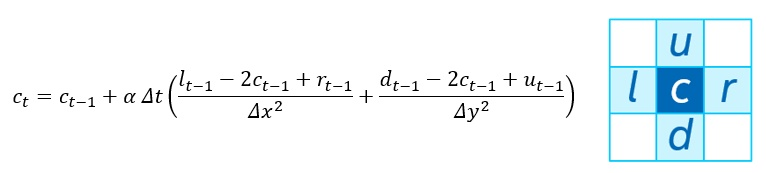
図 1. 2 次元熱伝導方程式とシングル・ポイント・ステンシル
デフォルトの実装では、500 時間ステップ処理する 2000×2000 セルの平面からスタートします (図 2)。平面は均一温度が異なる中央の円を除いて、均一温度に初期化されています。外枠は 4 つの異なる温度に固定されます。
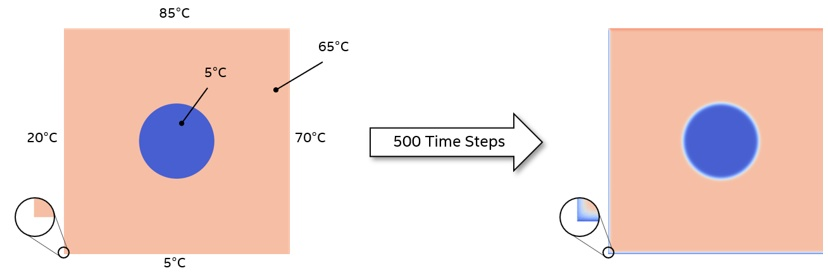
図 2.計算機の設定
この記事では、標準的な C/C++ で書かれたコードを使用し、いくつかの簡単な DPC++ の構成要素を追加して、異なる並列処理ユニットで実行する方法を紹介します。DPC++、SYCL*、oneAPI の使用経験があると理解しやすいかもしれません。
DPC++ への最初の移行
PRACE のオリジナルコードには、問題を複数のプロセッサーと複数のノードで処理されるタイルに分割するための MPI 構文が搭載されています。これらは、コアの計算に集中するために最初はコードから削除され、並列処理を導入後コードに書き戻します。また、問題を単純化するために、出力画像の定期的な書き込みや再起動チェックポイントなどの機能も削除しています。最初と最後の平面を描写する画像の書き込みに関連するコードは、便利な機能検証ツールとして残されています。
さらにシンプルにするために、単一カーネルで平面全体を更新するようにしました。MPI ベースのコードでは、エッジと内部を分離し、内部を更新しながら、他のプロセスからハローをコピーできるようにしています。1 つのタイルのエッジが隣接するタイルのハローになります。ハローが更新された後、ハローと内部の両方に依存するエッジを計算することができます (図 3)。この最初の移行作業では、エッジと内部は 1 つとして扱われます。
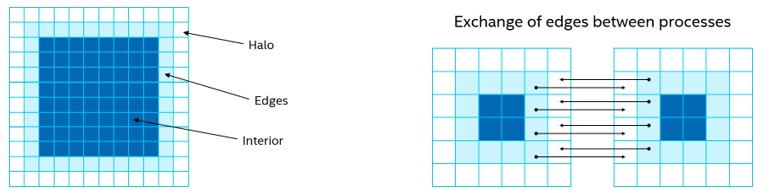
図 3. データの配置と交換
DPC++ のヘッダーと名前空間
DPC++ を使用するには、2 つのヘッダーファイルをインクルードする必要があります。1 つ目のファイルは、DCP++ 言語のサポートを提供し、DPC++ コンパイラーとともに提供され、main.c、core.c、および heat.h で参照されます。2 つ目のヘッダーファイルは DPC++ サンプルプログラムのコレクション3から抜粋したもので、例外ハンドラーのためにインクルードされています。また、コード本体の SYCL* 構造を単純化するために、sycl 名前空間を宣言しています。
#include <CL/sycl.hpp> #include "dpc_common.hpp" using namespace sycl;
main.c のその他の変更点は、先頭と最後が DPC++ コードでラップされた時間反復ループを含みます。以下の 5 つのコードセグメントは連続したコードですが、ここでは説明を容易にするために分けてあります。
デバイスとキュー
デフォルトのセレクターが選択されており、ランタイムがカーネルを実行するターゲットデバイスを選択することになります。通常は、GPU がある場合は GPU が使用され、ない場合はホスト CPU が使用されます。特定のデバイスを使用するには、default_selector の代わりに cpu_selector または gpu_selector を使用します。次に、try-catch ブロックでラップされたセレクターと例外ハンドラーに基づいて queue を定義します。
default_selector d_selector;
try {
queue q(d_selector, dpc::exception_handler);
バッファー
バッファーは、ターゲットデバイスに存在するデータのコンテナーであり、OpenCL* コードのプログラマーにはおなじみのものです。オリジナルのコードのデータ構造から問題のサイズを取得し、ハローのために各次元に 2 つずつ追加します (各辺に 1 つのセル) (図 3)。オリジナルのホスト配列の問題サイズと次元に基づいて、global_range を 1 次元の範囲として宣言します。次に、この範囲とホストデータのポインターを参照するバッファーを定義します。
