インテル® ソフトウェア開発ツール購入者限定サイトのご案内: インテル® ソフトウェア開発ツール/有償サポート製品を購入いただき、有効なサポートをお持ちの方を対象に、米国インテル社によるプログラミング・ガイドや技術ウェビナーの日本語訳、弊社で開催したセミナーやイベントのアーカイブなどを順次掲載しています。
概要
インテル® ソフトウェア開発ツールとは?

現在のデータセントリックなワークロードを効率良く処理させるためには、GPU や FPGA など演算アクセラレーターを用いることが一般的になっています。
インテル® ソフトウェア開発ツールは、Unified Acceleration (UXL) Foundation が管理する、アクセラレーター向け統合プログラミング・モデルのオープン仕様 oneAPI に基づいて、インテルが提供する現在と将来の CPU、GPU、FPGA のそれぞれに最大限のパフォーマンスを発揮させるための包括的なプログラミング手段を提供します。
C++ 言語と SYCL* および対応ライブラリーによって新しいコードを直接プログラミングできるのみならず、Fortran、C/C++、OpenMP*、MPI、Python* といった既存の標準的な手段やツールによるコードを引き続き利用して、Windows* および Linux* の各 OS 向けに高性能なアプリケーションを開発できます。
「インテル® oneAPI ベース・ツールキット」には、oneAPI に基づいて、単一のコードで複数種類のアクセラレーターに対応できる SYCL* と C++ のコンパイラー、oneAPI ライブラリー、CUDA* から SYCL* へのコード移行ツール、およびインテルのアーキテクチャーにおける性能解析ツールなどが含まれます。
詳細・新機能 技術情報インテル® oneAPI ベース・ツールキットの他にも、開発用途に応じて異なる構成のツールキットをご利用いただけます。
| インテル® oneAPI ベース・ツールキット | データ並列 C++ コンパイラーとパフォーマンス・ライブラリー |
| インテル® oneAPI ベース & HPC ツールキット | ベース・ツールキットに同梱されるツール + Fortran コンパイラーおよび MPI 開発ツール |
製品種類
ライセンス
開発者数サポート、ノード数サポートが提供されています。
ライセンス規定の詳細はライセンスページを参照ください。
開発者数サポート
64 ノード以下の開発システムに対して、購入ライセンスで指定される数のユーザーを含む開発チームに製品を使用する許可を与えます。
ノード数サポート
65 ノード以上の開発システムを利用するすべてのユーザーに製品を使用する許可を与えます。
ツールキット
お客様の用途に応じて、サポートが必要なツールキットの範囲をお選びいただけます。
インテル® oneAPI ベース・ツールキット
データ並列 C++ コンパイラーとパフォーマンス・ライブラリー
1 つのプログラミング・モデルで複数のアーキテクチャー (CPU、GPU、FPGA) にわたって高いパフォーマンスを発揮できるコードの開発を支援します。
インテル® oneAPI ベース & HPC ツールキット
ベース・ツールキット + Fortran コンパイラー & MPI 開発ツール
Fortran コンパイラーと MPI 開発ツールにより、CPU およびアクセラレーターまたはそれらのクラスターへ最適化された HPC アプリケーションの開発を支援します。
インテル® Fortran コンパイラー向けサポートサービス
インテル® Fortran コンパイラーと対応ライブラリーのみ
Fortran のソースコードを現代化し、CPU およびアクセラレーターへ最適化された HPC アプリケーションの開発を支援します。
インテル® oneAPI ベース & HPC ツールキットでは、ターゲット・プラットフォームのメモリーシステムの種類により、シングルノードとマルチノードの 2 つの製品が提供されます。
- シングルノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムのターゲット・プラットフォーム向け
- マルチノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムに加え、HPC クラスターを含む分散メモリーシステムのターゲット・プラットフォーム向け
アプリケーションを作成してクラスターシステムなどの分散メモリーシステムで実行する場合は、シングルノードではなく、マルチノードをご利用ください。
一覧
| 製品 | ツールキット | ライセンス |
|---|---|---|
| インテル® ソフトウェア開発ツール | インテル® oneAPI ベース・ツールキット | 特 / 開 |
| インテル® oneAPI ベース & HPC ツールキット | 特 / 開 / ノ / サ | |
| インテル® Fortran コンパイラー向けサポートサービス | 特 / 開 |
- 特: 特定ユーザーライセンス、開: 開発者サイズライセンス、ノ: ノードライセンス、サ: サイトライセンス
- インテル® oneAPI ベース・ツールキットおよびインテル® oneAPI ベース & HPC ツールキットには、対応 OS およびプログラミング言語による製品分類はありません。各ツールキットおよびそのコンポーネントごとでサポートされるすべての OS とプログラミング言語を利用できます。
ベンチマーク
推論およびトレーニングにおけるパフォーマンスの向上
