

データ並列 C++ (DPC++) は、 Khronos SYCL* 標準ベースのヘテロジニアスで移植性の高いプログラミング言語です。 このシングルソース・プログラミング言語は、 CPU、 統合 / ディスクリート GPU、 FPGA、 その他のアクセラレーターなど、 さまざまなプラットフォームをターゲットにすることができます。 ここでは、 DPC++ で何ができるのか理解するため、 重要な OpenCL* アプリケーションである GPU-Quicksort を DPC++ に移行します。 目標は、 OpenCL* アプリケーションの性能を超えることです。 OpenCL* C で汎用アルゴリズムを記述することは非常に困難であり、 異なるデータ型を扱うソートのようなアルゴリズムの実装では、 これが深刻な問題となります。 OpenCL* で記述されたオリジナルの GPU-Quicksort は、 符号なし整数をソートします。
ここでは、 DPC++ でテンプレートを使用して、 複数のデータ型に対応した GPU-Quicksort を実装する方法を示します。 そして、 DPC++ が移植性に優れていることを示すため、 GPU-Quicksort を Windows* と RHELに移植します。
GPU-Quicksort とは
GPU-Quicksort は、 高度に並列化されたマルチコア ・ グラフィックス・プロセッサー向けに設計された、 ハイパフォーマンスなソート・アルゴリズムです。 2009 年に、当時スウェーデンのチャルマース工科大学の学生であった Daniel Cederman 氏と Phillippas Tsigas 教授によって開発されました。 元々 CUDA* で実装されていましたが、 2014 年に筆者がインテル® インテグレーテッド ・プロセッサー ・ グラフィックス上でハイパフォーマンスを実証し、 入れ子の並列処理とワークグループ ・スキャン関数を使用するため OpenCL* 1.2 と OpenCL*2.0 で実装し直し、 インテルの OpenCL* ドライバーで完全に実装されました。 ここでは、 GPU-Quicksort のOpenCL* 1.2 実装を DPC++ に移行して、 符号なし整数だけでなく、 単精度や倍精度の浮動小数点もソートできるように実装を汎用化します。
OpenCL* とは
OpenCL* 1.2 実装をベースに作業を開始します。 インテルは、 ヘテロジニアス並列システムをプログラミングするための Khronos 標準規格である OpenCL* を、 さまざまなオペレーティング ・ システムとプラットフォームで完全にサポートしています。 OpenCL* は以下で構成されます。
- ランタイム
- ホスト API
- デバイス C ベースのプログラミング言語である OpenCL* C
これは OpenCL* の利点でもあり、 制限でもあります。 利点は、 ハイパフォーマンスで移植性の高いヘテロジニアス並列アプリケーションを記述できることです。 主な制限は、 ホスト側とデバイス側で別々のコードを記述してデバッグする必要があること、 およびプログラマーに馴染みのあるテンプレートやその他の C++ 機能を利用できないため、 汎用ライブラリーの記述が困難なことです。
データ並列 C++ とは
データ並列 C++ (DPC++) は、 Khronos SYCL* を拡張したインテルの実装です。 SYCL* 標準は、 上記のOpenCL* の制限に対応するように設計されています。 DPC++ は次の機能を提供します。