size_t num_items = (current.nx + 2) * (current.ny + 2); auto global_range = range<1> (num_items); buffer current_buf (current.data, global_range); buffer previous_buf (previous.data, global_range);
キューのサブミットとアクセサー
時間処理 for ループはオリジナルコードから変更していません。ループの反復ごとに、定義されたキューに対しカーネルをサブミットします。アクセサーは、バッファーがデバイス上でアクセスされる方法を定義します。この例では,両方のバッファーに対して read_write アクセスを宣言しています。各ループの反復では、1 つのバッファーが読み込まれ、1 つのバッファーが書き込まれますが、バッファーがコンテキスト内に留まっている間にバッファーをスワップするので、これらのバッファーを read または write として定義することはできません。
/*Time evolve */
for (iter = iter0; < iter0 + nsteps; iter++) {
q.submit([&}(handler &h) {
auto current_accessor =
current_buf.get_access<sycl::access::mode::read_write>(h);
auto previous_accessor =
previous_buf.get_access<sycl::access::mode::read_write>(h);
カーネル実行
parallel_for カーネルを使用しているので、このセクションの本文は、この問題のすべてのアイテム (つまり、この場合はハローを含む平面上のすべてのセル) に対してサブミットされます。計算されるセルを識別するカーネルに渡される 1 次元の ID を定義します。2 次元の ID を使用することで、カーネル本体内でのインデックスを補助することができます。しかし、最小限のコード変更で機能的な移植を示すために、1 次元の ID を選択しました。カーネルの本体は、後述する別ファイル core.c の evolve 関数内に含まれています。オリジナルのコードでは、同等の evolve 関数への呼び出しポインターが 1 つあり、ループ内でポインターをスワップしています。ここでは、バッファー管理を簡単にするために、ループの反復ごとに、parallel_for を個別に呼び出して、アクセサーへのポインターを切り替えています。
if ((iter -iter0) % 2 ==)
h.parallel_for({num_item}, [=](id<1> i) {
evolve(i, current_accessor.get_pointer(),
previous_accessor.get_pointer(),
current.nx_full, current.ny_full, dx2, dy2, a dt);
});
else
h.parallel_for({num_item}, [=](id<1> i) {
evolve(i, previous_accessor.get_pointer(),
current_accessor.get_pointer(),
current.nx_full, current.ny_full, dx2, dy2, a dt);
});
}); // submit
} // for loop
エラー処理
カーネルの実行中に発生したエラーは、ホスト・アプリケーション・スコープに渡され、そこで従来の C++ の例外処理で処理されます。ここでは、サンプルプログラムで提供されている標準例外ハンドラーを利用しています。
} catch (exception const &e) {
std::cont << "An exception is caught.\n";
std::terminate();
}
カーネルコード
次のコードは、core.c の完全なリストです。プロセス間の通信や、内部とエッジの計算を分離する必要がないため、オリジナルコードから大幅に簡素化されています。オリジナルコードでは、従来の CPU プログラミングと同様に、evolve 関数が平面全体に対して 1 回だけ呼び出され,2 つのネストされた for ループが x および y 次元をトラバースして各セルの更新を計算します。parallel_for 呼び出しを使用しているため、next 関数は個々のセルごとに呼び出されます。そのため、for ループは必要ありません。
