概要
精度の高いデータで高速なアプリケーションを素早く開発

初めてのチューニングから高度な最適化にわたって、インテル® VTune™ プロファイラー は CPU と GPU パフォーマンス、スレッドのパフォーマンスとスケーラビリティー、バンド幅、キャッシュ利用など、パフォーマンス向上のための豊富な情報を収集します。一般的なスレッド化モデルをサポートし、解析を支援するハイレベルな情報を提供するため、素早く簡単にチューニングを行うことができます。解析結果をタイムラインとソースコード上でソート、フィルターして可視化できます。
シングルコード・プロファイラーとは異なり、C/C++、Fortran、Python*、Go*、Java* が混在したコードの hotspot を正確に特定します。
詳細・新機能 ライセンス・サポートサービス最新のプロセッサーのパフォーマンス解析
最新のプロセッサーのパフォーマンスを解析する場合、シングルスレッド・パフォーマンスを最適化するだけでは十分ではありません。ハイパフォーマンスなコードには、次のものが求められます。
- 複数の CPU を利用するためのスレッド化とスケーラビリティー
- 複数の FPU を効率良く使用するためのベクトル化
- NUMA とキャッシュを利用するためのチューニング
メディア・アプリケーションでは、OpenCL* と GPU のチューニングも必要になります。インテル® VTune™ プロファイラー では、これらの高度なプロファイル機能をフレンドリーな 1 つのインターフェイスから利用できます。
インテル® VTune™ プロファイラー 2026
バージョン 2026.0 新機能およびシステム要件
新機能やシステム要件などの詳細は、以下のリリースノートやシステム要件、およびインテル社公開の情報を参照ください。
最新バージョンに関する日本語情報をお探しの方は、ツールキットのリリースノートをあわせてご参照ください。
インテル® VTune™ プロファイラーに関するその他のドキュメントについては、こちらを参照ください。
詳細
最初にチューニングすべきことは?
多くの時間を費やしているコードを素早く特定
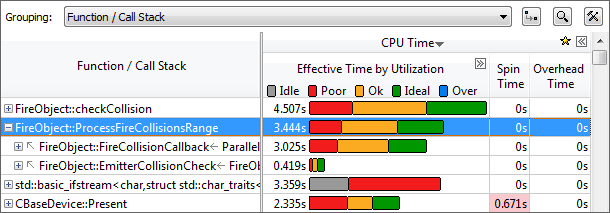
hotspot 解析結果では、多くの CPU 時間を費やしている関数のリストがソートして表示されます。これにより、チューニングによって最大の効果が得られる箇所を確認できます。[+] をクリックするとコールスタックが表示され、ダブルクリックで該当するソースコードが表示されます。
結果を素早く解析 – プロファイルデータをソース上に表示