- シングルソースのプログラミング ・ モデル。 ホストとデバイスを同じコードベースでプログラミングできます。
- C++ テンプレートとテンプレート ・メタプログラミング。 移植性を損なうことなく、 パフォーマンスへの影響を最小限に抑えて、 デバイス上でこれらを活用できます。
DPC++ では、 プログラマーは CPU、 GPU、 および FPGA をターゲットにして、 アクセラレーター固有のチューニングを行うことができ、 OpenCL* よりも確実に改善されています。 また、 インテル® VTune™ プロファイラーやインテル® Advisor などのインテル® ソフトウェア ・ ツールと、 GDB でサポートされています。 ここでは、DPC++ の特にテンプレート機能を活用します。
開始点 : 2014 年の Windows* アプリケーション
「OpenCL* 2.0 の GPU-Quicksort: 入れ子の並列処理とワークグループ ・ スキャン関数」にある、OpenCL* 1.2 で実装された GPU-Quicksort を開始点として使用します。このアプリケーションは、Windows*向けに記述されているため、 作業を始める前に、時間を測定するクロスプラットフォーム ・コードを追加し、アライメントされたメモリーの割り当て / 解放を Windows* の _alligned_malloc/_aligned_free から aligned_alloc/free に変更して、Ubuntu 18.04 に移行しました。
GPU-Quicksort アーキテクチャーについて簡単に見てみましょう。 2 つのカーネルで構成されます。
1. gqsort_kernel
2. lqsort_kernel
OpenCL* 1.2 で記述されたこれらのカーネルは、 ディスパッチャー ・ コードによって結合され、 入力が lqsort_kernel でソートできる小さなチャンクに分割されるまで繰り返し gqsort_kernel を呼び出し
ます。 ユーザーはアプリケーションで以下を指定できます。
- 測定のためソートを実行する回数。
- カーネルを実行するベンダーとデバイス。
- カーネルを実行するベンダーとデバイス。
- 入力のサイズ。
- デバイスの詳細を表示するかどうか。
このアプリケーションは、典型的な OpenCL* アーキテクチャーに従って、OpenCL* プラットフォームとデバイスを初期化し、コードをビルドするユーティリティーをサポートします。 OpenCL* カーネルとサポート関数は、ユーザー引数を受け取るメイン ・アプリケーションとは別のファイルにあり、 プラットフォームとデバイスを初期化し、カーネルをビルドし、 メモリーを適切に割り当て、 バッファーを作成してカーネル引数にバインドし、ディスパッチャー関数を起動します。
データ並列 C++/OpenCL* の相互運用性 : プラットフォームの初期化
最初に、 インテル® oneAPI ベース・ ツールキットをインストールします。 これには、 インテル® oneAPI DPC++ コンパイラーが含まれます。 CL/sycl.hpp ヘッダーをインクルードして、 DPC++ の冗長性を避けるため名前空間 cl::sycl を使用して DPC++ への移行を開始します。