parallel_for 関数を呼び出す際に使用されるグローバル範囲には、ハローが含まれています。この範囲は更新されませんが、エッジの新しい値を計算するために必要です。バッファー外のメモリーを読み込もうとすると、セグメンテーション違反になるので、if 文を使ってハローを省略しています。実際の計算はコードの最後の行に限られており、オリジナルコードと非常に似ています。それ以外の中間変数は、可読性を向上するために宣言されています。
関数のパラメーターは微妙に変更されています。最も明らかな点は、どのセルが計算されているかを識別するために必要な ID が含まれていることです。また、dx と dy.dx2 ではなく、dx2 と dy2 をカーネルに渡しています。dy2 はもともとカーネルで計算されていましたが、その値はすべてのセルで一定です。新しい evolve 関数はすべてのセルに対して呼び出されるので、毎回これらの値を計算する必要はありません。また、この関数を SYCL_EXTERNAL と宣言して、これがカーネルコードであることをコンパイラーに伝える必要がありますが、これは本体からは明らかではありません。それに合わせて、ヘッダーファイルの関数プロトタイプもこれに応じて変更します。
#include <CL/sycl.hpp>
#include "heat.h"
SYCL_EXTERNAL void evolve(sycl::id<1> i, double *curr, double * prev, int nx,
int ny, double dx2, double dy2, double a, double dt){
size_t width = ny + 2;
size_t num_items = (nx + 2) * (ny + 2);
if (i > width && i % width != 0 && (i+1) % width != 0 && i < num_items -
width) {
size_t iu = i - width;
size_t id = i + width;
size_t ir = i + 1;
size_t il = i - 1;
curr[i] = prev[i] + a * dt * ((prev[iu] - 2.0 * prev[i] + prev[id]) / dx2
+ (prev[ir] - 2.0 * prev[i] + prev[il]) / dy2);
}
}
アプリケーションとカーネルのコンパイル
オリジナルコードでは mpicc コンパイラーを使用しています。DPC++ 用にコンパイルするには、dpcpp コンパイラーを使用し、Makefile を適宜変更します。しかし、PNG ファイルの書き出しに関連するファイルには C コンパイラーが必要です。そこで、GCC を使用し、関数のプロトタイプを extern “C” {…} でラップします。これらのファイルは libpng4 を参照しています。libpng は sudo apt-get install libpng-dev でインストールするか、ソースからダウンロードしてビルドすることができます。
FPGA をターゲットにする
上記のコードと修正された Makefile は、ターゲットとなる CPU と GPU に適しています。FPGA については、ソースコードと Makefile に若干の変更を加えています。
FPGA が定義されたときに fpga_selector を選択するように main.c を変更します。
#include <CL/sycl/INTEL/fpga_extensions.hpp> ... #if FPGA INTEL::fpga_selector d_selector; #else default_selector d_selector #endif
Makefile には、コンパイラーとリンカー向けのオプションが追加されています。また、CPU/GPU バージョンと区別するため、実行ファイルの名前を変更します。