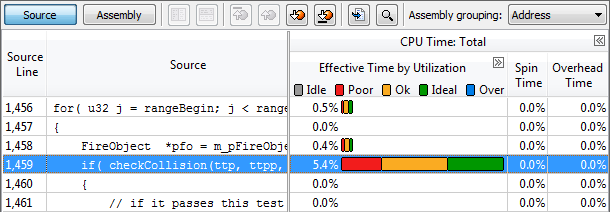
関数リストをダブルクリックすると、関数で最も時間を費やしているソースコード内の該当箇所に移動します。
C/C++、Fortran、Python*、Go*、Java* 混合コードをプロファイル

シングルコード・プロファイラーとは異なり、C/C++、Fortran、Python*、Go*、Java* が混在したコードの hotspot を正確に特定します。
最新プロセッサー上でパフォーマンスを発揮する 3 つのポイントを参照
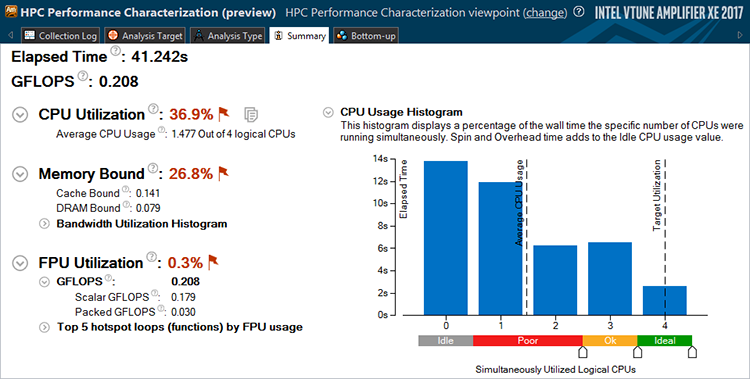
最新ハードウェアのパフォーマンスを発揮するための 3 つの重要な要素の概要を取得するには、新しい HPC パフォーマンスの特徴付けを使用します: CPU 使用率 (スレッド)、メモリーアクセス、および FPU 使用率 (FLOPS)。それから、各要素に対して、詳細な分析をドリルダウンします。
マルチコアの世界ではスレッドのパフォーマンスが重要な課題
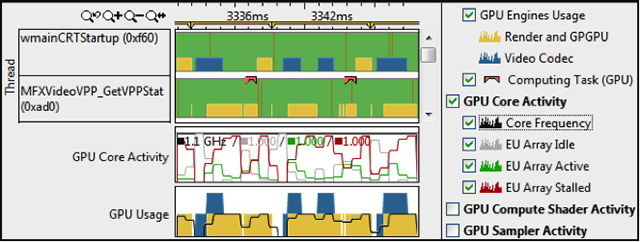
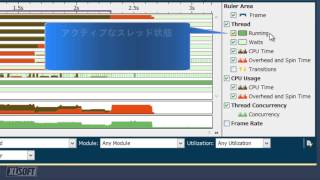
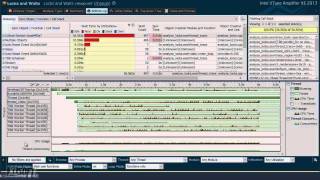
インテル® VTune™ プロファイラーは、インテル® oneTBB、OpenMP* などのスレッド化モデルをサポートします。タスクの開始/終了、同期、待機時間などマルチスレッドの概念を簡単に理解することができます。待機時間を確認する "Lock & Wait" 解析 (次にあるイメージ) は便利な機能の 1 つです。タイムラインの可視化 (以下の 2 番目のイメージ) では、ロック競合 (黄色のトランジション)、負荷インバランス、そして不用意なシリアル化など、並列処理のパフォーマンスを低下させるすべての原因を容易に検出できます。
"locks and waits" 解析で遅いスレッドのコードの一般的な原因を特定
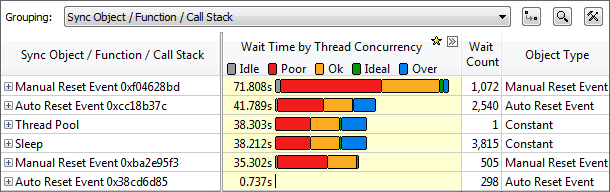
ロックでの長時間の待機は、待機中のコアが十分に活用されず、並列プログラムのパフォーマンスを低下させる一般的な原因となります。"basic hotspots" と "locks & waits" プロファイルは、インテルおよび互換プロセッサーの両方で動作するソフトウェア・コレクターを利用しています。
素早く結果を確認可能 – タイムラインのフィルター処理で必要なデータを得る