プラットフォーム、デバイス、コンテキスト、およびキューは、OpenCL* ではなく、簡潔な DPC++ で初期化します。

アプリケーションの残りの部分は OpenCL* ベースであるため、 OpenCL* コンテキスト、 デバイス、 およびキューを取得する必要があります。

これが最初の反復です。 インテル® DPC++ コンパイラーで設定してコンパイルし、 実行します。
データ並列 C++: インテルの GPU の選択
最初の反復の欠点は、 常にデフォルトのデバイスを選択することです。 選択されるデバイスは、 インテルの GPU であるとは限りません。 インテルの GPU を指定するには、 カスタム ・ デバイス ・ セレクターを記述する必要があります。

ユーザーが要求した場合、 intel_gpu_selector を使用してインテルの GPU を選択します。
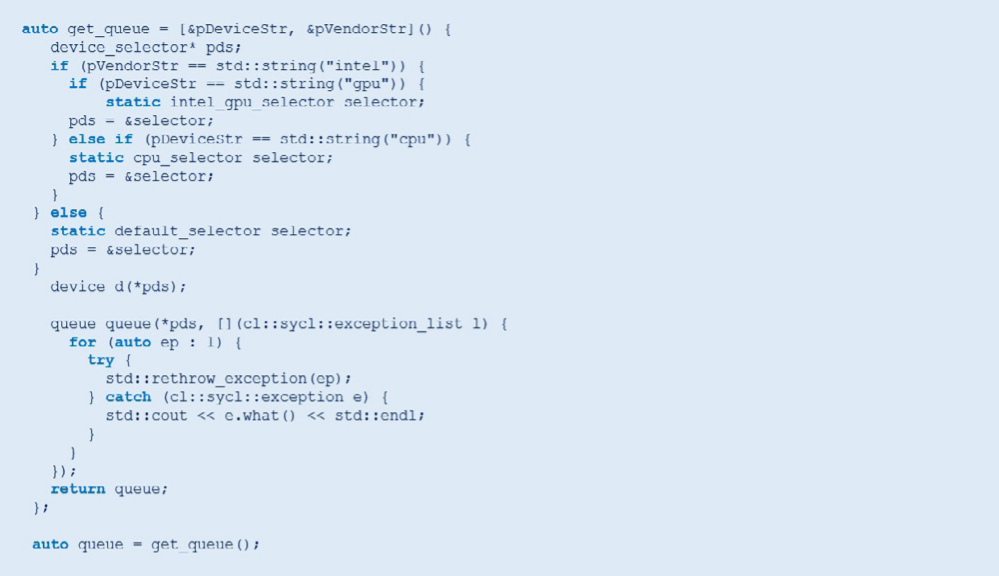
データ並列 C++: カーネル引数の設定とカーネルの起動
第 3 反復では、 DPC++ を使用してカーネル引数を設定し、 カーネルを起動します。 プログラムのビルドとカーネルの取得は、 OpenCL* で行います。 cl::sycl::kernel オブジェクトを使用してオリジナルの OpenCL* カーネルをラップします。 次に例を示します。

clSetKernelArg メ ソ ッド を DPC++ の set_arg メ ソ ッド に、clEnqueueNDRange 呼び出しを
parallel_for 呼び出しにそれぞれ置き換えます。 以下の例は、gqsort_kernel ですが、 lqsort_
kernel の変更も非常に似ています。

以下のように、 1 回の set_args 呼び出しですべてのカーネル引数を設定することもできます。

parallel_for も次のように簡潔に指定することができます。

データ並列 C++: バッファーの作成とアクセスモードの設定
OpenCL* バッファーを DPC++ バッファーに変換します (最初の 2 つは、 アライメントされた割り当てで関数に参照渡しされるメモリーをラップしており、 残りの 3 つは STL ベクトルから作成されます)。 参照渡しのバッファーは、 get_access メンバー関数の前に template キーワードを使用します。 必要なアクセス(読み取り、 書き込み、 あるいは両方) に応じて、 バッファーのアクセスモードは異なります。 カーネル引数としてバッファーを直接渡すのではなく、 バッファーへのアクセサーを渡します。

データ並列 C++: プラットフォームとデバイスのプロパティーの照会
OpenCL* では、clGetPlatformInfo メソッドと clGetDeviceInfo メソッドを使用してプラットフォー
ムとデバイスのプロパティーを照会します。 これらの情報の照会には、 get_info<> メソッドを使用します。次に例を示します。

または、 次のようなより複雑な構造のプロパティーを照会することもできます。

OpenCL* カーネルからデータ並列 C++ への移行 – パート 1: gqsort_kernel
ここまでは、 DPC++ でプラットフォームとデバイスを初期化し、 バッファーとアクセサーを作成してカーネルにバインドし、 デバイスでカーネルを起動しました。 しかし、 カーネルの作成は OpenCL* で行う必要があります。OpenCL* C と clBuildProgram/clCreateKernel API を使用して、 プログラムをビルドしカーネルを作成します。 OpenCL* C カーネルは、 実行時にビルドの前にプログラムにロードされる別のファイルに格納されます。 これを変更します。 2 つのカーネルのうち、 簡単な gqsort_kernel から作業します。
DPC++ では、 ラムダまたはファンクターを使用してカーネルを作成します。 通常、 小さなカーネルはラムダを使用して作成します。 サポート関数を使用する複雑なカーネルでは、 ファンクター ・ クラスを作成したほうが良いでしょう。 gqsort_kernel_class ファンクターを作成して、 後で複数のデータ型をソートできるようにテンプレート化します。