CXXFLAGS=-03 -g -Wall -std=c++17 -fintelfpga -DFGA LDFLAGS=-L$(LIBPNG_ROOT)/Lib -fsycl-link -Xshardware -fintelfpga EXE=heat.fpga
インテル® DevCloud 上でアプリケーションを実行する
インテル® DevCloud5 は、プリインストールされた環境と複数のインテル® CPU、GPU、および FPGA テクノロジーへのアクセスにより、oneAPI および DPC++ を無料で試す機会を提供します。以下のコードは、インテル® DevCloud へのアクセスがすでに利用可能で、『Get Started Guide』6 に従って設定されていることを前提としています。
コードをコンパイルして実行する前に、libpng をインストールする必要があります。インテル® DevCloud では sudo アクセスができないため、ソースからコンパイルして行います。「関連情報」の 7 からソースコードをダウンロードし、インテル® DevCloud にコピーしてから、以下の手順を実行します。
tar xf libpng-1.6.37.tar.gz cd libpng-1.6.37/ ./configure --prefix=/home/<username>/lib/libpng-1.6.37 make check make install
その後、~/.bashrc に以下のコードを追加するか、新しいセッションでこれらのコマンドを実行してください。これで、環境変数 LIBPNG_ROOT を使って、Makefile の中でライブラリーを参照することができます。
export LIBPNG_ROOT=/home/<user>/lib/libpng-1.6.37 export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:$LIBPNG_ROOT/lib"
熱伝導方程式のコンパイルおよび実行には、CPU と GPU の関連する計算ノード上で、それぞれ以下のコマンドを用いてインタラクティブなセッションを開始します。
qsub -I -I nodes=1:sk1:ppn=2 -d qsub -I -I nodes=1:gen9:ppn=2 -d
次に、セッションを終了する前にコードを作成して実行します。
make ./heat exit
FPGA のコンパイルに時間がかかるため、次のように FPGA コンパイルノードの 1 つをターゲットにしてバッチジョブとしてサブミットすることを推奨します。
qsub -1 nodes=1:fpga_compile:ppn=2 -d . . /compile_fpga.sh
また、CPU と GPU のコンパイルの間で make clean を行うか、FPGA は、競合を避けるために別のディレクトリーでコンパイルすることを推奨します。compile_fpga.sh の内容は以下の通りです。このファイルは実行可能でなければなりません。
#!/bin/bach make -f Makefile.fpga
注) FPGA のコンパイル用に別の Makefile を保持していることに注意してください。ジョブのステータスは qstat コマンドで確認できます。正常に完了すると、インタラクティブなセッションを開始して、FPGA 上でカーネルを実行することができます。
qsub -I -1 nodes=1:fpga_runtime:ppn=2 -d .
動作の検証
実行終了時には、ホスト・アプリケーションは、特定のセルの最終値を端末に表示するとともに、最終平面の PNG 画像を出力します (図 4)。この特定の値は、異なるコードの反復やカーネルターゲットに対するクイックチェックを行います。この値は、CPU、GPU、FPGA で実行しても同じで、オリジナルコードの値と一致します。PNG 画像はサードパーティーのアプリケーションで比較することができ、3 つのテクノロジーやオリジナルコードに違いは見られません。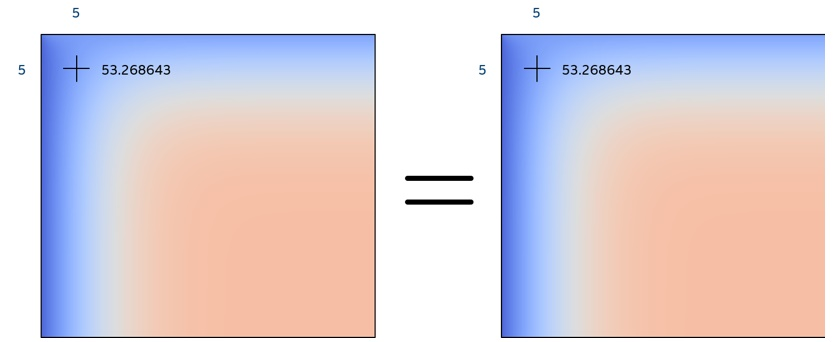
図 4. 最終面の PNG 画像
MPI の実装