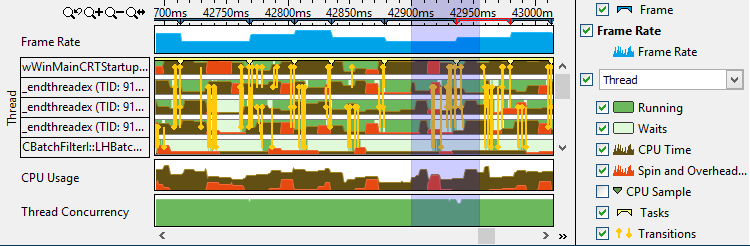
タイムラインで time range を選択し、情報をマスクして必要なデータをフィルターする (例えばアプリケーションの起動時間)。タイムラインを選択してフィルターすると、選択された範囲のグリッドの CPU 時間を多く消費している 関数リストが更新されます。黄色の線は低速なトランジションです。過度のトランジションは、ロック競合と低い並列パフォーマンスを示すことがあります。スピンロックの問題を診断するため CPU 時間のマークを無効にする – スレッドが実行中もしくは待機中の時間だけを表示し、必要のないシリアル化を特定します。
リモートシステムを簡単にプロファイル – ライセンスはホストのみに必要で、ターゲットには不要
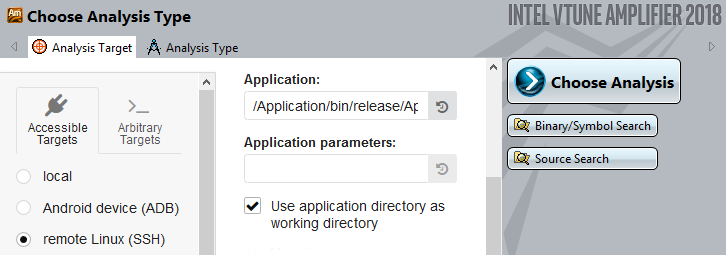
現在のホストまたはリモートシステム上で簡単にデータを収集できます。もしくは、リモートシステム上でコマンドラインを使用してデータを収集し、その後ホストでインポートしてローカルでデータを解析できます。
ヒント: 最適なパフォーマンスを達成するには、VNC スロー・グラフィックスは避けましょう。UI をローカルで実行してください。リモートターゲットからデータをインポートしましょう。リモートシステムへのインストールとデータの収集にはライセンスは必要ありません。ライセンスは、収集したデータを分析もしくは表示する場合にのみ必要です。リモートデータ収集については、 こちらの iSUS の記事もご覧ください。
ドライバーをチューニング。低いオーバーヘッドで高い精度を得る
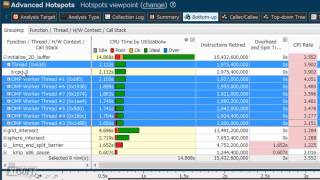
インテル® プロセッサーは、オンチップのパフォーマンス・モニタリング・ユニット (PMU) を搭載しています。インテルおよび互換プロセッサーで動作する "basic hotspots" 解析に加え、インテル® VTune™ プロファイラーには、インテル® プロセッサー上のパフォーマンス・モニタリング・ユニット (PMU) を使用した非常にオーバーヘッドの少ない収集を行う "advanced hotspots" があります。システム全体の解析では、ドライバーも分析できます。高解像度 (~1 ミリ秒対 ~10 ミリ秒) で小さな関数中のホットスポットを検出できます。
"あらかじめプリセットされた" バンド幅とメモリー解析で簡単にセットアップ
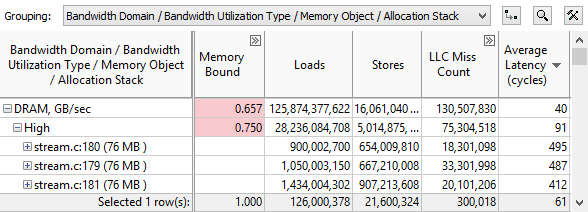
