

この記事は、インテルのウェブサイトで公開されている「oneAPI and AI Tools 2025.1」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
インテル® ソフトウェア開発ツールの最新のアップデート 2025.1 がリリースされました。
今回のリリースでは、CPU、GPU、NPU 上での AI の生産性とパフォーマンスの向上に力を入れています。ビジュアル AI 推論のサポートを強化し、すべてのソフトウェア開発者向けに高度な並列コンピューティングの生産性とコード品質保証の向上を倍増させました。クラウドに接続されたエッジ推論デバイス、エクサスケール・スーパーコンピューター、あるいはその中間をターゲットとしている場合でも、本リリースのコンパイラーとライブラリー機能の更新により、作業が容易になり、生産性が向上します。
この記事では、これらの改善がソフトウェア開発にどのようなメリットをもたらすかについて説明します。
→ 主な機能改善の概要は、インテル® ソフトウェア開発ツール最新情報のトピック「より高速な AI、リアルタイム・グラフィックス、よりスマートな HPC: インテル® ソフトウェア開発ツール 2025.1 リリース!」で紹介されています。
まず、生成 AI (GenAI) とビジュアル AI のユースケースから見ていきましょう。
オープンソース AI フレームワークの活用
インテルは、業界標準のツールやフレームワークに注目し、最適化のノウハウや経験を提供することで AI に取り組んでいます。このアプローチは、既存の開発ワークフローや AI フレームワークを使用できるようにすることで、お客様にメリットをもたらします。
そのため、特定のハードウェア・セットに依存したり、レガシー・コードベースを放棄することなく、それらの利用を効率化し、インテルのハードウェアのメリットを活用できるように移行することが可能です。
TensorFlow や PyTorch、さらには JAX Python ライブラリーにも、インテルのハードウェア向けの最適化が追加されています。JAX Python ライブラリーはインテルの AI ツールに統合され、マシンラーニング・モデルの数値計算や科学計算、最適化タスクを高速化するインテル® ディストリビューションの Python* の最適化の恩恵を受けることができます。
PyTorch 向けの最新の最適化
PyTorch* 向けインテル® エクステンション (英語) で利用可能であり、PyTorch 2.6 にもアップストリームされている最新の追加機能と最適化は、AI ソリューションがインテルの CPU と GPU をシームレスにターゲットにできることを示しています。
DeepSpeed* 向けインテル® エクステンション (英語) が PyTorch リリースに統合されました。また、インテル® GPU デバイス上の SYCL カーネルサポートと同様のものを、DeepSpeed にすでにアップストリームされている Microsoft Research のオープンソース最適化ライブラリーに追加し、幅広い大規模言語モデル (LLM) に追加の最適化を適用しました。
2024年からは、torch.tensor デバイスの名前を変更するだけで、SYCL 対応デバイス上でアクセラレーターへのオフロードコードを実行できるようになりました
# CUDA Code
tensor = torch.tensor([1.0, 2.0]).to("cuda")
# SYCL Code
tensor = torch.tensor([1.0, 2.0]).to("xpu")FP32、BF16、FP16、自動混合精度 (AMP) などのデータ型の中から、AI ユースケースに最適なデータ型を使用できます。GenAI LLM は INT4 に最適化され、トランスフォーマー・エンジンは FP8 をサポートします。
例えば、縮小された FP16 浮動小数点データ型を、P-cores 搭載インテル® Xeon® 6 プロセッサーなどの CPU 上で CPU ネイティブのインテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) アクセラレーターと組み合わせて使用すると、PyTorch の Inductor モードと Eager モードの両方で推論が大幅にスピードアップします。
