概要
すべてのアプリケーションに万能なスレッド化ソリューションはありません。これと同じように、インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) を使用してアプリケーションをビルドし、マルチスレッドを実行する方法もさまざまです。スレッド化は低レベルのプリミティブ (インテル® IPP ライブラリー内) や高レベルのオペレーティング・システムに実装できます。ここでは、インテル® IPP を利用したアプリケーションで安全にマルチスレッド実行の利点を活かす方法を説明します。
この記事は、「マルチスレッド・アプリケーションの開発のためのインテル・ガイド」の一部で、インテル® プラットフォーム向けにマルチスレッド・アプリケーションを効率的に開発するための手法について説明します。
はじめに
インテル® IPP は、デジタルメディアやデータ処理アプリケーション向けに高度に最適化されています。このライブラリーには、信号処理、画像、オーディーオ、ビデオエンコード/デコード、データ圧縮、ストリング処理、暗号化など、各種分野の基本的なアルゴリズムでよく使用される最適化関数が含まれています。ライブラリーは、広範囲に SIMD (Single Instruction Multiple Data) 命令や SSE (ストリーミング SIMD 拡張命令) 、および現在のインテル® プロセッサーで利用可能なハードウェア・マルチスレッドを活用します。最近のプロセッサーで見受けられる SSE 命令の多くは、DSP (デジタル・シグナル・プロセッサー) にならったもので、データの配列やベクトルを処理するアルゴリズムを最適化するのに理想的です。
インテル® IPP ライブラリーは、Windows*、Linux*、Mac OS* X、QNX*、VxWorks* オペレーティング・システム向けにビルドされたアプリケーションに使用できます。また、インテル® C/Fortran コンパイラーや、Microsoft* Visual Studio* C/C++ コンパイラー、最新の Linux ディストリビューションに含まれている gcc コンパイラーと互換性があります。さらに、インテル® Core™ プロセッサーおよびインテル® Atom™ プロセッサーを含む、複数の世代のインテル®プロセッサーや互換 AMD プロセッサーとの動作も確認されています。32 ビットと 64 ビットの両オペレーティング・システムおよびアーキテクチャーに対応しています。
序説
インテル® IPP ライブラリーは、マルチスレッド化を実現するための各種手法を取り入れて構築されています。スレッドセーフな設計で、1 つのアプリケーション内で複数のスレッドからライブラリー関数を安全に呼び出すことができます。既存のアプリケーションを記述し直してマルチスレッド・アプリケーションを作成しなくても、インテルの OpenMP* ライブラリーを通じて、マルチスレッドが組み込まれたライブラリーにより、すぐさまパフォーマンスを向上させることができます。
インテル® IPP のプリミティブ (インテル® IPP ライブラリーの基礎を成す低レベルの関数) は、データのベクトルと配列で、繰り返し演算が行われるよう設計されたアルゴリズム要素のコレクションで、マルチスレッド・アプリケーションの実装に理想的な条件です。プリミティブは、下層のオペレーティング・システムから独立しており、ロック、セマフォー、グローバル変数を使用しません。また、一時およびステートメモリー格納には C 言語の標準ライブラリーのメモリー割り当てルーチン (malloc/realloc/calloc/free) のみを利用します。外部システム関数との依存関係をさらに排除するため、i_malloc インターフェイスを使用して、C 言語の標準ライブラリーの代わりに独自のメモリー割り当てルーチンを使用することもできます。
低レベルのアルゴリズム的プリミティブのほか、インテル® IPP ライブラリーには画像、メディア、音声コーデック (エンコーダー/デコーダー)、データ圧縮ライブラリー、ストリング処理関数、暗号化を実装する、業界標準の高レベルなアプリケーションとツールが含まれています。このようなツールの多くで、複数のハードウェア・スレッド間で処理を分散できるよう複数のスレッドが使用されます。
インテル® IPP ライブラリーは、大量の数値計算を行うアルゴリズムの要件を満たすように設計された関数セットを通じて、SIMD 命令 (MMX、SSE など) に簡単にアクセスできるため、シングルスレッド・アプリケーションでもパフォーマンスを大幅に向上させることができます。
図 1 は、MMX/SSE 命令の恩恵を受けずに実装された関数と、インテル® IPP 製品の各種ドメインで測定された性能向上の相対的な平均値です。(実際の性能は異なることがありますのでご注意ください。)
