

この記事は、インテル® デベロッパー・ゾーンに公開されている「Solving Heterogeneous Programming Challenges with Fortran and OpenMP」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
はじめに
ヘテロジニアス・コンピューティングは、長年にわたってコンピューター・サイエンスの中心にありました。最近では、ハードウェアの多様化、クラウド・コンピューティングの完熟したソリューション、および AI/ML 計算需要の指数関数的な増加の波に乗り、ハードウェア設計の具体的な目的を後押しすることで、ハードウェアはよりミッション・クリティカルになり、ビジネスの成功の鍵を握っています。ヘテロジニアス・コンピューティングという新しい技術トレンドに適応するには、いくつかの特性を満たすため、最先端のソフトウェア工学、基本的なプログラミング、コード設計が必要です。
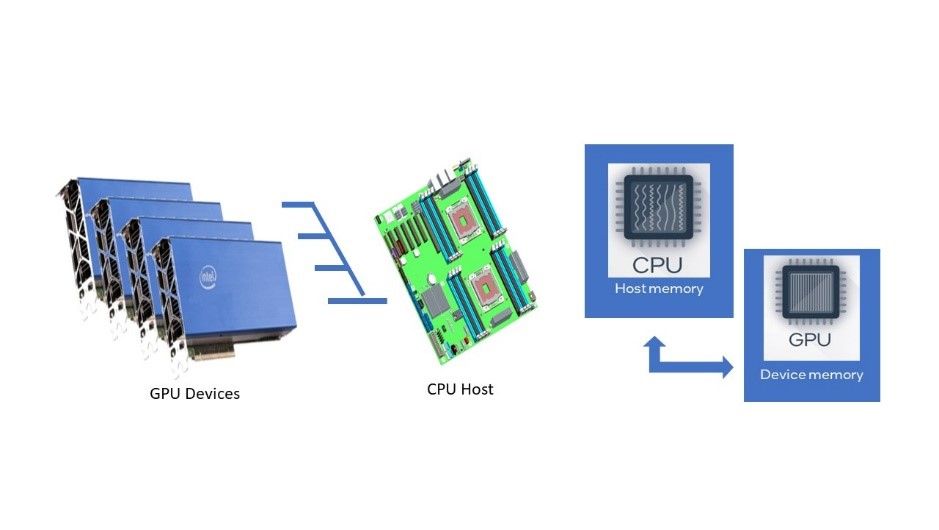
いくつかの重要な特性を以下に示します。
- さまざまなベンダーのさまざまなハードウェア (CPU、GPU、FPGA など) で実行できます。
- ホストおよびデバイスメモリー、デバイス上の各種メモリー、ハードウェア・スケジューラーによってロードされた各種メモリーイメージなど、さまざまなメモリーモデルを認識して利用できます。
- 非巡回グラフの実行順序で実行できます。
- 他の確立されたライブラリーの既存の API でプログラミングでき、他のバックエンド・カーネルと相互運用できます。
カーネル・プログラミングとディレクティブベース・プログラミング
科学、研究、工学分野のハイパフォーマンス・コンピューティングにおいて、最も重要なプログラミング基本言語は C/C++ と Fortran です。C/C++ は最もポピュラーな選択肢です。Fortran は最も古いプログラミング言語で、今でも鮮やかに進化しており、ミッション・クリティカルで非常に洗練された巨大なコードベースを持っています。Fortran ベースの言語は、時代とともに絶えず進化しています。最新の Fortran は、特に数値計算や科学計算に適した、汎用のコンパイル済み命令型プログラミング言語です。
ヘテロジニアス・コンピューティングの進歩により、基本言語のパラダイムは常に再構築されています。ヘテロジニアス・コンピューティングのフレームワークとして一般的なプログラマーに最も人気があるのは、カーネル・プログラミングとディレクティブベース・プログラミングの 2 つです。
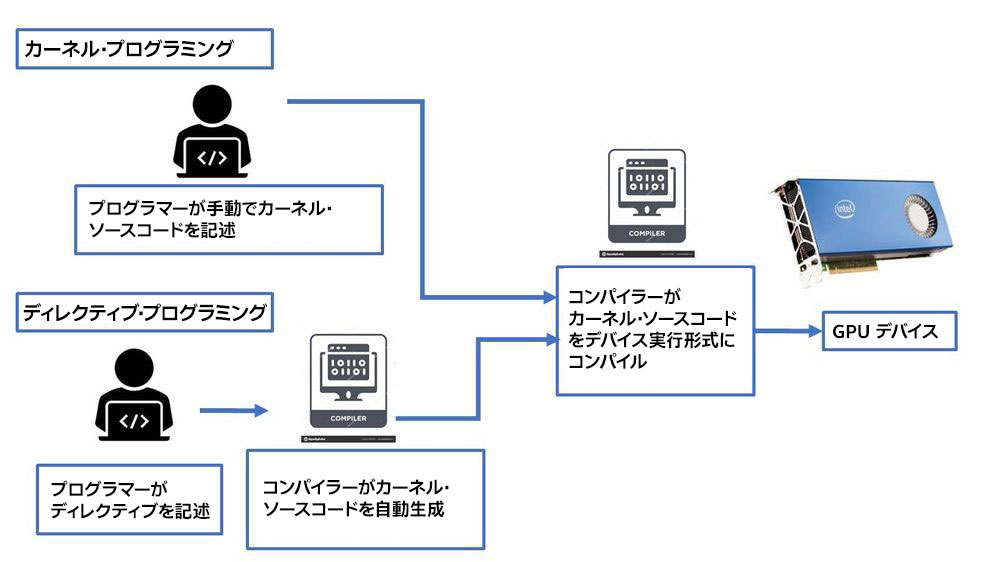
カーネル・プログラミングは通常、基本言語拡張によって実装されます。ターゲット・ハードウェア上でどのように計算を行うかは、プログラマーに任せられています。C/C++ では、CUDA*、SYCL*、OpenCL* などが使用さることが多いです。SYCL* やその他の指示文による並列プログラミングについては、別の論文でも説明されています。Fortran 向けの一般的なカーネル・プログラミング・モデルはありません。Fortran プログラマーは、C/C++ コードを呼び出して、GPU 上で実行する CUDA*/SYCL*/OpenCL* カーネルを利用できます。
もう 1 つの重要なフレームワークは、ディレクティブ・プログラミングです。特定のターゲット・ハードウェア用のコードカーネルを生成するハードウェア固有の言語拡張でコーディングする場合と比較して、ディレクティブ・プログラミングは、「単一のコードボディー」という特徴があります。ディレクティブ・プログラミングは、1 つのソースコードが、アクセラレーターの有無に関係なく複数のプラットフォームで動作することを仮定します。コンパイラーがディレクティブを理解できなかったり、コードのディレクティブ処理をオフにした場合、ディレクティブは無視されます。ディレクティブベース・プログラミングの標準として最もよく知られているのは、OpenACC と OpenMP* の 2 つです。OpenMP* に比べると歴史は浅いものの、Cray、CAPS、NVIDIA、PGI によって開発された OpenACC は、CPU、GPU、およびさまざまなアクセラレーターに対応した、ハイパフォーマンス・コンピューティング向けの世界初の高レベルのディレクティブベース・プログラミング・モデルとして知られています。
