

この記事は、インテルのウェブサイトで公開されている「Enhance the Performance of LLMs using Intel® VTune™ Profiler for High-Performance GenAI」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。
大規模言語モデル (LLM) は、多くの生成 AI (GenAI) アプリケーションの基本コンポーネントであり、そのようなワークロードの効率は、構成する LLM の効率に大きく依存します。インテル® VTune™ プロファイラーを使用すれば、高度に最適化された生成 AI アプリケーションの LLM のパフォーマンス・ボトルネックを解析して修正できます。パフォーマンス解析およびデバッグツールは、C/C++、SYCL、Python、JAVA、OpenVINO™、OpenCL など、複数のプログラミング言語とフレームワークをサポートしており、I/O パフォーマンス、ホットスポット、メモリーの割り当てと使用状況、HPC パフォーマンス特性など、ワークロードのさまざまな側面を検証できます。
パフォーマンスの問題を修正するため LLM を解析することは、次のようないくつかの要因により困難な作業です。
-
LLM の動的な振る舞い: LLM は、入力データに基づいて動的に応答し、同じ入力に対して異なる出力を生成する可能性があるため、さまざまなタスクにわたるパフォーマンスを予測することは困難です。
-
規模と複雑さ: LLM は、数十億ものパラメーターを含む可能性があり、パフォーマンス解析を複雑にします。
-
チューニングと最適化: さまざまなハイパーパラメーターのチューニングと最適化手法の影響を解析するには、専門知識と広範な実験が必要です。
-
バイアス、解釈可能性、環境変動: LLM は、トレーニング・データのバイアスを反映し、異なる環境で予測不可能な振る舞いをする可能性があります。特定のタスクでモデルが特定の動作をする理由を解釈することは、多くの場合、容易ではありません。
この記事では、最近「インテル® VTune™ プロファイラーのクックブック」に追加されたレシピについて解説します。このレシピは、インテル® ディストリビューションの OpenVINO™ ツールキット上に展開され、最新のインテル® Core™ Ultra 200V シリーズ (開発コード名 Lunar Lake) 上で実行される生成 AI アプリケーションの LLM パフォーマンスをプロファイルするため、インテル® VTune™ プロファイラーを活用する方法を紹介しています。
レシピの詳細は、「インテル® Core™ Ultra プロセッサー 200V シリーズでの大規模言語モデルのプロファイル」を参照してください。
前提条件と環境設定
このレシピでは、以下のハードウェアとソフトウェアを使用します。
-
生成 AI ソフトウェア: Phi-3 アプリケーション (英語) および Hugging Face phi-3-mini-4k-instruct LLM (英語)
-
パフォーマンス解析ツール: インテル® VTune™ プロファイラー 2025.0 以降
-
推論エンジン: インテル® ディストリビューションの OpenVINO™ ツールキット 2024.3 以降 (ダウンロード)
-
ハードウェア: インテル® Core™ Ultra 5 プロセッサー 238V
-
オペレーティング・システム: Microsoft Windows
環境設定には、OpenVINO™ ツールキットのソースコードのビルドと、LLM アプリケーションのビルドと実行が含まれます。
手順については、レシピの「環境の設定」セクションを参照してください。
インテル® VTune™ プロファイラーを使用した LLM パフォーマンスの解析