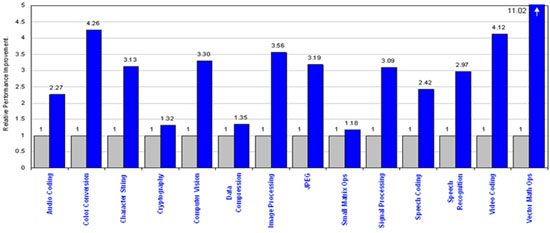
図 1. 各種インテル® IPP 製品ドメインの相対的なパフォーマンス向上
システム構成: クアッドコア インテル® Xeon® プロセッサー、2.8GHz、2GB: Windows* XP、インテル® IPP 6.0 ライブラリーを使用
アドバイス
インテル® IPP ライブラリーで複数のハードウェア・スレッドを活用するには、ライブラリーのマルチスレッド・バリアントを使用するか、あるいはライブラリー付属のスレッド化されたサンプル・アプリケーションを使用するのが最も早く簡単な方法でしょう。大幅にコードを変更しなくても、単にインテル® IPP を使用するよりも優れたパフォーマンスが得られます。
ライブラリー (バージョン 6.1) の基本バリアントには、シングルスレッドのスタティック・ライブラリー、マルチスレッドのスタティック・ライブラリー、マルチスレッドのダイナミック・ライブラリーの 3 つがあります。3 つのバリアントはすべてスレッドセーフです。シングルスレッドのスタティック・ライブラリーは、カーネルモードのアプリケーションか、または OpenMP ライブラリーが受け付けられない、あるいはサポートされてない場合 (リアルタイム・オペレーティング・システムで使用される場合など) に使用します。
2 つの選択肢: OpenMP によるスレッド化とインテル® IPP
インテル® IPP の低レベルのプリミティブは基本的なアトミック演算であり、活用できる並列化をライブラリー関数の約 15% に制限します。インテルの OpenMP ライブラリーは、この「裏側」の並列化を実装するために利用され、マルチスレッドのライブラリーが使用されるときにはデフォルトで有効になります。
マルチスレッド・プリミティブのリストは、インテル® IPP のドキュメント・ディレクトリーの ThreadedFunctionsList.txt ファイルに記載されています。
注: インテル® IPP ライブラリーはインテル®C コンパイラーと OpenMP を使用して構築されていますが、これらのツールを使ってアプリケーションをビルドしなければならないわけではありません。インテル® IPP ライブラリーのプリミティブは関連するオペレーティング・システム (OS) プラットフォーム用の C コンパイラーと互換性のあるバイナリー形式で提供されており、アプリケーションへのリンク準備ができています。つまり、インテル® IPP を使用するアプリケーションは、インテルのツールでも、またその他の開発ツールでもビルドが可能です。
インテル® IPP プリミティブの OpenMP によるスレッド化の制御
スレッド化されたインテル® IPP プリミティブで使用される OpenMP スレッドのデフォルトの数は、システムのハードウェア・スレッドの数と同じで、プロセッサーの数と種類によって決まります。例えば、インテル® ハイパースレッディング・テクノロジー (インテル® HT テクノロジー) 対応のクアッドコア・プロセッサーの場合、8 つのハードウェア・スレッド (4 コアがそれぞれ 2 つのスレッドをサポート) があります。インテル®HT テクノロジーが搭載されていないデュアルコア・プロセッサーの場合は、2 つのハードウェア・スレッドがあります。
2 つのインテル® IPP プリミティブ、ippSetNumThreads() と ippGetNumThreads() は、インテル® IPP ライブラリーのマルチスレッド・バリアントの OpenMP によるスレッド化についてユニバーサルな制御とステータスを提供します。ippGetNumThreads を呼び出して、現時点のスレッドキャップを特定し、ippSetNumThreads を使用してそのスレッドキャップを変更します。ippSetNumThreads では、利用可能なハードウェア・スレッド数を超える数のスレッドキャップは設定できません。このスレッドキャップは、マルチスレッド・プリミティブで使用できる OpenMP のソフトウェア・スレッドの上限数を設定する役目を果たします。一部のインテル® IPP 関数で最適な並列効率性を得るためにスレッドキャップで指定されたスレッド数よりも少ない数のスレッドが使用されることはありますが、スレッドキャップで許容された数を超える数のスレッドが使用されることはありません。
インテル® IPP ライブラリーのスレッド化バリアントにある OpenMP を無効にするには、アプリケーションの冒頭で ippSetNumThreads(1) を呼び出すか、あるいはアプリケーションをインテル® IPP のシングルスレッドのスタティック・ライブラリーにリンクします。