あらかじめプリセットされたプロファイルで、簡単に解析の設定が可能。複雑なイベント名を覚えることなく、バンド幅をチューニングしキャッシュ効率を最適化できます。
パフォーマンスが向上する可能性がある箇所をハイライト
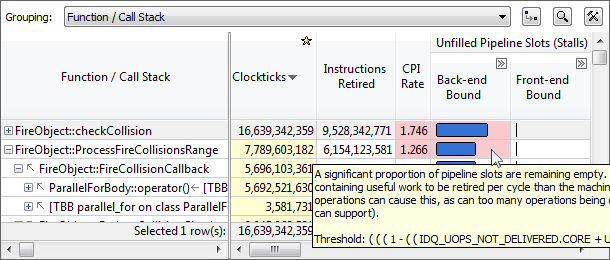
ピンク色にハイライト表示された項目は、チューニングでパフォーマンスが向上する可能性がある事を示します。マウスオーバーすることでチューニングのためのアドバイスが表示されます。
簡単で、より効率良い OpenMP* と MPI マルチランクのチューニング
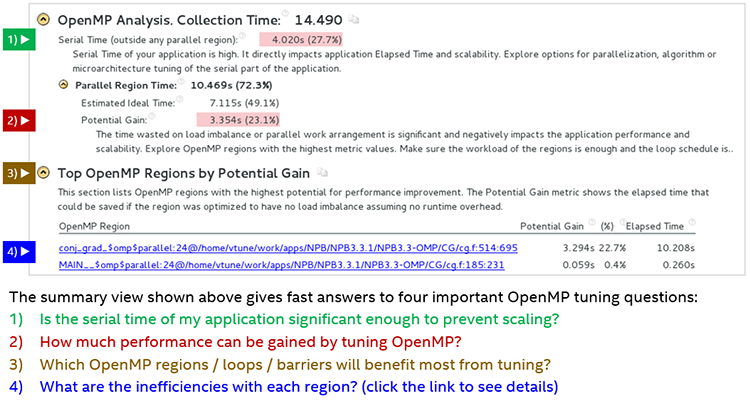
サマリーレポートは、効率良く OpenMP* のパフォーマンスを改善するための上位 4 つの問題を表示します。リンクをクリックすると詳しい情報を取得できます。
OpenMP* のパフォーマンスをどのように改善できるか素早く参照可能
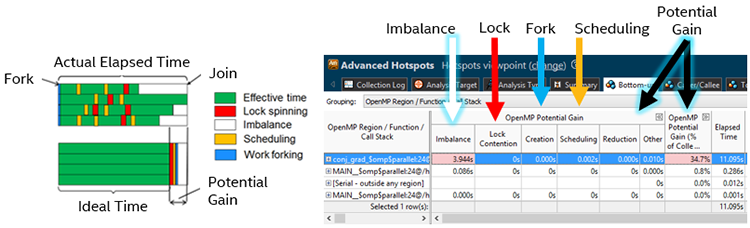
それぞれの OpenMP* 領域のチューニングでパフォーマンスが向上する可能性をハイライトします。例えば、参考画面のイメージでは、バランスを調整することで 34% 高速になる可能性があります。
MPI + OpenMP* のマルチランクを簡単に解析
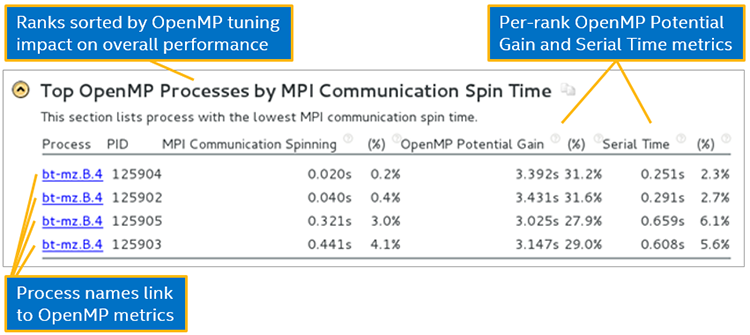
インテル® VTune™ プロファイラーのサマリー表示には、改善された OpenMP* パフォーマンスによって、パフォーマンスが向上する上位の MPI ランクのテーブルがまとめられています。
MPI と OpenMP* のハイブリッド・アプリケーションでは、ランク間の MPI 通信とともに OpenMP* が非効率である部分を探すことが重要です。少ない通信スピン時間で多くのランクが実行され、そしてより多くの OpenMP* チューニングがアプリケーションの実行時間に影響します。インテル® VTune™ プロファイラーはクラスターにインストールできます。
ストレージデバイス解析 (HDD、SATA または NVMe SSD)
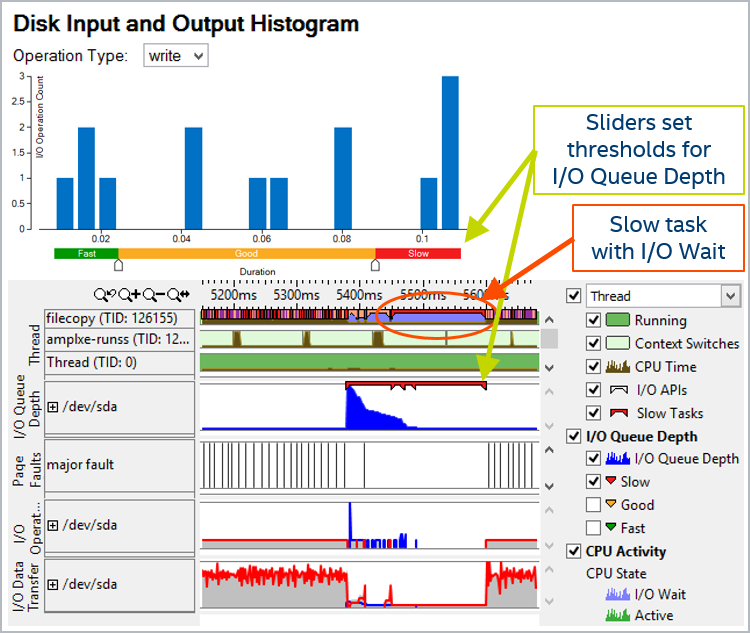
I/Oバウンドまたは CPU バインドが起こっていますか? I/O 操作(非同期および同期)と計算の間のインバランスを調査しましょう。 CPU が I/O を待っているときに、ソースコードにマッピングされたストレージアクセスを参照してください。
使いやすい OpenCL™ と GPU プロファイル – Windows* と Linux で利用可能!
