

この記事は、インテル® コミュニティーのブログに公開されている「AI Data Processing: Near-Memory Compute for Energy-Efficient Systems」の日本語参考訳です。原文は更新される可能性があります。原文と翻訳文の内容が異なる場合は原文を優先してください。

今日のシステムは、ほぼ例外なく、限られたシステムレベルの電力バジェットの中で動作させる必要があります。このような電力制約のあるシステムでは、システム内のあらゆる場所でエネルギーを節約することで、より多くのエネルギーを計算に充てることができ、結果としてシステムの性能を向上させることができます。システム内でデータを移動させると、演算に直接的に寄与しないエネルギーが消費されます。メモリーとプロセッシング間のデータの移動を可能な限り短くすることで、システムエネルギーの節約を実現します。エネルギー節約は、メモリー周辺コンピューティングのノーススター指標として、第一の目標であるべきです。
先日の国際固体回路会議 (ISSCC) で、「We have rethought our commute; Can we rethink our data’s commute?」というタイトルのプレゼンテーションを行いました。ここでは、ニアメモリー・コンピュート (NMC) の研究者がよくとるメモリーデバイス+小型計算カーネルという視点ではなく、システムレベルの視点での発表を行いました。この観点から、なぜ今、NMC をシステムに採用するのか、またシステムレベルで乗り越えるべき障壁について説明しました。
問題点は?
コンピューティングの誕生以来、いくつかのメモリー技術は大容量化を目指している中、ほかのメモリー技術は高性能化を目指して利用されてきました。今日のシステムで使われているメモリーとストレージの階層は、ピラミッドで表されています (図 1 参照)。この階層は、さまざまなメモリー技術の基本的な特性、すなわち容量あたりの帯域幅を変えることでビットあたりのコストが異なるように設計されていることを利用したものです。
ピラミッドの頂点に位置するメモリーは、容量あたりのスループットが高く、レイテンシーも低いのですが、容量あたりのコストが割高になります。階層が下に行くほど、システムはレイテンシーの桁外れの増加に対応し、合理的なコストで大容量を提供します。しかし、その結果、ビット・アクセスあたりのエネルギーが著しく増加します。このエネルギー増加は、メモリー技術と、メモリーからプロセッシング・ユニットへのデータ移動の両方が原因です (注:データ移動エネルギーはシステムスコープによって大きく異なるため、記載されているエネルギーはメモリーデバイスのエネルギーです)。
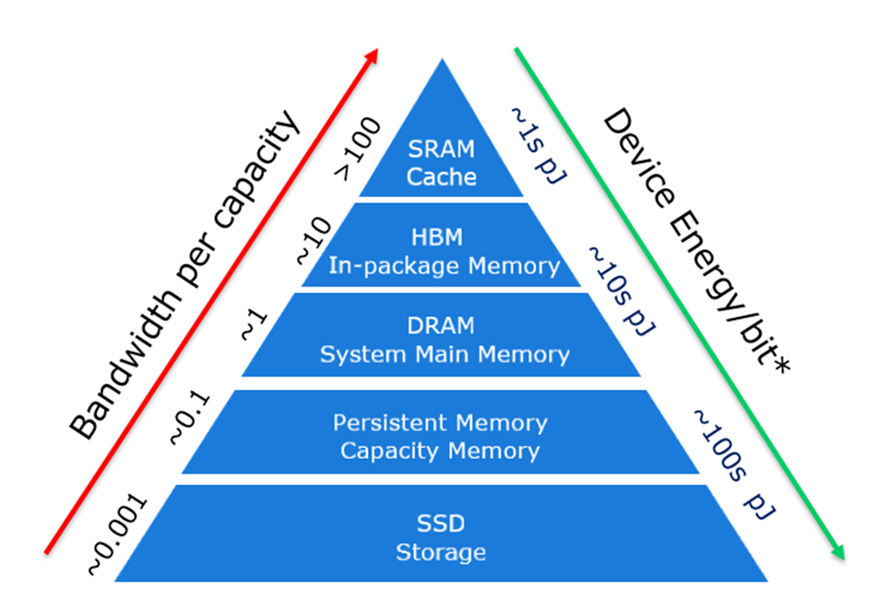
図 1: メモリー/ストレージの階層構造