MPI マルチプロセスのサポートをコードに追加する前に、ホストとデバイスの間で問題をどのように分割するか、また、演算をどのように並列化するかを見つけなければなりません。妥当な開始点は、エッジの計算とプロセス間の転送をホストに任せ、内部の計算はデバイスに任せることです。これは、オリジナルコードのアプローチとも一致します。時間反復ループでは、各反復の終わりにポインターをスワップする前に同期ポイントを設けて、エッジとは独立して内部を処理できます (図 5)。2 つの行は並行して動作することができます。
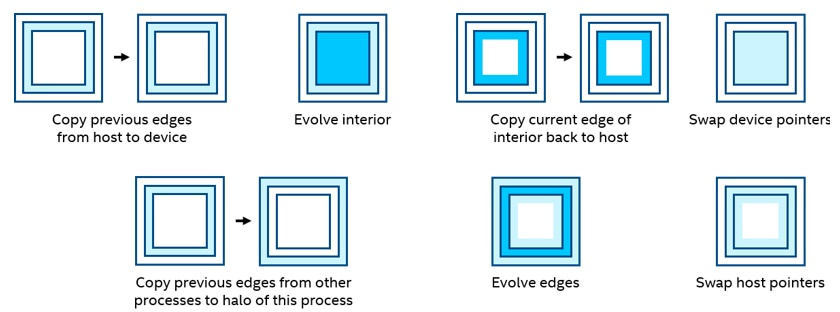
図 5. ポインターの入れ替え
もう 1 つ重要なのは、MPI プロセス間で問題をどのように分割するかということです。オリジナルコードでは 2 次元分解を採用しています。つまり、4 つのプロセスで問題を 4 つの象限 (2×2タイル) に分割しています。必要なデータだけを転送する場合、ホストとデバイス間のデータ転送は複雑になり、左端と右端の個々の PCIe* トランザクションが多数発生します。1 回の大きな転送は複数回の小さな転送よりも高速であるため、デバイスの内部処理の各反復間でデータ平面全体を転送する方が効率的です。しかし、より良い方法は、問題を 1 次元のみで分解することです。そうすれば、ホストとデバイスの間で必要なデータだけを転送することができ、その転送に必要なのは、2 つのロットの連続したメモリー (上辺と下辺) だけです (図 6)。図 7 は、すべてのデータを転送するのにかかった時間で正規化した相対実行時間を示しています。1 次元実装では、この問題のグローバルエッジが固定されているため、左右のエッジを転送する必要はありません。そのため、1 次元と 2 次元の分解で転送されるデータ量は同じです。
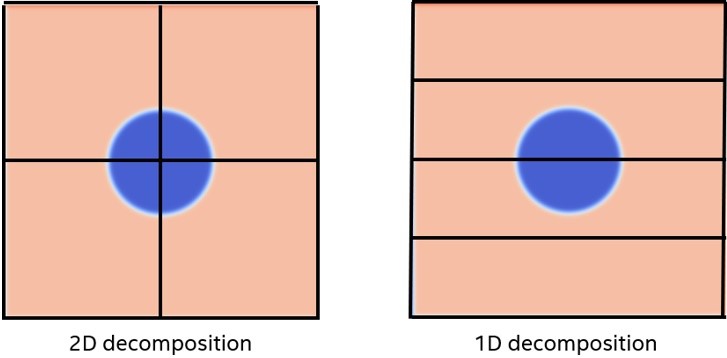
図 6. 1 次元データと 2 次元データの分解
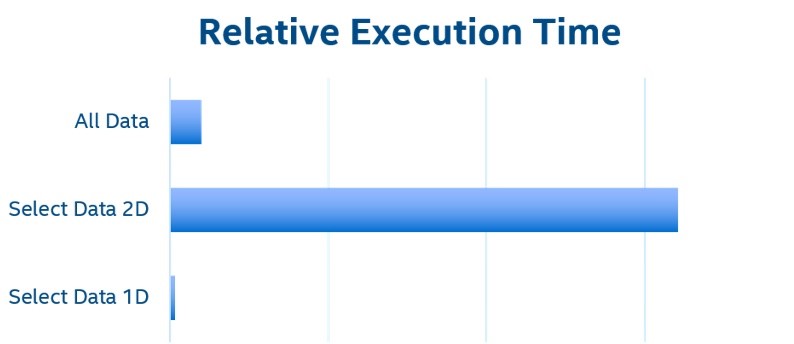
図 7.相対的な実行時間
setup.c の MPI_Dims_create 関数に渡す次元を変更することで、強制的に 1 次元の分解を行うことができます。この関数にゼロを渡すことで、ランタイムが各次元の範囲を定義することができます。2 つ目の値として 1 を使用することにより、単一列実装を行います。
//int dims[2] = {0, 0};
int dims[2] = {0, 1};
これまでの実装で使われていたバッファーの実装では、実行前に暗黙的にデバイスにデータを転送し、バッファーがコンテキストから外れたときに再びデータを戻していました。
ループ内でデータを転送できるようにするためには、より細かい制御が必要です。統合共有メモリー (USM) モデルでは、データをデバイス、ホスト、共有のいずれかに割り当てることができ、おなじみの C++ 構文でメモリーを操作することができます。ここでは、ホストとデバイス間のデータ転送を明示的に制御できる、デバイス割り当てメモリーを使用します。
オリジナルコードを開始点とし、MPI のコードをすべて残した上で、以下のように変更しました。ヘッダーと名前空間の変更は、以前と同じなのでここでは省略します。以下の 5 つのセクションは、連続したコードを表しています。
デバイスメモリーの割り当て
デバイスセレクターとキューは、最初の実装と同じです。バッファーの代わりに malloc_device を使用してデバイス上のメモリーを明示的に定義し、明示的な memcpy 関数でコピーしています。デバイス・コンテキストを提供するために、キューを参照する必要があります。wait 関数は、前のメモリー操作が完了するのを待ちます。これは、ホストとアクセラレーターの並列動作を可能にするために、要求されたアクションを送信した後もホストの実行を継続するために必要です。待機機能は、ホストの実行を継続する前に、実行順序が異なる可能性のあるキュー内のすべてのアクションが完了することを保証するための同期ポイントとして機能します。前述の例では、SYCL* ランタイムはバッファーを使ってスケジューリング操作を行っていました。
default_selector d_selector;
try {
queue q(d_selector, dpc::exception_handler);
size_t num_item = (current.nx + 2) * (current.ny + 2);