インテル® ソフトウェア開発ツールによる MLPerf™ DeepCAM のベンチマークのテスト結果は、HPC データセンターにおいて、気候データからハリケーンや大気の川を検出する際に一般的に使用されます。
ディープラーニングにおける推論とトレーニングの向上
インテル® アドバンスト・マトリクス・エクステンション (インテル® AMX) によるハードウェア・アクセラレーションと、int8 (推論) および bfloat16 (トレーニング/推論) データ型のサポートにより、前世代のインテル® Xeon® スケーラブル・プロセッサーと比較して、AI およびディープラーニングの推論とトレーニングのワークロードのパフォーマンスが大幅に向上します。第 4 世代インテル® Xeon® スケーラブル・プロセッサーで実行される TensorFlow* および PyTorch* フレームワークは、インテル® AMX のサポートとインテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (oneDNN) によって拡張された最適化機能により、最先端の AI パフォーマンスを提供します。

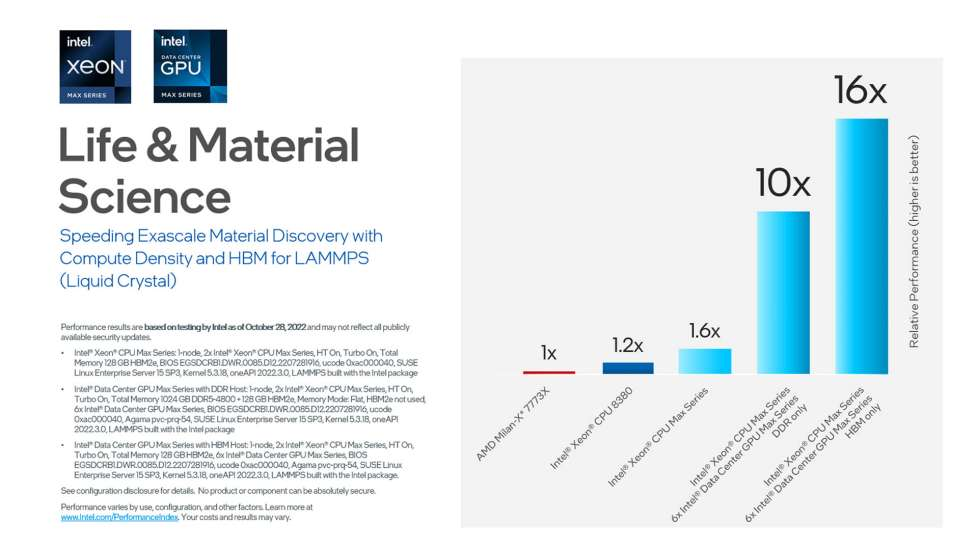
エクサスケールにおける材料発見のスピードを向上
インテル® ソフトウェア開発ツールによる LAMMPS (液晶ワークロード) のベンチマークのテスト結果は、ライフサイエンスの分野や材料工学の分野において、一般的な分子動力学コードです。
ライフサイエンスおよび材料工学における開発をスピードアップ
このベンチマークは、DDR と高帯域幅メモリーの両方を使用して、インテル® Xeon® プロセッサー・マックス・シリーズおよびインテル® データセンター GPU マックス・シリーズの組み合わせで実行されました。脳機能マッピング向けのコードの多くは C++ で記述されているため、インテル® oneAPI DPC++/C++ コンパイラー (SYCL* を使用した C++ の oneAPI 実装) を使用して並列処理とベクトル化情報を公開し、GPU を効果的に使用します。コードの他の部分の並列処理のために、コンパイラーでインテル® oneAPI マス・カーネル・ライブラリー (oneMKL) と OpenMP* も使用されました。
インテル® ソフトウェア開発ツール 2025
バージョン 2025.1 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートや動作環境、およびインテル社公開の情報を参照ください。
インテル® ソフトウェア開発ツールに関するその他のドキュメントについては、こちらを参照ください。
同梱ツール/機能一覧
インテル® ソフトウェア開発ツール向けサポートサービス |
||||
|---|---|---|---|---|
| インテル® oneAPI ベース・ツールキット (旧製品: インテル® VTune™ プロファイラー、インテル® DAAL、インテル® MKL、インテル® IPP、インテル® TBB、インテル® System Studio for FreeBSD) |
インテル® oneAPI ベース & HPC ツールキット | インテル® Fortran コンパイラー向けサポートサービス | ||
| シングルノード (旧製品: インテル® Parallel Studio XE Composer Edition、Professional Edition) |
マルチノード ※2 (旧製品: インテル® Parallel Studio XE Cluster Edition) |
|||
| インテル® oneAPI DPC++/C++ コンパイラー | ■ | ■ | ■ | |
| インテル® DPC++ 互換性ツール | ■ | ■ | ■ | |
| インテル® oneAPI DPC++ ライブラリー | ■ | ■ | ■ | |
| インテル® oneMKL 数値演算ライブラリー |
■ | ■ | ■ | ■ |
| インテル® oneDAL データ解析ライブラリー |
■ | ■ | ■ | |
| インテル® oneTBB マルチスレッド・ライブラリー |
■ | ■ | ■ | |
| インテル® oneCCL コレクティブ・コミュニケーション・ライブラリー |
■ | ■ | ■ | |
| インテル® oneDNN ディープ・ニューラル・ネットワーク・ライブラリー |
■ | ■ | ■ | |
| インテル® IPP 画像処理ライブラリー |
■ | ■ | ■ | |
| インテル® クリプトグラフィー・プリミティブ・ライブラリー 暗号化ライブラリー |
■ | ■ | ■ | |
| インテル® VTune™ プロファイラー パフォーマンス分析ツール |
■ | ■ | ■ | |
| インテル® Advisor 並列化アドバイスツール |
■ | ■ | ■ | |
| インテル® ディストリビューションの GDB システム全体のデバッグツール |
■ | ■ | ■ | |
| インテル® ディストリビューションの Python* ※3 | ■ | ■ | ■ | |
| インテル® Fortran コンパイラー | ■ | ■ | ■ | |
| インテル® MPI ライブラリー メッセージ・パッシング・ライブラリー |
■ | ■ | ||
| 取り扱い OS 環境 ※1 | W / L | W / L | W / L | W / L |
| ※1 | W: Windows* (Visual Studio*)、L: Linux* (GNU*) |
| ※1 | 対応動作環境の詳細は各製品のリリースノートを参照してください |