Intel & Shen, Meng, “Silicon Photonics for Extreme Scale Systems”, Journal of Lightwave Technology, 2019
データセットがメモリー密度を上回るペースで増加し続ける中、システムレベルのデータ移動に費やされるエネルギーは増大しています。AI データ処理におけるディープラーニング (DL) データセットは特にその顕著な例で、モデル・パラメーターのサイズは GPU や CPU のローカル高帯域幅メモリーを超えて、ほかの階層にまで拡大する傾向にあります。このようなデータの流れは、さまざまな階層から計算エンジンへ、そしてその逆へと、計算から失われるシステムエネルギーの源となります。
アプローチの対象
Near Memory Compute (NMC または CNM)、Near Memory Processing (NMP または PNM)、Processing in Memory (PiM) など、多くの略語が、選択したコンピュートからメモリーへの移行を示すのに使用されています。このブログでは、システムレベルのアプローチで、これらの用語をすべて NMC に集約し、CPU や GPU よりも物理的にメモリーに近い場所にある、単純なものからより複雑なものまでのコンピュートという概念で説明しています。NMC では、システムレベルで 3 つの重要な位置の区別があります。「プロセッサーと一緒」というシステム位置は、データ移動のエネルギーが節約されないことを意味するため、ここでは、触れないこととします。また、「メモリー内」は、より高価な新しいメモリーを意味するため、メモリー設計者に一任することにします。
NMC は、メモリー・コントローラーをシステムレベルでメモリーと一緒に格納し、なおかつロジックプロセスで構築するという、その中間の妥協点から始まるというのが我々の予測です。この NMC は、現在のシステムよりも低い消費電力と高い帯域幅で、メモリー常駐型データへのアクセスを提供し、すでにスケールアップしているメモリーの経済性に挑戦する必要性を排除するものです。NMC は、CXL メモリーモジュール、メモリー/ストレージ・ファブリック・スイッチ、または SSD にコンピュート機能を搭載することが可能です。
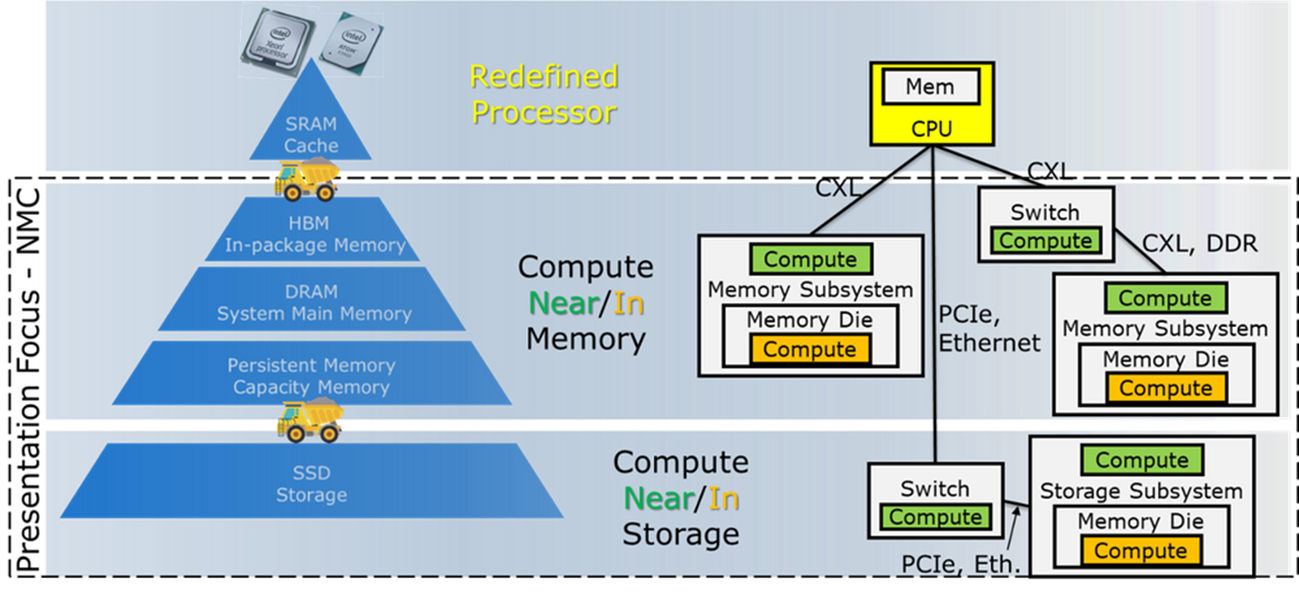
図 2: NMC のためのアプローチの連続性 (緑色でハイライト表示)
なぜ今なのか?
NMC は 1960 年代から研究されていますが、現在の私たちの大規模な商用システムでは使われていません。私たちが自問自答しなければならないのは、「何が変わったのか」ということです。何が変わったこ図 2: NMC のためのアプローチの連続性 (緑色でハイライト表示)
とで NMC の採用が現実的になったのでしょうか。