インテル® VTune™ プロファイラーの GPU オフロード解析機能を使用すると、CPU と GPU 上のコード実行を解析し、それらのアクティビティーを相関させることができます。例えば、GPU オフロード解析結果の [グラフィックス] ウィンドウには、さまざまな操作 (リソース割り当て、データ転送、タスク実行など) について、各計算タスクに費やされた合計時間に関する情報が表示されます。解析結果の [プラットフォーム] ウィンドウには、CPU に展開されたモデルと GPU に展開されたモデルが示されます。また、図 1 に示すように、GPU メモリーアクセス、CPU 時間、GPU 周波数など、さまざまなメトリックも表示されます。これらのメトリックを相関させることで、GPU リソースの使用状況を把握できます。
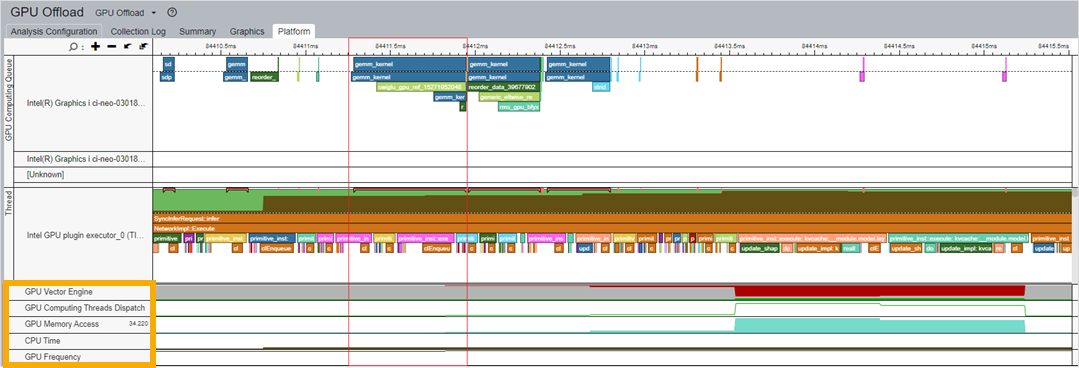
図 1: GPU オフロード解析
上記のメトリック間の相関関係から、CPU または GPU 上でカーネルごとに最も時間を費やしている操作 (ホットスポット) を特定できます。その後、GPU 計算/メディア・ホットスポット解析を実行することで、ホットスポットの挙動を詳細に把握できます。解析結果の [サマリー] ウィンドウでは、GPU や共有ローカルメモリーの読み取り/書き込み帯域幅など、メモリーレベルでの特定の帯域幅使用率を調べることができます。下の図 2 は、GPU メモリー読み取り操作に使用された帯域幅を示すヒストグラムの例です。
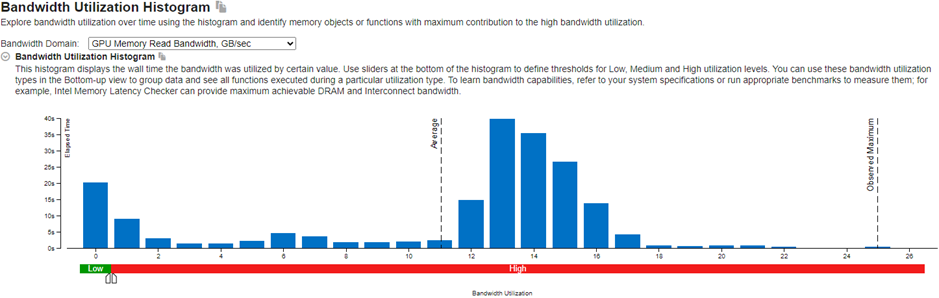
図 2: 帯域幅使用率ヒストグラム
インテル® VTune™ プロファイラーでは、メモリー階層ダイアグラムを使用して、メモリー依存のパフォーマンス問題を解析することもできます。[プラットフォーム] ウィンドウでは、GPU L3 キャッシュ帯域幅とキャッシュミス、GPU 周波数、GPU メモリーアクセスなど、さまざまなメトリックの傾向を確認できます。
OpenVINO™ ツールキットを用いた生成 AI 開発段階における LLM パフォーマンスの最適化
インテル® VTune™ プロファイラーは、インストルメンテーションおよびトレース・テクノロジー (ITT API) (英語) を利用して、OpenVINO™ ツールキットを用いた LLM 推論タスクの実行時間を解析します。レシピでは、インテル® VTune™ プロファイラーが生成 AI ワークロードの最適化に役立つ 4 つのシナリオについて説明しています。
-
最適化モデルのコンパイル: GPU 計算/メディア・ホットスポット解析結果から、推論ごとのコンパイル時間が分かります。OpenVINO™ ツールキットのモデルキャッシュ機能 (英語) を利用することで、モデルのコンパイルを高速化できます。
ov::Core core; core.set_property(ov::cache_dir("/path/to/cache/dir")); auto compiled = core.compile_model(modelPath, device, config);詳細は、「OpenVINO™ ツールキットのモデルキャッシュ機能」 (英語) を参照してください。
-
SDPA (Scaled Dot-Product Attention、スケーリングされたドット積アテンション) サブグラフの最適化: ニューラル・ネットワークにおいて「アテンション」とは、予測を行う際に入力データの特定の部分に動的に注目するモデルのメカニズムを指します。Transformer モデルでは、SDPA はアテンション・スコアを計算する基本メカニズムです。MHA (Multi-Head Attention) メカニズムは、複数のモデル・コンポーネントから SPDA 結果をキャプチャーすることで SPDA 機能を拡張します。
OpenVINO™ ツールキットは、SPDA 融合 (大きなグラフ内のサブグラフを結合してパフォーマンスを向上させるプロセス) 用の ScaledDotProductAttention 演算子 (英語) を提供しています。この演算子は、SPDA の推論時間を短縮し、メモリー依存の問題を軽減するのに役立ちます。また、MHA の並列処理とメモリー・アクセス・パターンの向上にも役立ちます。インテル® VTune™ プロファイラーを使用して、OpenVINO™ ツールキットを利用した最適化の前と後の推論時間とメモリー・ボトルネックを比較できます。
-