インテル® Arc™グラフィックスの全ファミリー (インテル® Core™ Ultra プロセッサー (シリーズ 2)、インテル® Arc™ A シリーズ・グラフィックス、インテル® Arc™ B シリーズ・グラフィックスなど) を含むインテル® GPU 向けに最適化が拡張されました。Windows では、インテル® GPU ソフトウェア・スタックのインストールが簡素化され、torch-xpu ターゲットのサポートと torch core のバイナリーリリースをワンクリックでインストールできるようになりました。
FlexAttention による推論の高速化
もう 1 つの興味深い追加機能は、FlexAttention の TorchInductor CPP バックエンド最適化における x86 CPU サポートです。これにより、高度な重み付き推論のパフォーマンスが向上します。
アテンション設定は、データセット入力シーケンスの最も関連性の高い部分にフォーカスするため、モデルに重みを割り当てる手段です。しかし、これらのアテンション重みには多くのバリアントが存在します。望ましい結果を得るため、重みの組み合わせを高度にカスタマイズする必要が頻繁に生じる場合、開発者やデータアナリストが、アテンション・メカニズムが適切に調整されていないために推論パフォーマンスの低下に頻繁に遭遇するのは当然でしょう。そこで PyTorch の FlexAttenstion の出番です。FlexAttenstion は、数行の PyTorch コードで再利用できる最適化済みのアテンション・メカニズムのバリアントを提供します。必要なアテンション・メカニズムの組み合わせは、torch.compile を使って FlexAttension カーネルに融合して最適化できます。手書きコードに匹敵するパフォーマンスを実現するため、使用されるすべてのアテンション・バリアントに包括的な最適化を適用できます。
→ ブログ記事「インテル® プラットフォーム向けの PyTorch 2.6 の最新機能を活用する」 (英語) を参照してください。
インテル® oneDNN と Python をベースに構築
インテルの PyTorch 向け最適化は、インテル® ディストリビューションの Python* とインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) (英語) の最新の機能も活用しています。
インテル® ディストリビューションの Python* は、3 つの基本パッケージで構成されています。
- dpnp (NumPy (英語) 向けデータ・パラレル・エクステンション)
- numba_dpex (Numba (英語) 向けデータ・パラレル・エクステンション)
- dpctl (デバイス選択、デバイス上のデータ割り当て、テンソルデータ構造のサポート、Python 向けユーザー定義データ並列拡張用のユーティリティーを備えたデータ・パラレル・コントロール・ライブラリー)
本リリースでは、以下に対応しました。
- Python Array API 仕様 (リビジョン「2023.12」) に 100% 準拠
- NumPy 2.0 サポートと NumPy 2.2.3 との互換性
- CuPy との 90% の機能互換性
これにより、インテルのハードウェアをターゲットとする場合、既存の Python 実装を変更することなく、さらに簡単に使用できます。
インテル® oneDNN にも多大な労力と開発が投入されました。最新のインテル® Xeon® プロセッサーと幅広いインテル® Arc™ グラフィックス向けの最適化とパフォーマンス・チューニングが強化されています。
開発者は、インテル® AMX 命令セット対応のインテル® Xeon® 6 プロセッサーを含む最新のインテル® Xeon® プロセッサー向けの最適化により、強化された行列乗算と畳み込みのパフォーマンスを活用して、データセンターの AI ワークロードを高速化できます。