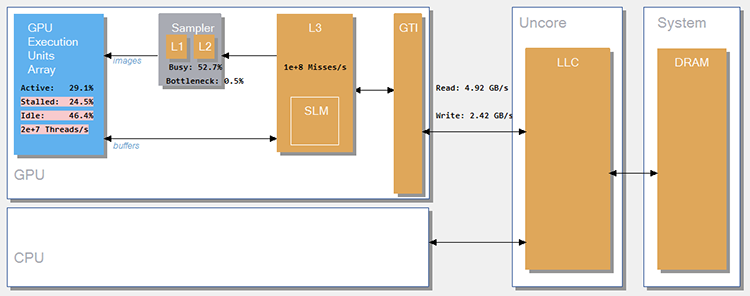
新しいプロセッサー上で OpenCL* をチューニングする場合、GPU アーキテクチャーのダイアグラムによって GPU ハードウェアのメトリックを簡単に確認することができます。
GPU とプラットフォームのデータを解析
最新のプロセッサーでは、必要に応じて OpenCL* とメディア・アプリケーション向けの GPU とプラットフォーム・データを収集できます。GPU/CPU アクティビティーを関連付けることが可能です。
特殊なコンパイラーやビルドは不要
低オーバーヘッドの収集は、データの精度を高めます。
コマンドラインを使用して自動化
コマンドライン・ツールを使用して回帰テストを自動化できます。また、簡単にリモート収集を行うためリモートシステムに軽量コンポーネントをインストールできます。
システム全体の解析
ドライバー、カーネルモデル、そしてマルチプロセス・アプリケーションをチューニング。
Microsoft* DirectX* フレームの自動識別
Windows* ゲーム中の低速な部分は? 開発者は、ゲーム中で時間がかかりフレームレートの低い場所を特定するために多くの時間を費やす必要はありません。インテル® VTune™ プロファイラーを使うことで、Microsoft* DirectX* のフレームを自動的に認識し、遅いフレームで何が起こっているかを見るためのフィルター処理が可能です。DirectX* を使用していない場合は? 時間がかかる場所に API を追加してフレーム解析を行うことで、遅延を解析することができます。
低オーバーヘッドの Java* プロファイル
Java* コードもしくは Java* とネイティブ・コードが混在したコードの解析結果を元の Java* のソースにマッピングします。インストルメント・コードを使用するほかの Java* プロファイラーとは異なり、インテル® VTune™プロファイラーは、ハードウェアとソフトウェア収集による低オーバーヘッドの統計的なサンプリングを行います。ハードウェアによる収集は、プロセッサーのパフォーマンス・モニター・ハードウェアを使用するため、非常に低オーバーヘッドです。
ユーザータスクの解析
タスク・アノーテーション API は、インテル® VTune™ プロファイラーが実行されたタスクを表示できるよう、ソースに注釈をつけるために使用されます。例えば、パイプラインのステージに API でラベルを付け、タイムラインに表示させることで、領域の詳細を明らかにします。これにより、プロファイルされたデータが分かりやすくなります。
ドキュメント
オンライン・コンテンツ
HPC アプリケーションに役立つハイパフォーマンス解析
このセッションでは HPC の分野に特化したパフォーマンス解析技術を性能解析ツール「インテル® VTune™ プロファイラー」を使用してご紹介します。
まず最初に、現在の HPC 業界における一般的なパフォーマンス解析の状況をご紹介します。そして次に、インテル® VTune™ プロファイラーに搭載される HPC Performance Characterization (HPC 特性解析) について、その概要を説明します。これは、HPC
アプリケーションのパフォーマンス特性を解析する機能となります。 さらに、HPC 特性解析を使用したパフォーマンス解析の例もご紹介します。

製品トレーニング
- 製品概要
- Hotspot 解析
- Concurrency (コンカレンシー) 解析
- Locks & Waits (ロックと待機) 解析
- Advanced Hotspots 解析 (前編)
- Advanced Hotspots 解析 (後編)
関連ページ


関連製品


お知らせ
2026年5月、インテル社よりリリースされたインテル® ソフトウェア開発ツールの最新バージョン 2026 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2026 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
バージョン 2026 の初期リリースには、最新のインテル® DPC++/C++ コンパイラー 2026.0 およびインテル® Fortran コンパイラー 2026.0 の英語版が含まれます。
技術サポートが提供される対象バージョンは、サポート対象のバージョンに関する記載をご確認ください。
ツールの提供終了に関するご案内
開発元であるインテル社の方針により、バージョン 2026 のリリースに伴い、以下のツールは提供終了となりました。
- インテル® DPC++ 互換性ツール
問題報告やリクエストは SYCLomatic のオープンソース・レポジトリーへ提出してください。
以下のツールにつきましては、開発元であるインテル社の方針により、バージョン 2026.0 以降に含まれなくなりました。スタンドアロン・パッケージは、2026年以降に廃止される予定です。
- インテル® Advisor