| ※2 |
インテル® oneAPI ベース & HPC ツールキットでは、ターゲット・プラットフォームのメモリーシステムの種類により、シングルノードとマルチノードの 2 つの製品が提供されます。
|
ベース・ツールキット
ダイレクト・プログラミングを実現するデータ並列 C++ (DPC++) コンパイラー
本製品に含まれるコンパイラーとライブラリーを使用することで、AI アクセラレーション向けインテル® ディープラーニング・ブースト (インテル® DL ブースト) を含むインテル® アドバンスト・ベクトル・エクステンション 512 (インテル® AVX-512) 対応の第 3 世代インテル® Xeon® スケーラブル・プロセッサー等、最新のハードウェアの最先端の機能をすべて活用し、インテルの CPU、GPU、FPGA のパフォーマンスを最大限に引き出すことで、計算を高速化します。
製品には、ハードウェア・ターゲット間でコードを再利用し、CPU、GPU、および FPGA アーキテクチャーで高い生産性とパフォーマンスを実現するインテル® oneAPI DPC++/C++ コンパイラー、インテル® oneAPI DPC++ 互換性ツール、インテル® oneAPI DPC++ ライブラリー、スレッド/数学/マルチメディア/信号処理パフォーマンス・ライブラリー、解析/エラー検出/並列化アドバイス/デバッグツール、数学パフォーマンス・ライブラリーを活用した Python* パッケージが含まれています。
インテル® oneAPI DPC++/C++ コンパイラー
データ並列 C++、C++、C、SYCL*、および OpenMP* をサポートする標準ベースのクロスアーキテクチャー・コンパイラーです。実績のある LLVM コンパイラー・テクノロジーとコンパイラーを主導してきたインテルの経験を活用して、優れたパフォーマンスを実現します。主要なコンパイラー、開発環境、オペレーティング・システムとのシームレスな互換性を提供します。
OpenMP* 並列プログラミング仕様を利用して、スレッド化とベクトル化を行うことでパフォーマンスをさらに向上できます。
ツールは主要な開発環境とシームレスに統合され、開発者の生産性を高めます。また、拡張された最適化レポートとインテル® VTune™ プロファイラーおよびインテル® Advisor の統合により、開発者はコードのプロファイルを制御できます。
インテル® DPC++ 互換性ツール
CUDA* ソースコードを DPC++ コードへ移行するのを支援します。
インテル® oneAPI DPC++ ライブラリー
生産性を高めるアルゴリズムと関数によりデータ並列ワークロードを高速 化します。
インテル® ディストリビューションの GDB
効率良くコードをトラブルシューティングするのに役立ちます。
インテル® ディストリビューションの Python*
インテル® ディストリビューションの Python* は、パフォーマンス指向の統合型ディストリビューションで、Python* アプリケーションを高速化します。
強力なインテル® パフォーマンス・ライブラリーを使用して、最適化されたアルゴリズム、スレッド化、ベクトル化機能を活用し、NumPy*/SciPy*/scikit-learn
のような Python* 計算パッケージのパフォーマンスを向上できます。
別の方法として、Numba* で (LLVM) JIT コンパイル、Cython* で Python* を C
コンパイルしてパフォーマンスを引き出すこともできます。
ディストリビューションは pip および conda と互換で、Windows*、macOS*、Linux* で利用可能です。
インテル® oneMKL
数学ライブラリー
インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL) には、アプリケーションのパフォーマンスを向上して開発時間を短縮します。
最新のプロセッサーは、コア数が増加し、ベクトルユニットがより広くなり、改良されたアーキテクチャーを採用しています。すべての処理能力を活用する最も簡単な方法は、この高度に最適化された算術演算ライブラリーを使用することです。
インテル® oneMKL には、線形代数、高速フーリエ変換、ニューラル・ネットワーク、ベクトル演算、統計、その他の高度な関数を含む、さまざまなルーチンが含まれています。単一の C または Fortran API 呼び出しにより、最適なコードパスが選択され、これらの関数は、現在、将来のプロセッサー・アーキテクチャーに合わせて自動的にスケーリングします。
インテル® oneDAL
データ解析およびマシンラーニング・ライブラリー
インテル® oneAPI データ・アナリティクス・ライブラリー (インテル® oneDAL) は、高度に最適化されたマシンラーニングと高速なビッグデータ解析を実現します。
この包括的なライブラリーは、データ解析処理のすべての段階 (前処理、変換、解析、モデリング、意思決定) を高速化し、エッジからクラウドまで、オフライン、ストリーミング、分散型使用モデルをサポートします。
インテル® oneDAL は、スレッド化とベクトル化を最大限に活用し、最高のパフォーマンスを引き出せるようにデータの取り込みとアルゴリズムの計算を最適化します。
アルゴリズムの透明性を示しコミュニティーに貢献するためオープンソース・バージョンも提供されています。
インテル® IPP
画像、信号、データ処理アプリケーション向けに最適化されたビルディング・ブロック