クライアント CPU での AI 推論は、インテル® Arc™ グラフィックス上、特にインテル® Core™ Ultra プロセッサー (シリーズ 2) 搭載 AI PC とインテル® Arc™ B シリーズのディスクリート・グラフィックス上でインテル® oneDNN を使用するとパフォーマンスが向上します。インテル® oneDNN は、暗黙的なカジュアルマスクを使用したゲート付き多層パーセプトロン (ゲート付き MLP) と SPDA (Scaled Dot-Product Attention) により、AI モデルのパフォーマンスを最適化します。Graph API による int8 または int4 圧縮キーと値のサポートは、推論の速度と効率の両方を向上します。
モデル圧縮による推論の高速化
インテル® ニューラル・コンプレッサー (英語) の目的は、推論効率の向上を支援することです。
モデル最適化によりモデルサイズを縮小し、CPU、GPU、またはインテル® Gaudi® AI アクセラレーター上でディープラーニング推論の速度を向上させます。
これはオープンソースの Python ライブラリーであり、最先端の INT8/FP8/INT4/FP4/NF4 (正規化 Float 4) による低ビット LLM 量子化とスパース性を利用して、複数のディープラーニング・フレームワークにおける量子化、プルーニング、知識蒸留といった一般的なモデル最適化手法を自動化します。
エッジからクラウドへの推論スケーリングの事前準備として、大規模モデルから知識を蒸留し、小規模モデルの精度を向上するのに最適なツールです。
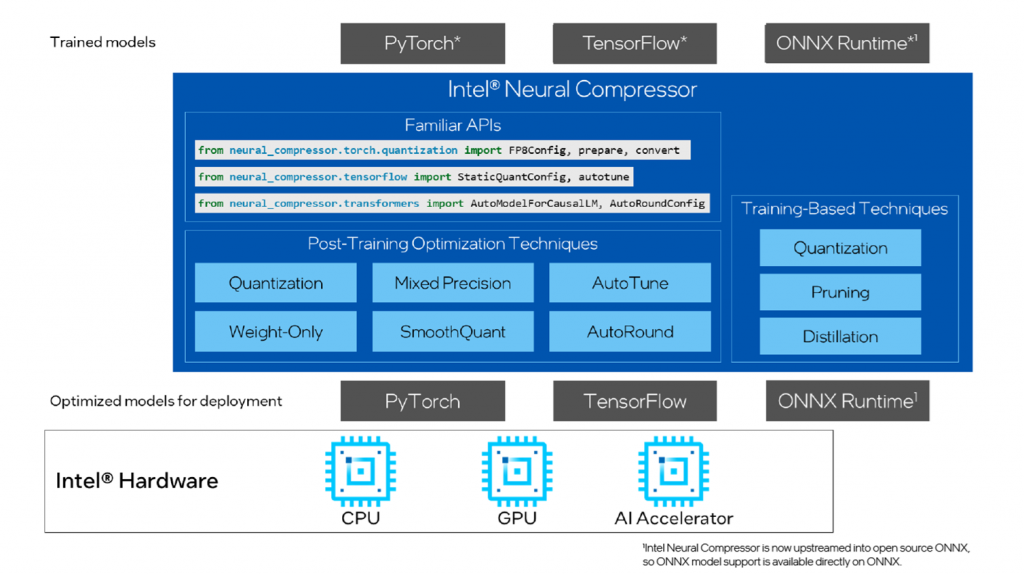
図 1: インテル® ニューラル・コンプレッサーの概要
ビジュアル AI とレンダリングの高速化
新リリースのインテル® oneAPI DPC++/C++ コンパイラーとインテル® DPC++ 互換性ツールでは、Vulkan および DirectX 12 との SYCL 相互運用性が強化されています。GPU からイメージ・テクスチャー・マップ・データを直接共有できるようになり、CPU と GPU 間の余分なイメージコピーが排除され、イメージ処理と高度なレンダリング・アプリケーションでシームレスなパフォーマンスが確保され、コンテンツ作成の生産性が向上します。
さらに、特に動的画像配列や、アクセサーではなくハンドルを介したイメージアクセスにおいてイメージ管理機能を強化する、SYCL 2020 のバインドレス画像拡張 (英語) が提案されています。
これらの改善は、SYCL 対応 GPU アクセラレーションを活用したゲーム、グラフィックス、ビジュアル AI、および視覚的に魅力的な動的コンテンツの開発を簡素化することを目的としています。これにより得られる生産性の向上は、GenAI、ビジュアル AI、そして高度で複雑な画像データ解析にメリットをもたらします。
AI 推論のプロファイルとチューニング
エッジ推論のパフォーマンスでは、潜在的なパフォーマンス・ボトルネックを理解し、インテル® Core™ Ultra プロセッサー搭載 AI PC 上で実行されるワークロードをチューニングすることが重要です。このプロセッサーには、CPU、GPU、ニューラル・プロセッシング・ユニット (NPU) の 3 つのコンピューティング・エンジンが搭載されています。インテル® VTune™ プロファイラーは、DirectML または WinML API を呼び出す AI ワークロードのパフォーマンス・ボトルネックを特定し、Python 3.12 で最も時間のかかるコード領域とクリティカルなコードパスを特定することで、ビジュアル AI の最適化を支援します。
AI PC の場合、NPU を含むプラットフォームとマイクロアーキテクチャーが考慮されます。NPU は、長時間にわたって持続的に実行される低消費電力の AI 支援ワークロードに最適です。例えば、背景のぼかしや画像のセグメンテーションなどのウェブカメラ・タスクを実行する場合、NPU で実行することで全体的なパフォーマンスが向上します。