インテル® oneAPI ベース・ツールキットまたはインテル® oneAPI ベース & HPC ツールキットの有償サポートサービス製品を購入されたお客様は、それによるサポートサービスが有効な間、相当する旧バージョンのソフトウェアに対する技術サポートをご利用いただけます。ただし、それら旧バージョンの継続的な使用は推奨しません。
2024年11月6日、インテル社よりリリースが発表されたインテル® ソフトウェア開発ツールの最新バージョン 2025 に対応する有償サポートサービスの提供を開始します。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2025 を無料でダウンロードしてご利用いただけます。また、必要に応じて数世代前までの旧バージョンをダウンロードしてご利用いただけます。
2023年11月24日、インテル® VTune™ プロファイラー 2024 が同梱されるインテル® ソフトウェア開発ツールに対応する有償サポートサービスの提供を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2024 を無料でダウンロードしてご利用いただけます。
2022年12月19日、インテル® VTune™ プロファイラー 2023 が同梱されるインテル® oneAPI 2023 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2023 を無料でダウンロードしてご利用いただけます。
2021年 12月 23日、インテル® VTune™ プロファイラー 2022 が同梱されるインテル® oneAPI 2022 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2022 を無料でダウンロードしてご利用いただけます。
2020年 12月 9日、インテル® VTune™ プロファイラー 2021 が同梱されるインテル® oneAPI 2021 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2021 を無料でダウンロードしてご利用いただけます。
2019年 12月 18日、インテル® VTune™ プロファイラー 2020 の販売を開始しました。
本バージョンより、製品名が 「インテル® VTune™ Amplifier」 から 「インテル® VTune™ プロファイラー」 に変更となりました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2020 を無料でダウンロードしてご利用いただけます。
開発元の方針により、2019年 8月 6日を以って、インテル® VTune™ Amplifier Windows/Linux OS 共通ライセンスへの特別アップグレード製品の販売を終了いたします。
バージョン 2017 以前のインテル® VTune™ Amplifier 各 OS 向けライセンスをお持ちの場合、今後 Windows/Linux OS 共通ライセンスをご利用を希望される場合は、インテル® VTune™ Amplifier の新規ライセンスをご購入ください。
2018年 9月 13日、インテル® VTune™ Amplifier 2019 の販売を開始しました。
過去に製品をご購入いただき、現在有効なサポートサービスをお持ちのお客様は、すぐにバージョン 2019 を無料でダウンロードしてご利用いただけます。
バージョン 2017 以前のインテル® VTune™ Amplifier 製品では、Windows、Linux 各ホスト OS 向けのライセンスを販売しておりましたが、インテル社の意向により、2017年
9月 14日のバージョン 2018 リリースより、Windows、Linux 両 OS でご利用いただける「OS 共通製品」へと変更されました。
また、製品名についても、インテル® VTune™ Amplifier XE for Windows および for Linux から、「インテル® VTune™ Amplifier」 へと変更されました。
この変更により、これまでのインテル® VTune™ Amplifier for Windows または for Linux (各ホスト OS 向け製品) をお持ちのお客様が、サポートサービスの更新を希望される場合には、以下いずれかの特別アップグレード製品を購入いただくことにより、OS 共通ライセンスへアップグレードいただく必要がございます。
-
インテル® VTune™ Amplifier 特別アップグレード (OS 共通ライセンスへのアップグレード)
-
インテル Parallel Studio XE への特別アップグレード
インテル® VTune™ Amplifier OS 共通ライセンスを含む上位製品へのアップグレードです。詳しくは こちらのページをご覧ください。
インテル® VTune™ Amplifier for Windows または for Linux (各 OS 向け製品) のサポートサービスが有効な場合、本特別アップグレードをご購入いただくことで、OS
共通ライセンスへアップグレードいただけると共に、インテル® VTune™ Amplifier のサポートサービス更新用製品「SSR (期限内更新用)」よりも安価にて、サポートサービスの期間を 1 年間延長いただけます。詳しくは こちらのページをご覧ください。