インテル® インテグレーテッド・パフォーマンス・プリミティブ (インテル® IPP) を使用して、高度に最適化された画像処理、信号処理、セキュリティー、ストレージ・アプリケーションを作成できます。
この高度なツールは、最新の命令セットを活用してインテル® プロセッサーの能力を引き出す、最適化された低水準 API を提供します。これらの最適化は、多くの計算ドメイン (特に信号処理、画像処理、データ処理) を高速化します。
クロス OS のサポートおよび最良の最適化パスを選択する内部ディスパッチャーにより、複数の世代のプロセッサーで機能する移植性に優れたコードを素早く作成することができます。
インテル® oneTBB
スレッド・ライブラリー
インテル® oneAPI スレッディング・ビルディング・ブロック (インテル® oneTBB) は、ループやタスクベースのアプリケーションで並列パフォーマンスとスケーラビリティーを簡単に利用できます。
このツールにより、コア数の増加に伴ってパフォーマンスがリニアにスケーリングする、プラットフォームの詳細やスレッド化のメカニズムが抽象化された強固なアプリケーションを開発することができます。
マルチコアおよびメニーコア・ハードウェアの電力とパフォーマンスを効率良く使用する最適なスレッド・スケジュールとワーク分割を自動的に決定します。
インテル® oneCCL
コレクティブ・コミュニケーション・ライブラリー
インテル® oneAPI コレクティブ・コミュニケーション・ライブラリー (インテル® oneCCL) は、最適化された通信パターンを実装して、ディープラーニングやマシンラーニング・モデルのトレーニングを複数のノードに分散します。
インテル® oneDNN
ディープ・ニューラル・ネットワーク・ライブラリー
インテル® oneAPI ディープ・ニューラル・ネットワーク・ライブラリー (インテル® oneDNN) は、パフォーマンスを最適化したビルディング・ブロックを使用して、インテルの CPU および GPU 上で高速なニューラル・ネットワークを開発できます。
インテル® VTune™ プロファイラー
パフォーマンス・プロファイラー
-
広範なプロファイル作成機能
単純なアプリケーションのチューニングを行う場合でも、スレッド化された MPI アプリケーションの高度なパフォーマンス最適化を行う場合でも、インテル® VTune™ プロファイラーで必要なデータを取得可能。hotspot、スレッド化、ロックと待機、DirectX*、OpenCL*、OpenMP*、帯域幅、キャッシュ、ストレージ・レイテンシーなどに関する豊富なパフォーマンス・データを収集します。コンテナー内のプロファイルも可能です。 -
生産性
良いデータがあっても、それを役立てることができなければ意味がありません。データを考察するにはマイニングが必要です。強力な解析により、タイムラインやソースコードで結果をソート、フィルター、視覚化して時間を節約できます。 -
C、C++、C#、Fortran、Python*、Go*、Java*、OpenCL* に対応
シングルコード・プロファイラーとは異なりインテル® VTune™ プロファイラーは言語が混在したコードの hotspot を正確に特定します。
インテル® Advisor
ベクトル化/スレッド化アドバイザー
最近のプロセッサーでは、ベクトル化とスレッド化を行ったコードは非常に高速に実行できます。しかし、コードがベクトル化できない理由を理解することは容易ではありません。
インテル® Advisor は、C、C++、Fortran ソフトウェア・アーキテクト向けの高性能ベクトル化/スレッド化プロトタイプ生成ツールです。
新しいルーフライン解析機能は、パフォーマンスへの影響が大きく、最適化が不十分なループを特定して最適化を単純化します。安全に効率良くベクトル化できるように、反復回数、データ依存性、メモリー・アクセス・パターンなどの必要なキーデータを取得します。
インテル® AVX-512 対応ハードウェアがない場合でも、最新のインテル® AVX-512 命令セット向けの最適化を行えます。
OpenMP*

標準規格に基づいた並列モデル
OpenMP* は、ハイパフォーマンスな並列化およびベクトル化されたアプリケーションの作成を単純化するディレクティブ・ベースのコンパイラー拡張機能です。OpenMP* を使用すると、SIMD 命令を活用した移植性に優れたアプリケーションを作成できます。
OpenMP* はインテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーにシームレスに統合されます。Windows* および Linux* でサポートされています。
OpenMP* 関連の情報については、以下を参照ください。
ベース & HPC ツールキット
クラスター向けソフトウェア開発のための Fortran コンパイラー、チューニング・ツール、最適化された MPI ライブラリー
ベース・ツールキットの機能に加え、MPI-3 規格に対応した MPI ライブラリーや、MPI 通信によるパフォーマンスの問題となる箇所を素早く発見する性能解析ツールが含まれています。
インテル® アーキテクチャー・ベースのクラスター向けにハイパフォーマンスなプログラム開発をするためには本製品が最適です。
- シングルノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムのターゲット・プラットフォーム向け
- マルチノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムに加え、HPC クラスターを含む分散メモリーシステムのターゲット・プラットフォーム向け