NMC にとって「今がそのときかもしれない」理由は 3 つあります。
まず、デンナー・スケーリングの鈍化により、デバイスレベルでの電力削減が制限されていることです。トランジスターをスケーリングしても、もはや従来のような電力削減の効果は得られません。このように、これまで重要な役割を果たしてきたデバイスレベルでの電力削減ができなくなると、システムの革新にエネルギー削減のバトンを渡さなければなりません。
第 2 に、異なる計算エンジン (CPU と GPU、あるいは CPU とアクセラレーターなど) が協調して問題をより効率的に解決するコンピューティング・モデルが普及してきました。このようなシステムレベルのヘテロジニアス・コンピューティングを迅速に導入し、高水準言語 (ライブラリー、ランタイム、コンパイラーによって完全に駆動されるためプログラマーには見えない) からそのようなアーキテクチャーをプログラムできるようにすることが、NMC が成功するためには不可欠となります。
今日では、CPU だけでなく、CPU と GPU のヘテロジニアスなシステムで実行するために、高水準言語が使用されています。AI 分野では、プログラマーは PyTorch や TensorFlow、あるいはそれに近い抽象化レベルでコードを書くことが多くあります。インテルは、ヘテロジニアス・コンピューティングを可能にする oneAPI オープンソース・プログラミング・モデルを継続的に改良しています。このようなプログラミング・モデルは、NMC のコンピュート・エージェントにも拡張できる可能性があります。
第 3 に、インテルが開拓し、現在業界全体のコンソーシアムが主導している新しいメモリー・インターコネクトである CXL の導入は、ニアメモリー・コンピュートへの道筋を提供するものです。現在、私たちは DRAM を DDR インターフェイスでシステムに接続していますが、このインターフェイスでは、データが一定のナノ秒の時間内に到着することが要求されます。CXL は可変遅延メモリーアクセスを可能にし、NMC がデータにアクセスする時間、おそらく複数のデータ要素にアクセスし、答えを返す前に計算を完了する時間を確保できる可能性があります。CXL モジュールには、CXL リンクとメモリーを接続し、エラー訂正を行うメモリー・コントローラーが論理プロセスで組み込まれています。これは NMC を導入する明らかな場所です。
システム統合の壁は高い
メモリー階層は、システムレベルで数十年にわたり進化してきました。性能向上のためのインターリーブ、信頼性のためのエラー訂正、セキュリティーのための暗号化などが含まれます。たとえば、計算に必要なすべてのデータが 1 つのメモリー・コンポーネントに存在したり、そこに存在するデータがエラー訂正されていると仮定することは現実的ではありません。