AI アプリケーションのパフォーマンスを最大限に高めるには、NPU のコンピューティング・リソースとメモリーリソースを最大限に活用する必要があります。
インテル® VTune™ プロファイラーを使用すると、NPU で実行されているコードのボトルネックを特定できます。以下のことが可能です。
- NPU と DDR メモリー間で転送されるデータ量の把握
- NPU で最も時間のかかるタスクの特定
- NPU の使用率を時間経過とともに視覚化
- NPU の帯域幅使用率の把握
→ AI PC の推論ワークロードを高速化する方法を紹介したチュートリアル「インテル® Core™ Ultra プロセッサー上でインテル® VTune™ プロファイラーを使用して NPU 依存の AI PC アプリケーションを高速化する」 (英語) を確認してください。
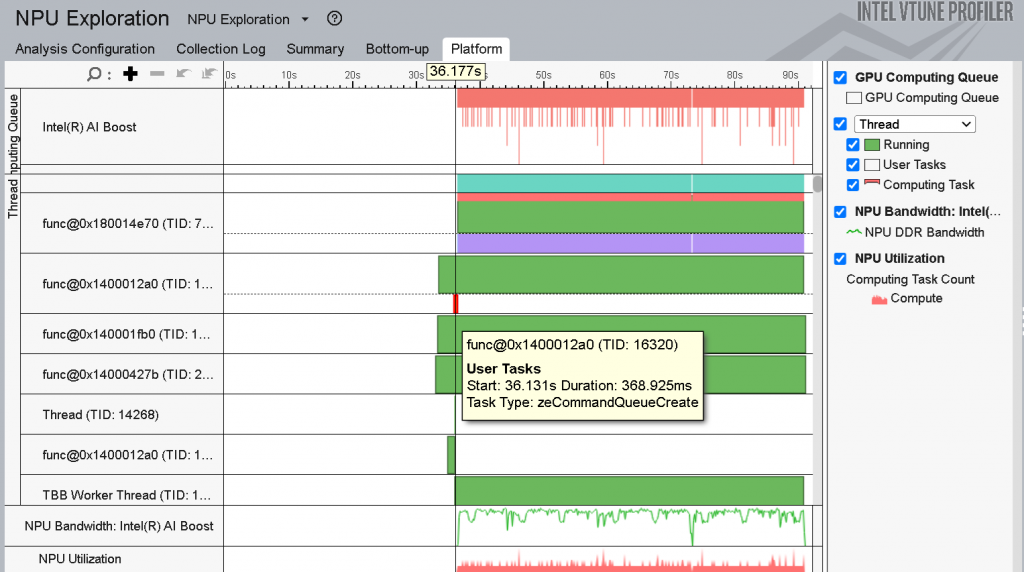
図 2: インテル® VTune™ プロファイラーの NPU 全般解析のスレッドビュー
→ インテル® VTune™ プロファイラーを使用した GenAI 大規模言語モデルのパフォーマンス解析とチューニングに関する一般的なチュートリアルは、「インテル® VTune™ プロファイラーを使用した GenAI LLM パフォーマンスの向上」 (英語) を参照してください。
高性能データ・アナリティクス
パフォーマンスのスケーリングは、フォームファクターや消費電力が制限された環境でエッジ推論やイメージ処理をサポートするだけでなく、分散コンピューティング構成やスーパーコンピューターだけが提供できる最高レベルの機能を必要とするユースケースにも、同じソフトウェア開発の原則とツールを適用し拡張します。
分散コンピューティング向けのスケーリング
インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) (英語) は、非常に大規模なデータセットの推論とトレーニングを最適化し、スケーリングするのに役立ちます。
世界規模の環境データ調査、大規模な人口統計調査、疫学研究、金融リスク評価などに AI を適用することを想像してみてください。高性能分散コンピューティングの原則を AI に適用することで、追加のコンピューティング・ニーズと、膨大な量のアドレス指定可能なモデルデータへのアクセスに対応できます。これにより、分散マルチノード構成を使用して、複雑または大規模なデータセット・モデルをより迅速にトレーニングすることが可能です。これは一般的な MPI および lib-fabrics 標準に基づいて構築されており、Cornelis Networks、InfiniBand、イーサネットなどのさまざまな相互接続をサポートしています。
共通標準への準拠により、新規および既存のディープラーニング・フレームワークへの統合が容易になります。2025.1 では、以下に対応しました。
- 集合通信の制御を強化するため、集合操作をサポートする Group API を拡張し、コミュニケーターを分割する新しいAPI を追加しました。
- 各プロセッサーがほかのすべてのプロセッサーに個別のメッセージを送信する、単一プログラムによる複数データ操作である all-to-all の最適化により、より効果的なスケールアップを実現します。
大規模データセットを使用する AI の計算領域は、従来のハイパフォーマンス・コンピューティングと AI の組み合わせです。大規模データセットを使用する分散型の可視化およびシミュレーション・ワークロードはますます増えており、トレーニング、推論、非線形方程式や微分方程式の数値解法、モンテカルロ・シミュレーションにおいて GPU アクセラレーション・オフロード・カーネルを活用しています。
このようなケースでは、インテル® MPI ライブラリーと新たにリリースされたインテル® SHMEM ライブラリー (英語) を併用することで、分散環境における通信とリモート・メモリー・アクセス (RMA) の効率を向上させることができます。