行列乗算 (MatMul) と Logits の最適化: LLM において「語彙サイズ」とは、モデルが認識できるトークンまたは一意の単語の数を指します。語彙サイズが大きければ、必要な MatMul 計算の数とメモリー使用量も大きくなります。レシピでは、別のグラフ最適化手法を適用することで、Logits (ニューラル・ネットワークの最後の層によって計算される非正規化スコア) の MatMul 計算とメモリー使用量を軽減する方法を示しています。インテル® VTune™ プロファイラーを使用して、パフォーマンスの向上と推論時間の短縮を解析できます。
-
KV キャッシュの最適化: LLMは、テキストを生成する際に、各入力トークンのキーと値 (KV) ペアを計算します。KV キャッシュ最適化は、過去のキーと値を保存することで、同じ KV を繰り返し計算することを防ぎます。OpenVINO™ ツールキットは、連続する 2 つの推論呼び出し間で KV キャッシュをモデルの内部状態として保存する Stateful API を提供します。これにより、推論時間とメモリーコピーのオーバーヘッドを大幅に削減できます。
次のステップ
インテル® VTune™ プロファイラーを使用して、最適化された生成 AI アプリケーションの LLM パフォーマンスを向上させる詳細な手順を説明したレシピを参照してください。今すぐインテル® VTune™ プロファイラーを使って、ワークロードにおけるさまざまなハードウェア・レベルおよびソフトウェア・レベルのパフォーマンス・ボトルネックを軽減または解決しましょう。
AI および HPC 向けのインテルのその他の oneAPI ツールキット もぜひチェックしてみてください。
ソフトウェアの入手
インテル® VTune™ プロファイラーは、インテル® oneAPI ベース・ツールキットの一部として、またはスタンドアロン版 (英語) としてインストールできます。
関連資料
- oneAPI プログラミング・モデル
- インテル® VTune™ プロファイラーのドキュメントとサンプルコード (英語)
- YouTube で公開されているインテル® VTune™ プロファイラーのトレーニング・ビデオ・シリーズ (英語)
- インテル® VTune™ プロファイラー・クックブック
- AI 開発を開始する (英語)
- 生成 AI デベロッパー・リソース (英語)
- トップ AI 開発者になろう (英語)
製品および性能に関する情報
1 性能は、使用状況、構成、その他の要因によって異なります。
インテル® VTune™ プロファイラー を含むインテル® ソフトウェア開発ツール向けサポートサービス
エクセルソフトが提供するインテル® ソフトウェア開発ツール向けサポートサービスでは、インテル® ソフトウェア開発ツールの旧バージョンから新バージョンへの移行、CUDA から SYCL へのコード移行、他社製 GPU とのコード互換など、新しい環境でこれまで通り業務を遂行するための移行を支援します。製品の移行に関してお悩み、質問などお気軽にお問い合わせください。
最新のドキュメント日本語参考訳
エクセルソフトでは、バージョン 2025.1 に対応するドキュメントの日本語参考訳を一般公開しています。現在、以下のドキュメントに関する日本語参考訳をご参照いただけます。
- インテル® ソフトウェア開発ツールの製品カタログ
- インテル® ソフトウェア開発ツールのリリースノート、動作環境 (ベース・ツールキット、ベース & HPC ツールキット)
- インテル® oneAPI DPC++/C++ コンパイラーのリリースノート、動作環境
- インテル® DPC++ 互換性ツールのリリースノート、動作環境
- インテル® Fortran コンパイラーのリリースノート、動作環境
6/26 (木) AI ソフトウェア開発者向けイベント「AI DEVELOPER TECH DAY」参加登録受付中
このイベントでは、インテル ソフトウェア開発ツールや代表的なオープンソース・フレームワークを利用して、インテルのデータセンター向け CPU、GPU、AI アクセラレーターや AI PC 上で、大規模言語モデル (LLM) を含む生成 AI を活用した AI ソフトウェアを効率よく開発および最適化するための手法について紹介します。