インテル® Fortran コンパイラー
Fortran と OpenMP* をサポートする標準ベースの CPU および GPU コンパイラーです。実績のある LLVM コンパイラー・テクノロジーとコンパイラーを主導してきたインテルの経験を活用して、優れたパフォーマンスを実現します。主要なコンパイラー、開発環境、オペレーティング・システムとのシームレスな互換性を提供します。
インテル® MPI ライブラリー
メッセージ・パッシング・インターフェイス・ライブラリー
インテル® MPI ライブラリーは、MPI レイテンシーを最小限に抑え、広範なインターコネクト・ファブリック (Infiniband*、Myrinet*、iWARP、TCP/IP など) で業界最先端のパフォーマンスと強固なスケーリングを実現します。
MPI ランタイムクラスターおよびパフォーマンスを最適化するアプリケーション固有のチューニングをサポートします。
インテル® oneAPI DPC++/C++ コンパイラーとインテル® Fortran コンパイラーに加えて、ノードレベルのメモリー、スレッド、プロファイル・ツール、インテル® VTune™ プロファイラーなどの強力なインテル® ソフトウェア開発ツールとの統合により、MPI アプリケーションの迅速な開発、プロファイル、解析が可能です。
お知らせ
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
バージョン 2025 の初期リリースには、最新のインテル® DPC++/C++ コンパイラー 2025.0 およびインテル® Fortran コンパイラー 2025.0 の英語版が含まれます。
技術サポートが提供される対象バージョンは、サポート対象のバージョンに関する記載をご確認ください。
ツールの提供終了に関するご案内
開発元であるインテル社の方針により、バージョン 2025 のリリースに伴い、以下のツールは提供終了となりました。
- インテル® Fortran コンパイラー・クラシック (ifort)
今後も Windows* および Linux* サポート、新しい言語サポート、新しい言語機能、最適化オプションを含む最新の機能を利用される場合は、今すぐ LLVM ベースのインテル® Fortran コンパイラー (ifx) へ移行することを推奨します。新しいコンパイラーとの相違点など、移行のための技術的な情報については、「インテル® oneAPI ポーティング・ガイド ― ifx へ移行する ifort ユーザー向け」をご参照ください。
以下のツールにつきましては、開発元であるインテル社の方針により、バージョン 2024.1 以降に含まれなくなりました。スタンドアロン・パッケージは、2025年以降に廃止される予定です。
インテル® oneAPI ベース & HPC ツールキットの有償サポートサービス製品を購入されたお客様は、それによるサポートサービスが有効な間、相当する旧バージョンのソフトウェアに対する技術サポートをご利用いただけます。ただし、それら旧バージョンの継続的な使用は推奨しません。
2024年6月9日をもって、製品の開発、提供元であるインテルの意向により、有償サポートサービス製品のひとつであった「インテル® oneAPI ベース & レンダリング・ツールキット」の販売を終息しました。
インテル® oneAPI ベース & レンダリング・ツールキットによって優先サポートが提供されていた固有のツールキット「インテル® レンダリング・ツールキット」は、引き続き、インテルのウェブページ、または各ライブラリーやツールのオープンソース・プロジェクト・ページから、どなたでもダウンロードできます。
2023年11月24日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2024 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
バージョン 2024 の初期リリースには、最新のインテル® DPC++/C++ コンパイラー 2024.0 およびインテル® Fortran コンパイラー 2024.0 の英語版が含まれます。
技術サポートが提供される対象バージョンは、サポート対象のバージョンに関する記載をご確認ください。
ツールの提供終了に関するご案内
開発元であるインテル社の方針により、バージョン 2024 のリリースに伴い、以下のツールは提供終了となりました。
- インテル® C++ コンパイラー・クラシック (icc)
- インテル® Cluster Checker
- インテル® oneAPI IoT ツールキット
インテル® oneAPI IoT ツールキットまたはインテル® C++ コンパイラー・クラシック (icc) やインテル® Cluster Checker が同梱されたツールキットの有償サポートサービス製品を購入されたお客様は、それによるサポートサービスが有効な間、相当する旧バージョン (2023.2 またはそれ以前) のソフトウェアに対する技術サポートをご利用いただけます。ただし、それら旧バージョンの継続的な使用は推奨しません。
開発元であるインテル社の方針により、インテル® oneAPI ツールキット 2024 のリリースを以ってインテル® Fortran コンパイラー・クラシック (ifort) における macOS* のサポート終了が予定されています。今後も macOS* サポートをご利用いただく場合、旧製品バージョンのサポートサービスに関するポリシーに沿って、有効なサポートサービスをお持ちのお客様を対象にバージョン 2023 の提供が継続されます。