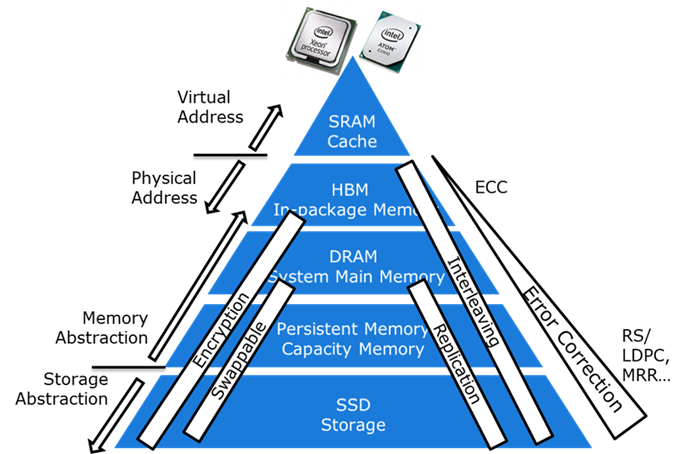
図 3: システムレベル設計
図 3 に示すように、NMC の成功は、これらの要素をすべて考慮したシステム設計によって実現されます。
NMC アプローチのためのスコアカード
NMC の最初のハードルは、消費電力、性能、コストにおいて本当に大きな利点があるかということであり、NMC に内在するシステムレベルの大幅な作業分割の変更を動機付けるに十分な利点です。
NMC が有用であるためには、システムのほかの部分と調和する形でシステムに統合されなければなりません。開発者の利便性は必須です。約束されたシステムレベルの大きな利点に到達するために、アプリケーション・コードの変更は必要ないはずです。ソフトウェア・インフラストラクチャーの変更は許されます。実際、NMC が存在するシステムではアプリケーションが NMC を活用し、存在しないシステムでは効果的に実行できるようなソフトウェア・インフラストラクチャーが必要であると思われます。
オフロードエンジン自体は、多くの NMC の提案にあるハードウェアのタイムラインではなく、ソフトウェアのタイムラインで動作するアルゴリズムの変更に対応できる柔軟性を備えていなければなりません。特に AI 分野では、アルゴリズムの急速な革新により、性能が急速に向上し続けており、NMC の設計を成功させるためには、これらを受け入れなければなりません。
そしてもちろん、どのようなソリューションであっても、すでに述べたようにシステムにきれいに統合され、大規模なシステムに拡張する道筋を提供しなければなりません。最後に、コストは許容範囲内でなければなりません。新しいメモリーダイが、少量生産であっても容量あたりのコストが同じであると仮定することは現実的ではありません。
新しい NMC 技術を研究するとき、あるいは他社の NMC 技術を検討するときは、図 4 のスコアカードを通じて、その技術が実際のシステムレベルの展開にどの程度適しているかを判断してください。

省エネルギーがニアメモリー・コンピューティングを推進する
ニアメモリー・コンピュートの研究には長い歴史がありますが、実際のシステムにはほとんど影響を与えていません。システムのエネルギー・オーバーヘッドを削減することが、データセンターのコストを抑え、世界のエネルギー消費に対応する強力なシステム設計の中心になるにつれ、NMC はその足場を固めることとなるでしょう。プログラマー・フレンドリーかつホリスティックな方法で作成された NMC システム・インテグレーションは、急速に発展する AI 分野での応用が期待されます。私たちは今、フォン・ノイマン氏のルーツからさらに進んだ、コンピュート・ニア・メモリー・ソリューションの競争市場を先導するコンピューター・アーキテクチャーの新たなルネッサンスを迎えようとしているのかもしれません。