課題
ディレクティブ・プログラミングの主な対象はドメイン・サイエンティストであり、その多くはアルゴリズムをコードで表現する程度のプログラミングしか学んでいません。多くの場合、これらの開発者は、CUDA*/SYCL*/OpenCL* などのカーネル・プログラミング・モデルを使用してアルゴリズムを明示的に並列化するのに必要なプログラミング・スキルや時間がありません。開発者であるドメイン・サイエンティストは、コード内の並列処理を表現する記述スタイル、例えば、ループ構造は並列処理の対象である、行列は入力としてのみ使用され、出力用に転送する必要はない、一部の関数呼び出しはデバイス上でのみ呼び出される可能性がある、などに容易に適応できます。OpenMP* により、これらのユーザーは、ループと配列という馴染みのあるコーディング・スタイルを維持しながら、デバイスとホストの配列が不要になるようにデータ管理を簡素化し、ループを GPU カーネルに自動的に変換することで、最新の GPU でコードを高速化することができます。また、既存のコードバリアントは、利用可能なアクセラレーター・デバイスにディスパッチできます。OpenMP* は、多くの場合、新規ユーザーやドメイン・サイエンティストにとって習得がより簡単です。一方、開発ツールベンダーは、より複雑なディレクティブを処理してアクセラレーターの潜在能力を最大限に引き出すコンパイラーを開発するため協力することができます。
ソリューション
ヘテロジニアス・コンピューティングにおける Fortran + OpenMP* オフロードの仕組み
Fortran + OpenMP* オフロードが、ヘテロジニアス・コンピューティングにおける次の 3 つの課題をどのように解決するかを例を挙げて説明します。
- オフロード
- メモリー管理
- デバイス上での既存 API の呼び出しここでは、Fortran と OpenMP* の基本知識があることを前提としています。コードスニペットはコンパイル用の完全なコードではありません。要点を簡潔に示すため、変数の宣言/初期化は省略されています。コード例の完全版は、「OpenMP* 公式リファレンス・ドキュメント」 (英語) を参照してください。
ソリューションの説明
オフロード
最初に、GPU へのオフロードの例から見てみましょう。
最初の例は、データ移動を考慮しています。target 構文は、コード領域をターゲットデバイスにオフロードします。変数 p、v1、v2 は、map 節を使用してターゲットデバイスに明示的にマップされています。変数 N は、ターゲットデバイスに暗黙的にマップされています。
!$omp target map(v1,v2,p) !$omp parallel do do i=1,N p(i) = v1(i) * v2(i) end do !$omp end target
これは単純なスカラーデータ移動です。ポインター、構造体 (集合体)、割付け配列、マッピングメカニズムは高度なトピックであるため、ここでは取り上げません。
2 つ目の例は、target teams 構文と distribute parallel do 構文を使用して target teams 領域でループを実行する方法を示します。target teams 構文は、チームのリーグを作成し、各チームのプライマリー・スレッドが teams 領域を実行します。
チーム領域を実行するプライマリー・スレッドごとに、teams 構文の reduction 節によって変数 sum のプライベート・コピーが作成されます。チーム内のプライマリー・スレッドとすべてのスレッドは、parallel do 構文の reduction 節によって作成された変数 sum のプライベート・コピーを持ちます。sum 変数の 2 つ目のプライベート・コピーは、teams 構文によって作成されたプライマリー・スレッドの sum 変数のプライベート・コピーにレデュースされます。teams 領域の終了時に、各プライマリー・スレッドの sum 変数のプライベート・コピーは、最終の sum 変数にレデュースされ、target 領域に暗黙的にマップされます。