新しい LLVM ベースのインテル® Fortran コンパイラー (ifx) では macOS* をサポートしておらず、インテル® プロセッサーの搭載に関わらず、現時点で macOS* サポートが追加される予定はありません。
2023年5月2日より、インテル® oneAPI ツールキットについて、Fortran 言語ユーザー向けにサポート対象を限定 (※) することで、お求めやすい価格で購入いただけるサポート製品を販売しております。
「インテル® Fortran コンパイラー向けサポートサービス」でサポートされるコンポーネント:
- インテル® Fortran コンパイラー
- インテル® (Visual) Fortran コンパイラー・クラシック
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)
※ インテル® oneAPI ベース & HPC ツールキット (シングルノード) の一部です。コンポーネントの一覧は、こちらのページをご覧ください。
インテル® oneAPI Fortran プロモーション製品による有効なサポートサービスをお持ちの場合は、「インテル® Fortran コンパイラー向けサポートサービス」の SSR (サポートサービス更新) 製品により、サポートサービスの期間を更新できます。
2022年12月19日、インテル® oneAPI 2023 の販売を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
インテル® oneAPI 2023 の初期リリースには、最新のインテル® DPC++/C++ コンパイラー 23.0 およびインテル® Fortran コンパイラー 23.0 の英語版が含まれます。
技術サポートが提供される対象バージョンは製品ごとに異なりますので、サポート対象のバージョンに関する記載をご確認ください。
インテル® oneAPI ツールキット製品の新バージョン 2022 について、Fortran 言語ユーザー向けにサポート対象を限定 (※) することでお得な価格で購入いただけるプロモーション製品を販売いたします。
サポートされるコンポーネント:
- インテル® Fortran コンパイラー
- インテル® ディストリビューションの Python*
- インテル® oneAPI マス・カーネル・ライブラリー (インテル® oneMKL)
※ インテル® oneAPI ベース & HPC ツールキット (シングルノード) の一部です。コンポーネントの一覧は、こちらのページをご覧ください。
2023年5月2日より、インテル® oneAPI Fortran プロモーション製品に代わって、インテル® Fortran コンパイラー向けサポートサービス製品を、よりお求めやすい価格で提供しています。
すでにインテル® oneAPI Fortran プロモーション製品による有効なサポートサービスをお持ちの場合は、「インテル® Fortran コンパイラー向けサポートサービス」の SSR (サポートサービス更新) 製品により、サポートサービスの期間を更新できます。
2021年 12月 23日、インテル® oneAPI 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日に提供が開始されたインテル® oneAPI 2022 の初期リリースには、最新のインテル® DPC++/C++ コンパイラー 22.0 およびインテル® Fortran コンパイラー 22.0 の英語版が含まれます。日本語版のインテル® コンパイラーをご利用いただく場合、インテル® Parallel Studio XE 製品を引き続きご使用ください。
技術サポートが提供される対象バージョンは製品ごとに異なりますので、サポート対象のバージョンに関する記載をご確認ください。
バージョン 2021 より、インテル® Parallel Studio XE、インテル® System Studio が「インテル® oneAPI」に名称統一され、ベース・ツールキット、ベース & HPC ツールキット、ベース & IoT ツールキット、ベース & レンダリング・ツールキットの 4 つのツールキットとなりました。
新旧名称の対比については、こちらを参照ください。
2020年 12月 8日、インテル® oneAPI 2021 の販売を開始しました。過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、インテル® oneAPI ツールキット製品を無料でダウンロードしてご利用いただけます。
インテル® oneAPI ツールキット製品には、最新インテル® コンパイラー 21.1 の英語版が含まれています。インテル® コンパイラーの日本語版は同梱されていません。日本語版をご利用いただく場合、インテル® Parallel Studio XE 製品を引き続きご使用ください。
また、インテル® oneAPI 2021 をご利用、ご評価いただき、新機能などの新バージョンに関するご意見をお聞かせいただいた方の中から抽選で 30 名様にプレゼントが当たるキャンペーンを実施中です。この機会に、ぜひ最新バージョンをお試しください。
キャンペーンの応募条件に関する詳細につきましては、こちらのキャンペーン専用ページをご参照ください。
FAQ
これらのライブラリーは、oneAPI イニシアチブと連携して、コミュニティーによる仕様策定や定義が進められている oneAPI ライブラリー仕様の一部であるためです。