典型的なファンクター ・ クラスには、 パラメーターとして反復 ID (この例では nd_item<1> id) を受け取 る void operator() があります。 カーネル本体は void operator() にあります。 ファンクターには、 OpenCL* カーネルのグローバルおよびローカル ・メモリー ・ ポインターと同等の、 グローバルおよびローカル アクセサーを受け取るコンストラクターがあります。 典型的な DPC++ ファンクターには、 グローバルおよび ローカルアクセサーの型を定義する using 句を持つプリアンブルがあります。gqsort_kernel の例では、 次のようになります。

ファンクターの private セクションには、 void operator() の本体で使用されるすべてのグローバルおよ
びローカルアクセサーが含まれます。 この例では、 次のようになります。 最初の 5 つは、 グローバルバッファーへのアクセサーで、 残りはローカルバッファーへのアクセサーです。

gqsort_kernel は、 サポート構造体と 2 つのサポート関数 plus_prescan と median を使用する複雑
なカーネルです。 これらのサポート関数は、特殊な OpenCL* 関数を使用し、ローカルメモリー配列および変数、ローカルおよびグローバルバリア、 アトミック操作を幅広く使用します。 これらの要素をすべて DPC++ に変換する必要があります。
関数から開始しましょう。 構造体はテンプレート化されているため省略します。 スキャン合計を計算する plus_prescan 関数は比較的単純なため、 ソートを汎用的にする準備としてテンプレート関数にするだけで DPC++ に移行できます。

median 関 数 は、 テ ン プ レ ート 関 数 に す る だ け で なく、 OpenCL* C の select 関 数 を DPC++ の cl::sycl::select 関数に置き換えて、 同様のホスト関数と区別するため名前を median_select に
変更します。

OpenCL* C では、 ローカルメモリー変数と配列をカーネルの本体内で作成して、 カーネル引数として渡すことが可能です。 しかし、 DPC++ では、 ファンクターを使用する場合、 ファンクターを構築する際にローカル ・ バッファー ・アクセサーを渡します。 この例では、 すべてのローカルメモリー変数と配列は符号なし整数を格納するため、 特殊な local_read_write_accessor 型を作成します。

すべてのローカルメモリー変数を宣言します。

そして、 それらをパラメーターとして、 グローバル・バッファー・アクセサーとともにファンクター・コンストラクターに渡します。 次に、 生成されたオブジェクトを parallel_for に渡します。

この点において、 DPC++ は OpenCL* C よりも複雑です。 get_group_id 関数と get_local_id 関数は
次のようになります。

ローカルバリアは、

から以下に変更されます。

グローバルおよびローカルバリアは、

から以下に変更されます。

DPC++ のアトミック操作は、 OpenCL* C のように洗練されていません。
OpenCL* C では簡潔な以下のコードが

DPC++ では次のようになります。

DPC++ のアトミック操作は、 グローバルまたはローカル ・メモリー ・ ポインターを直接操作できないため、cl::sycl::atomic<> 変数をアトミック操作を行うために作成しています。
ここまでで、 サポート構造体とサポート関数を変換してテンプレート化し、 特殊な OpenCL* C 関数を DPC++ に変換しました。 また、 ローカルアクセサーを持つテンプレート関数を作成し、 バリアとアトミック操作を変換しました。
OpenCL* カーネルからデータ並列 C++ への移行 – パート 2: lqsort_kernel
lqsort_kernel の変換も gqsort_kernel の変換と似ています。lqsort_kernel_class ファンクターを作成して、 ローカルメモリー配列と変数、 およびバリアを変換します (アトミック操作はありません)。lqsort_kernel もサポート関数とサポート構 造体を 使用します。 gqsort_kernel で使用されるplus_prescan と median_select に加えて、 lqsort_kernel にはより複雑な bitonic_sort とsort_threshold があります。 変換後、 これらの関数は lqsort_kernel_class のメンバー関数になります。 DPC++ では反復オブジェクトが必要なバリアの使用により、 これらの関数のシグネチャーは変わります。 これらの関数は、 ローカルおよびグローバル ・メモリー ・ ポインターを使用するため、 特別な処理が必要です。 そのため、 OpenCL* C シグネチャーは、