リーグ内のチームの数は変数 num_blocks の値以下に、リーグ内の各チームのスレッド数は変数 block_threads の値以下になります。外側のループの反復は、各チームのプライマリー・スレッドに分配されます。チームのプライマリー・スレッドが内側のループよりも先に distribute parallel do 構文を検出すると、チーム内のほかのスレッドがアクティブになり、チームは並列領域を実行し、ループの実行を分担します。
!$omp target map(to: B, C) map(tofrom: sum)
!$omp teams num_teams(num_teams) thread_limit(block_threads) reduction(+:sum)
!$omp distribute
do i0=1,N, block_size
!$omp parallel do reduction(+:sum)
do i = i0, min(i0+block_size,N)
sum = sum + B(i) * C(i)
end do
end do
!$omp end teams
!$omp end target
メモリー管理
次に、OpenMP* を使用して、ヘテロジニアス・システムでメモリーを管理する例を見てみましょう。target data 構文は、配列 v1 と v2 をデバイスデータ環境にマップします。ホストデバイスで実行するタスクは、最初の target 領域に到達し、領域の実行が完了するまで待機します。最初の target 領域の実行後、ホストデバイスで実行するタスクは、関数 init_again_on_host() を呼び出して、タスクデータ環境の v1 と v2 に新しい値を代入します。target update 構文は、2 つ目の target 領域を実行する前に、タスクデータ環境から v1 と v2 の新しい値を、target data 構文のデバイスデータ環境内の対応するマップされた配列要素に割り当てます。
!$omp target data map(to: v1, v2) map(from: p)
!$omp target
!$omp parallel do
do i=1,N
p(i) = v1(i) * v2(i)
end do
!$omp end target
call init_again_on_host(v1, v2, N)
!$omp target update to(v1, v2)
!$omp target
!$omp parallel do
do i=1,N
p(i) = p(i) + v1(i) * v2(i)
end do
!$omp end target
!$omp end target data
デバイス上での既存 API の呼び出し
以下の例は、インテルによる拡張の実装であり、現在はインテル® Fortran コンパイラー (ifx) でのみ利用可能です。target variant dispatch 構文はインテルによる拡張で、このディレクティブに続くサブルーチンや関数の呼び出しに対して、条件付きディスパッチ・コードを発行するようにコンパイラーに指示します。デフォルトのデバイスが利用可能な場合、バリアントバージョンが呼び出されます。次の例は、target variant dispatch 構文を使用して、MKL dgemm のターゲットデバイス用のバリアントを呼び出す方法を示しています。
include "mkl_omp_offload.f90" program main use mkl_blas_omp_offload integer :: m = 10, n = 6, k = 8, lda = 12, ldb = 8, ldc = 10 integer :: sizea = lda * k, sizeb = ldb * n, sizec = ldc * n double :: alpha = 1.0, beta = 0.0 double, allocatable :: A(:), B(:), C(:) allocate(A(sizea)) ! Allocate matrices… … ! Initialize matrices… … !$omp target data map(to:A(1:sizea), B(1:sizeb)) map(tofrom:C(1:sizec)) !$omp target variant dispatch use_device_ptr(A, B, C) call dgemm(‘N’, ‘N’, m, n, k, alpha, A, lda, B, ldb, beta, C, ldc) ! Compute C = A * B on GPU !$omp end target variant dispatch !$omp end target data