次世代のインテル® コンパイラー・テクノロジーは LLVM ベースで、データ並列 C++ または OpenMP*
オフロードでアクセラレーター・テクノロジーをターゲットにすることができます。
インテル®
Fortranコンパイラー・クラシックおよびインテル® C++
コンパイラー・クラシックは、インテル® Parallel Studio XE およびインテル® System
Studio (C++ のみ) の一部として提供されているコンパイラーで、CPU
に特化した開発を行うユーザー向けに引き続きサポートされます。
ベータ版インテル® Fortran コンパイラーは CPU
をターゲットとする開発とインテルの GPU への OpenMP* オフロードをサポートし、インテル® oneAPI DPC++/C++
コンパイラーはインテルの CPU、GPU、FPGA をターゲットとする開発をサポートします。
いいえ。サポートされている言語ごとに (C++、Fortran、または C++ と Fortran のバリエーション) 製品が販売されていたのはインテル® Parallel Studio XE までです。インテル® oneAPI ベース & HPC ツールキットでは、サポートされているすべての言語が製品に含まれています。
いいえ。インテル® oneAPI ベース・ツールキット、インテル® oneAPI ベース & HPC ツールキット、インテル® oneAPI ベース & レンダリング・ツールキットの商用製品では、各ツールキットはサポートしているすべての OS に対応しており、OS による製品のバリエーションはありません。ホストおよびターゲット・プラットフォーム向けにサポートされているすべての OS にアクセスできます。OS サポートについては、各ツールキットのシステム要件を参照してください。すべてのコンポーネントがすべての OS でサポートされているわけではないことに注意してください。
インテル® oneAPI ベース & HPC ツールキットやインテル® oneAPI ベース & レンダリング・ツールキットの「シングルノード」バージョンと「マルチノード」バージョンの違いは何ですか?
インテル®oneAPI ベース & HPC ツールキット、およびインテル®oneAPI ベース &
レンダリング・ツールキットでは、ターゲット・プラットフォームのメモリーシステムの種類により、シングルノードとマルチノードの 2 つの製品が提供されます。
- シングルノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムのターゲット・プラットフォーム向け
- マルチノード: PC、ラップトップ、ワークステーションを含む共有メモリーシステムに加え、HPC クラスターやレンダーファームを含む分散メモリーシステムのターゲット・プラットフォーム向け
インテル® Parallel Studio XE とインテル® oneAPI ツールキットの対応については、新旧製品名一覧を参照してください。
いいえ。これらの「アドオン」ツールキットは、インテルの最新プラットフォームを対象とする開発ニーズを満たす完全なツールスイートの一部として、インテル® oneAPI ベース・ツールキットとともに使用するものです。スタンドアロンでは購入できません。
データ並列 C++ は C++ ベースで Khronos の SYCL* を統合しており、データ並列処理とヘテロジニアス・プログラミングをサポートします。言語拡張は、データ並列プログラミングを簡素化する拡張とともに、コミュニティー・プロジェクトを通じて推進されます。これらの拡張は、短期的には SYCL* 仕様の将来のバージョンに、長期的には ISO C++ 標準規格に含めることが提案されています。
データ並列 C++ は、CPU とアクセラレーターに並列プログラミングの生産性とパフォーマンスを提供する oneAPI の主要言語です。DPC++ の目標は、プログラミングを簡素化し、さまざまなハードウェア・ターゲットでコードを再利用できるようにしつつ、特定のアクセラレーター向けのチューニングも可能にすることです。データ並列 C++ は C++ ベースで Khronos SYCL* を統合しており、データ並列処理とヘテロジニアス・プログラミングをサポートします。言語拡張は、データ並列プログラミングを簡素化する拡張とともに、コミュニティー・プロジェクトを通じて推進されます。これらの拡張は、短期的には SYCL* 仕様の将来のバージョンに、長期的には ISO C++ 標準規格に含めることが提案されています。
oneAPI DPC++ コンパイラーを含む、多くのライブラリーとコンポーネントはすでにオープンソースであるか、間もなくオープンソースになる可能性があります。オープンソースの要素は、oneapi.com (英語) で確認できます。
oneAPI の言語、DPC++、およびライブラリーの仕様は、ほかのハードウェア・ベンダーが使用できるように公開されており、インテルでは各社に oneAPI の採用を推奨しています。独自の oneAPI 実装を作成して特定のハードウェア向けに最適化するかどうかは、各ベンダーや業界関係者次第です。例えば、Codeplay* は、NVIDIA* GPU 向けのハイパフォーマンス・コードを生成するため、オープンソースの DPC++ コンパイラーに NVIDIA* コンパイラー・バックエンドを提供しています。