OpenMP ライブラリーは、いくつかの構成環境変数を参照します。OMP_NUM_THREADS は実行時に OpenMP ライブラリーで使用されるデフォルトのスレッド数 (スレッドキャップ) を設定します。ただし、インテル® IPP ライブラリーはアプリケーションで使用される OpenMP のスレッド数を、前述したようにシステムのハードウェア・スレッド数か、あるいは ippSetNumThreads への呼び出しで指定された値のいずれかに制限することで、この設定を無効にします。インテル® IPP ライブラリーを使用しない OpenMP アプリケーションも OMP_NUM_THREADS 環境変数に影響を受けますが、インテル® IPP アプリケーションの ippSetNumThreads への呼び出しには影響を受けません。
入れ子の OpenMP
インテル® IPP アプリケーションで OpenMP によるマルチスレッド化も実装されている場合には、そのアプリケーションで呼び出されるスレッド化されたインテル® IPP プリミティブは、シングルスレッドのプリミティブとして実行されることがあります。これは、インテル® IPP プリミティブが OpenMP の並列化コードセクションで呼び出され、またインテルの OpenMP ライブラリーで入れ子の並列化が無効 (デフォルト) の場合に発生します。
OpenMP の並列領域の入れ子は、利用可能なハードウェア・スレッド数のオーバーサブスクリプションを引き起こす多数のスレッドを作成する恐れがあります。並列領域の作成にはオーバーヘッドが付き物です。OpenMP の並列領域の入れ子によるオーバーヘッドが得られる利点よりも上回ることもあります。一般に、インテル® IPP プリミティブが使用される OpenMP のスレッド化アプリケーションでは、ippSetNumThreads(1) を呼び出すか、またはインテル® IPP のシングルスレッドのスタティック・ライブラリーを使用するかして、インテル® IPP ライブラリー内のマルチスレッド化を無効にします。
コア・アフィニティー
信号処理ドメインのインテル® IPP プリミティブの中には、マージされた L2 キャッシュを活用する並列スレッドを実行するよう設計されたものがあります。このような関数 (単精度/倍精度 FFT、Div、Sqrt など) の場合、マルチスレッド・パフォーマンスを最大限に引き出すために共有キャッシュが必要です。つまり、このようなプリミティブのスレッドは、共有キャッシュを持つシングルダイの複数のコア上で実行されなければなりません。この条件が確実に満たされるよう、次の OpenMP 環境変数をインテル® IPP ライブラリーが実行される前に設定します。
KMP_AFFINITY=compact
シングルダイに複数のコアが搭載されているプロセッサーでは、この条件は自動的に満たされるため環境変数は不要です。ただし、複数のダイが搭載されたシステム (インテル®Pentium® D プロセッサーやマルチソケットのマザーボードなど) でキャッシュが共有されない場合、この OpenMP 環境変数が設定されていないと、このクラスのマルチスレッドのインテル® IPP プリミティブで大幅なパフォーマンス低下を招くことがあります。
利用ガイド
インテル® IPP アプリケーションのスレッド化
インテル® IPP ライブラリーには、インテル® IPP プリミティブを使用したマルチスレッドのアプリケーション・サンプルが多数用意されています。サンプルのすべてにソースコードが含まれています。アプリケーション・レベルでスレッド化を実装するサンプルや、インテル® IPP ライブラリーにビルトインされているスレッド化を利用するサンプルもあります。ほとんどの場合、マルチスレッド化によって大きなパフォーマンス・ゲインがもたらされます。
マルチスレッド・アプリケーションでプリミティブを使用する場合は、前のセクションで説明した手法を用いて、インテル® IPP ライブラリーのビルトインのスレッド化を無効にすることをお勧めします。こうすることで、ライブラリーのビルトインのスレッド化とアプリケーションのスレッド化メカニズムの競合がなくなり、利用可能なハードウェア・スレッドに対してソフトウェア・スレッドがオーバーサブスクリプションを引き起こすのを防ぎます。
インテル® IPP ライブラリーは、ベクトル演算に適したプロセッサーの SIMD 命令を有効利用します。そのため、大半のライブラリー・プリミティブでデータ配列における演算に重点が置かれています。スレッド化は、大部分が独立している複数のデータ要素での演算に適しています。ライブラリーによるスレッド化では、データ分解を使用するか、またはデータブロックを小さなブロックに分割して、同一の並列スレッドを複数実行してそのブロックを処理する方法が一般に最も簡単です。
メモリーとキャッシュのアライメント
大きなデータブロックを処理する際、アライメントが適切でないとスループットが低下します。インテル®IPP ライブラリーには、メモリーの割り当てとアライメントを行う関数セットが含まれており、この問題に対応します。さらに、たいていのコンパイラーは、バス効率の良いデータアライメントになるよう構造体をパディングするよう設定されています。