auto dev_curr = malloc_device<double>((num_item), q);
auto dev_prev = malloc_device<double>((num_item), q);
q.memcpy (dev_curr, current.data, num_items * sizeof(double));
q.memcpy (dev_prev, previous.data, num_items * sizeof(double));
q.wait();
エッジをデバイスにコピーする
各時間ステップの最初に、各スライスの上下が、エッジを特定するためのポインター演算を用いて、ホストからデバイスにコピーされます。これらのエッジは、ハローの影響で、それぞれ上下 1 列ずつになっています。最初にコピー操作が開始され、続いて交換機能、そして待機機能が実行されます。これは、コピーと交換が並行して行われるようにするためです。
/* Time evolve */
for (iter = iter0; iter < iter0 + nsteps; iter++) {
q.memory (dev_prev + previous.ny+2, previous.data+previous.ny+2,
(previous.ny+2) * sizeof(double));
q.memory (dev_prev + (previous.ny+2) * previous.nx, previous.data +
(previous.ny+2) * previous.nx, (previous.ny+2) * sizeof(double));
exchange_init(&previous, ¶llelization);
q.wait();
カーネルの実行
この実装では、デバイスは平面全体ではなく内部を処理します。したがって、それに合わせて計算の関数名も変更されています。もう 1 つの微妙な違いは、バッファーアクセサーへのポインターの代わりに、デバイスのメモリーポインターが渡されていることです。exchange_finalize 関数はオリジナルコードにあったもので、エッジを処理する前に MPI ベースのデータ交換が完了するのを待ちます。その後、カーネルが完了するのを待ってから、内部のエッジをホストにコピーして戻します。
q.submit([&](sycl::habdler &h) {
h.parallel_for(num_items, [=] (id<1> i) {
evolve_interior(i, dev_curr, dev_prev, current.nx, current.ny, dx2,
dy2, a,
dt);
});
});
exchange_finalize(¶llelization);
evolve_edges(¤t, $previous, a, dt);
q.wait();
q.memcpy (current.data + (current.ny+2) * 2, dev_curr + 2 * (current.ny+2),
(current.ny+2) * sizeof (double)):
q.memcpy (current.data + (current.ny+2) * 2, (dev_curr - 1) ,dev_curr +
(current.ny+2) * (current.nx -1), (current.ny+2) * sizeof
(double));
q.wait();
ポインターのスワップ
各時間反復の最後のステップは、ポインターのスワップです。ホストでは、オリジナルコードにあった swap_fields 関数で処理されます。デバイスでは、単純なポインターのスワップを行います。
swap_fields(¤t, &previous); double *dev_tem = dev_curr; dev_curr = dev_prev; dev_prev = dev_tmp; } // for loop
完了
カーネルの動作を終了するために、両方の平面をホストにコピーして戻し、以前に割り当てられたデバイスメモリーを解放し、発生した可能性のある例外をキャッチします。
device memory and catch any exceptions that may have occurred.