ポイントツーポイントのリモート・メモリー・アクセス (RMA)、OpenSHMEM 1.6 ストライド RMA 操作、アトミックメモリー操作 (AMO) 、シグナリング、メモリーオーダー、チーム、集合操作、同期など、OpenSHMEM 1.5 準拠の機能を備えたマルチノード・アクセラレーター・デバイスとホストをターゲットにすることができます。対称ヒープ API を使用したインテル® SHMEM ライブラリーの SYCL キュー順序付き RMA および SYCL ホスト USM アクセスにより、分散マルチノード SYCL デバイスアクセスを簡素化します。
→ サンプルコード (英語) とインテル® SHMEM ライブラリーのドキュメント (英語) を確認してください。
これらすべてをサポートするため、MPI 標準ベースの分散メッセージパッシングにも幅広い改善が加えられました。
- アプリケーションは、P-cores 搭載インテル® Xeon® 6プロセッサー向けの新しいパフォーマンス・チューニングを活用できます。これには、スケールアップを向上するスレッド分割とハンドオフ、インテル® MPIライブラリーをバックエンドとして使用したインテル® oneCCL 向けの CPU 推論の最適化、ポイントツーポイント共有メモリー操作の最適化などが含まれます。
- P-cores および E-cores 搭載プロセッサーのリソース使用率を向上させるため、ピニング・アルゴリズムが改良されました。
- インテル® MPIライブラリーは、MPI 標準に先駆けて、サポートされている GPU 上でデバイス開始 MPI-RMA 機能をサポートしました。
→ インテル® HPC ツールキットとインテルの AI ツールおよびフレームワークにより E-cores および P-cores 搭載インテル® Xeon® 6 プロセッサーのパワーを最大限に活用する方法を学ぶことができます。
信頼性、保守性、生産性
ソフトウェア・アプリケーションが扱う問題やアルゴリズムの複雑さは絶えず変化しており、SYCL、OpenCL、OpenMP などの言語による標準化されたマルチアーキテクチャー・コンピューティング・カーネル・オフロードの必要性だけでなく、生成されたコードを効率良く記述し、保守し、そして信頼性を確保することも求められています。
本リリースで LLVM ベースのコンパイラー・テクノロジーは、この点を改良しています。
インテル® oneAPI DPC++/C++ コンパイラーに導入された Ccache (英語) は、軽微な変更後のコードの再コンパイル時間を短縮し、ソフトウェア開発を加速します。以前のコンパイルをキャッシュして再利用することで、反復処理が高速化し、ワークフローが効率化されます。開発者は、ビルドに時間をかけずに、高品質のコードの作成に集中できます。
コマンドラインで使用する場合は、次のように、ccache ユーティリティー・プリプロセッサーへの呼び出しを追加するだけです。
$ ccache icx -c test.c
$ ccache icpx -fsycl -c sycl_test.cppCMake 環境では、-DCMAKE_CXX_COMPILER_LAUNCHER オプションを使用します。
$ cmake -DCMAKE_CXX_COMPILER=icpx -DCMAKE_CXX_COMPILER_LAUNCHER=ccache ..生産性を向上させ、製品リリースを迅速化するもう 1 つの方法は、製品リリース前のデバッグ回数や検証による遅れを減らすことです。これは、コード設計と実装の初期段階で潜在的な問題を検出することで実現できます。
サニタイザーは、コード内の望ましくない動作や未定義の動作を特定し、ピンポイントで検出するのに役立ちます。サニタイザーは、プログラムをインストルメントするコンパイラー・オプションで有効になり、バイナリーに安全チェックを提供します。サニタイザーを使用すると、開発プロセスの早い段階で効果的に問題を発見し、時間を節約し、製品レベルのコードでコストのかかるエラーが発生する可能性を軽減できます。
インテル® コンパイラーは、CPU および GPU をターゲットとするコード向けに、豊富なサニタイザーをサポートしています。
- Address Sanitizer – メモリーの安全性の問題を検出します。
- Undefined Behaviour Sanitizer – 未定義の動作を検出します。