から以下に変わります。

同様に、

も以下に変わります。

gqsort_kernel と同様に、 後で複数のデータ型を扱えるように、 UINT_MAX マクロを std::numeric_ limits::max() に置き換えてこれらの関数を変換します。 lqsort_kernel を変 換する際に、 ローカルメモリーへ のポインター (local uint* sn; など) は local_ptr<> オブジェクト (local_ptr sn; など) に置き換えられます。 ローカルアクセサーから ローカルポインターを取得するため、 アクセサーの get_pointer メンバー関数を呼び出します。

local_ptr<> オブ ジェクトと global_ptr<> オ ブ ジェ クト は ポイ ンター演算を使用するため、d + d_offset (d はグローバルポインター) は次のようになります。

ローカルメモリー変数は、 サイズ 1 のアクセサー (つまり、 gtsum[0] のようなインデックス 0 の配列アクセス) として変換します。 lqsort_kernel の変換が完了したら、 DPC++ へ完全に移行できますが、 この時点では符号なし整数しかソートできません。 しかし、 サポート構造体とサポート関数、および 2 つのメインカーネルのファンクター・クラスはすでにテンプレート化されているため、 複数のデータ型に対応するのは容易です。
データ並列 C++ の利点 : テンプレートと注意事項
DPC++ の真の力は、 C++ テンプレートを使用して汎用コードを記述できることです。 このセクションでは、 GPU-Quicksort を汎用化して、 符号なし整数だけでなく、 単精度や倍精度の浮動小数点など、 ほかの基本 データ型もソートできるようにします。 前述の UINT_MAX かstd::numeric_limits::max() への 変更に加えて、median_select 関数を変更する必要があります。 cl::sycl::select は、 第 1 引数と 第 2 引数の型のサイズに応じて、 異なる第 3 引数を受け取るため、 select_type_selector 型の特徴 クラスを追加します。

これにより、 ブール 値の比較を cl::sycl::select で必要な適切な型に変換することができます。
median_select は次のようになります。

追加の型に対応するには、 select_type_selector を編集します。 これで、 GPUQSort は GPU で単精
度と倍精度の浮動小数点もソートできるようになりました。
Windows* と RHEL への移植
DPC++ の移植性を実証するため、 Windows* と RHEL へコードを移植します。 RHEL への移植は非常に簡単です。 リンク時にインテルの imf 数学ライブラリーを追加するだけです。 Windows* への移植には、 もう少し手間がかかります。 コンパイル時に次の定義を追加します。

倍精度の cl::sycl::select は 第 3 引数に unsigned long long 型 (Linux* では unsigned
long 型) を必要とすることから、 倍精度の select_type_selector を次のように変更します。

Windows* では、 マクロ定義が std::max および std::min と競合しないように、 max および min を未定義にします。 これで、 Windows* および RHEL でインテルの GPU を使用して、 符号なし整数、 単精度浮動小数点、 倍精度浮動小数点をソートできます。
今すぐ実践してみましょう
この記事では、 GPU-Quicksort をオリジナルの OpenCL* 1.2 から DPC++ へ移行する方法をステップごとに説明しました。 ステップごとに、 アプリケーションの動作を確認できることが重要です。 DPC++ をワークフローに導入することを検討している場合は、 小規模から初めて、 徐々に追加していくか、 時間をかけて完全に移行してください。 容易に OpenCL* と DPC++ をコードベースに混在させ、 両方の利点を得られます。 従来の OpenCL* カーネルをそのまま使用しつつ、 DPC++ で開発する新しいコードでは C++ テンプレート、 クラス、ラムダを活用できます。 Windows* や各種 Linux* ディストリビューションへのコードの移植も容易で、 開発プラットフォームを選択できます。 さらに、 強力なインテルのツールが DPC++ プログラムのデバッグ、 プロファイル、 解析を支援します。
本記事は「Parallel Universe 40号」の「GPU-Quicksort」より転載したものです。その他「Parallel Universe」の記事はこちらからご覧いただけます。