oneAPI 仕様は、複数のベンダーの幅広い CPU とアクセラレーターをサポートするように設計されています。ベータ版インテル® oneAPI リファレンス実装は、現在、インテル® CPU (インテル® Xeon® プロセッサー、インテル® Core™ プロセッサー、Intel Atom® プロセッサー)、インテル® Arria® FPGA、インテル® Stratix® 10 FPGA、および将来のインテル製ディスクリート・データセンター GPU 向けプロキシー開発プラットフォームとして第 9 世代および第 11 世代インテル® プロセッサー・グラフィックスをサポートしています。今後も、その他のインテルのアクセラレーター・アーキテクチャーが追加される予定です。
いいえ。直接実行することはできませんが、1 つのハードウェア・アーキテクチャーに「固定」されていると感じ、ハードウェアをより自由に選択できる言語にコードを移行したいと考えている CUDA* 開発者を支援するため、インテル® DPC++ 互換性ツールを提供しています。
oneAPI は、インテルのハードウェアだけでなく、さまざまな種類のプロセッサーとアクセラレーターの開発を簡素化するように構築されています。ダイレクト・プログラミング・コンポーネントと API
ベースのプログラミング・コンポーネントの両方を含む標準およびオープン仕様に基づいており、広範なエコシステムの採用およびイノベーションを可能にします。
インテルは、コラボレーションを促進し、新しい機能と拡張機能を構築するため、DPC++
(oneAPI で使用されるダイレクト・プログラミング言語) のオープン・コミュニティー・プロジェクトを立ち上げました。イニシアチブに参加している企業は、オープン仕様を使用して、oneAPI
ベースの独自の実装を構築できます。
oneAPI には、Khronos Group の SYCL* 仕様を統合した C++ ベースのデータ並列 C++ (DPC++) と呼ばれる、ダイレクト・プログラミング向けの統一された言語が含まれています。また、サポートされるすべてのプラットフォームで、並列処理を実装して高水準言語のネイティブ・パフォーマンスを実現する各種パフォーマンス・ライブラリーを含む API ベースのプログラミングも含まれています。
いいえ。oneAPI は、C、C++、Fortran、Python*、MPI、OpenMP* などの既存の言語やプログラミング・モデルと共存できます。アプリケーションが CUDA* で記述されている場合は、一部のコードの書き直しが必要になることがあります。CUDA* から oneAPI への移行を支援するため、CUDA* 開発者向けにインテル® DPC++ 互換性ツールを提供しています。移行できなかったコードは、ツールの実行後に手動で編集する必要があります。
データセントリックな分野の特殊なワークロードには、強力な CPU から専用の AI シリコンまで、多様なコンピューティング・エンジンが必要となります。現在、データセントリックなハードウェアでは、異なる言語、ライブラリー、ソフトウェア・ツールを使用してプログラムされた個別のコードベースを維持しなければならないのが一般的です。これは複雑で、開発者は多くの時間を費やす必要があり、アクセラレーションとイノベーションの妨げとなります。インテルとそのエコシステムは、oneAPI を利用して、クライアントからデータセンター、エッジ、5G 通信など、さまざまな処理エンジンをサポートする統一されたソフトウェア・アーキテクチャーを構築しています。
最新のマルチコア・プラットフォーム向けに最適化を行うことが、インテル® プロセッサーの性能を最大限に引き出すための最良の方法です。インテル® ソフトウェア開発ツールと最新のプログラミング・モデルを採用することにより、プログラミングの投資を無駄にすることなく、新しいプロセッサー・テクノロジーを導入することができます。C/C++ プログラマーは、インテル® oneAPI ツールキットに含まれているインテル® スレッディング・ビルディング・ブロック (インテル® TBB) から始めると良いでしょう。インテル® TBB は、並列処理を活用するタスクベースの抽象化を、移植性とスケーラビリティーに優れ、安定性を備えた、将来にも対応できるタスク/データ並列モデルのセットとともに提供します。これらのモデルは既存のアプリケーションに簡単に統合でき、ソフトウェアおよびハードウェアの投資を保護します。
Fortran プログラマーおよび多くの C プログラマーは、OpenMP* に注目すべきです。
インテル® oneAPI ツールキット製品の 30 日間の評価版をダウンロードできます。評価ライセンスをリクエストした後、評価版ダウンロード専用フォームから発行される 13 桁のシリアル番号を添えて弊社までお問い合わせいただいた場合、評価期間中に無料のサポートを受けることができます。
インテル® oneAPI の評価版は、こちらからダウンロードできます。
macOS* (x86) 向けのインテル® oneAPI ツールキットは、2024.0 のリリースで提供が終了しました。
購入時の製品シリアル番号を用いてインテル® レジストレーション・センターで製品の登録を行い、ライセンスファイル (拡張子が .lic のファイル) を取得します。その後、取得したライセンスファイルを所定のディレクトリーに配置すれば製品版として使用することができます。
具体的な手順、ライセンスファイルの配置場所は 製品登録 & ダウンロード・ページのシリアル番号の登録方法を参照ください。
- 評価版から製品版に切り替える際に、再インストールする必要はありません。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル
® レジストレーション・センター操作マニュアルを参照ください。