iSUS では、皆様のご要望にお応えして、インテル® VTune™ Amplifier 2019 for Windows* Initial Release、Update 1、Update 2、Update 3 の日本語版を提供しています。日本語版では、GUI/CLI メッセージ、およびヘルプ (ドラフト版) やドキュメント類が日本語化されています。こちらの iSUS のページからお申し込みいただけます。
FAQ
基本的な hotspot (以前の「hotspot」)
- ソフトウェア・コレクターを使用します。
- ドライバーは必要ありません。
- インテル® プロセッサーおよび互換プロセッサーで利用できます。
- 分解能は ~10 ミリ秒。
- コールスタックを収集して呼び出しシーケンスを表示します。
- 仮想環境で動作します。
高度な hotspot
- ハードウェア・コレクターおよびオンチップのパフォーマンス・モニタリング・ユニットを使用します。
- インストールに管理者権限が必要なソフトウェアに含まれるドライバーが必要です。
- 収集にはインテル® プロセッサーが必要です。
- 分解能は ~1 ミリ秒 (より小さな関数を検出できます)。
- 最適なコールスタック収集。
- VM ベンダーでサポートされている場合のみ仮想環境で動作します (VMware vSphere* 5.1 など)。
はい。インテル® VTune ™ Amplifier は、インテルの命令セットを含むアプリケーションを解析する場合、インテル® プロセッサーと互換プロセッサーの両方で動作します。ソフトウェア・コレクターを使用するプロファイル機能 (「基本的な hotspot」および「ロックと待機」など) は、インテル® プロセッサーと互換プロセッサーの両方で動作します。ハードウェア・コレクターおよびオンチップのパフォーマンス・モニタリング・ユニットを使用するプロファイル機能 (「高度な hotspot」および「マイクロアーキテクチャー解析」など) は、データ収集にはインテル® プロセッサーが必要ですが、収集後の結果は互換プロセッサーで解析できます。
いいえ。インテル® VTune ™ Amplifier でプロファイルを行うために再コンパイルする必要はありません。しかし、最も完全で有用な結果が得られるように、最適化されたアプリケーションでデバッグおよびシンボル情報を有効にすることを推奨します。このため、リリースビルドのプロセスはデバッグ情報を追加するように修正する必要があります。
いいえ。製品を入手した後、CLI インストーラー (コマンドライン・インストーラー) から同じ OS のほかのシステムでのデータ収集を設定できます。リモートシステムでは、データの収集はできますが、収集したデータの表示にはライセンスが必要です。データを表示するには、製品をインストールしたシステムに結果ディレクトリーをコピーします。詳細については、ドキュメントの「Remote Tuning Workflow (リモート・チューニング・ワークフロー)」を参照してください。インストールの詳細については、リリースノートの「リモートシステムでのコレクターのインストール」を参照してください。
インテル® VTune ™ Amplifier にソースコードが表示されない理由はいくつかあります。
ソースコードを表示するには、デバッグ情報が利用可能になるようにコードをコンパイルする必要があります。例えば、Linux* では、"-g" オプションを指定してコンパイルしていることを確認します。
インテル® VTune ™ Amplifier にソースファイル、バイナリーファイル、シンボルファイルの場所を知らせる必要もあります。既存のプロジェクトを開くか新規プロジェクトを作成して、[Project Properties (プロジェクト・プロパティー)] ボタンをクリックします。[Project Properties (プロジェクト・プロパティー)] ダイアログで、[Search Directories (検索ディレクトリー)] タブをクリックします。プルダウンメニューで、[All files (すべてのファイル)] をクリックして、ファイルが含まれているディレクトリーを指定します。サブディレクトリーが含まれる場合は、[Search subdirectories (サブディレクトリーを検索)] ボックスをオンにします。
いいえ。Linux* では、ハードウェア・コレクターのドライバーをインストールするには root 権限が必要ですが、ドライバーをインストールした後は root 権限は必要ありません。プリインストールされる perf ドライバーを使用することもできますが、perf では一部の機能はサポートされていません。Linux* では、ハードウェア・コレクターを使用するには、ドライバー・アクセス・グループ (デフォルトは 'vtune') に属している必要があります (選択されるインストール・オプションに依存します)。ハードウェア・コレクターは、高度な hotspot 解析や高度な解析に使用されます。詳細については、ドキュメントの「Installing the Sampling Driver (サンプリング・ドライバーのインストール)」を参照してください。