- Memory Sanitizer – 初期化されていないメモリーの使用に関する問題を検出します。
- Thread Sanitizer – データ競合を検出します。
- Numerical Stability Sanitizer – 数値 (浮動小数点) に関する問題を検出します。
- Device-Side Address Sanitizer– SYCL デバイスコードのメモリーの安全性の問題を検出します。
- Device-Side Memory Sanitizer – 初期化されていないメモリーの使用に関する問題を検出します。
インテル® oneAPI DPC++/C++ コンパイラー 2025.1 リリースの新機能は以下のとおりです。
- C++ コード向けの Numerical Stability Sanitizer (数値安定性サニタイザー) の導入
- SYCL および OpenMP オフロード・デバイス・コード向けのメモリーおよびアドレス・サニタイザー・サポートの拡張 (無効なカーネル引数の検出、NULL ポインターの検出、OpenMP オフロードのプライベート・メモリー・サポートを含む)
OpenMP と同レベルのアドレス・サニタイザー・サポートが、インテル® Fortran コンパイラーにも追加されました。
- インテル® oneAPI DPC++/C++ コンパイラーは、すでに CPU でサポートしているメモリー・サニタイザーの機能を、GPU を含むデバイス側に拡張します。この拡張により、開発者は CPU とデバイスコードの両方で問題を簡単に検出してトラブルシューティングできるため、より信頼性が高いアプリケーションを実現できます。さらに、数値安定性サニタイザー (NSan) が追加され、浮動小数点演算に関連するコードの問題を迅速に特定して解決することで、アプリケーションの品質と安定性が向上します。
→ C/C++ コード向けの数値安定性サニタイザーは -fsanitize=numerical オプションで有効になります。
- インテル® Fortran コンパイラーは、CPU MemorySanitizer のサポートを GPU を含むデバイスに拡張しました。これにより、Fortran 開発者は CPU とデバイスコードの両方で問題を容易に検出し、トラブルシューティングできるため、アプリケーションの信頼性と堅牢性を高めることができます。
→ デバイスコードでこの機能を有効にするには、-Xarch_device -fsanitize=memory オプションを使用し、UR_ENABLE_LAYERS=UR_LAYER_MSAN ランタイム変数を設定します。ホストコードでメモリーアクセスの問題を特定するには、-Xarch_host -fsanitize=address オプションを使用します。
→ すべてのサニタイザー機能の詳細については、「インテル® oneAPI DPC++/C++ コンパイラーでサニタイザーを使用してバグを素早く検出」を参照してください。
- インテル® oneAPI DPC++/C++ コンパイラーのコード・カバレッジ・ツールには、C/C++、SYCL、OpenMP を使用するアプリケーション向けの GPU サポートと拡張 CPU カバレッジが追加されました。テスト済みおよび未テストのコード領域を識別する詳細な分析と包括的な HTML レポートが提供されるため、テストカバレッジとコード品質が向上し、ワークフローへの容易な統合が保証されます。
最新のオープン標準規格のサポート
最新の OpenMP および SYCL 機能による並列オフロードの効率性を利用できます。引数処理とリスト変数に関する最新の Fortran 23 機能により、コーディングの柔軟性が向上します。
- インテル® Fortran コンパイラーは、スレッド間で作業を効率良く分散する
WORKDISTRIBUTE構造と、ループネスト内のループ順序を変更するINTERCHANGE構造を導入することで、OpenMP 6.0 標準のサポートを拡張し、並列パフォーマンスとコード最適化を向上させます。 - インテル® Fortran コンパイラーは、