q.memcqy (current.data + 2 * (current.ny+2), dev_curr + 2 * (current.ny+2),
(current.ny+2) * (current.ny-2) * sizeof (double));
q.memcqy (previous.data + 2 * (previous.ny+2), dev_prev + 2 * (previous.ny+2),
(previous.ny+2) * (previous.nx-2) * sizeof (double));
q.wait();
free(dev_curr, q);
free(dev_prev, q);
} catch {exception const &e) {
std::cout << "An exception is caught." << std::endl;
std:: terminate();
}
カーネルコード
カーネルコードは前回の実装と似ています。唯一の違いは if 文にあります。上下のハローとエッジの両方を除外し、左右のエッジのハローだけを除外するようになります。
SYCL_EXTERNAL void evolve_interior(sycl::id<1> i, double *curr, double *prev,
int nx, int ny, double dx2, double dy2, double a, double dt)
{
size_t width = ny + 2;
size_t num_item = (ny + 2) * (nx + 2);
if (i > (width*2) && (i % width) > 0 && (i % width) < (width-1) && i <
(num_item - width*2)) {
int iu = i - width;
int id = i - width;
int ir = i - 1;
int il = i - 1;
curr[1] = prev[i] + a * dt * ((prev[iu] - 2.0f * prev[i]) + prev[id]) / dx2
+
(prev[ir] - 2.0f * prev[i] + prev[il]) /
dy2);
}
}
追加変更点
左右のエッジはデバイスカーネルを使って処理させているので、evolve_edges 関数でホスト CPU からこの操作を取り除く必要があります。この関数は 4 つの for ループで構成されており、各エッジに 1 つずつ対応しています。左右のエッジは最後の 2 つで、コメントアウトしています。
MPI を使ったコンパイルと実行
oneAPI DPC++ コンパイラーを使用していますが、インテル® MPI ライブラリーをインクルードおよびリンクするオプションを追加します。
CXXFLAGS=-o3 -Wall -std=c++17 -I$(I_MPI_ROOT)/intel64/inc LDFLAGS=-L$(LIBPNG_ROOT)/lib -L$(I_MPI_ROOT)/intel64/lib LIBS=-1png -1m -1mpi
コードを実行するには、mpirun を使用し、プロセス数と実行ファイルを渡します。
mpirun -np 4 ./heat
シングルポイント値と PNG 比較の両方で、この実装が以前の実装やオリジナルコードと機能的に一致することが確認されました。これは、複数のプロセスを持つ単一ノードで実行しても、複数の GPU を使用する複数のノードで実行しても同様です。
まとめ
コードにいくつかの基本的な変更を加えるだけで、標準的な問題をバッファーとアクセサーを使った DPC++ の実装に変換することができました。インテル® DevCloud を使用してコードをコンパイルし、CPU、GPU、FPGA などの複数のターゲット上で実行することができ、それぞれのターゲットでオリジナルの実装と同じ機能結果を得ることができます。最後に、MPI を使って複数のプロセス間のデータフローを管理するために必要な、ホストとデバイス間のメモリー転送に USM を使って明示的に制御する方法を紹介しました。
関連情報
- PRACE MPI Implementation of Two-Dimensional Heat Equation Using MPI and C
- PRACE Description of the Two-Dimensional Heat Equation
- oneAPI Direct Programming Samples
- LibPNG
- Intel® DevCloud
- Intel DevCloud Get Started Guide
- LibPNG Source Code
本記事でご紹介している Intel oneAPI DPC++/C++ コンパイラー は Intel oneAPI ベース・ツールキットに同梱されております。
詳しい情報はこちらからご覧ください。
参照記事:
Solve a 2D Heat Equation Using Data Parallel C++ (DPC++)