並列スレッドを実装する際、キャッシュラインに対するキャッシュ・アライメントとデータ間隔は非常に重要です。特に、インテル® IPP プリミティブをループする構造体が含まれた並列スレッドでは重要です。複数の並列スレッドの操作で同時あるいは共有データ構造が頻繁に利用される場合、あるスレッドの書き込み操作は「隣接した」スレッドのデータ構造に関連するキャッシュラインを無効にすることがあります。
同一のインテル® IPP の操作 (データ分解) の並列スレッドをビルドする際には、並列スレッドで処理される分解されたデータブロックの相対間隔と、その並列スレッド内のプリミティブが使用する制御データ構造の間隔を検討してください。インテル® IPP 関数の各反復で更新される状態を制御構造が保存する場合には特に注意が必要です。このような制御構造でキャッシュラインが共有されている場合には、更新処理によって近隣の構造が無効になることがあります。
この場合、プロセッサーのキャッシュ・ライン・サイズ (通常は 64 バイト) を複数占有するよう制御データ構造を割り当てるのが一番簡単な解決方法でしょう。また、コンパイラーのアライメント操作を使用して、常にキャッシュラインの境界でこのような構造や構造配列がアライメントされるようにすることもできます。制御構造をパディングするために使用されたバイトは、プリミティブの反復でキャッシュラインの更新に必要とされる、失ったバスサイクルを補います。
DMIP によるパイプライン処理
SIMD 命令、ハードウェア・スレッド数、高速キャッシュサイズの利用を最適化するためには、実行時にアプリケーションで対応することが理想的です。このような重要なリソースを最適に使用することで、ほぼ完璧に近い並列操作が達成される可能性があり、これはインテル® IPP の DMIP ライブラリーの最重要目標とされているものです。
DMIP による並列化の手法 (キャッシュに適したサイズのデータブロックで実行されるインテル® IPP プリミティブの並列シーケンスをビルドする) は、各関数呼び出しでデータセット全体を逐次処理していた部分から、アプリケーションのパフォーマンス・ゲインを引き出します。
例えば、画像全体を処理するのではなく、画像をキャッシュ可能なセグメントに分割し、キャッシュ中にある間、各セグメントで複数の処理を実行します。処理シーケンスは計算パイプラインで、データセット全体が処理されるまで、各タイルに適用されます。その後、並列で実行する複数のパイプラインをビルドし、パフォーマンスの向上を図ります。
この方法についての詳細な説明は、「A Landmark in Image Processing: DMIP」(英語) を参照してください。
スレッド化によるパフォーマンス効果
インテル®IPP に含まれているその他の高レベルのスレッド化ライブラリー・ツールをマルチコア環境で使用すると、パフォーマンスの大幅な向上を実現することができます。例えば、インテル® IPP のデータ圧縮ライブラリーは、よく使用されるデータ可逆圧縮ライブラリー、ZLIB、BZIP2、GZIP、LZO とのドロップイン互換が確保されています。インテル® IPP の BZIP2 ライブラリーや GZIP ライブラリーでは、ネイティブスレッドを使用して、並列で圧縮できるように大きなファイルを複数のブロックに分けるか、あるいは個別のスレッドで複数のファイルを処理することにより、マルチスレッド環境を有効利用します。この手法を用いると、クアッドコア・プロセッサーでインテル® IPP を使用していないシングルスレッドの実装と比べ、GZIP ライブラリーで 10 倍ものパフォーマンス・ゲインの達成が可能になります。
マルチメディアの分野 (ビデオ、画像処理) では、インテル® IPP の H.264、VC 1 デコーディングにより、ビデオフレームのデコーディング処理、再構成処理、デブロッキング処理を複数のネイティブスレッドを使用して並列化することで、理論上のほぼ限界の性能向上までスケーリングを実現できます。インテル® IPP で強化された H.264 デコーダーをクアッドコア・プロセッサーで実行すると、HD ビットストリームで 3 倍から 4 倍のパフォーマンス・ゲインがもたらされます。
最後に
すべての状況において最高のパフォーマンスが保証される万能な方法はありません。スレッド化やインテル® IPP ライブラリーを使用して達成されるパフォーマンスの向上は、アプリケーションの性質 (スレッド化をどの程度簡単に行えるか) や使用できるインテル® IPP プリミティブの組み合わせ (スレッド化バージョン/スレッド化されていないバージョン、使用頻度など)、ハードウェア・プラットフォーム (コア数、メモリー帯域幅、キャッシュサイズや種類など) により異なります。