SYSTEM_CLOCK組込み関数の整数引数の種別の一貫性を確保し、PUBLIC NAMELISTグループにPRIVATE変数を含めることができるようにすることで、Fortran 23 のサポートを強化しました。これにより、Fortran 23 言語標準への準拠が向上し、コードの柔軟性が向上します。 - C++ with SYCL GPU カーネルは、インテル® oneAPI DPC++ ライブラリー (インテル® oneDPL) (英語)を使用することで、
copy、transform、order-changing、generation、およびset操作などのアルゴリズムの実行速度が最大 3 倍向上します。また、範囲ベースの C++20 標準アルゴリズムのcopy、transform、およびmergeをサポートしました。
→ インテル® Tiber™ AI クラウドでホストされている Jupyter Notebook で最新のソフトウェア開発ツールを無料で試して、可能性を探ってみてください。
ソフトウェア開発の生産性を高めましょう
すべてのツールの 2025.1 リリースは、以下からダウンロードできます。
- インテル® oneAPI ベース・ツールキット – オープン・アクセラレーテッド・コンピューティング向けのマルチアーキテクチャー対応の C++ および Python 開発ツール
- インテル® HPC ツールキット – クラスター全体でスケーリングする高速なアプリケーションを実現
- AI ツールセレクター (英語) – oneAPI により AI ワークロードでエンドツーエンドのパフォーマンスを実現
小さなダウンロード・パッケージも利用可能
ツールキット・セレクター (英語) を使用して、フルキットまたは特定のユースケースに必要なコンポーネントのみを含むより小さなサイズの新しいサブバンドルをインストールすることで、ソフトウェアのセットアップを効率化できます。インテル® C++ エッセンシャルズ、インテル® Fortan エッセンシャルズ、インテル® ディープラーニング・エッセンシャルズを利用して、時間を節約し、手間を減らし、プロジェクトに最適なツールを入手できます。
すぐに使える Jupyter Notebook
インテル® Tiber™ AI クラウド上の Jupyter Notebook で、新しいソフトウェア開発ツールを無料でお試しいただけます。
関連情報
製品ニュース
コード生成とコードの正当性
AI ワークロードのプロファイル
- インテル® Core™ Ultra プロセッサー上でインテル® VTune™ プロファイラーを使用して NPU 依存の AI PC アプリケーションを高速化する (英語)
- インテル® VTune™ プロファイラーを使用した GenAI LLM パフォーマンスの向上 (英語)
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。詳細については、http://www.intel.com/PerformanceIndex/ (英語) を参照してください。
インテル® ソフトウェア開発ツール 2025.1 対応 ! インテル® ソフトウェア開発ツール向けサポートサービス
エクセルソフトが提供するインテル® ソフトウェア開発ツール向けサポートサービスでは、インテル® ソフトウェア開発ツールの旧バージョンから新バージョンへの移行、CUDA から SYCL へのコード移行、他社製 GPU とのコード互換など、新しい環境でこれまで通り業務を遂行するための移行を支援します。製品の移行に関してお悩み、質問などお気軽にお問い合わせください。
最新のドキュメント日本語参考訳
エクセルソフトでは、バージョン 2025.1 に対応するドキュメントの日本語参考訳を一般公開しています。現在、以下のドキュメントに関する日本語参考訳をご参照いただけます。
- インテル® ソフトウェア開発ツールのリリースノート、動作環境 (ベース・ツールキット、ベース & HPC ツールキット)
- インテル® oneAPI DPC++/C++ コンパイラーのリリースノート、動作環境
- インテル® DPC++ 互換性ツールのリリースノート、動作環境
- インテル® Fortran コンパイラーのリリースノート、動作環境