OpenMP* 実装
OpenMP* は、数少ない人気のディレクティブ・プログラミング・フレームワークの 1 つとして、コミュニティーの多大な努力が結集されています。大幅な改良と新しいアイデアを組み込んだ新しい仕様が、良いペースで発表されています。
AOMP は、OpenMP* と複数の GPU アクセラレーション・ターゲット (マルチターゲット) へのオフロードをサポートする AMD の LLVM/Clang ベースのコンパイラーです。インテル® Fortran コンパイラー (ifx) は、運用環境の CPU と GPU に対応しています。ifx コンパイラーは、インテル® Fortran コンパイラー・クラシック (ifort) のフロントエンドとランタイム・ライブラリーをベースにしていますが、LLVM バックエンド・コンパイラー・テクノロジーを採用しています。NVIDIA* HPC コンパイラーは、すべてのプラットフォームでマルチコア CPU 向けに OpenMP* を有効にし、NVIDIA* GPU へのターゲットオフロードをサポートしています。ARM、Flang、GNU、HPE、IBM、LLVM、Microsoft、Oracle などの他のベンダーも、自社のコンパイラー製品で堅牢な実装を積極的に提供しています。
IFX
インテル ® Fortran コンパイラー (ifx) は、Fortran コミュニティーにヘテロジニアス・コンピューティング実装を提供する最新のインテル製品です。インテル® Fortran コンパイラー・クラシック (ifort) のフロントエンドとランタイム・ライブラリーをベースに、LLVM バックエンド・テクノロジーを使用した新しいコンパイラーです。現時点で ifx は、Fortran 95 言語、OpenMP* 5.0 バージョン TR4、および一部の OpenMP* バージョン 5.1 のディレクティブとオフロード機能をサポートしています。ifx はバイナリー (.o/.obj) およびモジュール (.mod) ファイルと互換性があります。ifort で生成されたバイナリーとライブラリーは、ifx でビルドされたバイナリーやライブラリーとリンクでき、一方のコンパイラーで生成された .mod ファイルは、もう一方のコンパイラーで使用できます。どちらのコンパイラーも ifort ランタイム・ライブラリーを使用します。ifx は GPU オフロードもサポートしており、Fortran 2003、Fortran 2018、OpenMP* 5.0 および 5.1 (GPU オフロード) などの最新の標準に対応しています。詳細については、「適合性、互換性、および Fortran 機能」 (英語) を参照してください。
オープンソース、基本言語の進化、マルチベンダー
基本言語としての Fortran は、決して時代遅れではなく、鮮やかかつ実質的な発展を遂げています。コンピューティング・ハードウェアとソフトウェアが花開く時代に直面しながらも、Fortran は力強く生き続け、数多くの科学技術プロジェクトの中でミッション・クリティカルであり続けています。OpenMP* ランタイム・ライブラリーの堅牢な実装は、ターゲットデバイス上で並列処理と同時実行性を活用する記述方法を提供します。
関連情報
インテルによる Fortran + OpenMP* オフロードの実装についての詳細は、以下を参照してください。
以下のページでは、インテル® Tiber™ デベロッパー・クラウド (インテルの CPU、GPU、FPGA にアクセスできる無料のオンラインアカウント) へのアクセス方法を説明し、新しいインテル® Fortran コンパイラー (ifx) と OpenMP* の GPU オフロードを試すことができるチュートリアルを提供しています。
https://www.xlsoft.com/jp/products/intel/devcloud/index.html
手順に従って、最初の Fortran + OpenMP* オフロードプログラムを数分で試すことができます。