ハードウェアベースの (「高度な」) サンプリング解析タイプではプロセッサーのパフォーマンス・モニタリング・ユニット (PMU) との通信が必要になるため、インストーラーはデバイスドライバーをインストールしようとします。Windows® では、ドライバー (署名されています) をインストールするユーザーは管理者グループに属している必要があります。Linux* では、ドライバーをインストールするユーザーは、root ユーザーまたは sudo を利用可能なユーザーである必要があります。Linux* ユーザーは、デバイスドライバーなしでソフトウェアをローカルにインストールして、ユーザーモード・サンプリング解析タイプ (基本的な hotspot、コンカレンシー、ロックと待機) を使用できます。ユーザーはプリインストールされる perf ドライバーを使用することもできますが、perf では一部の機能はサポートされていません。ユーザーが root としてソフトウェアをインストールできる場合、ハードウェアベースのサンプルを収集するユーザーは、インストール中に定義されるユーザーグループに属している必要があります (インストール中に選択されるオプションに依存します)。デフォルトは 'vtune' グループですが、インストーラー (install.sh) の高度なオプションにアクセスして変更または省略することができます。
結果をインテル® VTune ™ Amplifier にインポートするには、最初にインポートする結果を含めるプロジェクトを作成する必要があります。インテル® VTune ™ Amplifier で、[File (ファイル)] > [New (新規)] > [Project (プロジェクト)] メニューをクリックします。プロジェクト名を指定するダイアログが表示されます。プロジェクト名を指定して、[OK] をクリックします。インテル® VTune ™ Amplifier の [Project Properties (プロジェクト・プロパティー)] ダイアログが表示されます。結果をプロジェクトへインポートするときにアプリケーションを指定する必要はありません。しかし、インポートした結果のソースを表示する場合は、ソースおよびバイナリーの場所を検索ディレクトリーに追加する必要があります。[Project Properties (プロジェクト・プロパティー)] ダイアログで、[Search Directories (検索ディレクトリー)] タブをクリックします。プルダウンメニューで、[All files (すべてのファイル)] をクリックして、ファイルが含まれているディレクトリーを指定します。サブディレクトリーが含まれる場合は、[Search subdirectories (サブディレクトリーを検索)] ボックスをオンにします。
検索ディレクトリーは、通常はデータ収集が完了した後に行われるファイナライズ中に使用されます。新しい検索ディレクトリーのパスを有効にするには、提供される新しい情報を使用してインテル® VTune ™ Amplifier で結果を再解決する必要があります。[Analysis Type (解析タイプ)] タブをクリックした後、[Start (スタート)] ボタンおよび [Project Properties (プロジェクト・プロパティー)] ボタンの下にある [Re-resolve (再解決)] ボタンをクリックします。
サンプルカウントは、実行可能なコードと通常関連付けられていないソース行 ('for' ループや 'while' ループの閉じ括弧など) に表示されることがあります。間違っているように見えるかもしれませんが、これはコンパイラーによって生成された命令の結果です。アセンブリー・コードを見ると、そのソース行に属するものとしてタグ付けされた (閉じ括弧)、サンプルが関連付けられたアセンブリー命令のデバッグ情報を明らかにすることができます。一方で、アセンブリー命令を見ると、特定のハードウェア・イベントが本来そのイベントを生成しない命令で収集されることがあります (例えば、ジャンプ命令のメモリーイベントやメモリー命令の算術イベント)。これは「イベントスキッド」と呼ばれ、命令ポインターをサンプリングする前にプロセッサーがいくつかのマイクロオペレーションを停止できないことが原因です。つまり、サンプルを処理している間に命令ポインターが後の命令を指してしまうのです。一般に、命令フローを調べることにより、そのイベントの原因となった命令を判断することができます。
アプリケーションが I/O をブロックしている場合、ファイルアクセスに起因する関数呼び出しが基本的な hotspot 解析に表示されます。また、1 つのファイルへのアクセスを待つ複数のスレッドがある場合、ファイルを保護する同期オブジェクト (クリティカル・セクションなど) がロックと待機解析に表示されます。
インテル® レジストレーション・センターで操作します。
操作手順やよくあるご質問、トラブルシューティングは、インテル® レジストレーション・センター操作マニュアルを参照ください。
最新版、または旧バージョンのダウンロードは、インテル® レジストレーション・センターで行います。
詳細は以下ページを参照ください。